










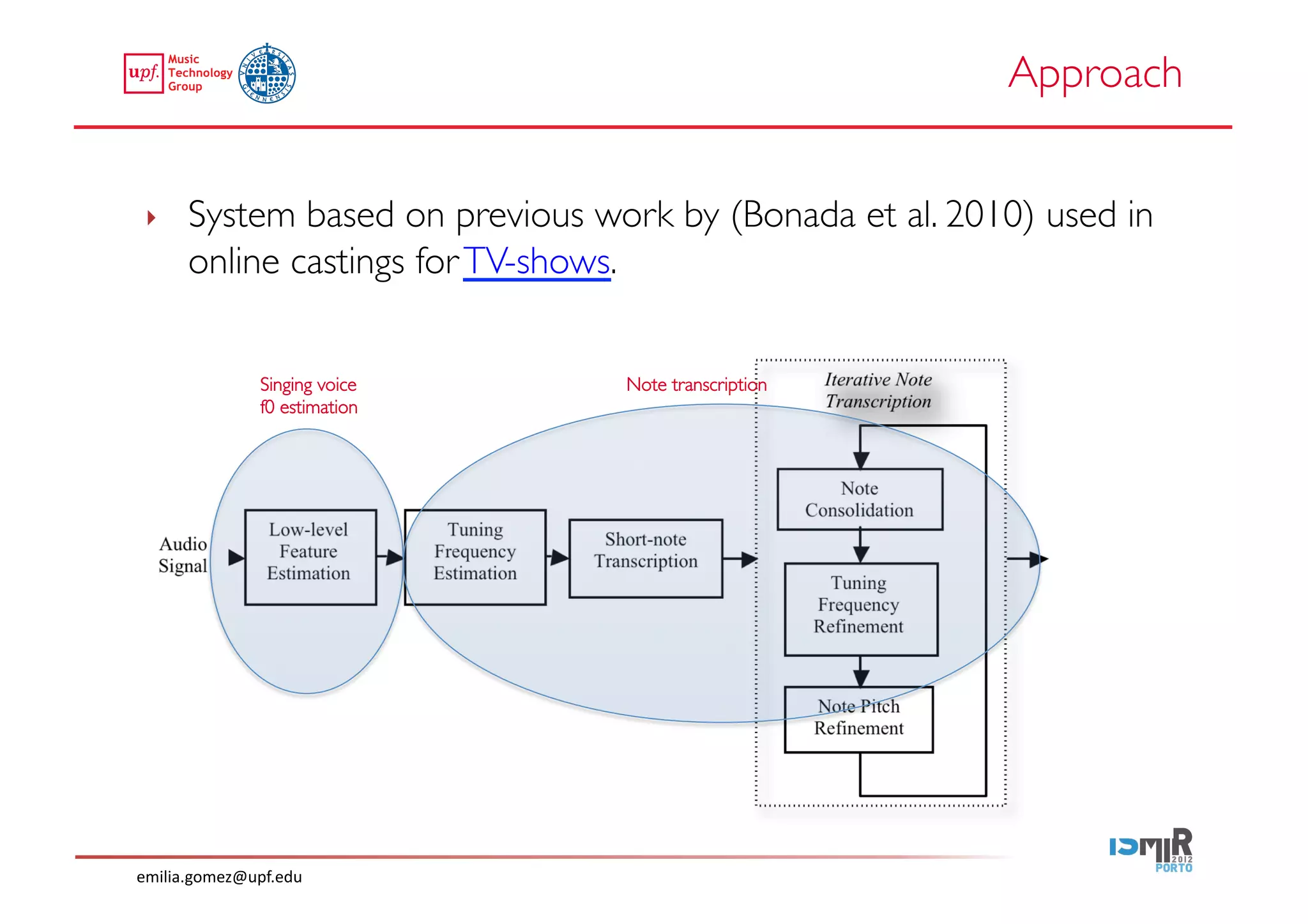
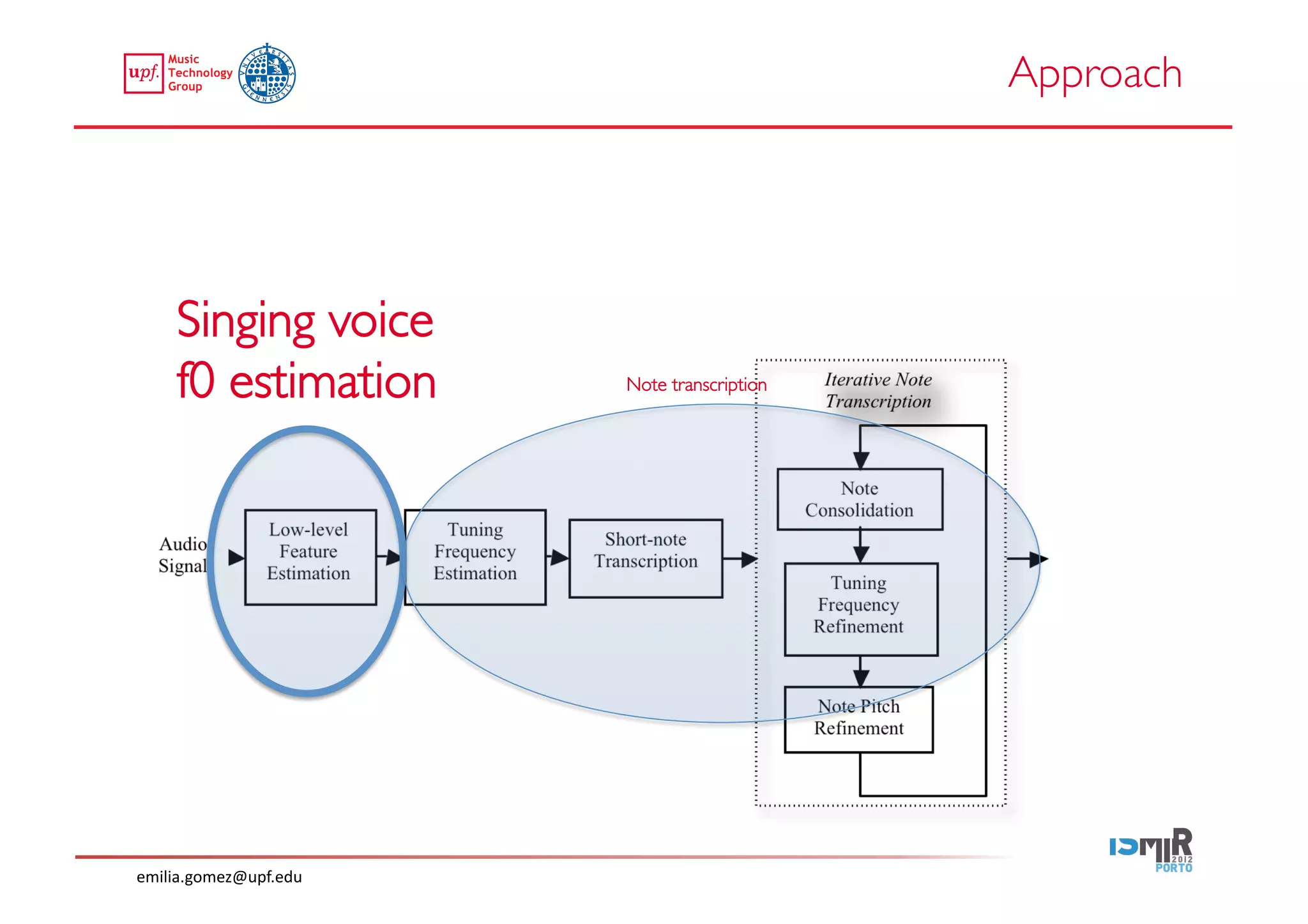



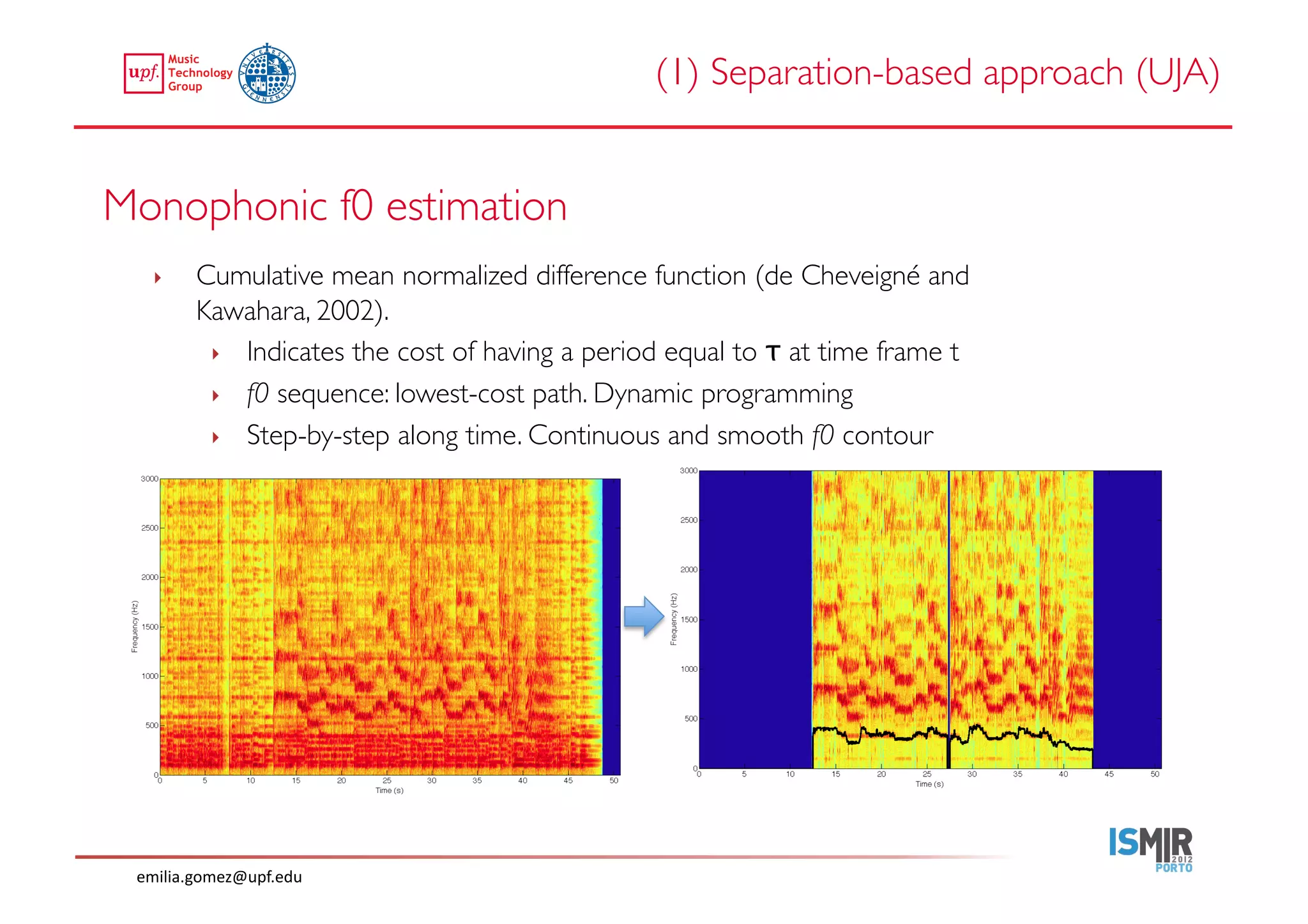

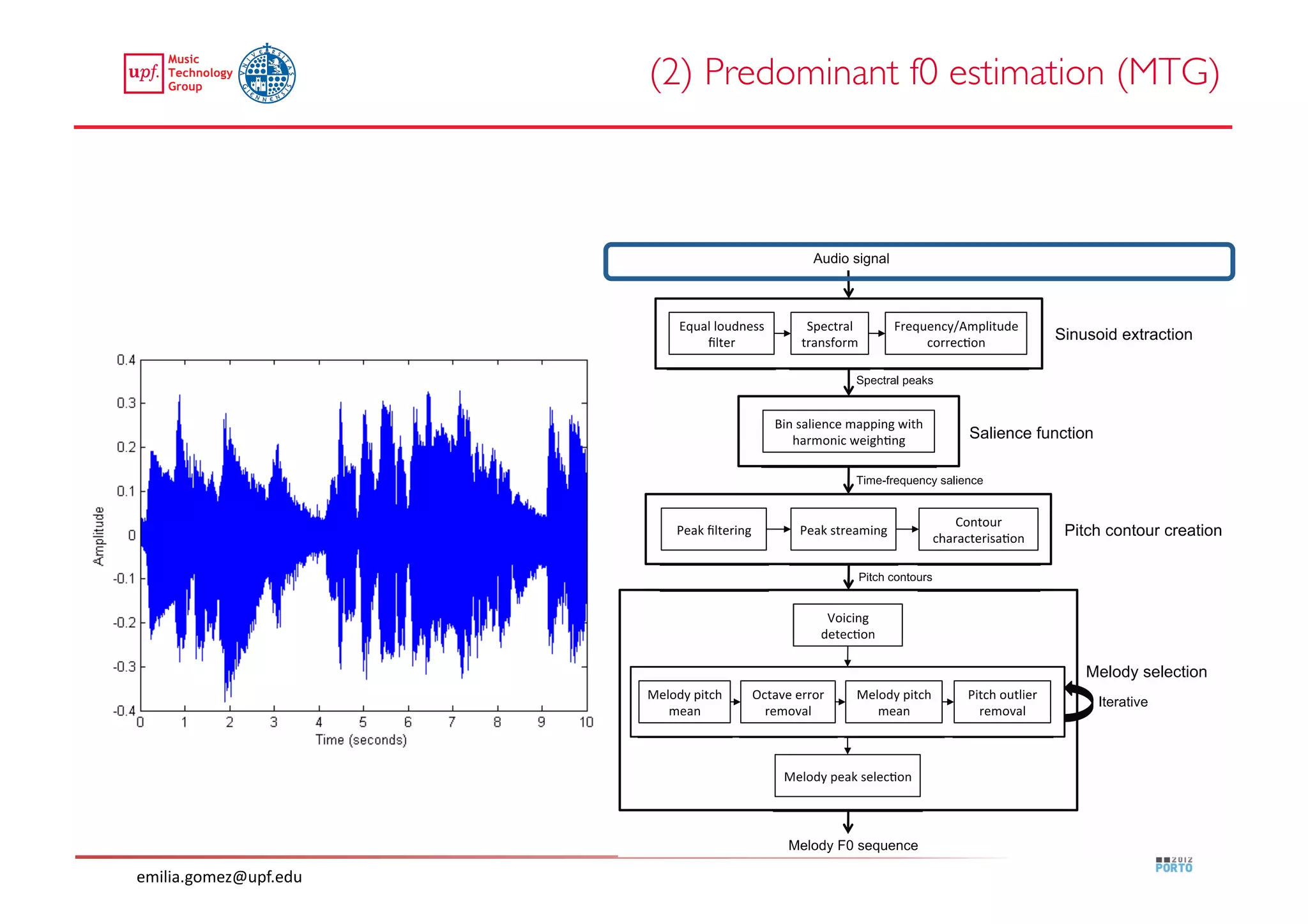
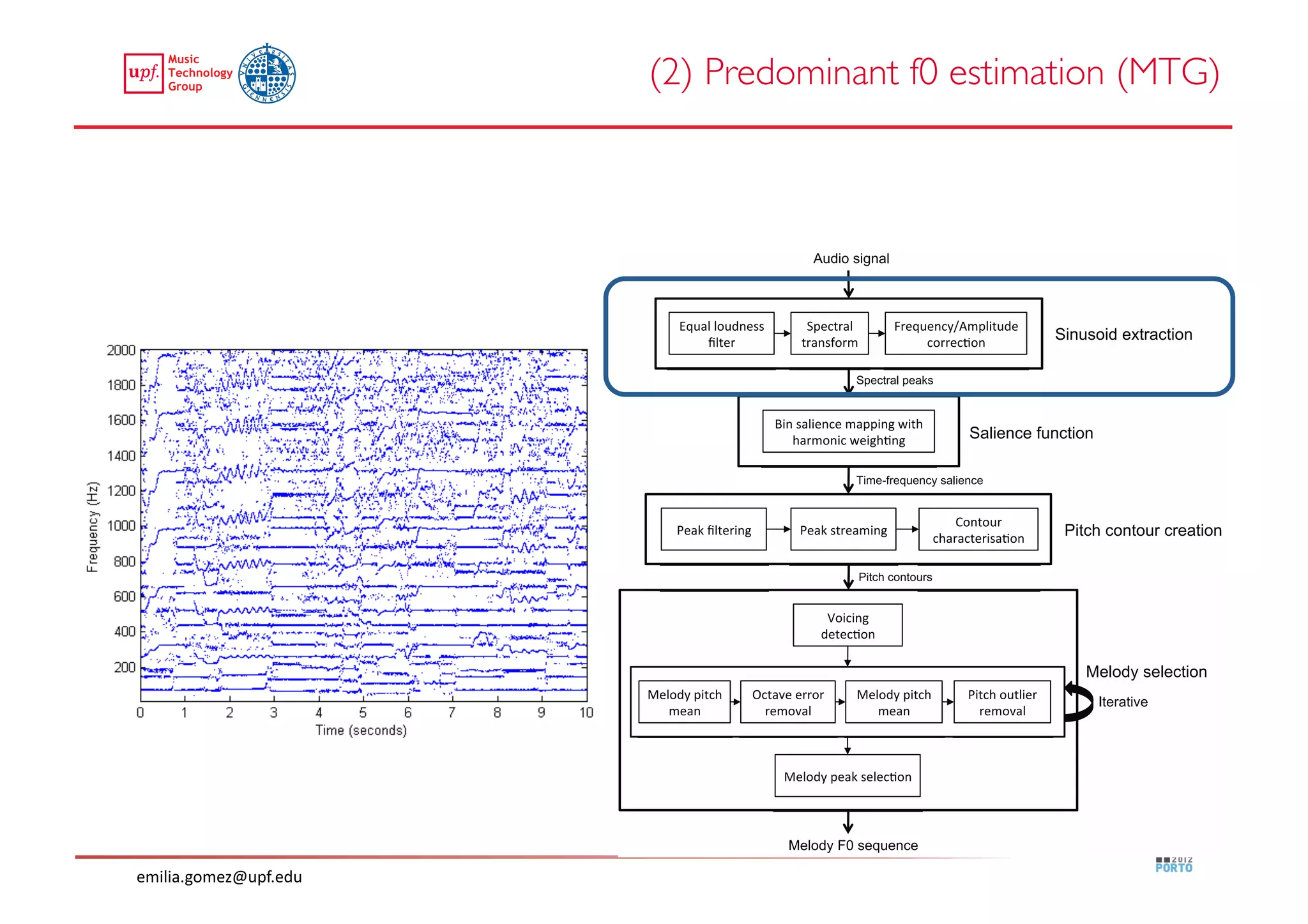
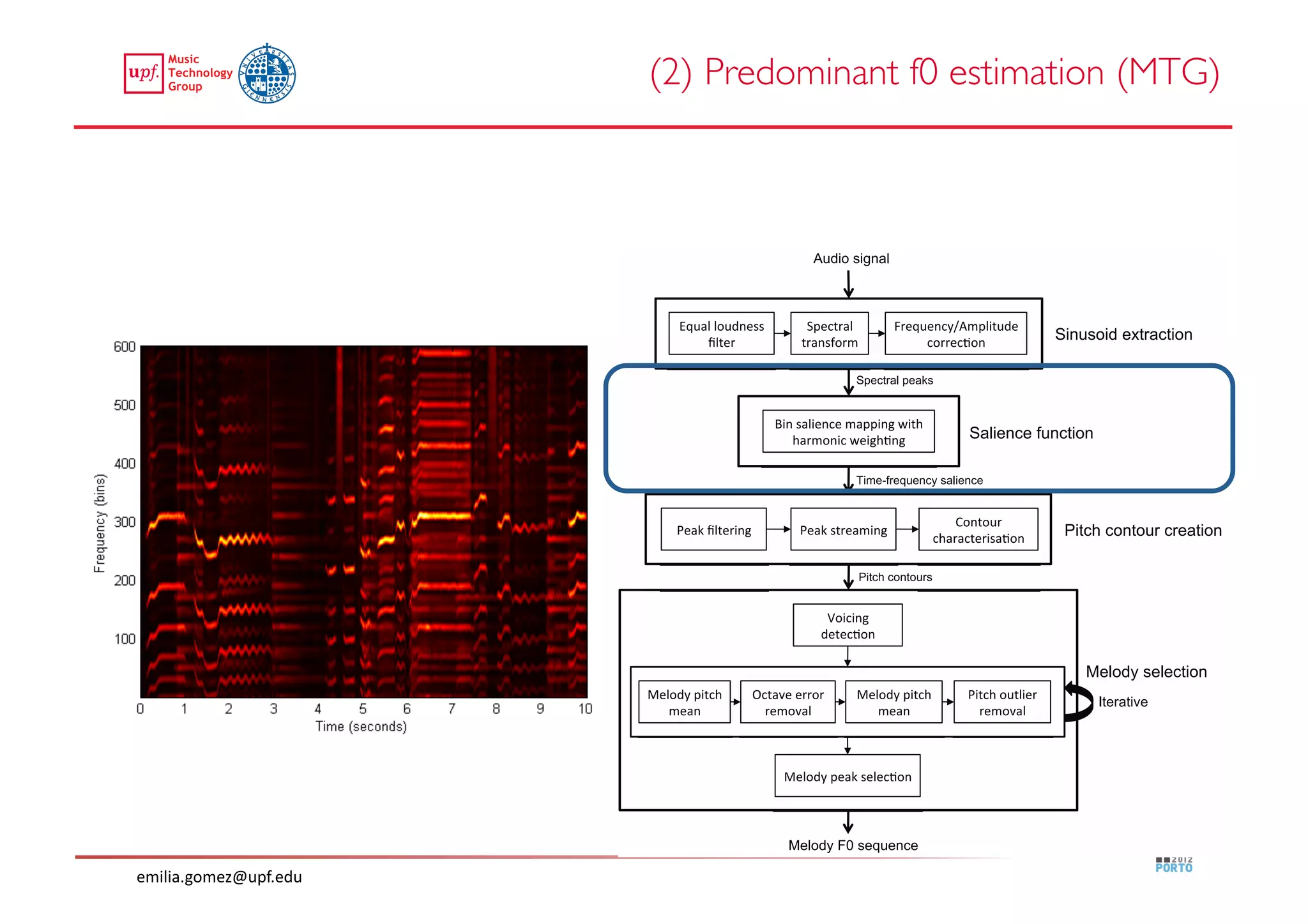
