Download as PDF, PPTX











![PGDay.IT 2017 - 11th
edition
Milan October, 13th
2017
Giuseppe Broccolo
g.broccolo.7@gmail.com
Viralize.com
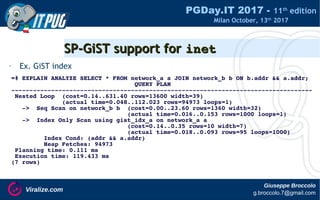
Extend AMs to datatypes: the OpClassesExtend AMs to datatypes: the OpClasses
• access methods use operator classes (opclass)
•
•
•
• define:
– operators for the needed types
– support functions depending on the access method
• can be extended to specific datatypes
CREATE INDEX idx_name
USING method
ON table (column opclass_name)
WITH (opt=value);
• CREATE OPERATOR CLASS opclass_name
FOR TYPE datatype
USING method
OPERATOR $$(),
[...],
FUNCTION func1(),
[...]](https://image.slidesharecdn.com/gbroccolopgdayit2017pg10indexes-171013122120/85/Indexes-in-PostgreSQL-10-12-320.jpg)












![PGDay.IT 2017 - 11th
edition
Milan October, 13th
2017
Giuseppe Broccolo
g.broccolo.7@gmail.com
Viralize.com
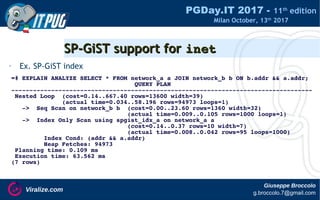
Hash indexes are now logged!Hash indexes are now logged!
• pre PostgreSQL 10:
hot standby
=# explain analyze select * from
=# hash_example where i = 123;
QUERY PLAN
-----------------------------------------
Index Scan using hash_idx on hash_example
(cost=0.00..8.02 rows=1 width=21)
(actual time=1.526..1.529 rows=1 loops=1)
[...]
master
=# explain analyze select * from
=# hash_example where i = 123;
ERROR: could not read block 0 in file
"base/16402/458955269": read only 0 of
8192 byte
=# SET enable_index_scan TO false;
SET
WALWAL WALWALWALWAL](https://image.slidesharecdn.com/gbroccolopgdayit2017pg10indexes-171013122120/85/Indexes-in-PostgreSQL-10-25-320.jpg)









The document presents a detailed overview of PostgreSQL indexes, focusing on the improvements and new features introduced in version 10, including parallelism, hash indexing, and support for sp-gist on inet data types. It discusses various access methods, their structures, and performance characteristics, as well as execution plans and their optimizations. The presentation also highlights the logging of hash indexes and enhancements in handling inet data with sp-gist methods.















![[PGDay.Seoul 2020] PostgreSQL 13 New Features](https://cdn.slidesharecdn.com/ss_thumbnails/2020pgdayseoulpostgresql13newfeatures-201116014501-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[DSC Europe 25] Srdj Stanisic - Local and Private AI in UX.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vwmetykqmztgmokmmkfa-3-srdjan-stanisic-local-and-small-ai-in-ux-260120105855-55a31869-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Tamas Srancsik - How To Teach Your AI Football? An Argument f...](https://cdn.slidesharecdn.com/ss_thumbnails/bcjh1m9xtbosv20ucftb-tamas-srancsik-how-to-teach-your-ai-football-260121115910-08b53e9e-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)
