行動決定テーブルを用いたマルチエージェントモデル
A
A
P1
A
B
P2
B
A
P3
B
B
P4
t-1
t-2
記憶長 m=2 の場合
t
行動決定テーブル
A
・・・
B
B
A
?
t-1
t-2
t
t-3
1
過去のゲームの履歴
各エージェントの行動でゲームをする
確率α
確率1-α
P3 ← P3
変更なし
報酬
行動決定テーブルの更新
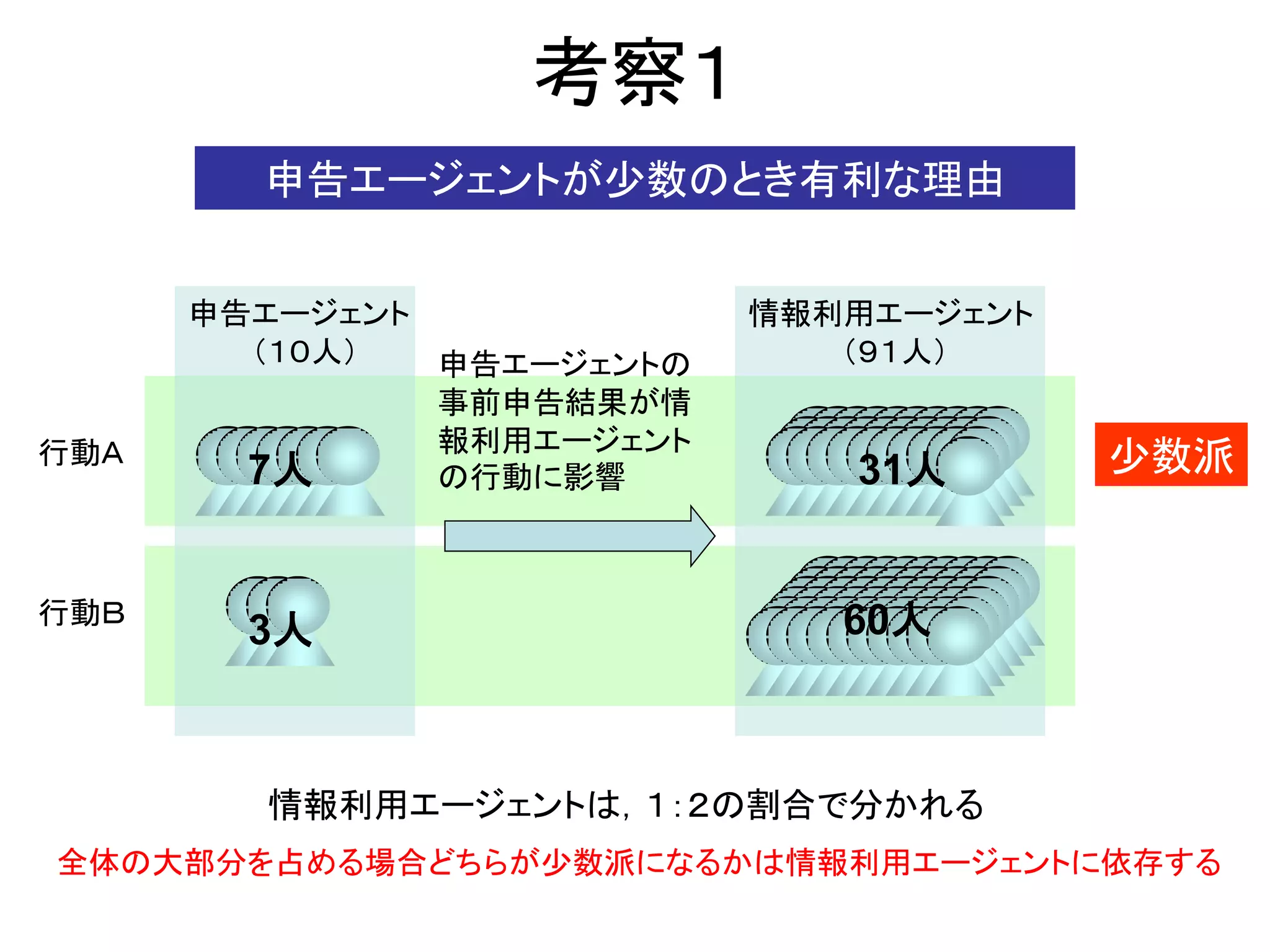
少数派
R
変更なし
多数派
無し
少数派だった行動
報酬の獲得,行動決定テーブルの更新
再びゲームをする
[和泉, et al., 04]
5.
