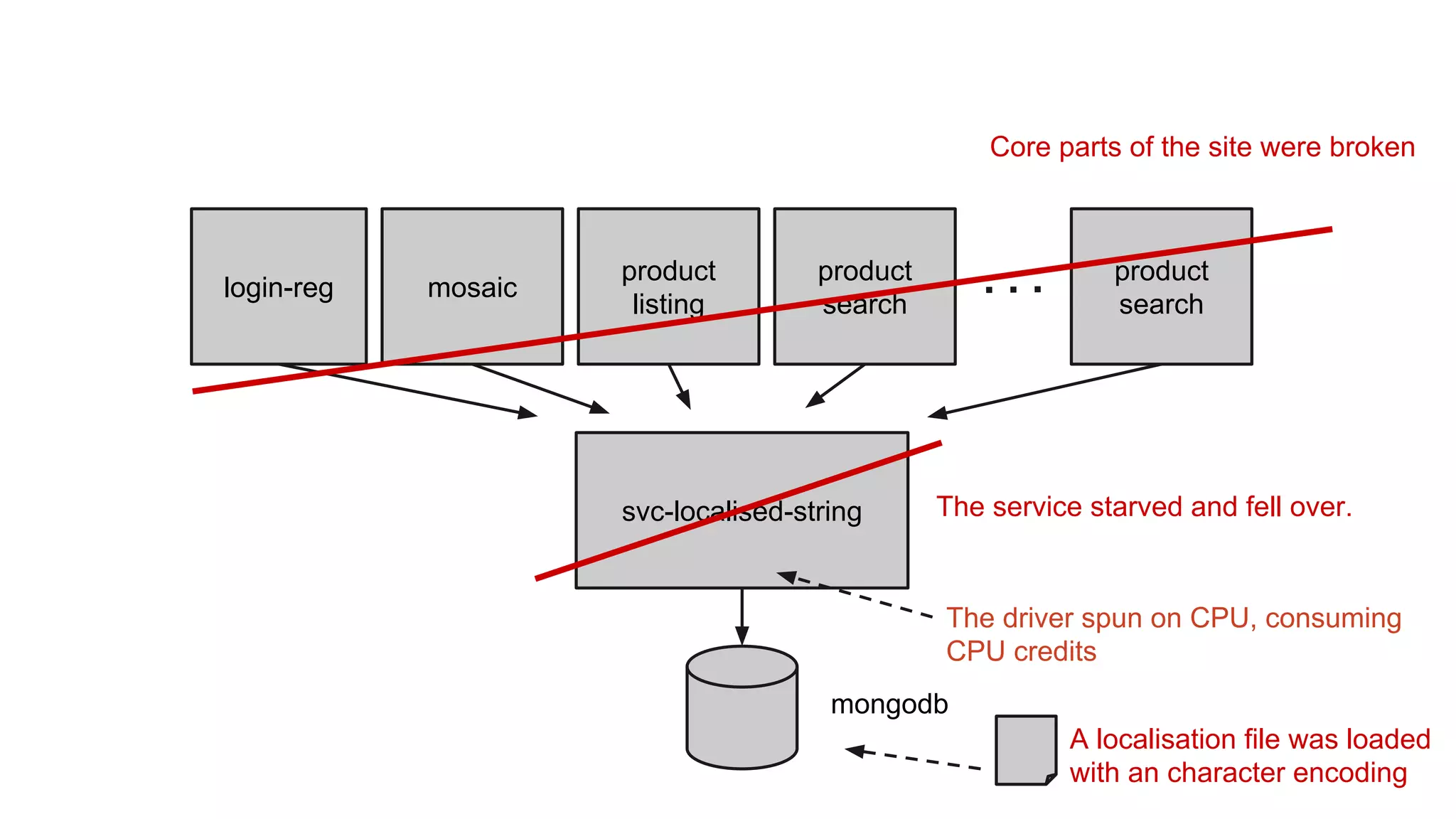
