Downloaded 68 times



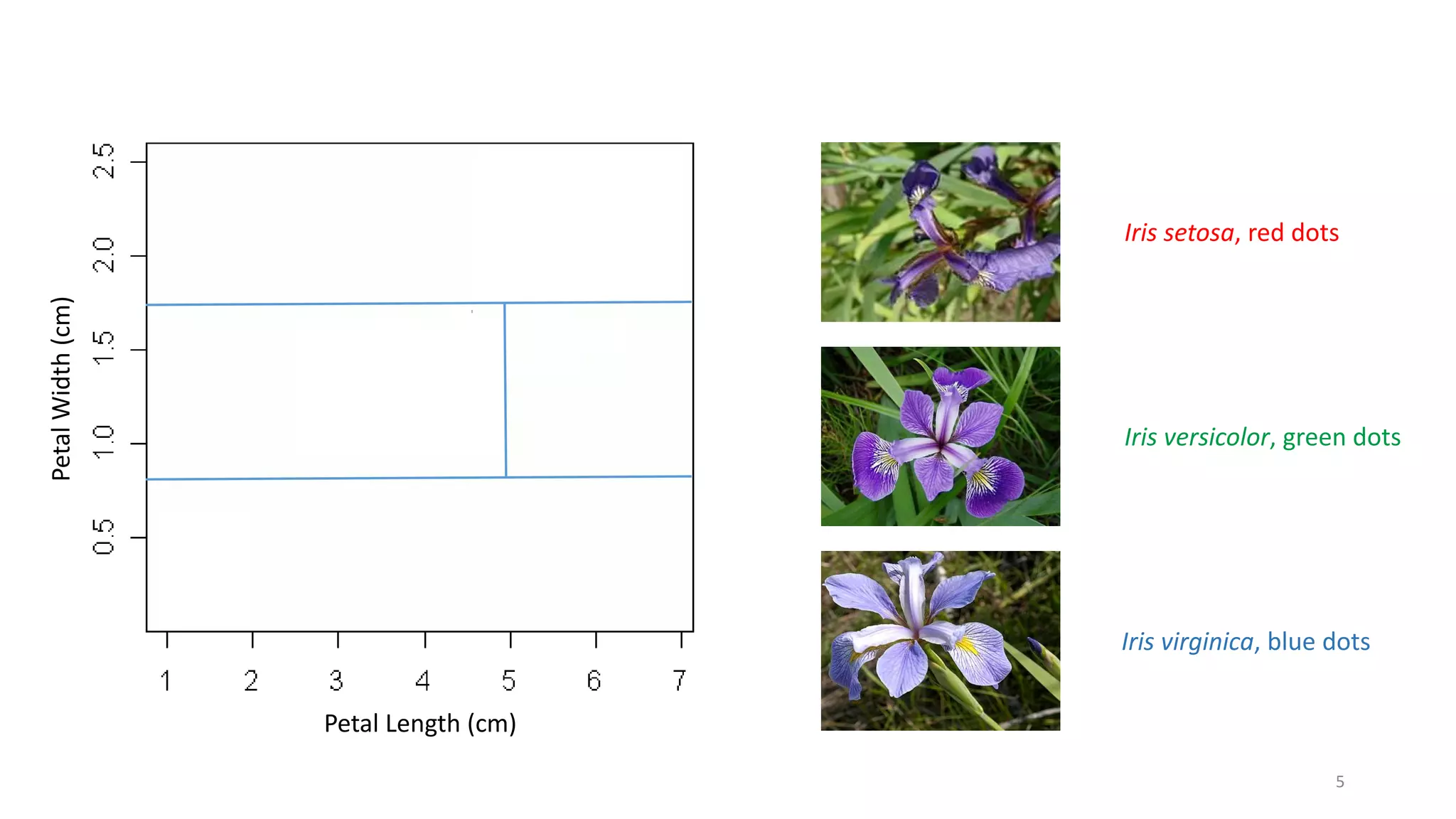
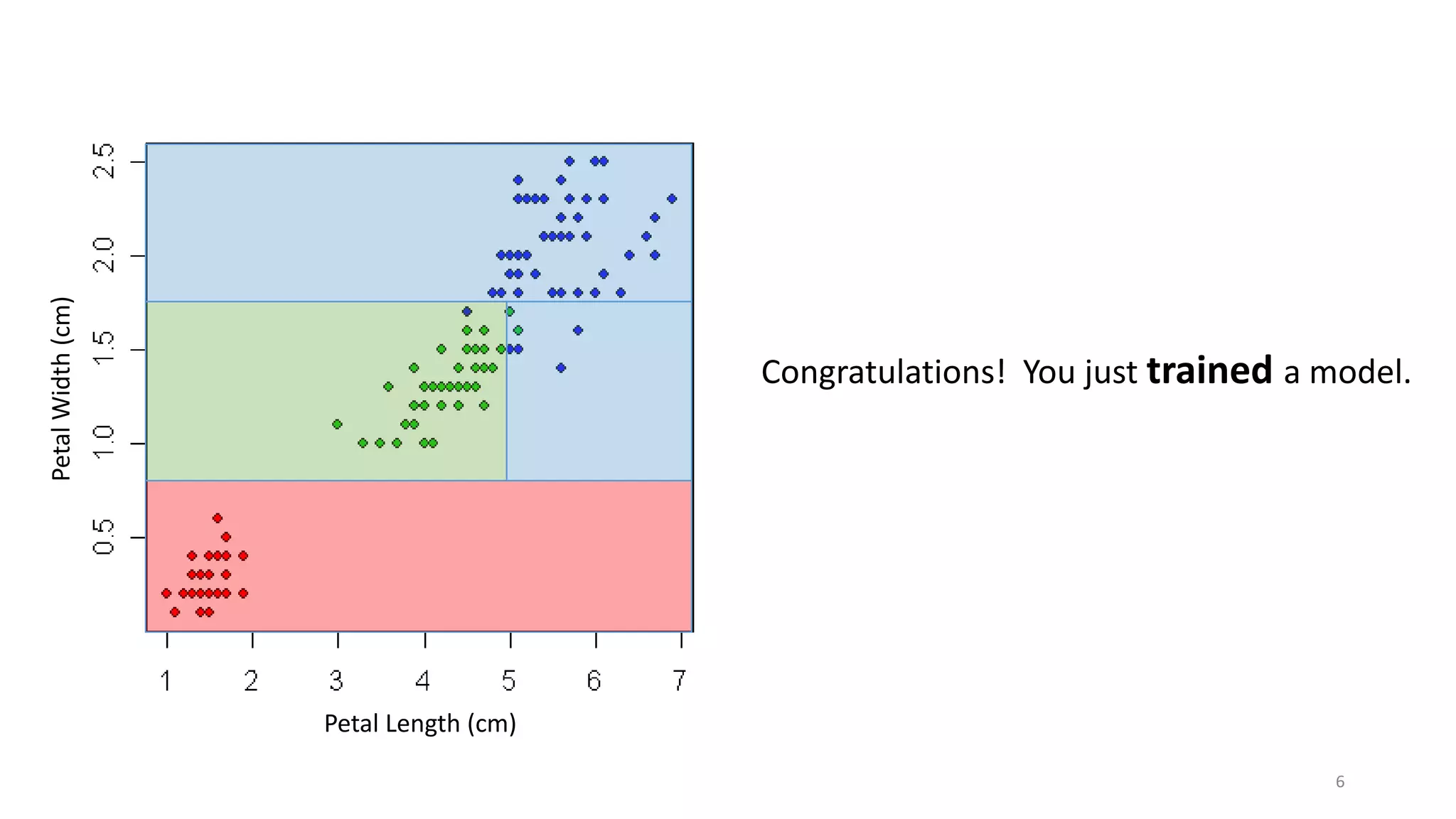