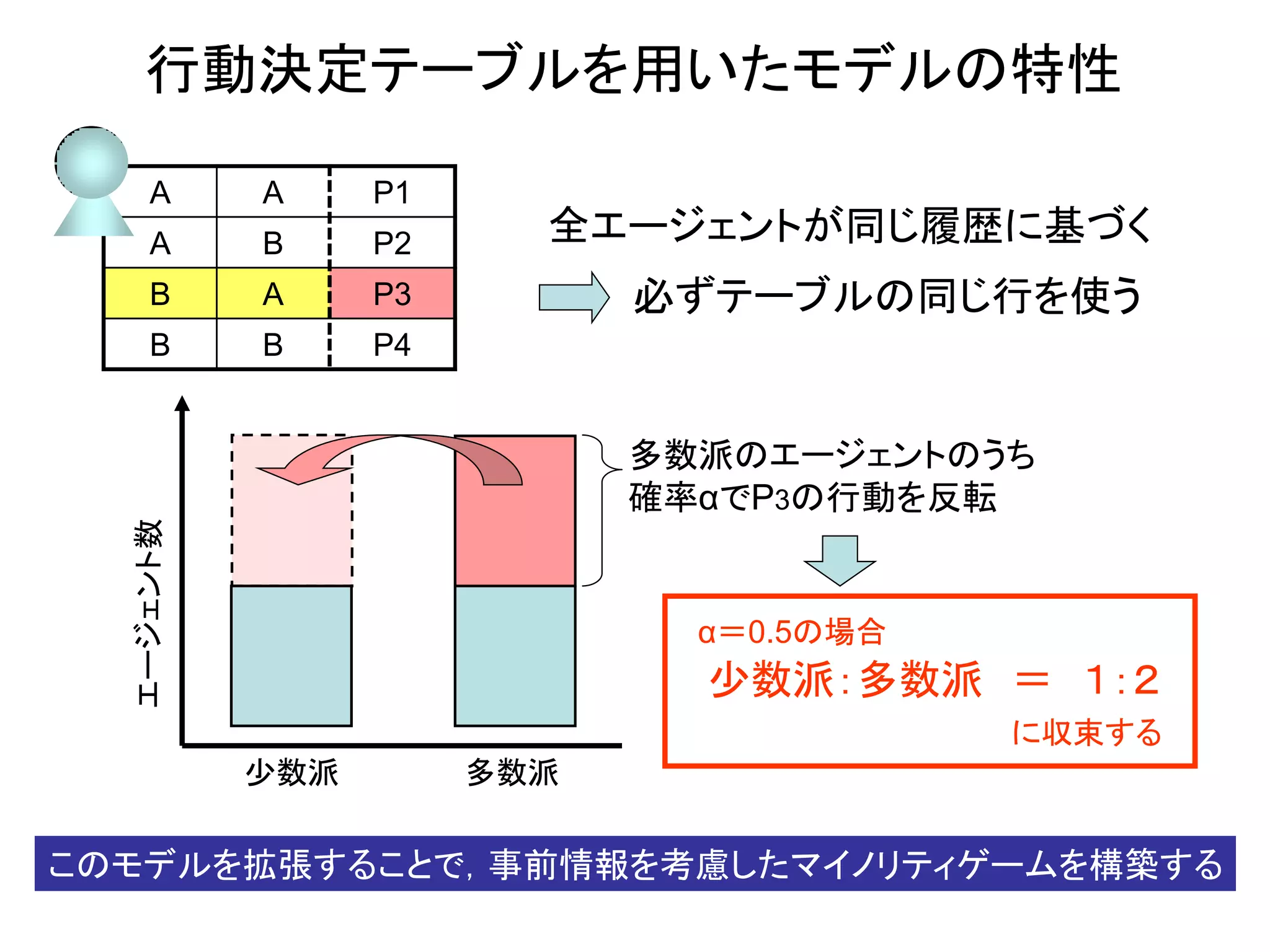
行動決定テーブルを用いたモデルの特性
A
A
P1
A
B
P2
B
A
P3
B
B
P4
全エージェントが同じ履歴に基づく
必ずテーブルの同じ行を使う
少数派
多数派
エージェント数
多数派のエージェントのうち
確率αでP3の行動を反転
少数派:多数派 = 1:2
α=0.5の場合
に収束する
このモデルを拡張することで,事前情報を考慮したマイノリティゲームを構築する
6.
