




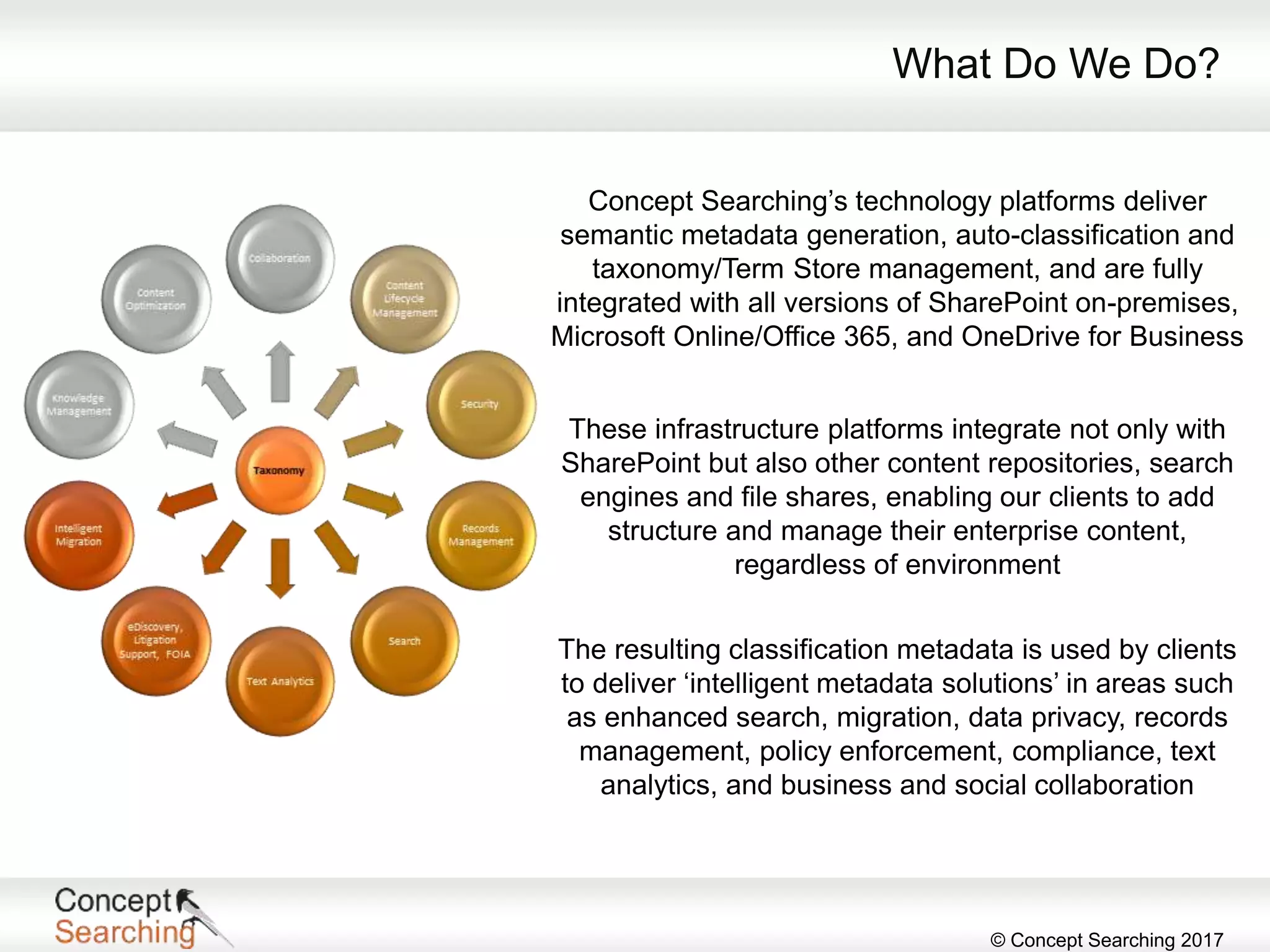
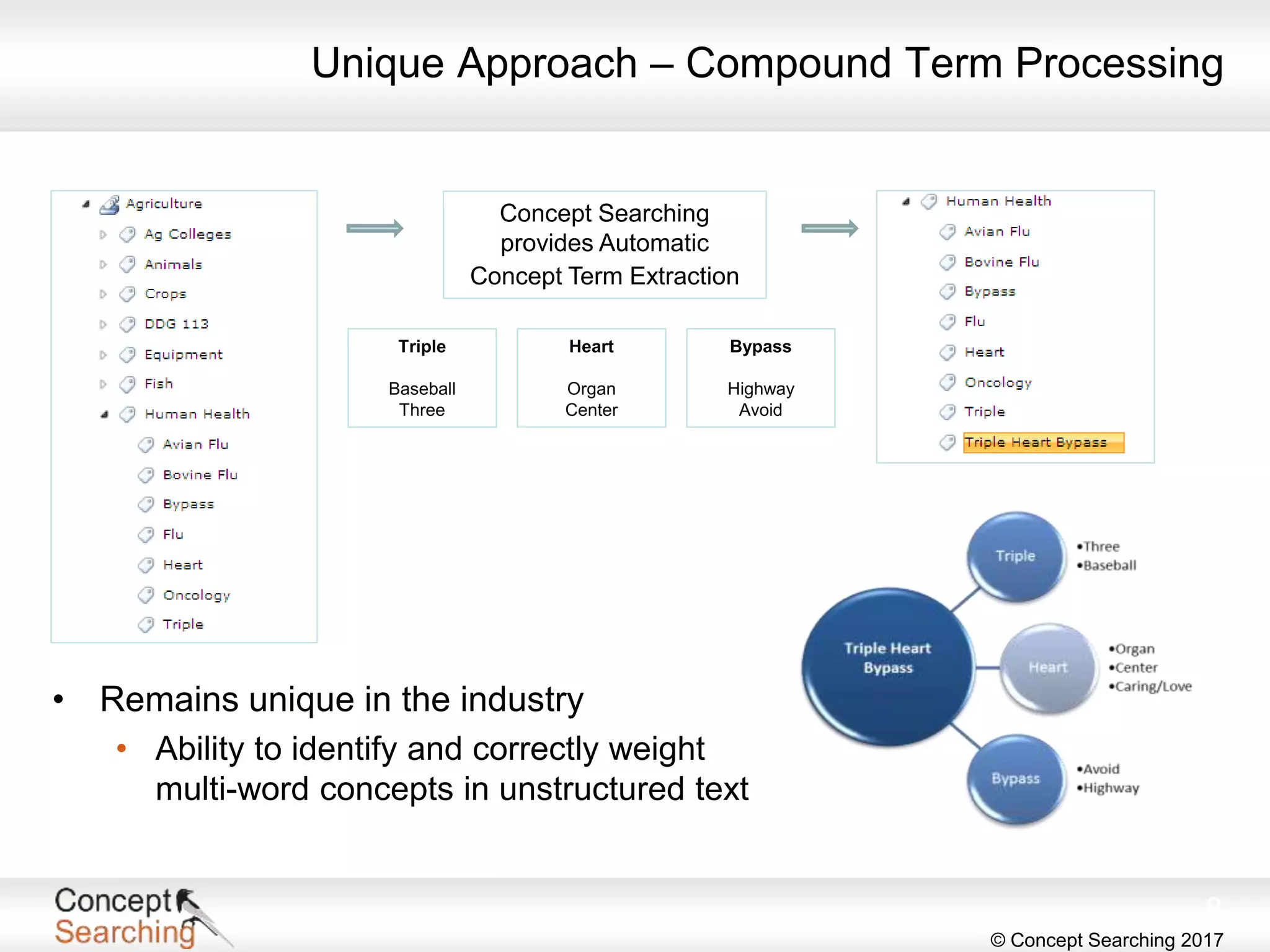
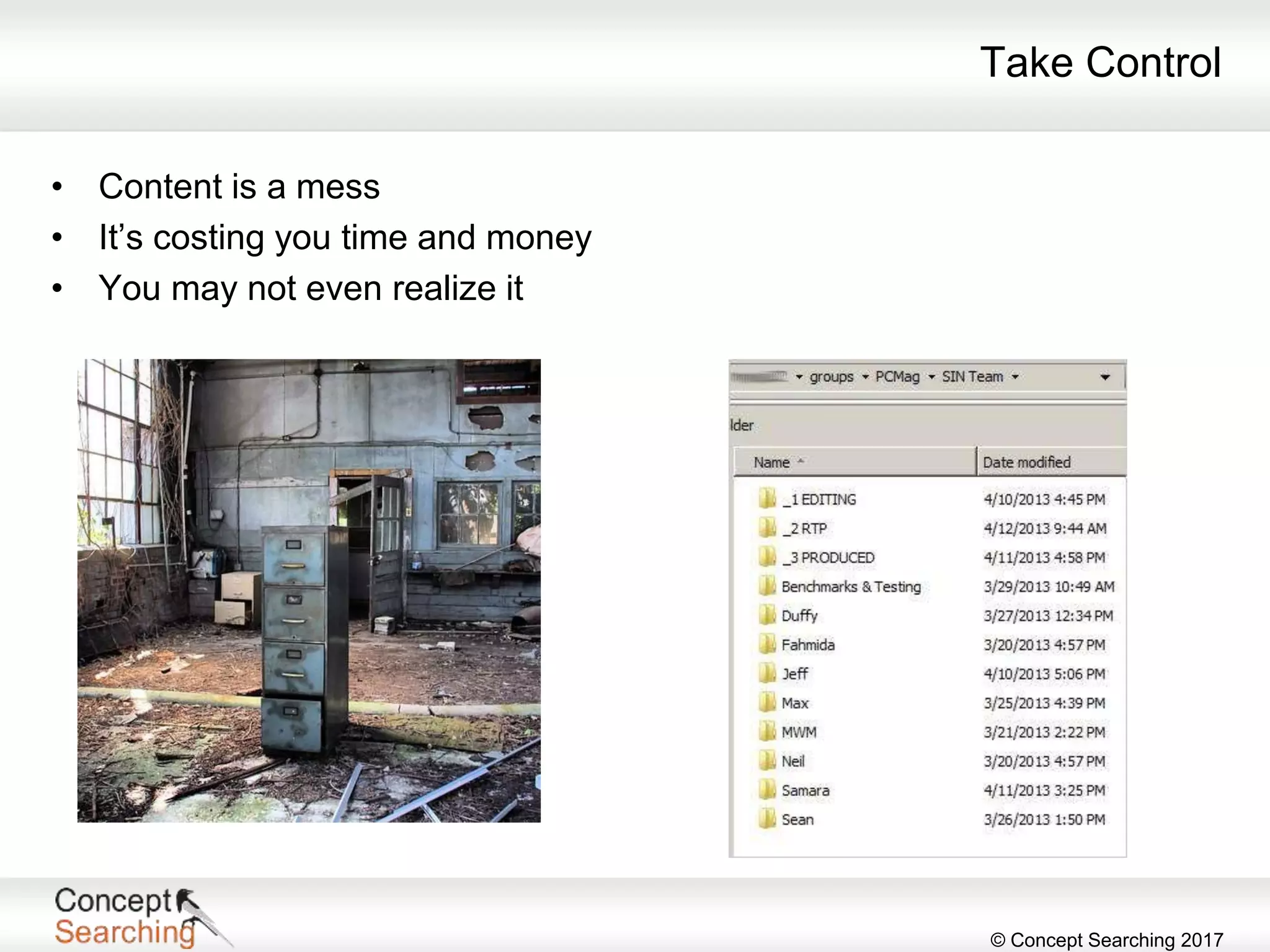