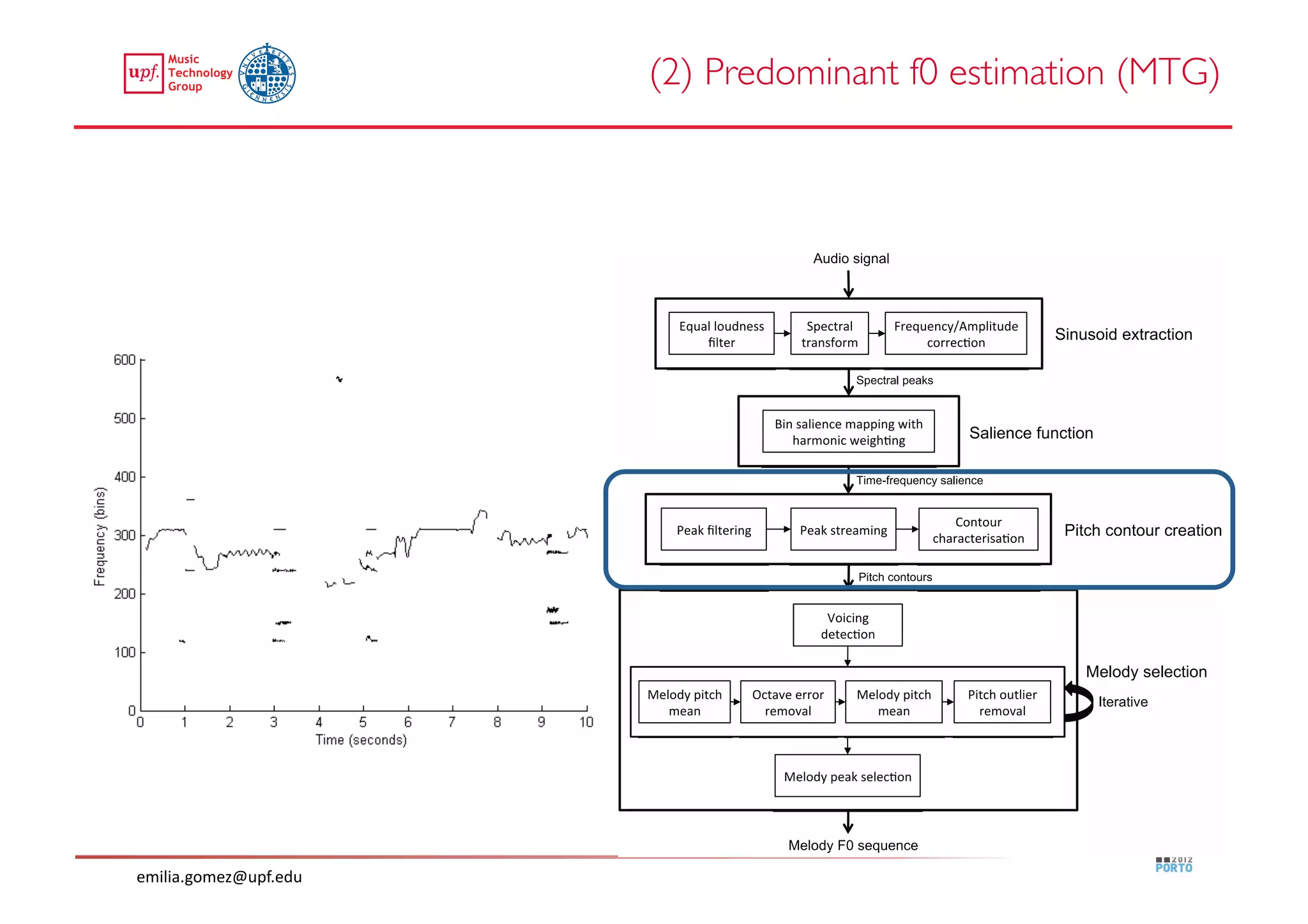
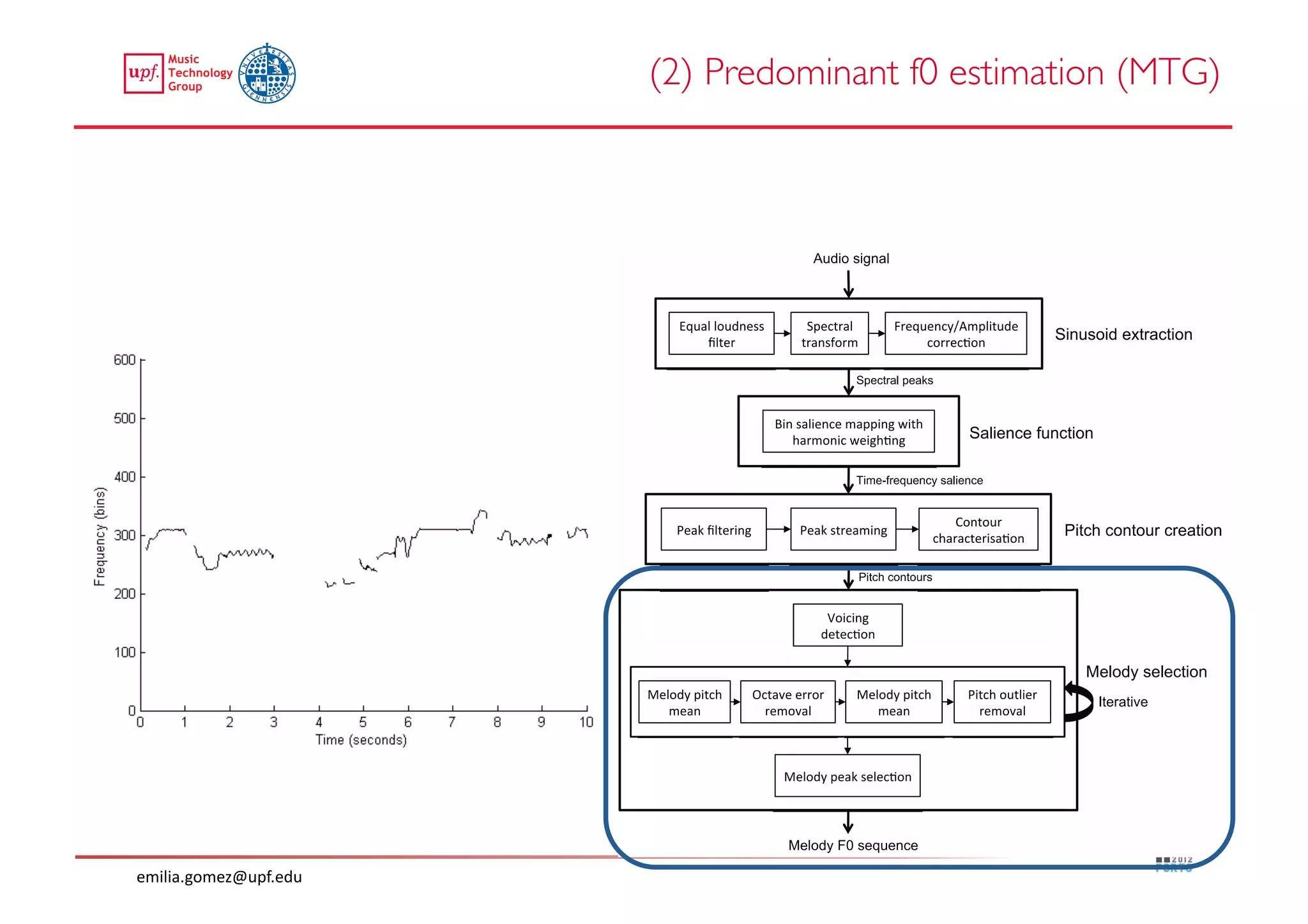
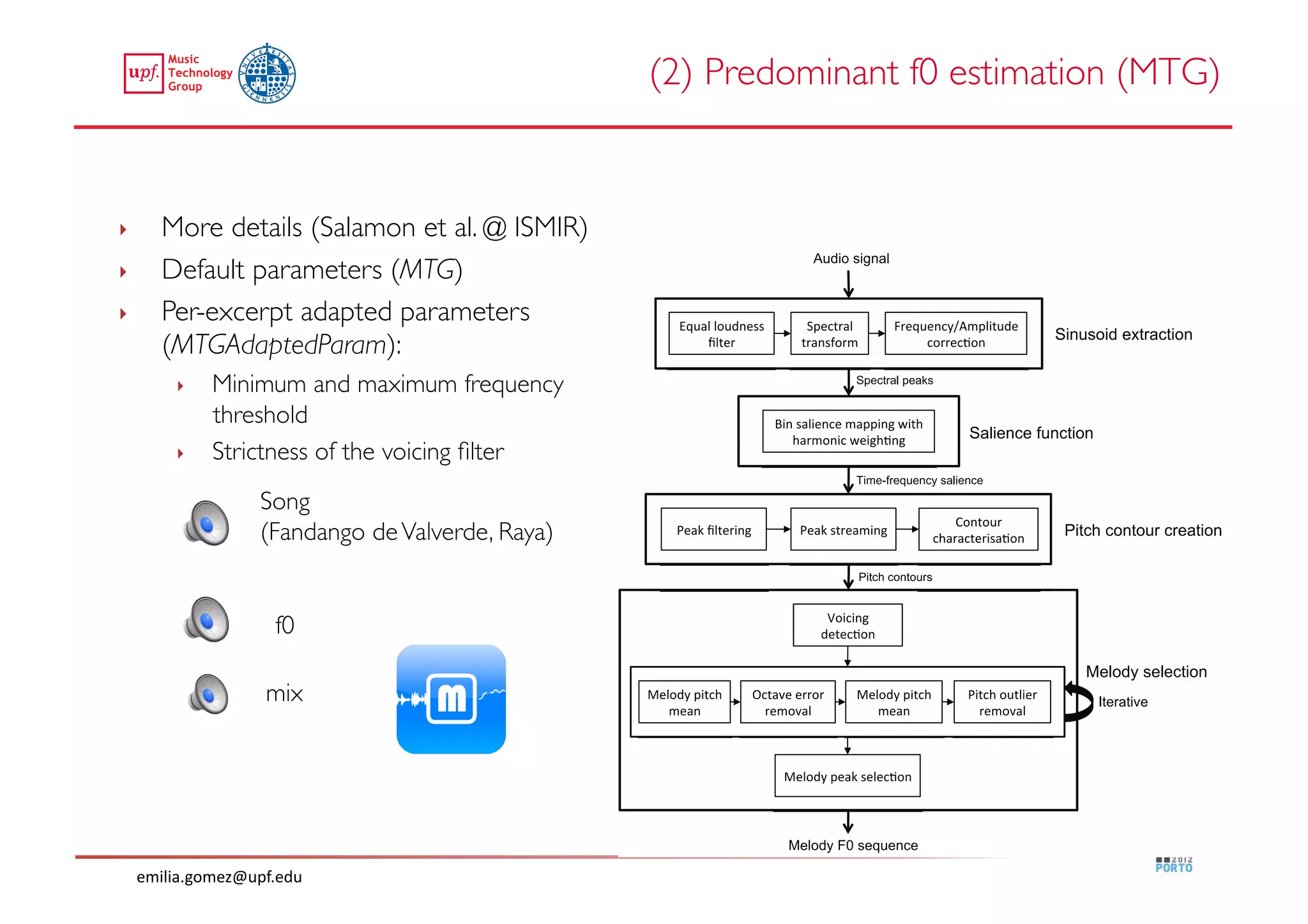
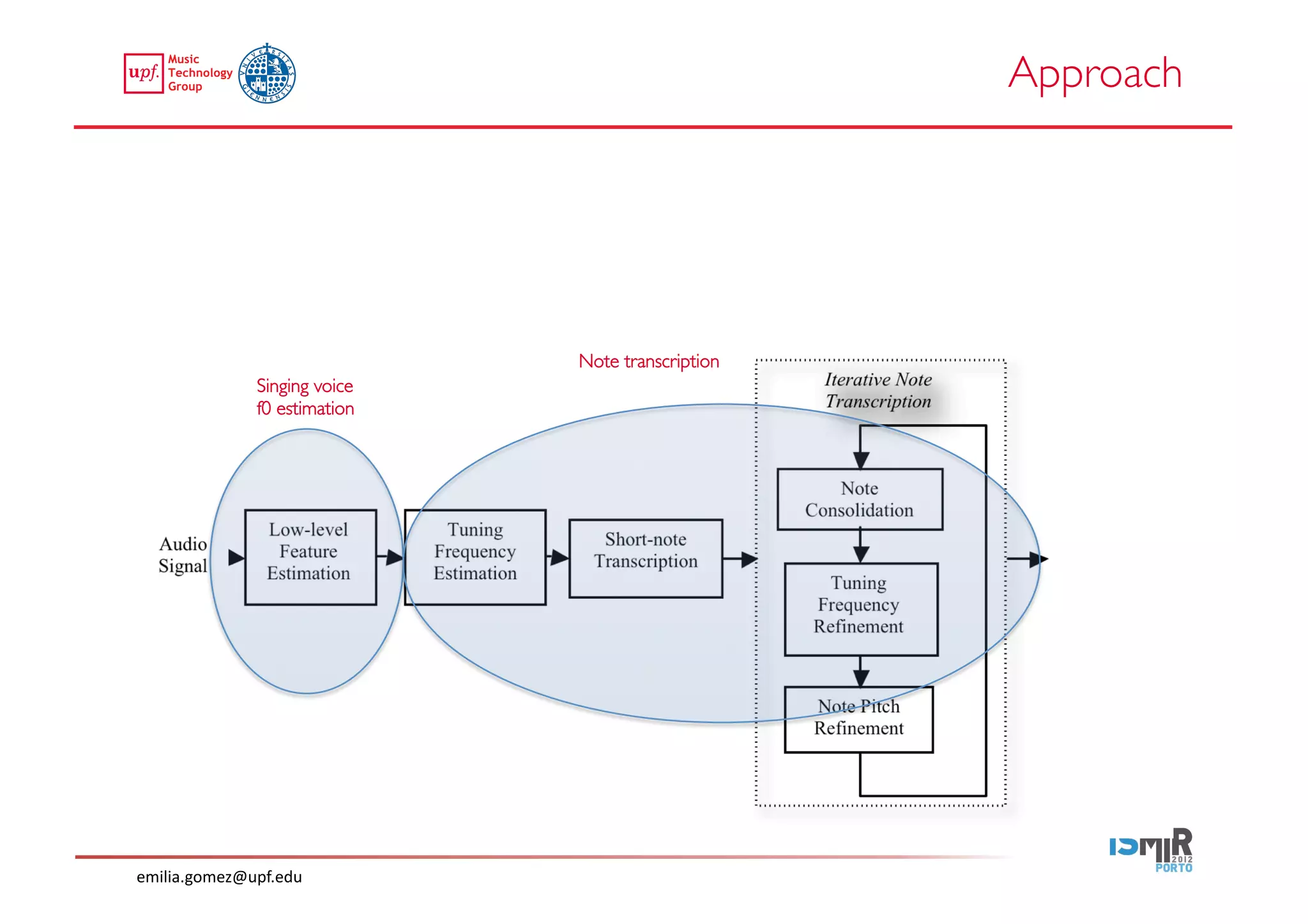
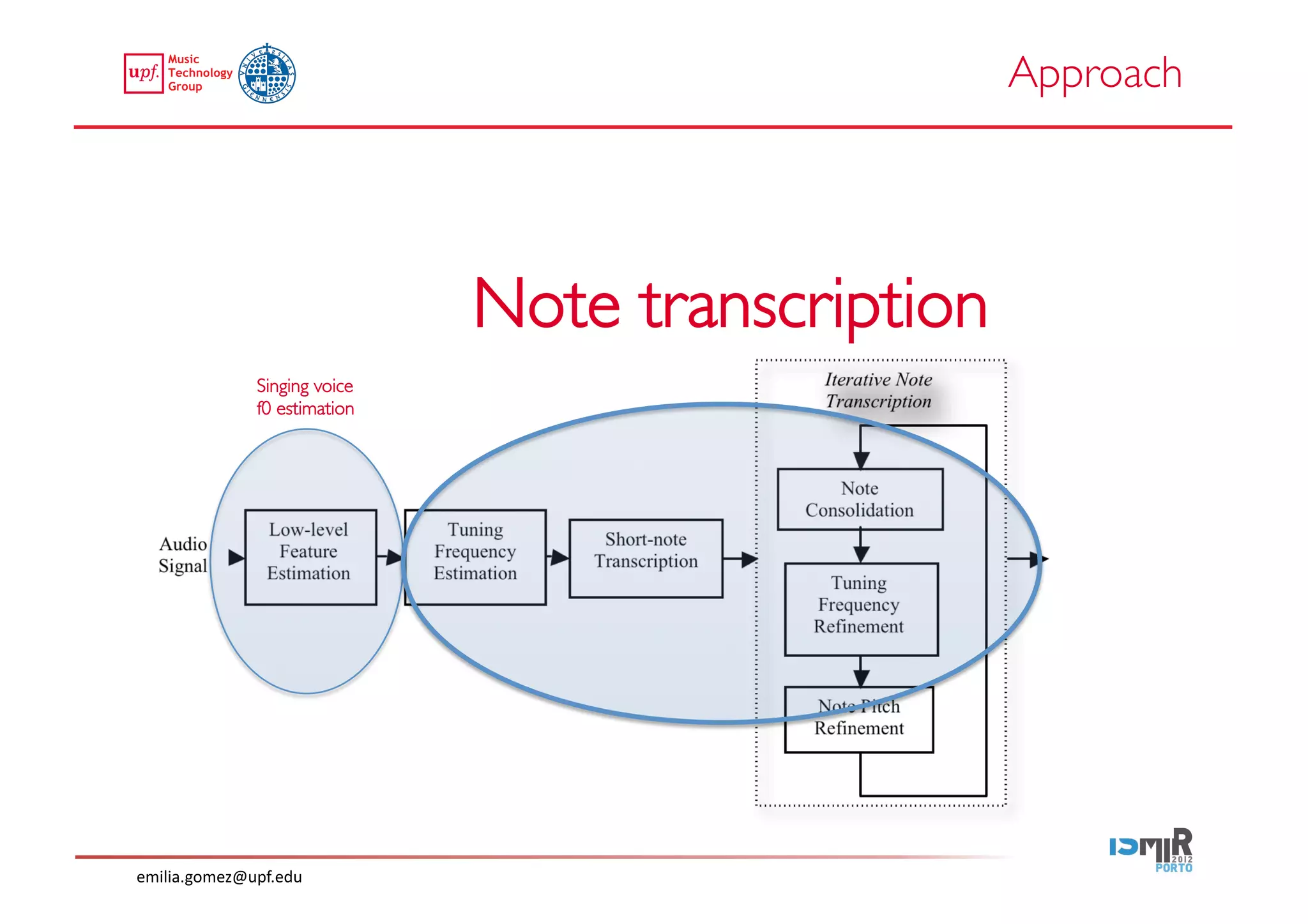
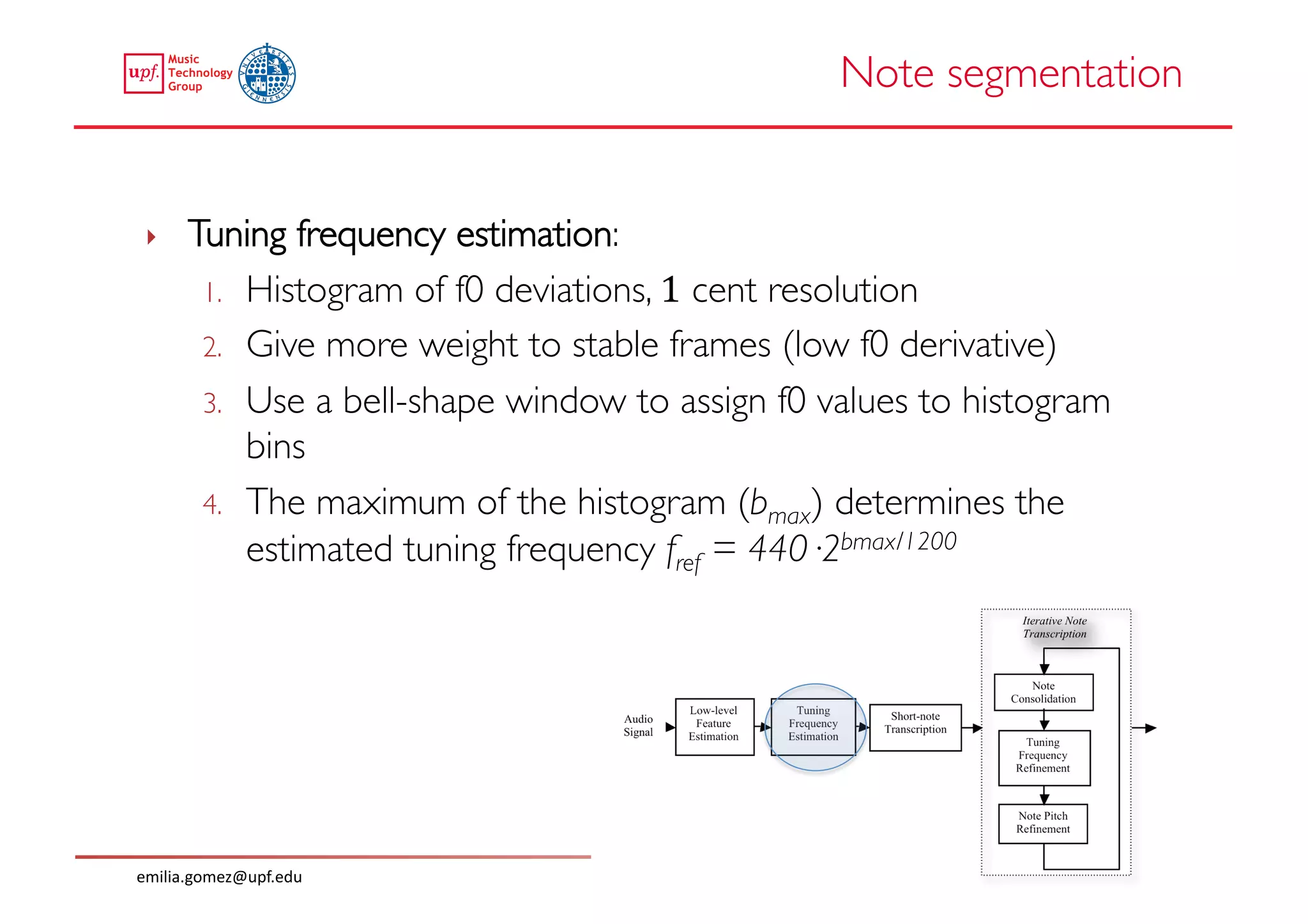