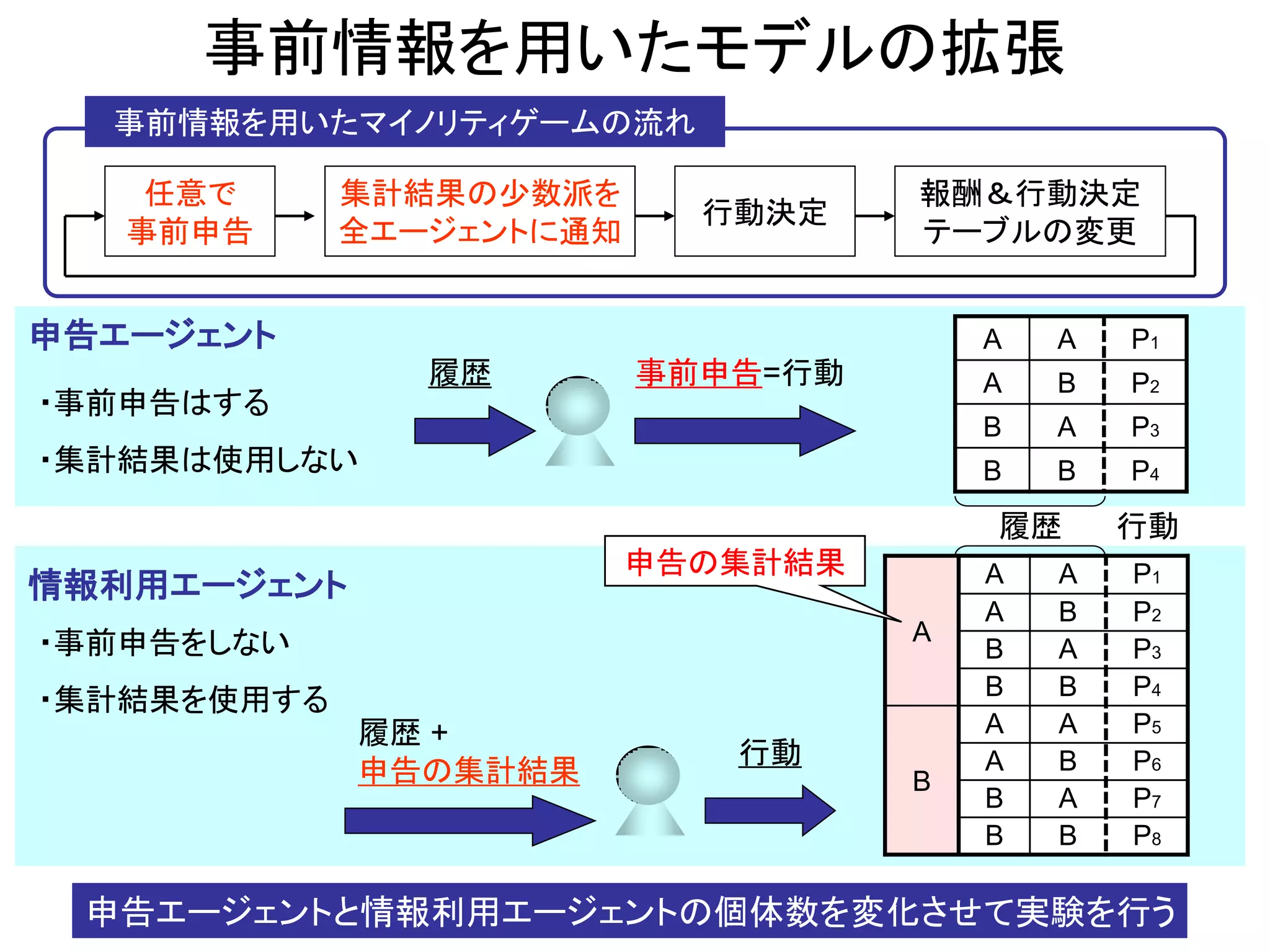
事前情報を用いたモデルの拡張
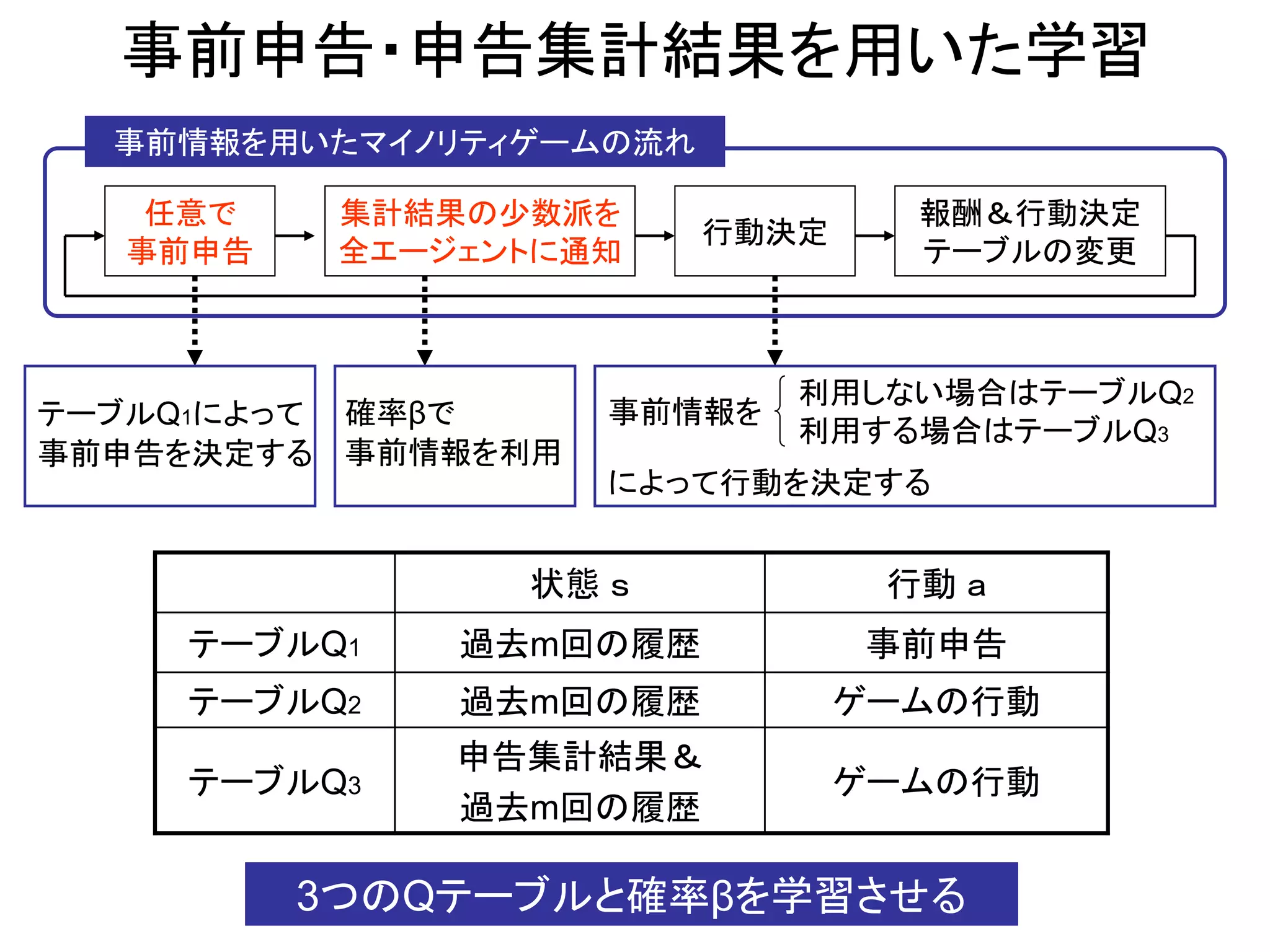
任意で
事前申告
行動決定
報酬&行動決定
テーブルの変更
履歴
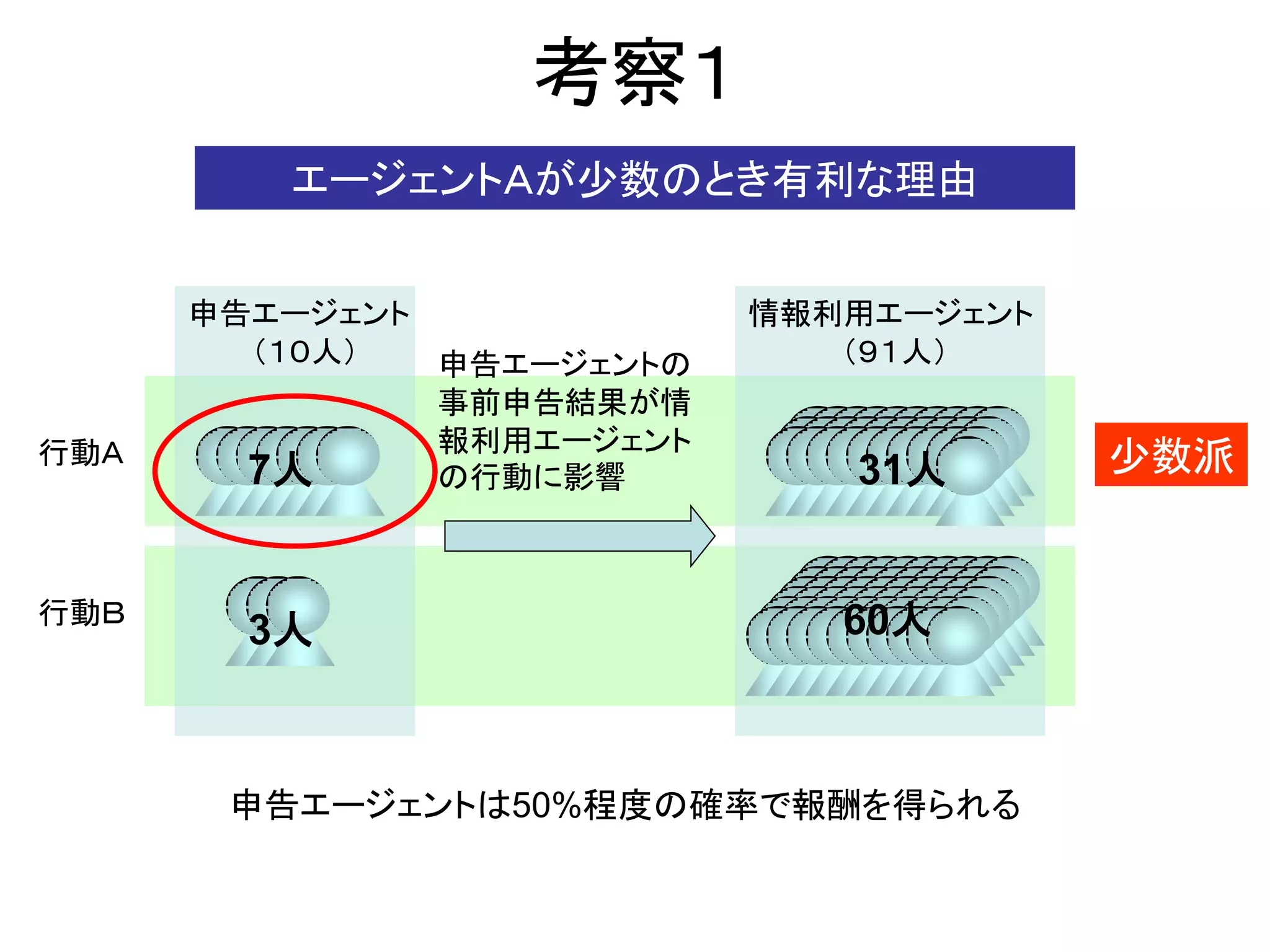
事前申告=行動
申告エージェント
情報利用エージェント
履歴 + 申告の集計結果
行動
履歴
行動
・事前申告はする
・集計結果は使用しない
・事前申告をしない
・集計結果を使用する
事前情報を用いたマイノリティゲームの流れ
集計結果の少数派を
全エージェントに通知
A
A
P1
A
B
P2
B
A
P3
B