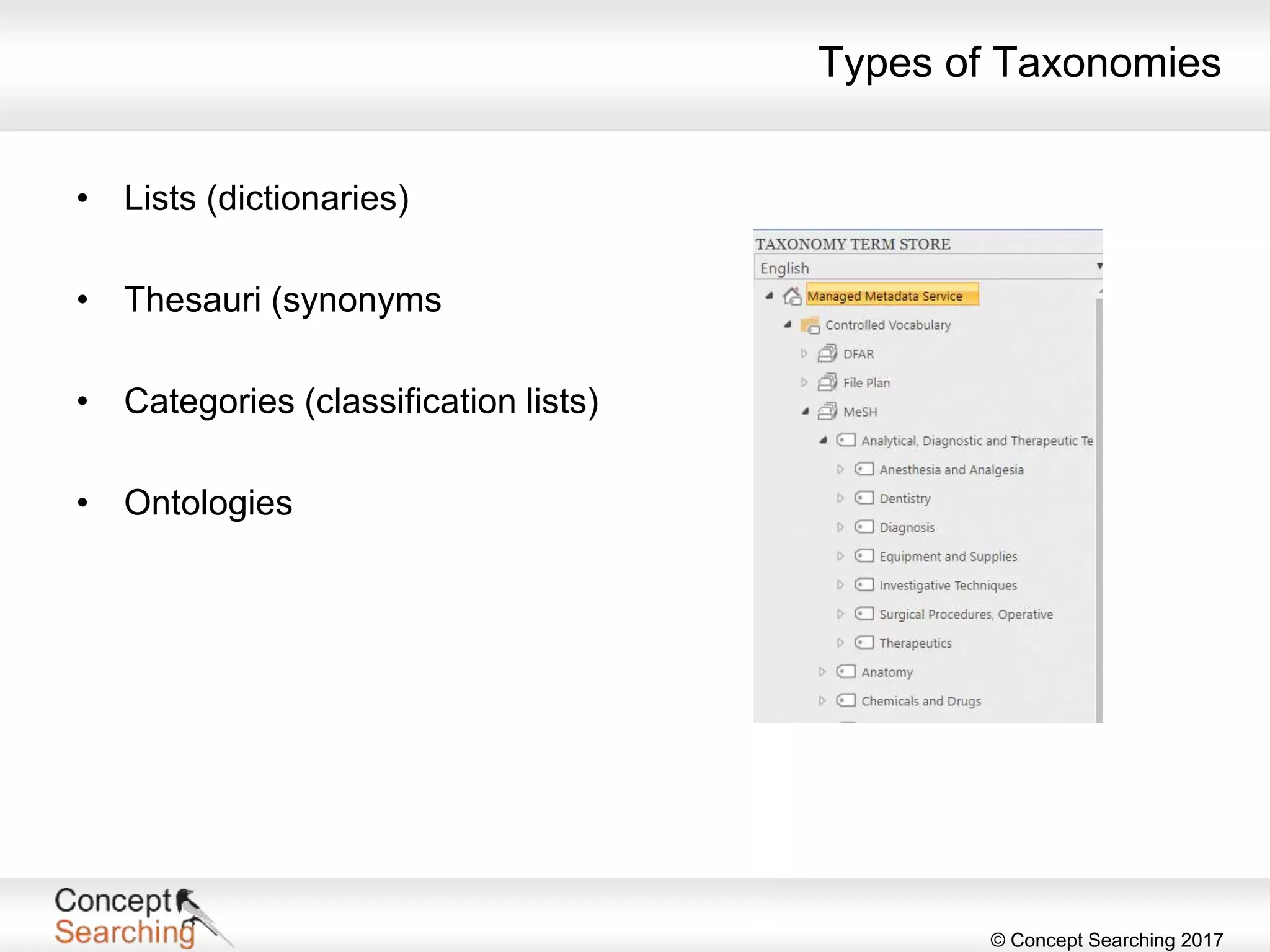

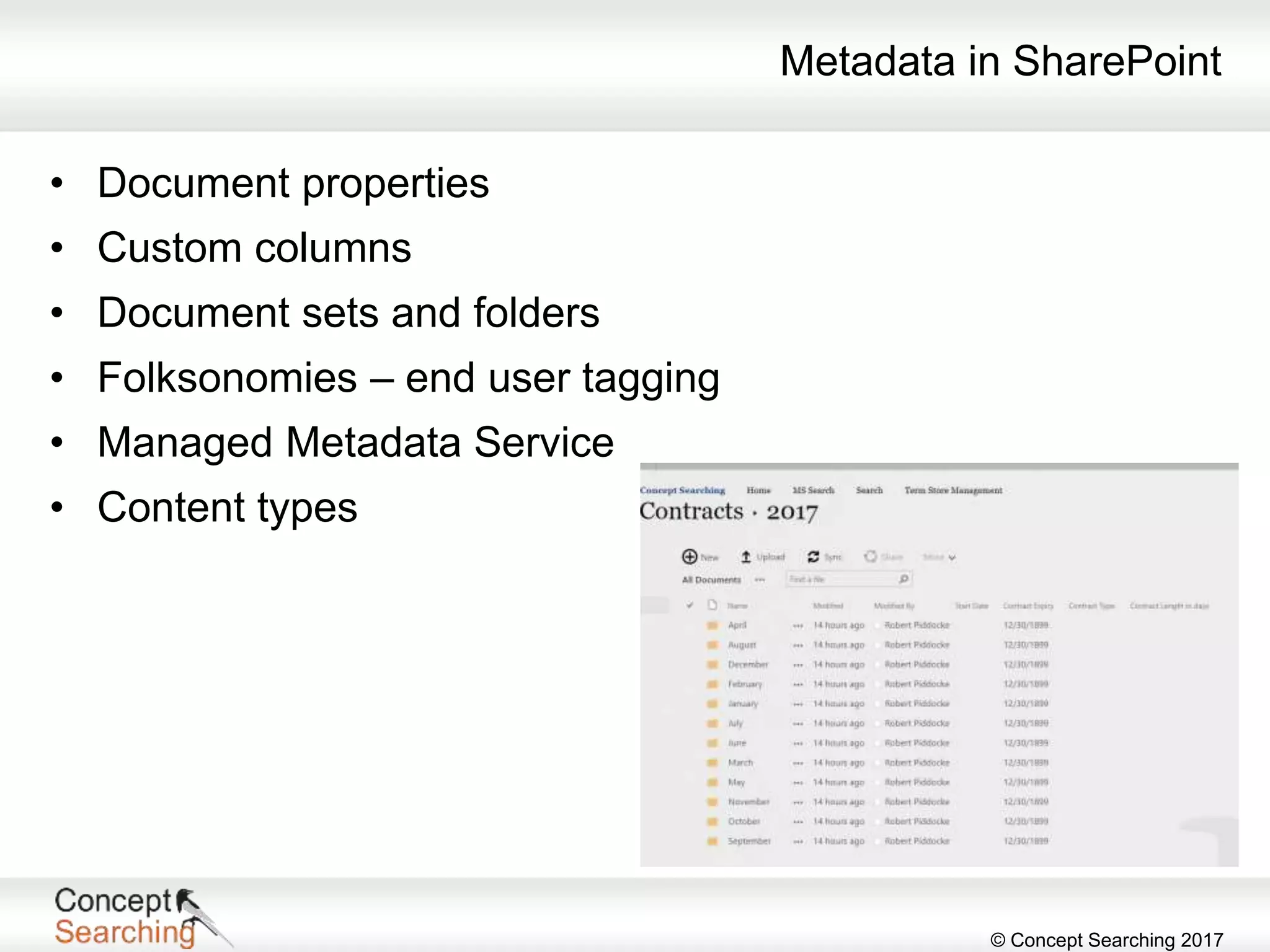

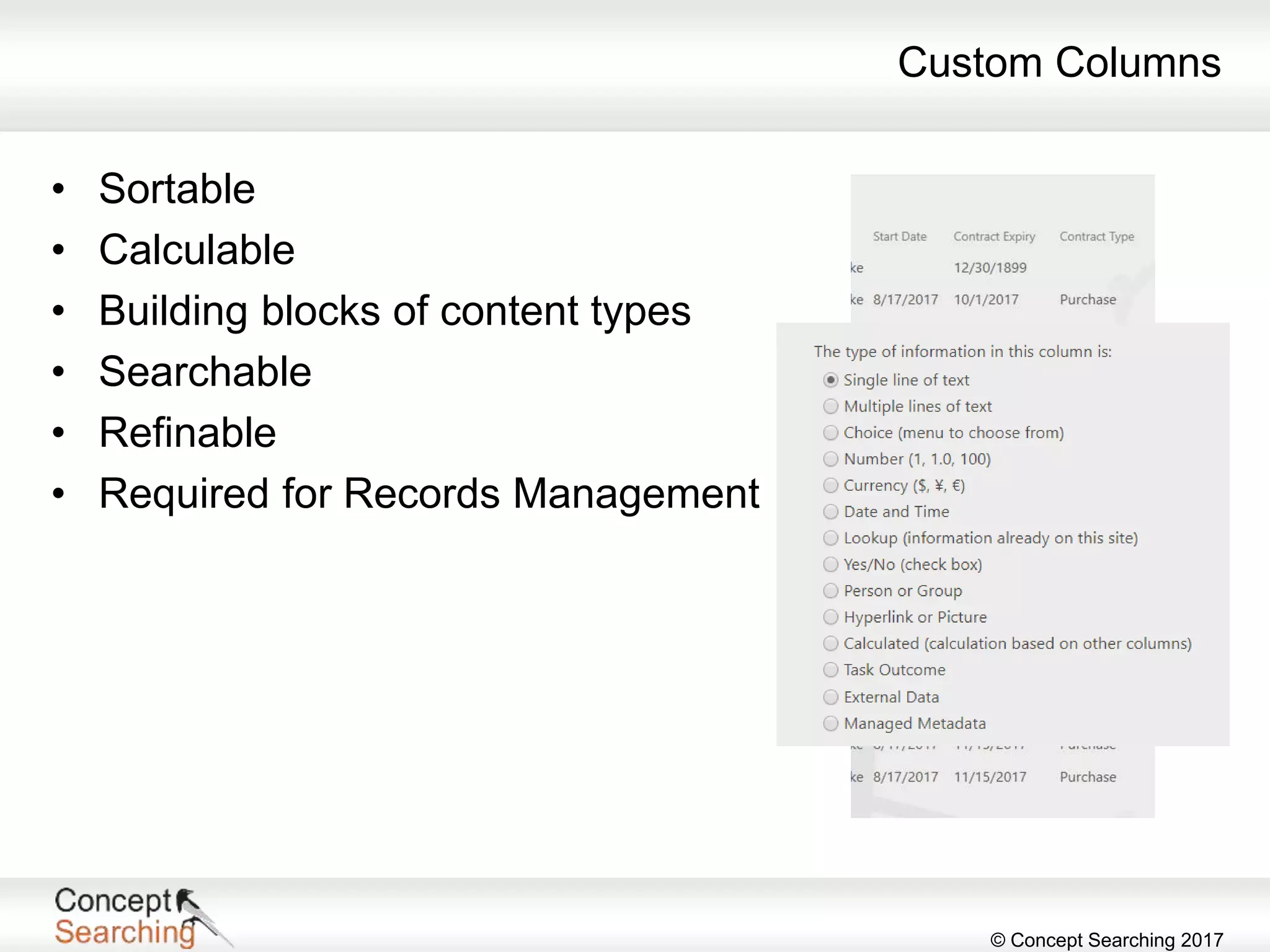






