Downloaded 20 times



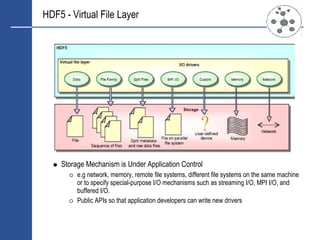



![Grid Infrastructure
Centralised Data Centres
Centralised data means centralised risk.
Extreme risk events would render business continuity planning ineffective.
Huge energy requirements (15MW, 5MW of which is cooling)
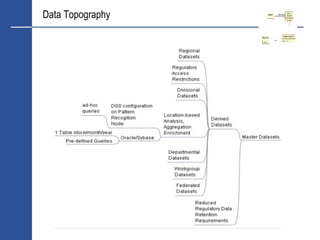
Data is Mobile - Not All Data Needs Enterprise Class Persistence
HDF5 makes it easy to forward cache static/reference data calved from master data
sets
Regional/Divisional/Departmental/Workgroup
Real-time computational derivation using FPGA’s and/or calculation farms
Reduced cost whilst maintaining regulatory compliance
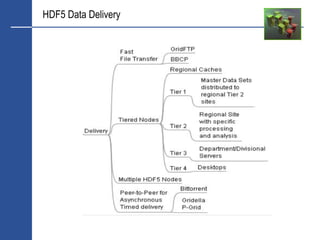
Micro-hosting - Crisis Resilient Grid Architecture
Software chooses the most appropriate execution environment and marshals data
accordingly
Each site operational has 20-30 low cost COTS nodes, minimal cooling, energy
footprint up to 15KW, multiple network connections.
KNURR Secure 10/20KW Water cooled cabinets located across infrastructure [3]](https://image.slidesharecdn.com/hdf5-101019233653-phpapp01/85/Hdf5-9-320.jpg)
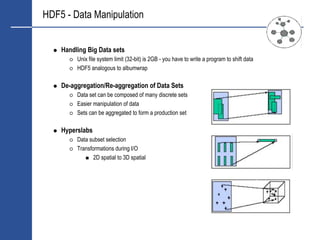
![HDF5 - Enabling High-Frequency Finance
HFF Drivers
Advances in statistical and Operational Research techniques
Improved access to data sets by academia.
Advances in computer infrastructure, reduction in storage costs
The need to find a trading edge.
Quantitative approach augmented by statistical analysis
HDF5 Global Data Repository For Raptor [2]
Project under way at Deutsche Bank, part of the Raptor infrastructure
Raptor requires massive data sets
Providing “early warning” predictive analysis
Pre transaction validation of complex derivatives transactions
Synthesised Data: yield curves, volatility surfaces (time/strike), vwap
News capture
Sentiment Analysis
Traffic Analysis](https://image.slidesharecdn.com/hdf5-101019233653-phpapp01/85/Hdf5-10-320.jpg)




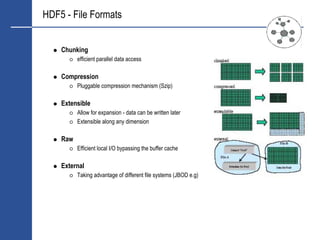
![Data Depth Perspective
Figures Are Humanly Incomprehensible
The World Produced in 1999 [1]:
1.5 exabytes (260) of storable content - 1.5 billion gigabytes
250 megabytes for every man, woman, and child on earth.
Printed documents of all kinds make up only .003 percent of the total.
Magnetic storage is by far the largest medium for storing information and is the most
rapidly growing
Shipped hard-drive capacity doubling every year.
Amount of human generated content - 5TB
Financial Market Data
LSE Basic set is 14GB for 2 Years (stock, shares, price, bid, ask, flags)
Market Depth + News + Traffic Analysis
VWAP + Volatilities
Many Terabytes required](https://image.slidesharecdn.com/hdf5-101019233653-phpapp01/85/Hdf5-15-320.jpg)
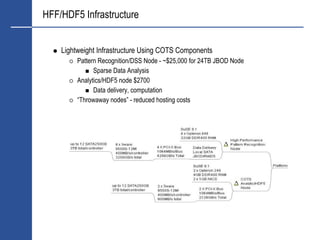