B
P4
A
A
A
P1
A
B
P2
B
A
P3
B
B
P4
B
A
A
P5
A
B
P6
B
A
P7
B
B
P8
申告の集計結果
申告エージェントと情報利用エージェントの個体数を変化させて実験を行う
Qテーブルとβの学習方法
Q学習:利用した行動価値関数を更新
(, ) ( , ) [ max ( , ) ( , )] 1 t 1 t 1 t t
a
t t t t t Q s a Q s a reward Q s a Q s a α
行動価値関数
申告集計結果の利用率β
if
if
0.05
0.05
申告集計結果を 利用して成功 or 利用しないで失敗
申告集計結果を 利用して失敗 or 利用しないで成功
Q学習の学習率
割引率
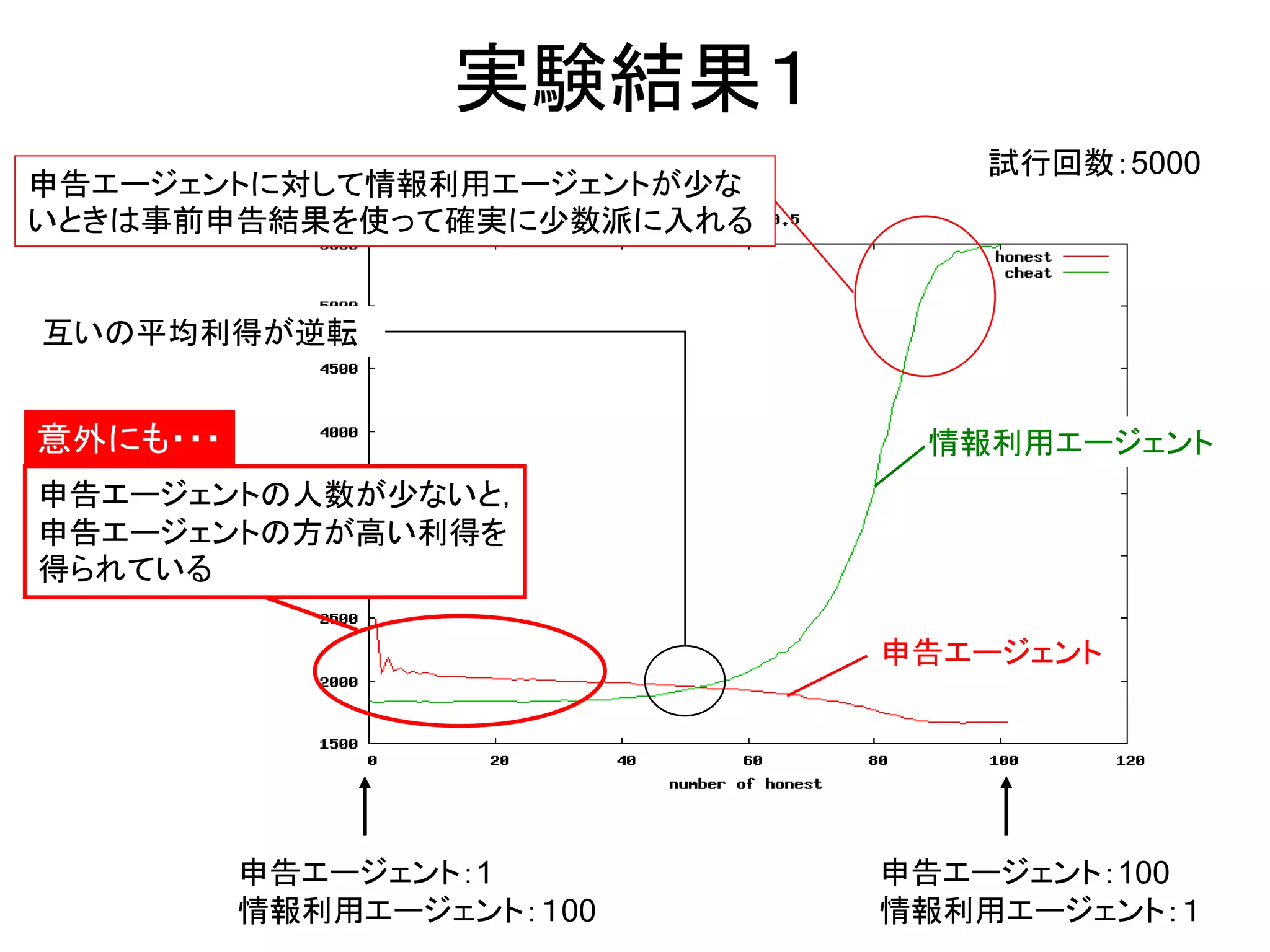
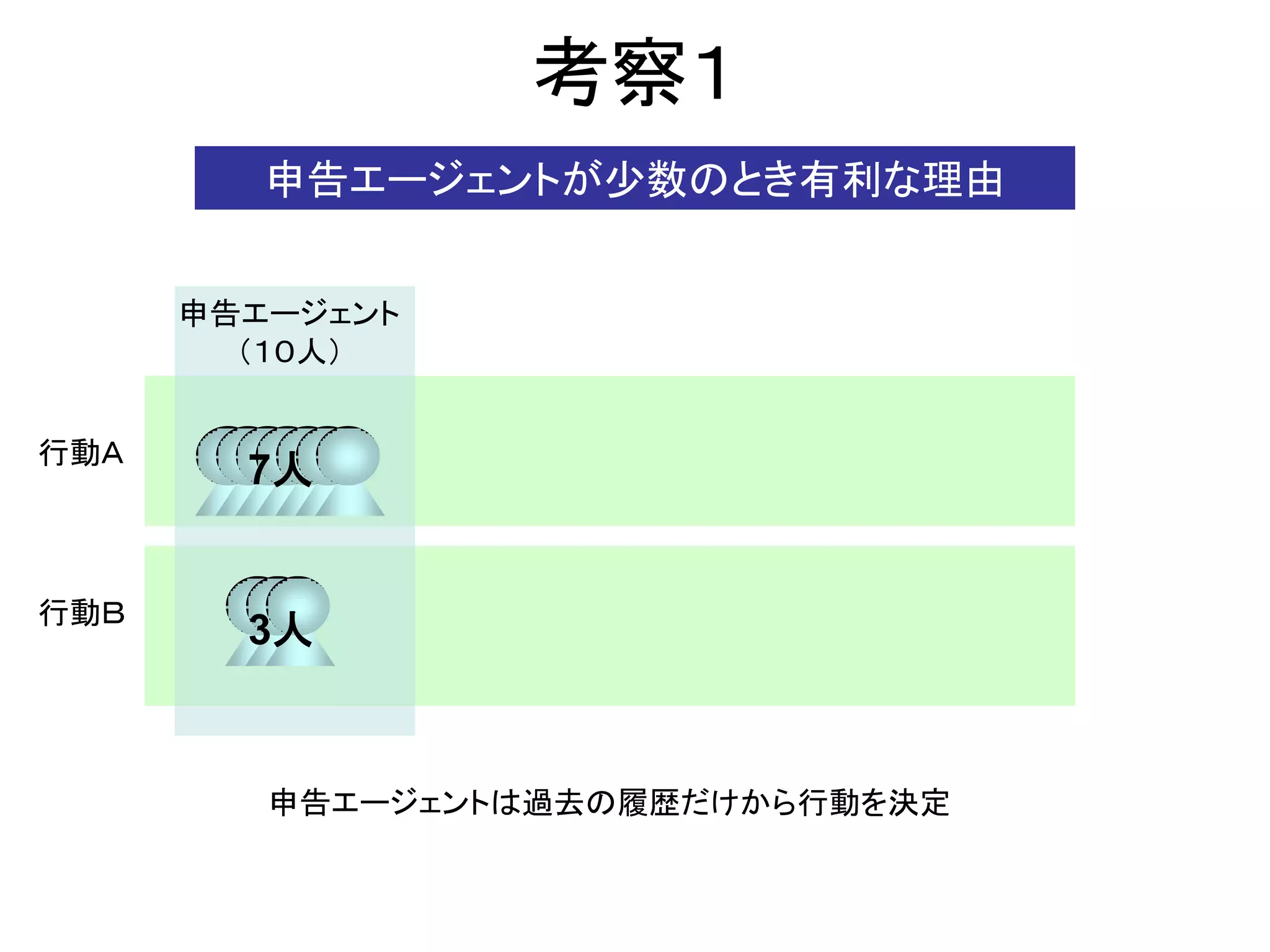
実験設定
実験設定
α=0.1
γ=0.0
βの初期値=1.0


![事前情報を含んだマイノリティゲームの提案
事前情報が行動に与える影響の分析
複雑系の側面をもつ株式市場をモデル化したマイノリティゲームを用いて,
事前情報が戦略の異なる複数の利己的エージェントの行動に与える影響を解析する
目的
現実にはうわさ,予想などの事前情報も考えて行動する
マイノリティゲームに関する先行研究
•StandardMGの研究(C-.Zhang 1997)
•人工市場のシンプルなモデルとしてのマイノリティゲーム