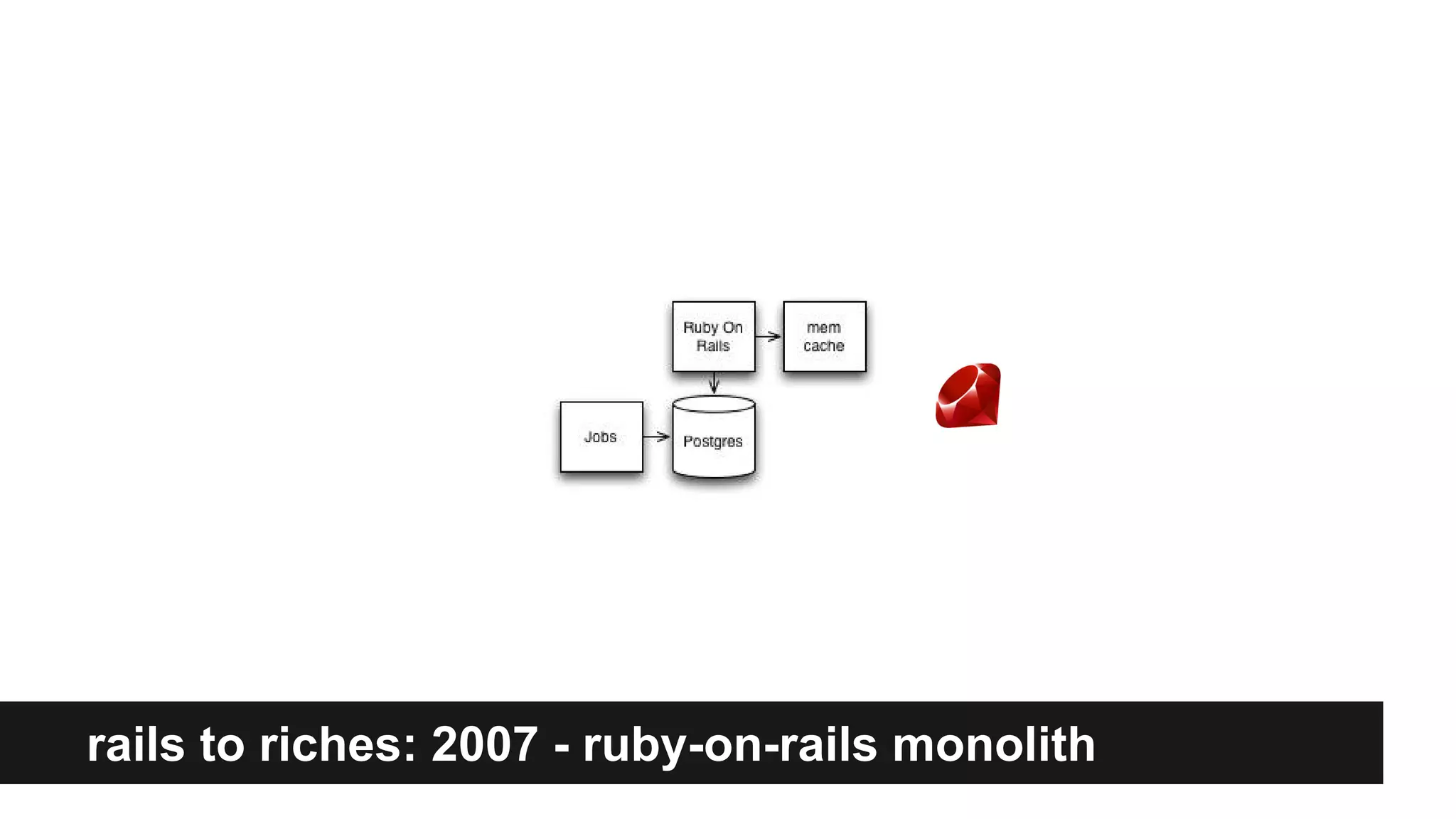