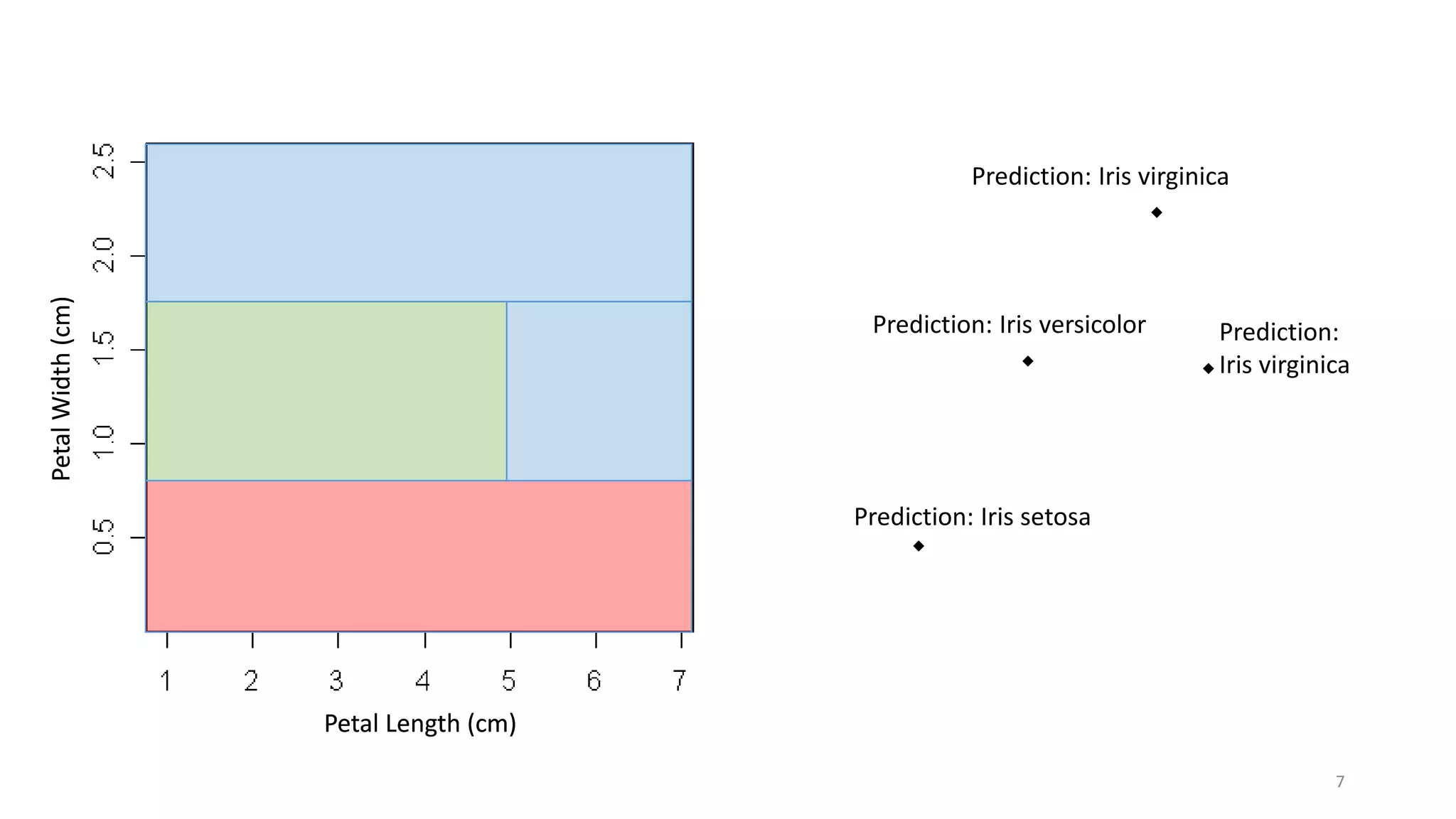
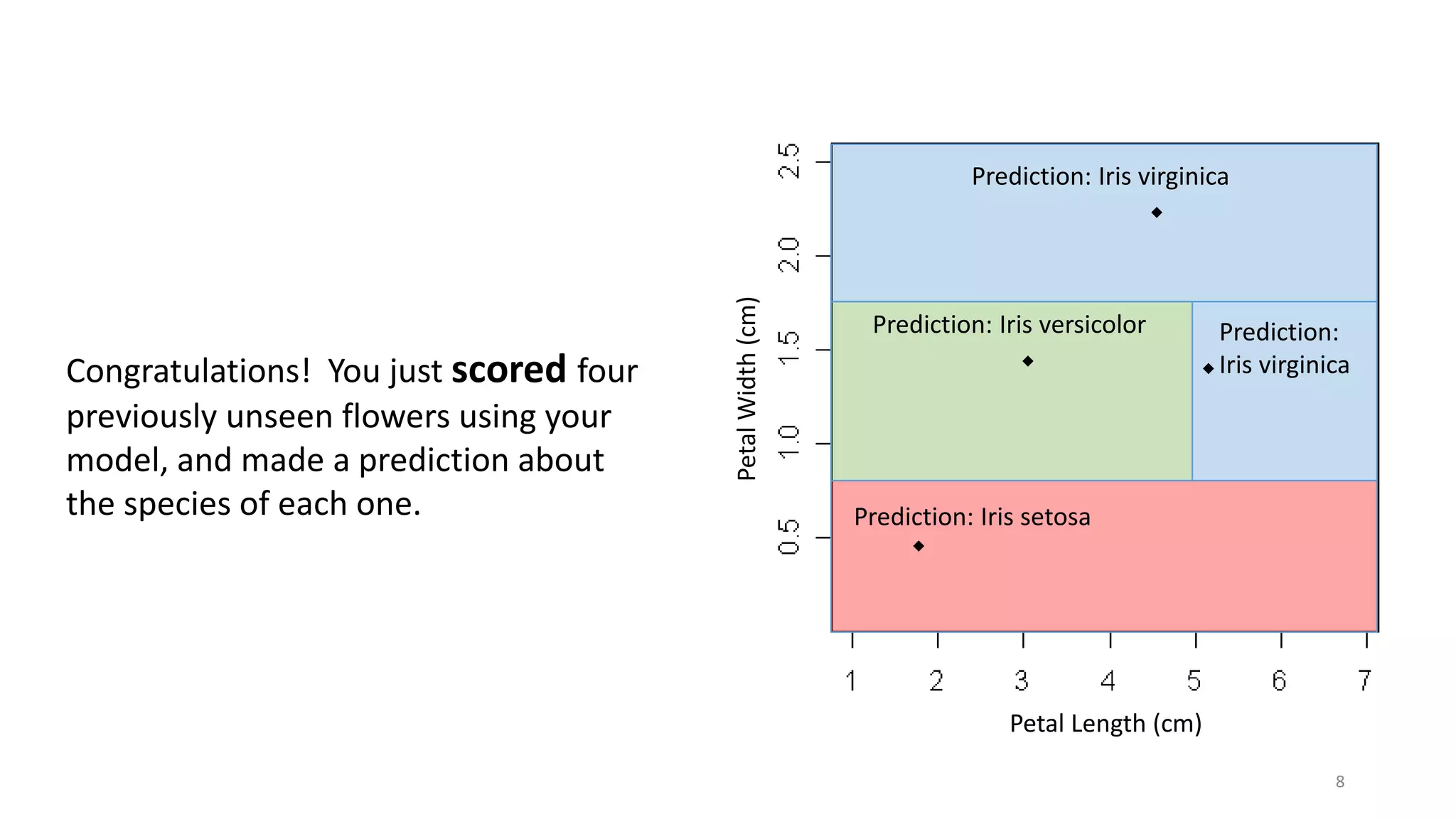
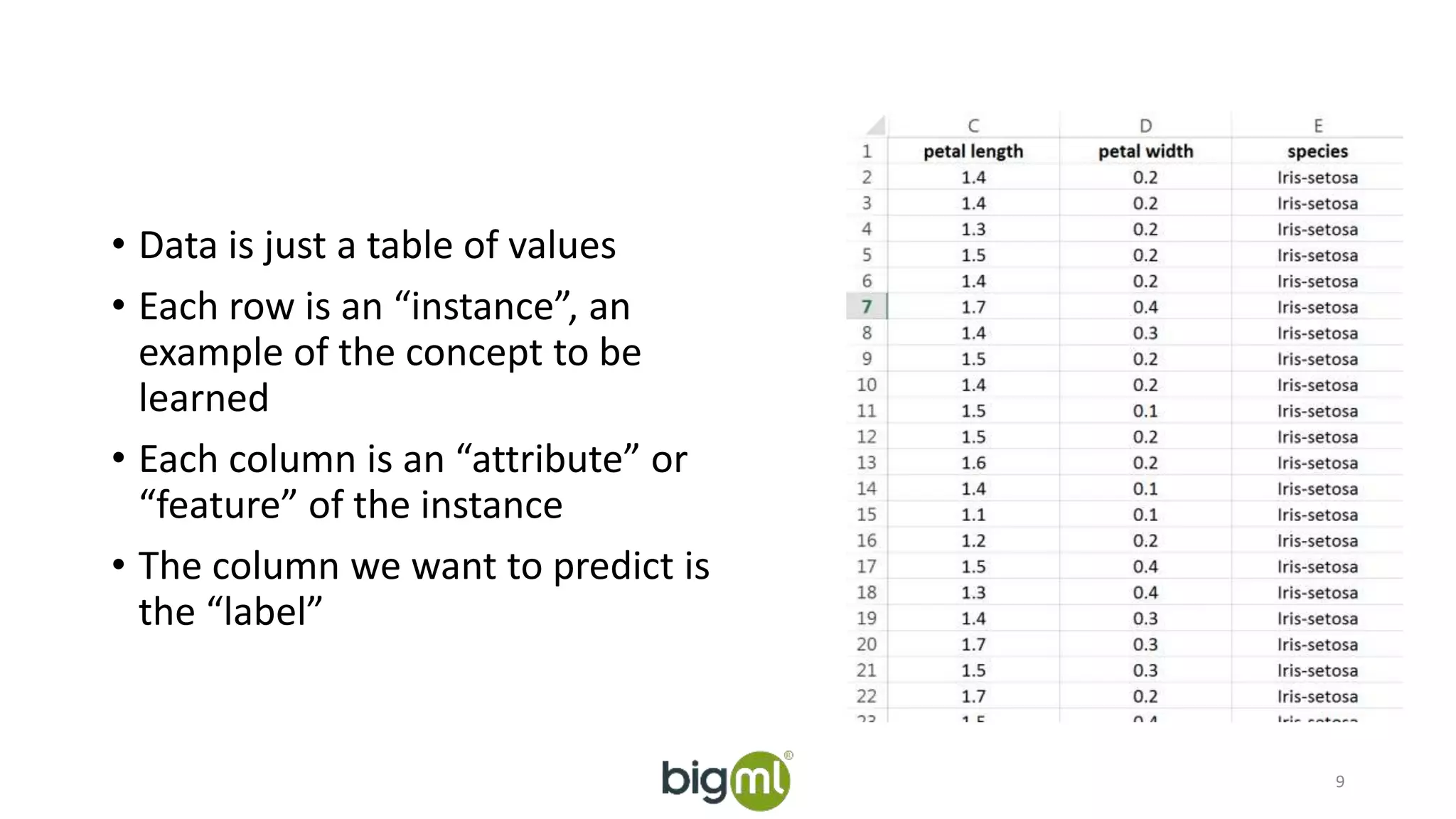