•進化的アルゴリズムは人工市場にふさわしいか[和泉 2004]
•エージェントの学習に「進化的アルゴリズム」を用いた研究
従来のMGではエージェントの行動はゲームの履歴だけで決定](https://image.slidesharecdn.com/godo-141008061325-conversion-gate02/75/godo-b-3-2048.jpg)
![行動決定テーブルを用いたマルチエージェントモデル
A
A
P1
A
B
P2
B
A
P3
B
B
P4
t-1
t-2
記憶長 m=2 の場合
t
行動決定テーブル
A
・・・
B
B
A
?
t-1
t-2
t
t-3
1
過去のゲームの履歴
各エージェントの行動でゲームをする
確率α
確率1-α
P3 ← P3
変更なし
報酬
行動決定テーブルの更新
少数派
R
変更なし
多数派
無し
少数派だった行動
報酬の獲得,行動決定テーブルの更新
再びゲームをする
[和泉, et al., 04]](https://image.slidesharecdn.com/godo-141008061325-conversion-gate02/75/godo-b-4-2048.jpg)

![Qテーブルとβの学習方法
Q学習:利用した行動価値関数を更新
( , ) ( , ) [ max ( , ) ( , )] 1 t 1 t 1 t t
a
t t t t t Q s a Q s a reward Q s a Q s a α
行動価値関数
申告集計結果の利用率β
if
if
0.05
0.05
申告集計結果を 利用して成功 or 利用しないで失敗
申告集計結果を 利用して失敗 or 利用しないで成功
Q学習の学習率
割引率
実験設定
実験設定
α=0.1
γ=0.0
βの初期値=1.0](https://image.slidesharecdn.com/godo-141008061325-conversion-gate02/75/godo-b-13-2048.jpg)


















![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)