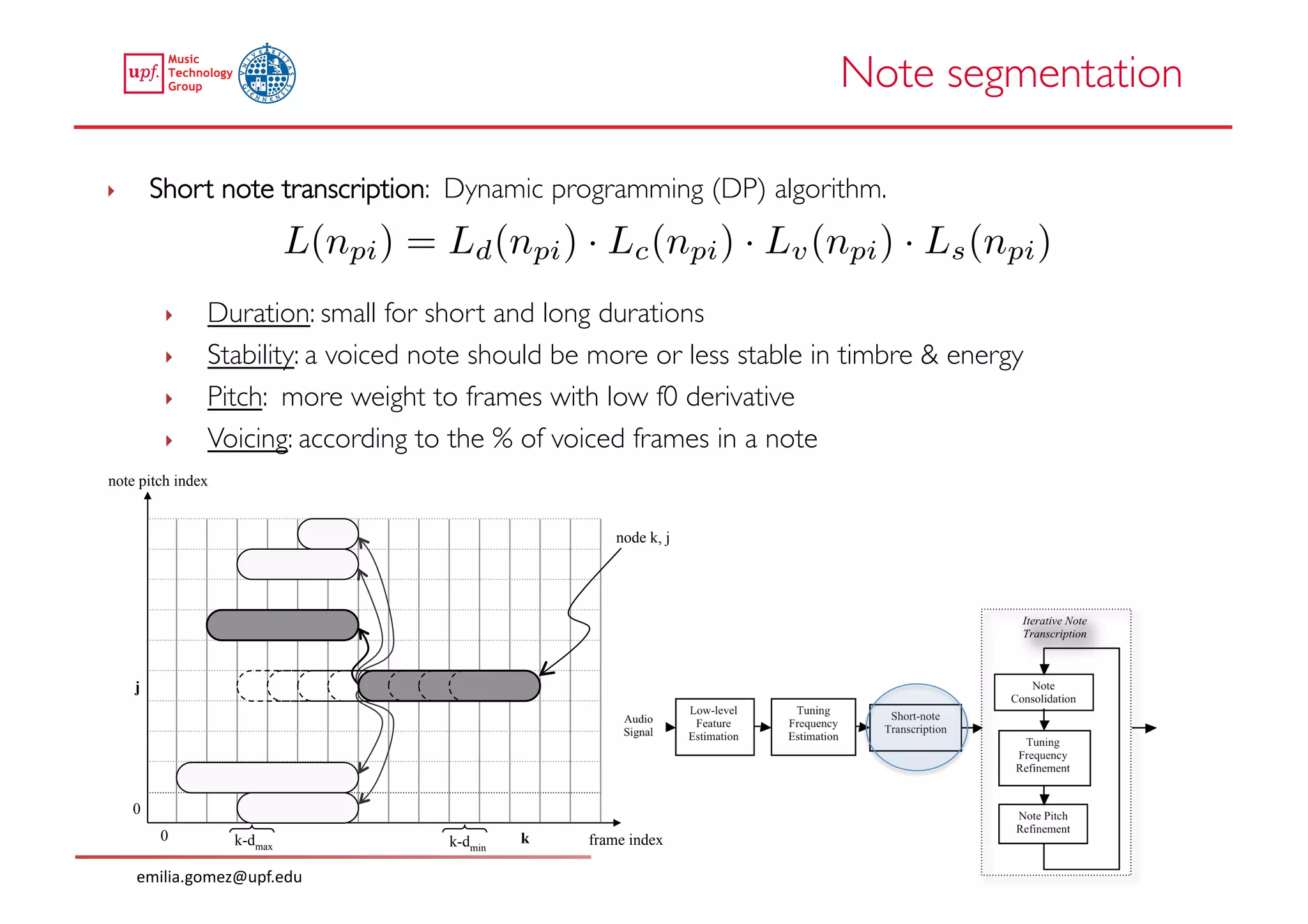
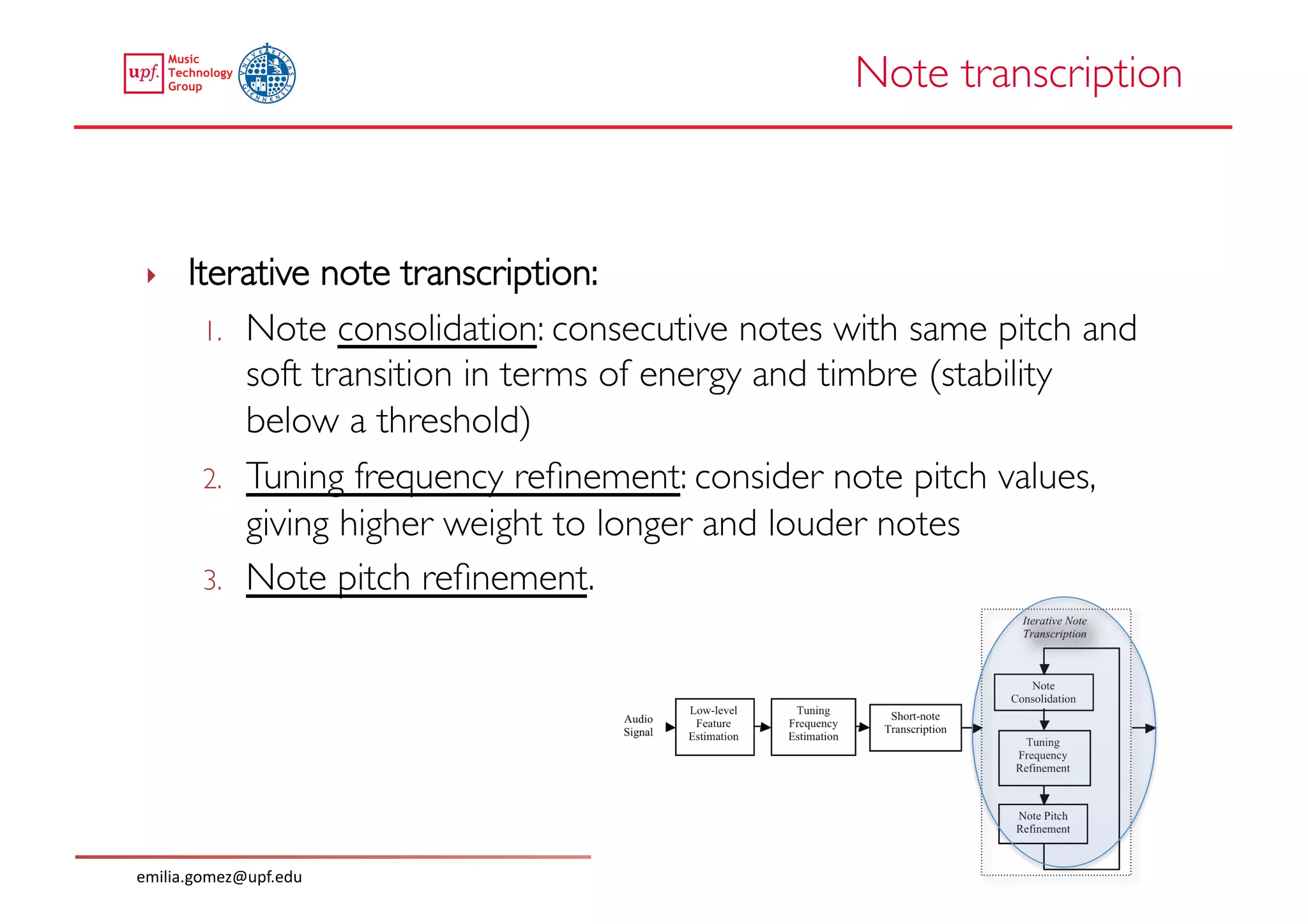





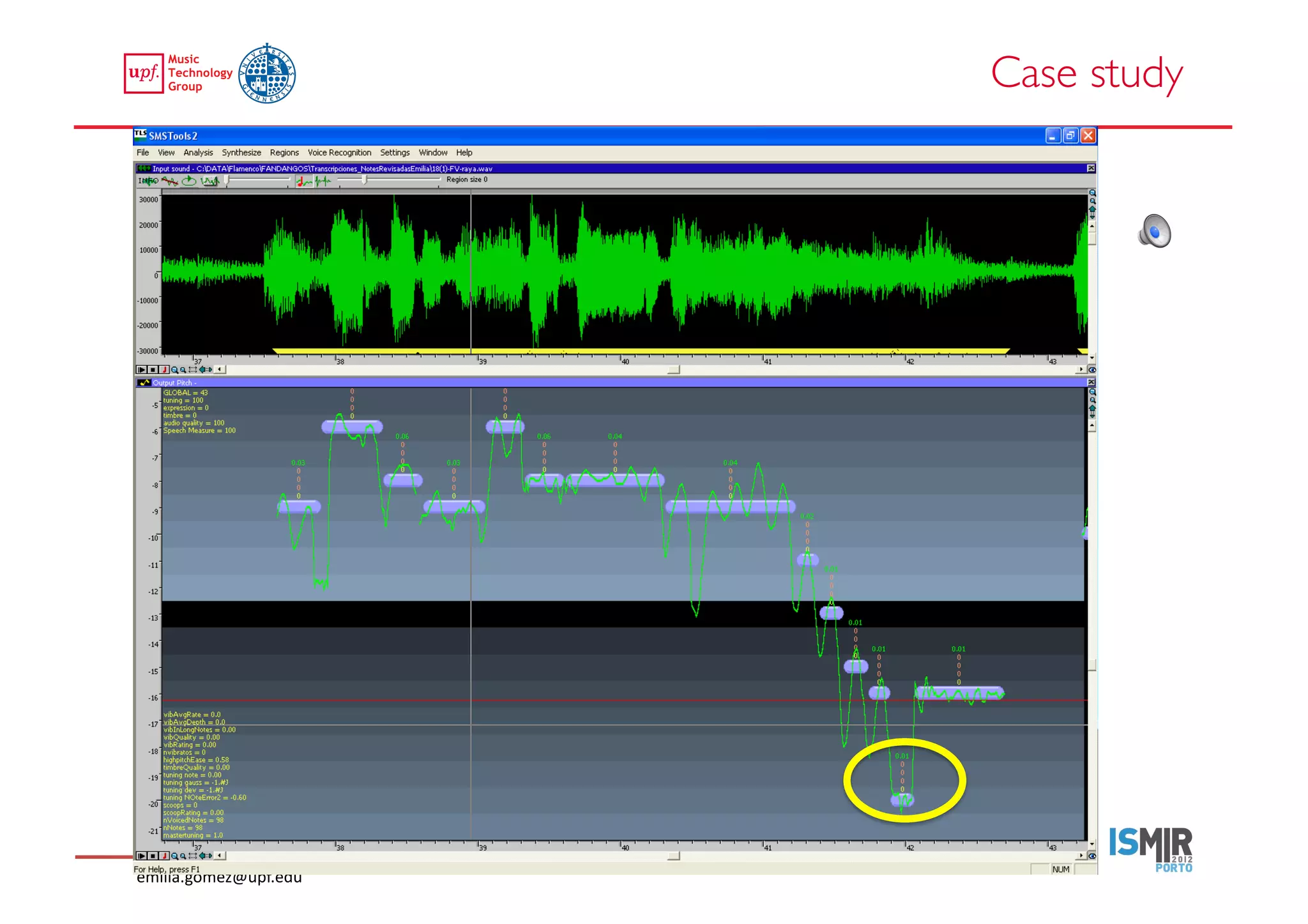
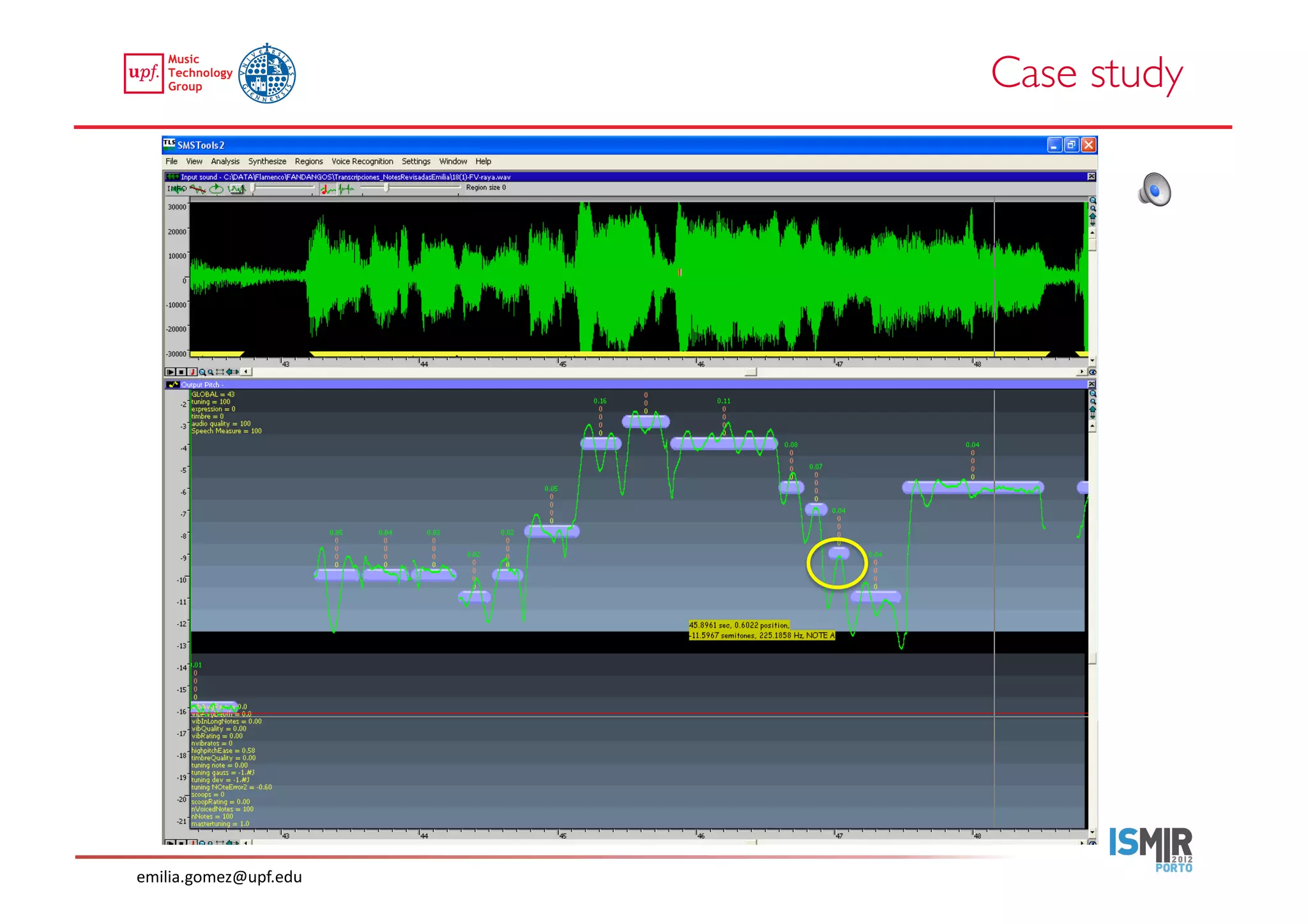
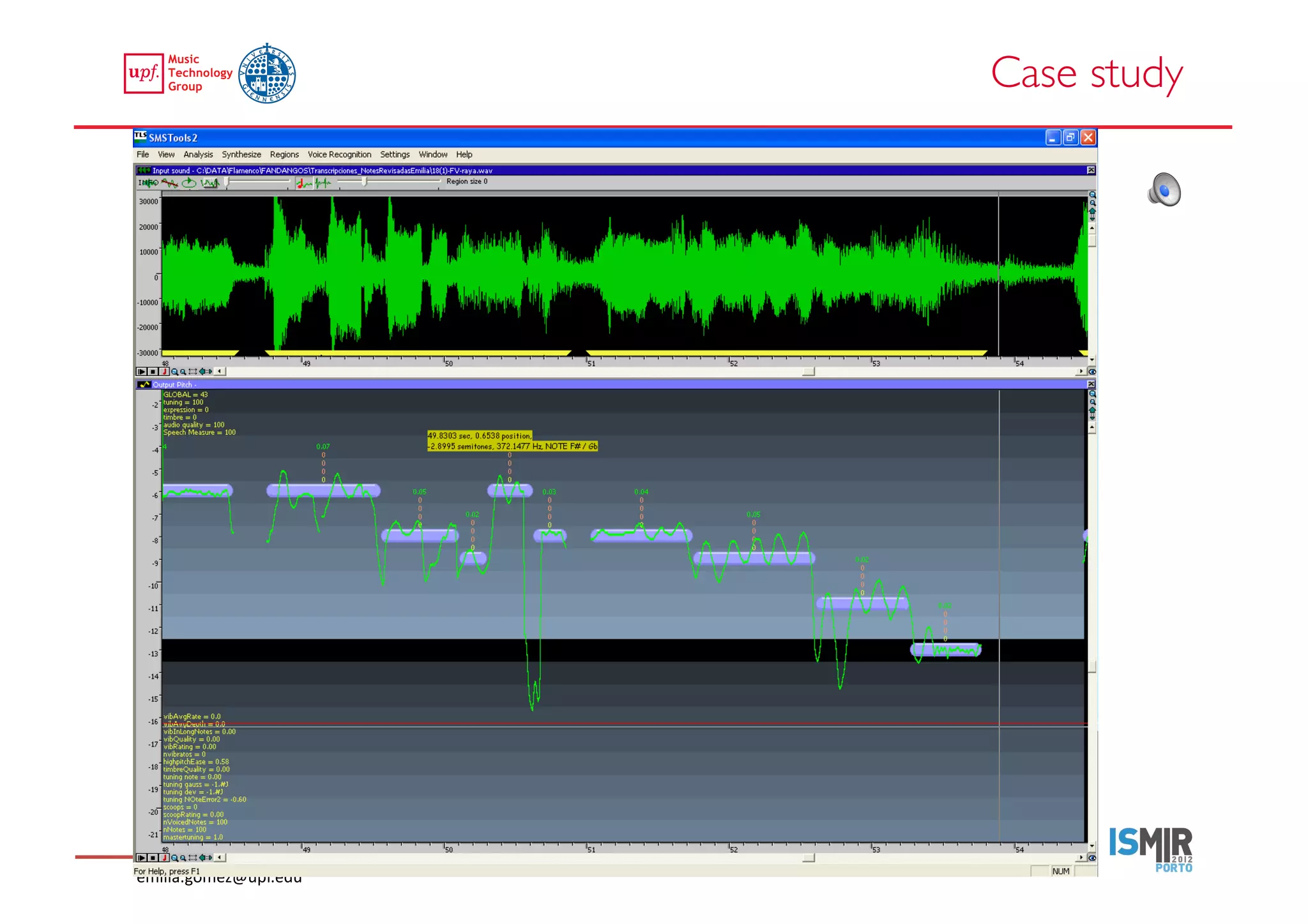
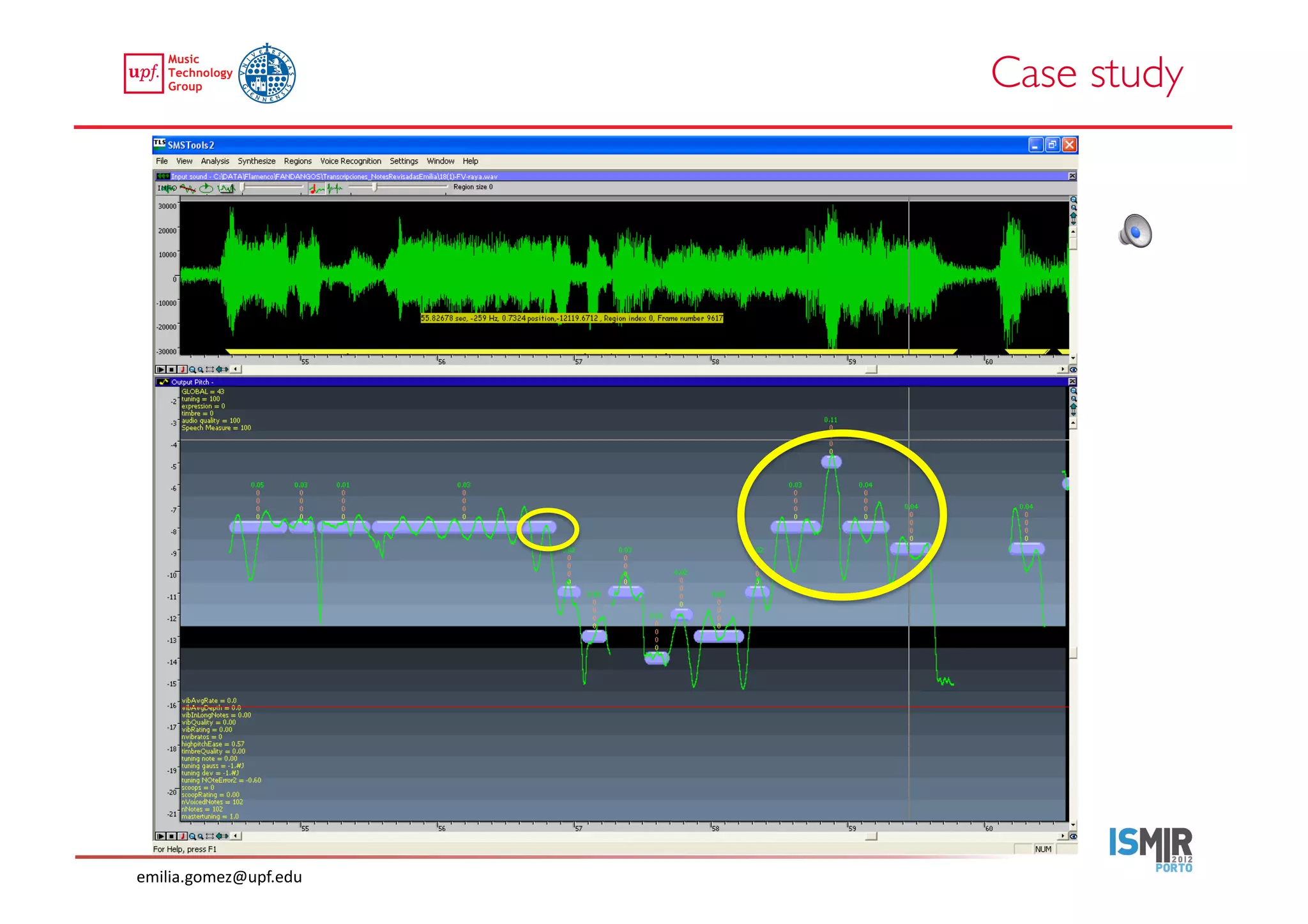