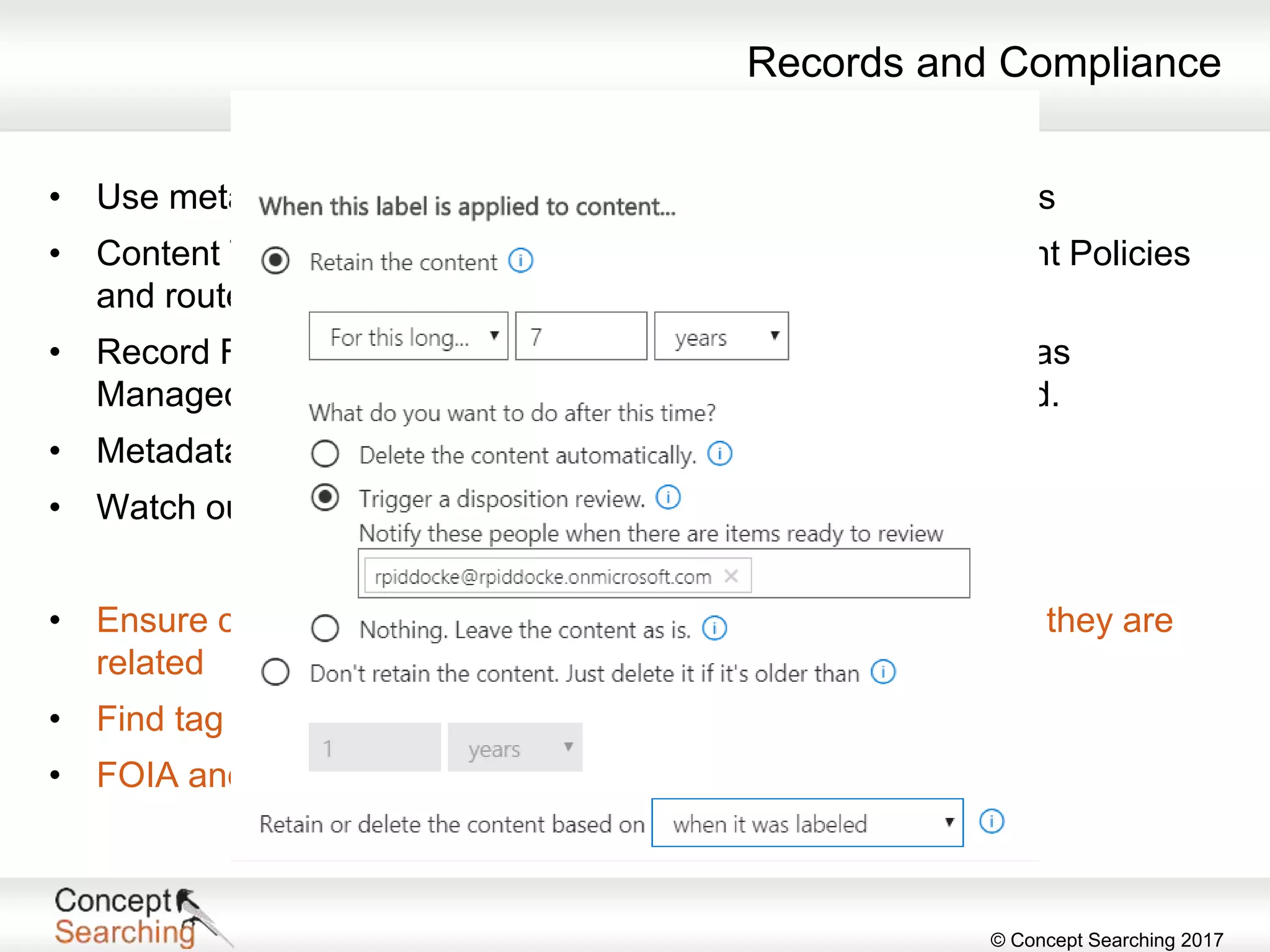
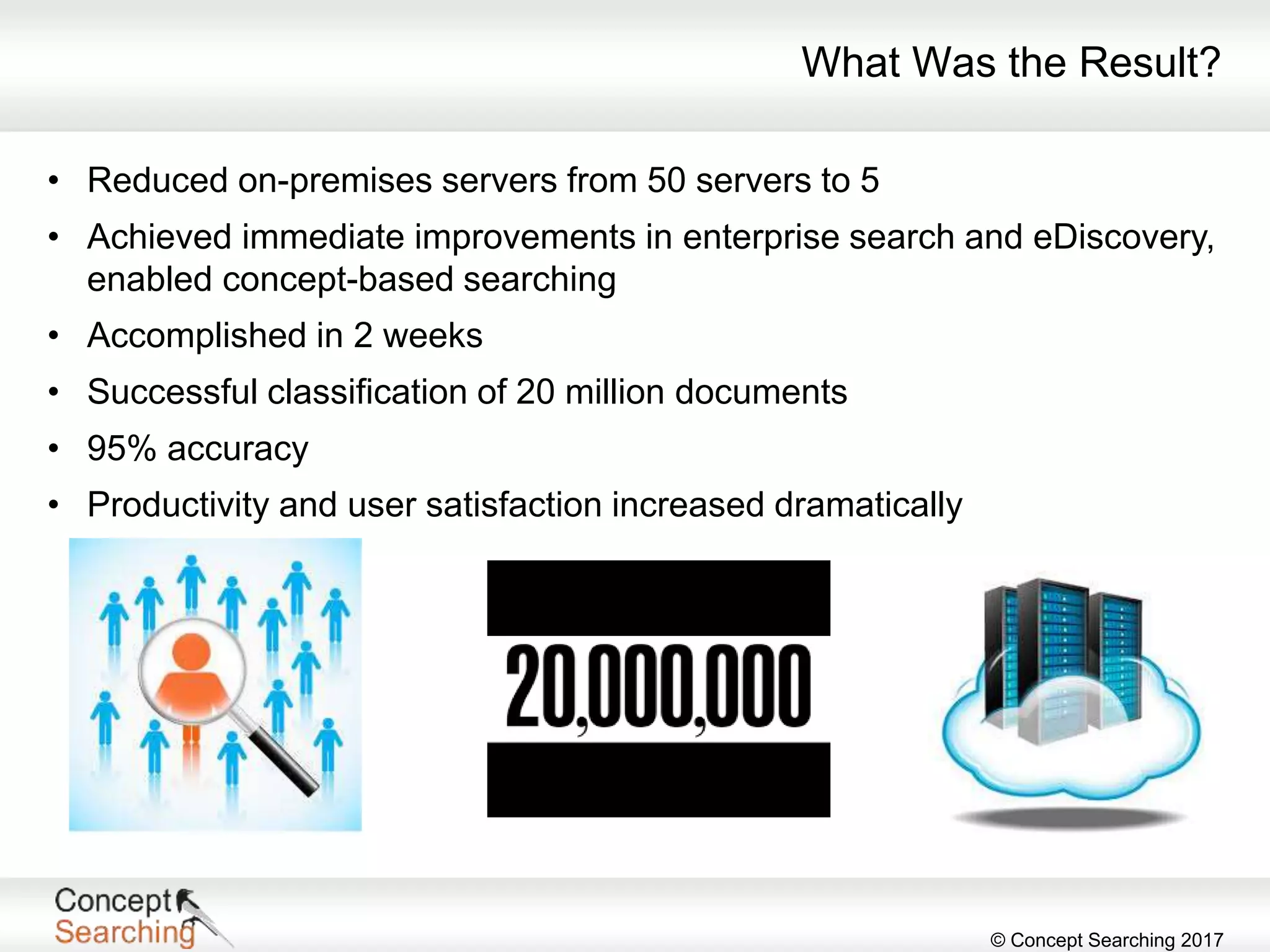



The document discusses the importance of metadata in SharePoint, highlighting its types, applications, and benefits for organizing and managing large amounts of unstructured data. It describes a case study of a global automotive organization that improved its search capabilities and reduced on-premises servers by implementing managed metadata solutions, leading to significant productivity gains. Key takeaways include the recommendation to use metadata over traditional folder structures and to leverage automation in tagging for governance and compliance.

















































































