Download to read offline












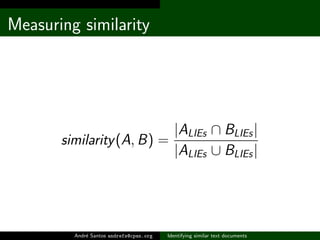

![Behold, pairbooks!
~ $ pairbooks PT_list.txt ES_list.txt
PTBR__Umberto_EcoO_nome_da_rosa.txt
(0.227) [6954,7382] ES__Umberto_EcoEl_Nombre_de_la_Rosa(...)
(0.018) [6954,11408] ES__Umberto_EcoEl_Pendulo_De_Foucau(...)
(0.018) [6954,5604] ES__Umberto_EcoDiario_Minimo__2.txt(...)
PTBR__Umberto_EcoO_Pendulo_de_Focault.txt
(0.391) [11276,11408] ES__Umberto_EcoEl_Pendulo_De_Foucau(...)
(0.042) [11276,6024] ES__Umberto_EcoLa_busqueda_de_la_Le(...)
(0.035) [11276,5604] ES__Umberto_EcoDiario_Minimo__2.txt
(...)
Andr´ Santos andrefs@cpan.org
e Identifying similar text documents](https://image.slidesharecdn.com/slides-111122131209-phpapp01/85/Identifying-similar-text-documents-15-320.jpg)





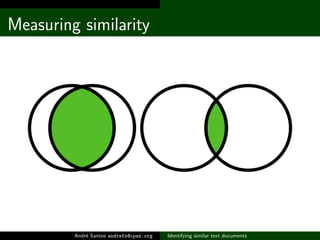
The document discusses methods for identifying similar text documents, focusing on measuring similarity based on language-independent elements and candidate pairs. It outlines a numerical system to categorize document similarity, with thresholds for duplication and potential relationships. The author suggests areas for future improvement, including the acceptance of equivalent words and stop words.






































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)