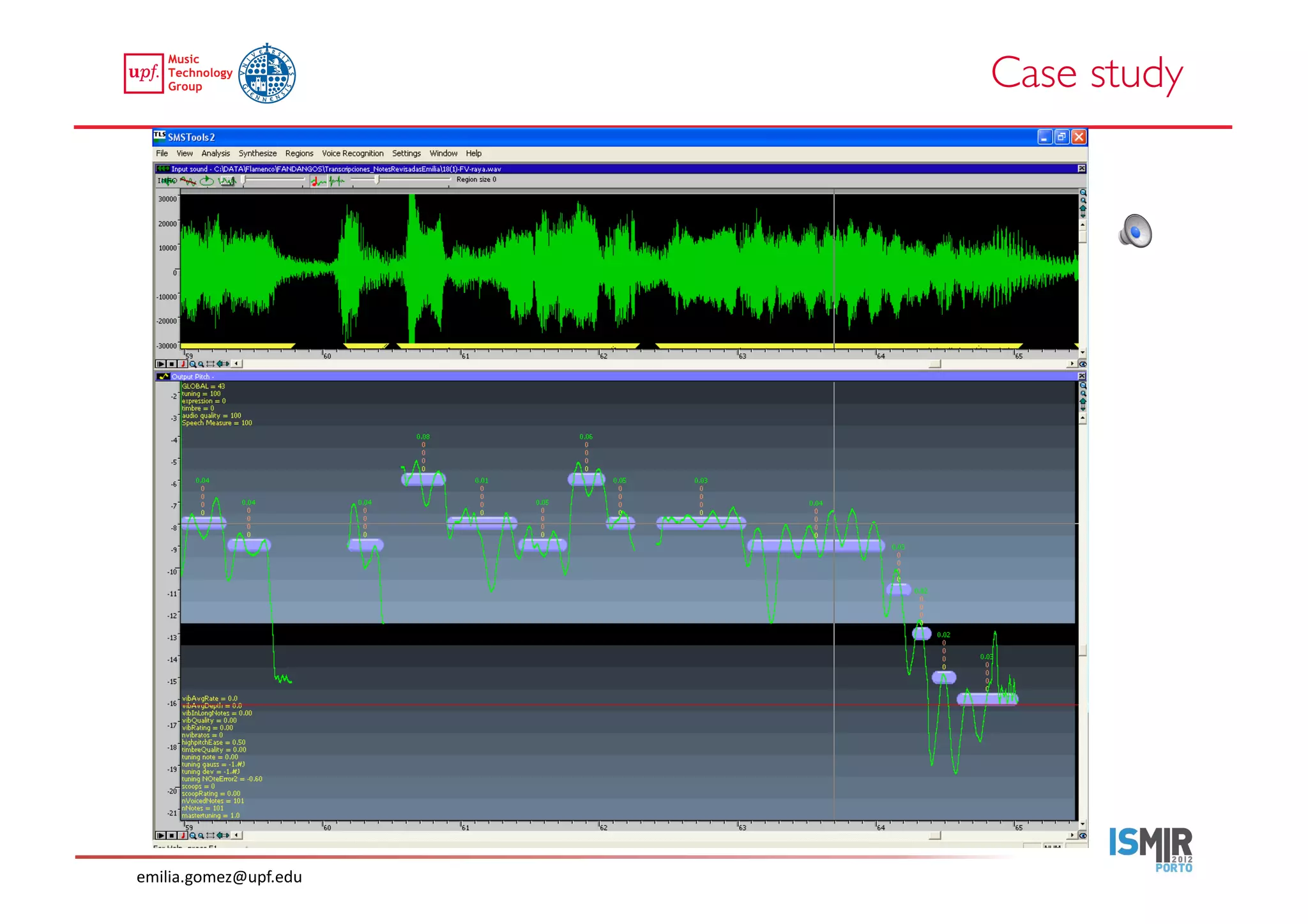
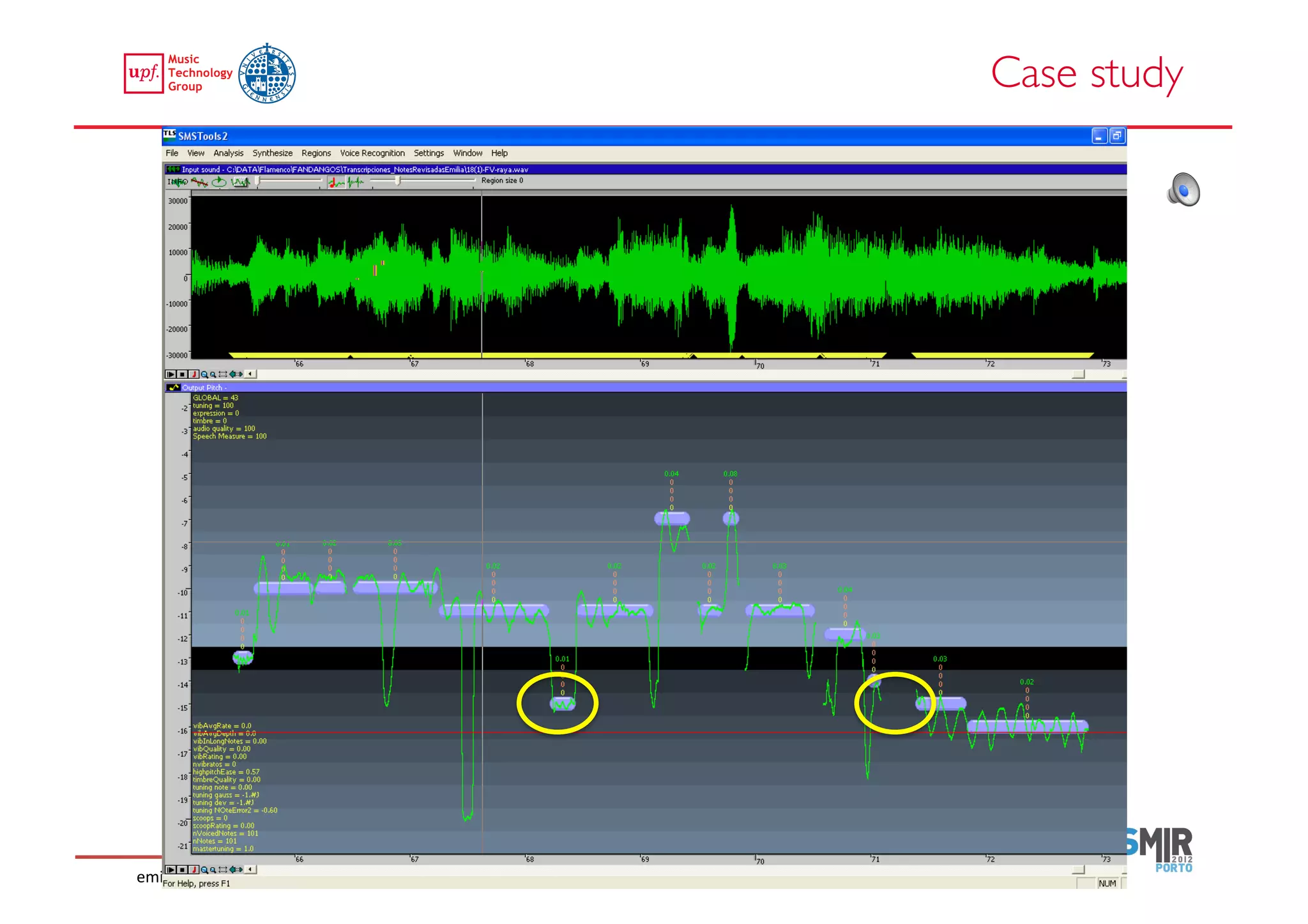


This document compares two approaches for the automatic transcription of accompanied flamenco singing: (1) a singing voice separation approach and (2) a predominant fundamental frequency estimation approach. Both approaches first estimate the singing voice fundamental frequency and then perform note segmentation and transcription. The separation-based approach uses non-negative matrix factorization to separate the singing voice from accompaniment. The predominant frequency estimation approach directly estimates the predominant pitch. Evaluation on 30 excerpts found both approaches achieved satisfying results, with the predominant frequency estimation approach performing slightly better with an accuracy of 84.68%. However, further improvements are still needed to better handle highly ornamented sections and accompanied passages.















![[Tutorial] Computational Approaches to Melodic Analysis of Indian Art Music](https://cdn.slidesharecdn.com/ss_thumbnails/tutorialmelodicanalysis-170910111235-thumbnail.jpg?width=640&height=640&fit=bounds)

























![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)