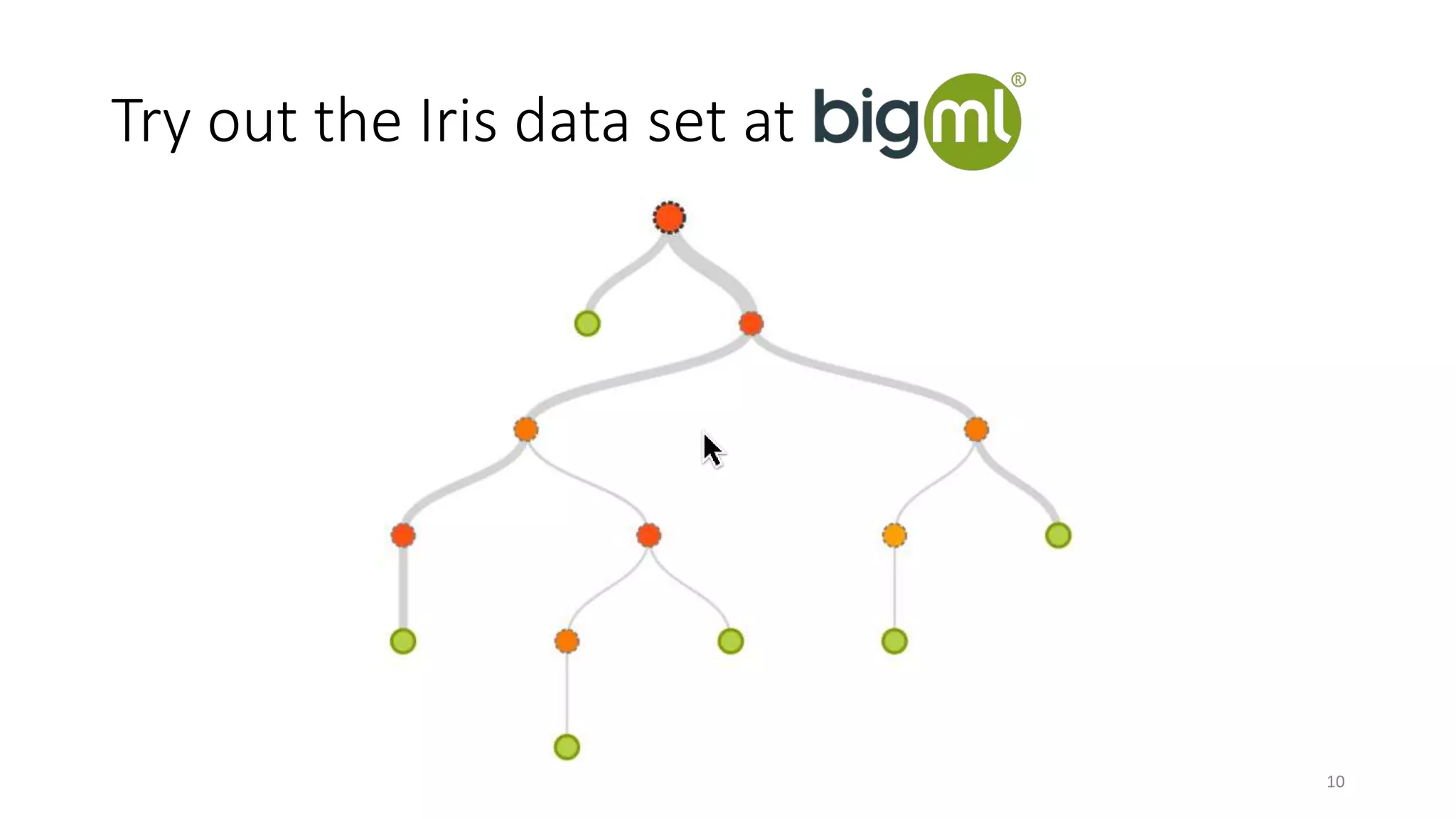
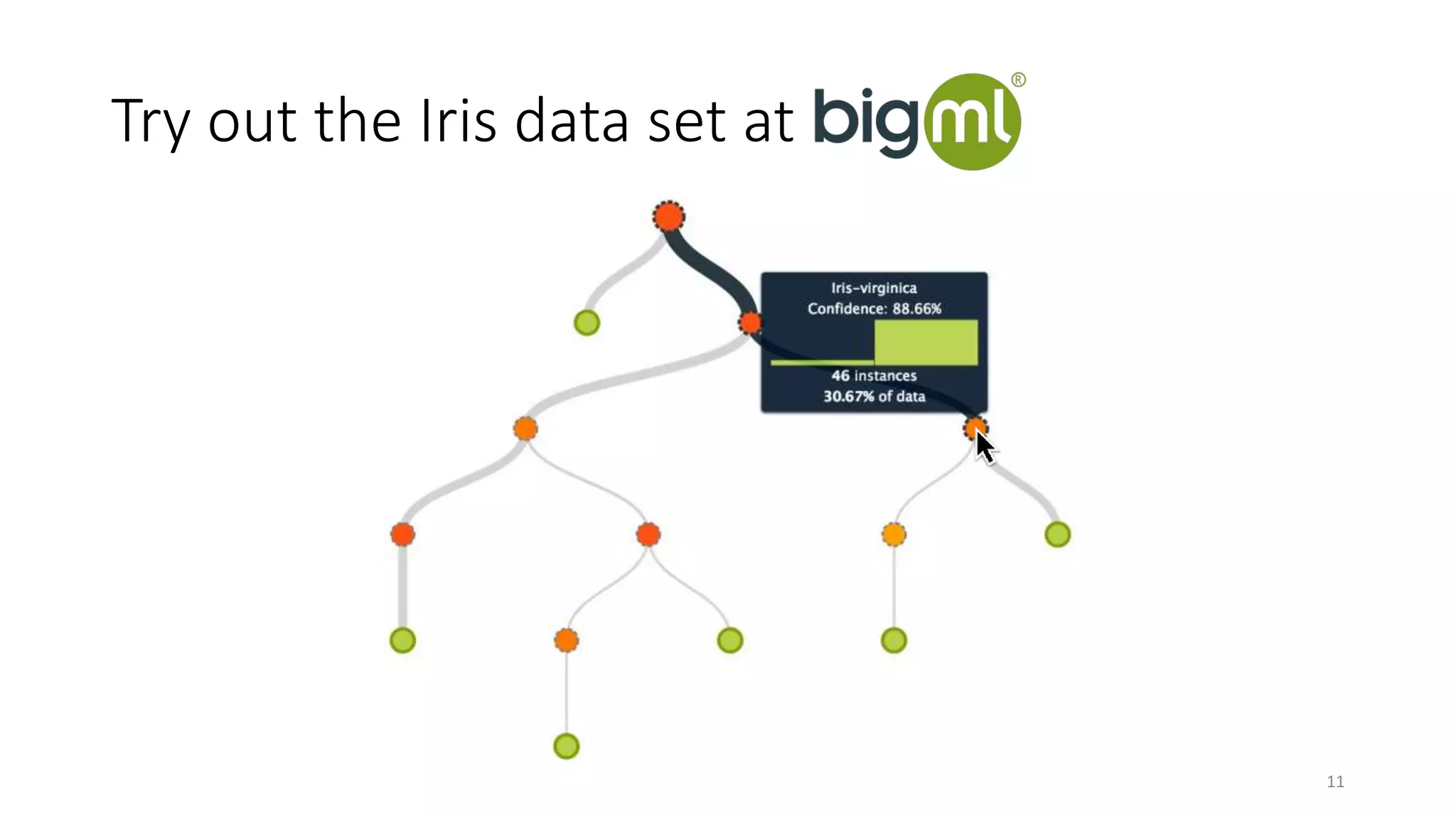











The document discusses machine learning, focusing on its definition and practical application using the iris and StumbleUpon datasets. It highlights the process of training versus scoring models, the importance of historical data, and the distinction between real-time training and scoring. Additionally, it emphasizes that effective machine learning does not require large datasets to generate useful insights.


































![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)












