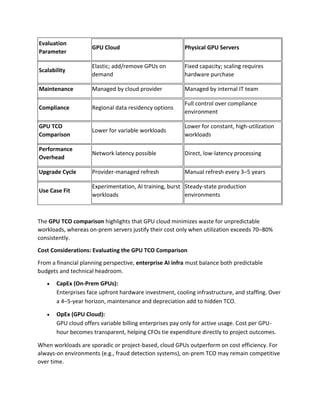
For Indian enterprises evaluating GPU cloud vs on-prem, ESDS Software Solution Ltd. offers GPU as a Service (GPUaaS) through its India-based data centers.
These environments provide region-specific GPU hosting with strong compliance alignment, measured access controls, and flexible billing suited to enterprise AI infra planning.
With ESDS GPUaaS, organizations can deploy AI workloads securely within national borders, scale training capacity on demand, and retain predictable operational costs without committing to physical hardware refresh cycles.