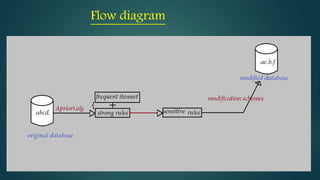
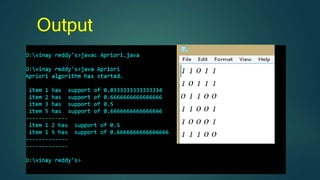
The document discusses hiding sensitive association rules from mined data. It begins with an introduction to privacy preserving data mining and association rule hiding algorithms. It then provides terminology for key concepts like data mining, association rules, support and confidence. The document outlines the scope and applications of association rule mining. It presents the problem formulation and discusses modification schemes for hiding rules, such as deletion and insertion of items. It provides implementation steps and a flow diagram for the process. Finally, it includes an example to illustrate the Apriori algorithm for mining association rules from transactional data.