![HDF5 File Creation
#include "hdf5.h"
#define FILE "dset.h5”
main() {
hid_t file_id, dataset_id, dataspace_id; /* identifiers */
hsize_t dims[2];
herr_t status;
/* Create a new file using default properties. */
file_id = H5Fcreate(FILE, H5F_ACC_TRUNC, H5P_DEFAULT, H5P_DEFAULT);
/* Create the data space for the dataset. */
dims[0] = 4;
dims[1] = 6;
dataspace_id = H5Screate_simple(2, dims, NULL);
/* Create the dataset. */
dataset_id = H5Dcreate(file_id, "/dset", H5T_STD_I32BE, dataspace_id,
H5P_DEFAULT);
/* End access to the dataset and release resources used by it. */
status = H5Dclose(dataset_id);
/* Terminate access to the data space. */
status = H5Sclose(dataspace_id);
/* Close the file. */
status = H5Fclose(file_id);
}](https://image.slidesharecdn.com/hdf5-101019233653-phpapp01/85/Hdf5-26-320.jpg)
![HDF5 Reading and Writing Existing Datasets
#include "hdf5.h"
/*
#define FILE "dset.h5"
* Writing and reading an existing dataset.
main() {
*/
hid_t file_id, dataset_id; /* identifiers */
herr_t status;
int#include "hdf5.h"
i, j, dset_data[4][6];
#define FILE "dset.h5"
/* Initialise the dataset. */
for (i = 0; i < 4; i++)
formain() j{< 6; j++)
(j = 0;
dset_data[i][j] = i * 6 + j + 1;
/* hid_t existing file. */
Open an file_id, dataset_id; /* identifiers */
file_id = H5Fopen(FILE, H5F_ACC_RDWR, H5P_DEFAULT);
herr_t status;
/* int an existing dataset. */
Open i, j, dset_data[4][6];
dataset_id = H5Dopen(file_id, "/dset");
/* /* Initialize */
Write the dataset. the dataset. */
status = H5Dwrite(dataset_id, H5T_NATIVE_INT, H5S_ALL, H5S_ALL, H5P_DEFAULT,dset_data);
for (i = 0; i < 4; i++)
status = (j = 0; j < 6; H5T_NATIVE_INT, H5S_ALL,
for H5Dread(dataset_id, j++) H5S_ALL, H5P_DEFAULT,dset_data);
/* dset_data[i][j] = i * 6 + j + 1;
Close the dataset. */
status = H5Dclose(dataset_id);
/* /* Open file. existing file. */
Close the an */
status = H5Fclose(file_id);
file_id = H5Fopen(FILE, H5F_ACC_RDWR, H5P_DEFAULT);
}
/* Open an existing dataset. */
dataset_id = H5Dopen(file_id, "/dset");
/* Write the dataset. */
status = H5Dwrite(dataset_id, H5T_NATIVE_INT, H5S_ALL, H5S_ALL,
H5P_DEFAULT,](https://image.slidesharecdn.com/hdf5-101019233653-phpapp01/85/Hdf5-27-320.jpg)

![References
[1] How Much Storage is Enough?
http://www.acmqueue.org/modules.php?name=Content&pa=showpage&pid=45
[2] Different Shades of Meaning in the Stock Market
http://www.enhyper.com/content/kerrraptor.jpg
[3] Knurr 10/20KW Water-cooled Environments
http://www.water-cooled-server-rack.com/](https://image.slidesharecdn.com/hdf5-101019233653-phpapp01/85/Hdf5-29-320.jpg)

Financial Data Infrastructure with HDF5 HDF5 is a file format and library that can address the growing need for data storage and management in financial institutions. It allows for [1] limitless data storage through efficient compression and configurable storage granularity, as well as [2] parallel data access and delivery. HDF5 is also infrastructure agnostic and can scale across heterogeneous environments. When used for financial market data and high frequency trading applications, HDF5 has the potential to store massive datasets needed for predictive analytics and algorithmic trading strategies.



































































