Downloaded 23 times


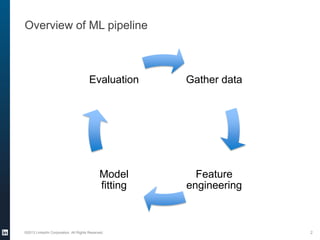



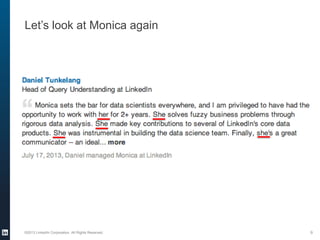

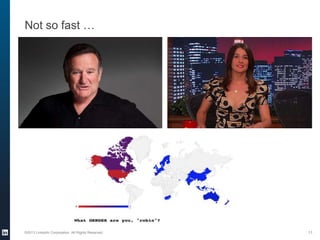


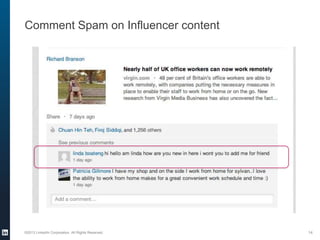

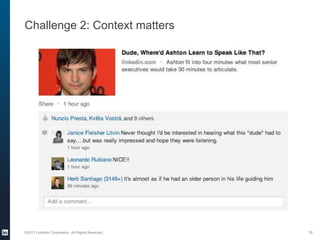

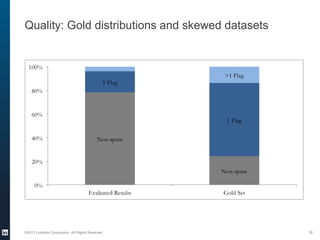



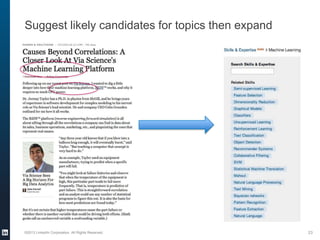

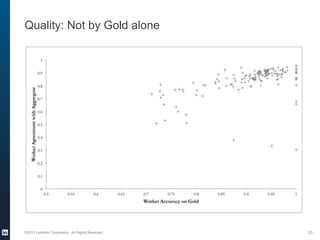
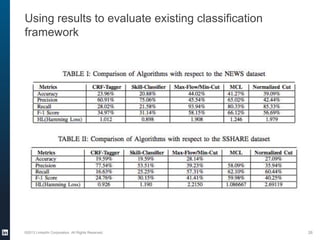

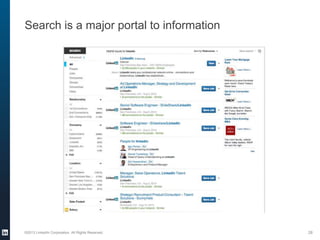
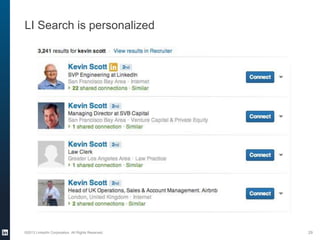

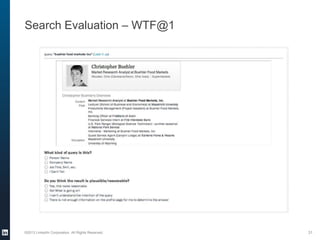
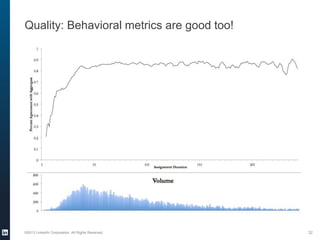












The document provides an overview of the machine learning pipeline, emphasizing data gathering, feature engineering, and model evaluation. Key points include the importance of context in tasks, the challenges of binary tasks, and the significance of quality data. It concludes with best practices for working with data and tips for improving classification models.















































![DataEngConf SF16 - BYOMQ: Why We [re]Built IronMQ](https://cdn.slidesharecdn.com/ss_thumbnails/byomq-160414230807-thumbnail.jpg?width=640&height=640&fit=bounds)



















![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)