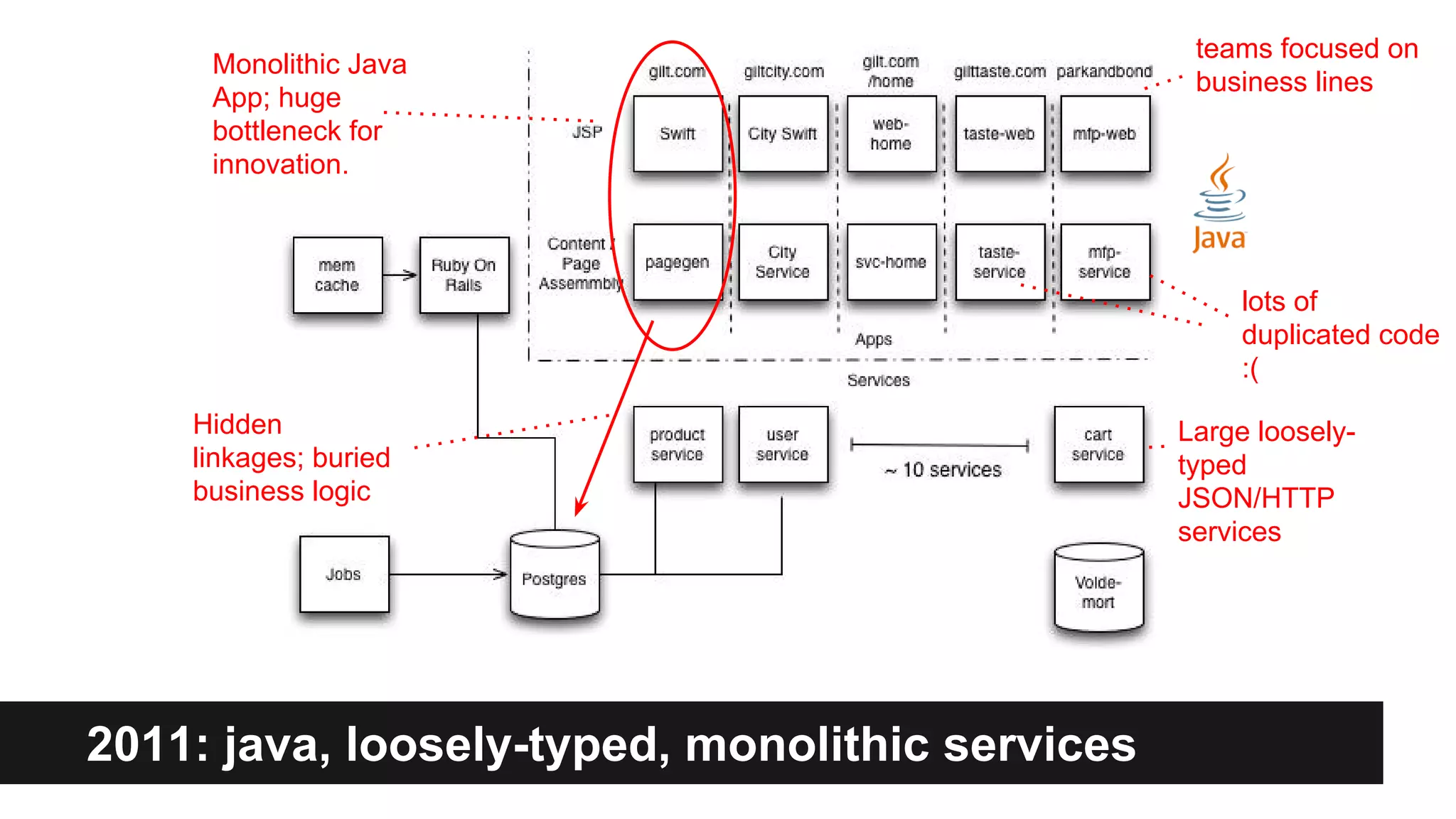
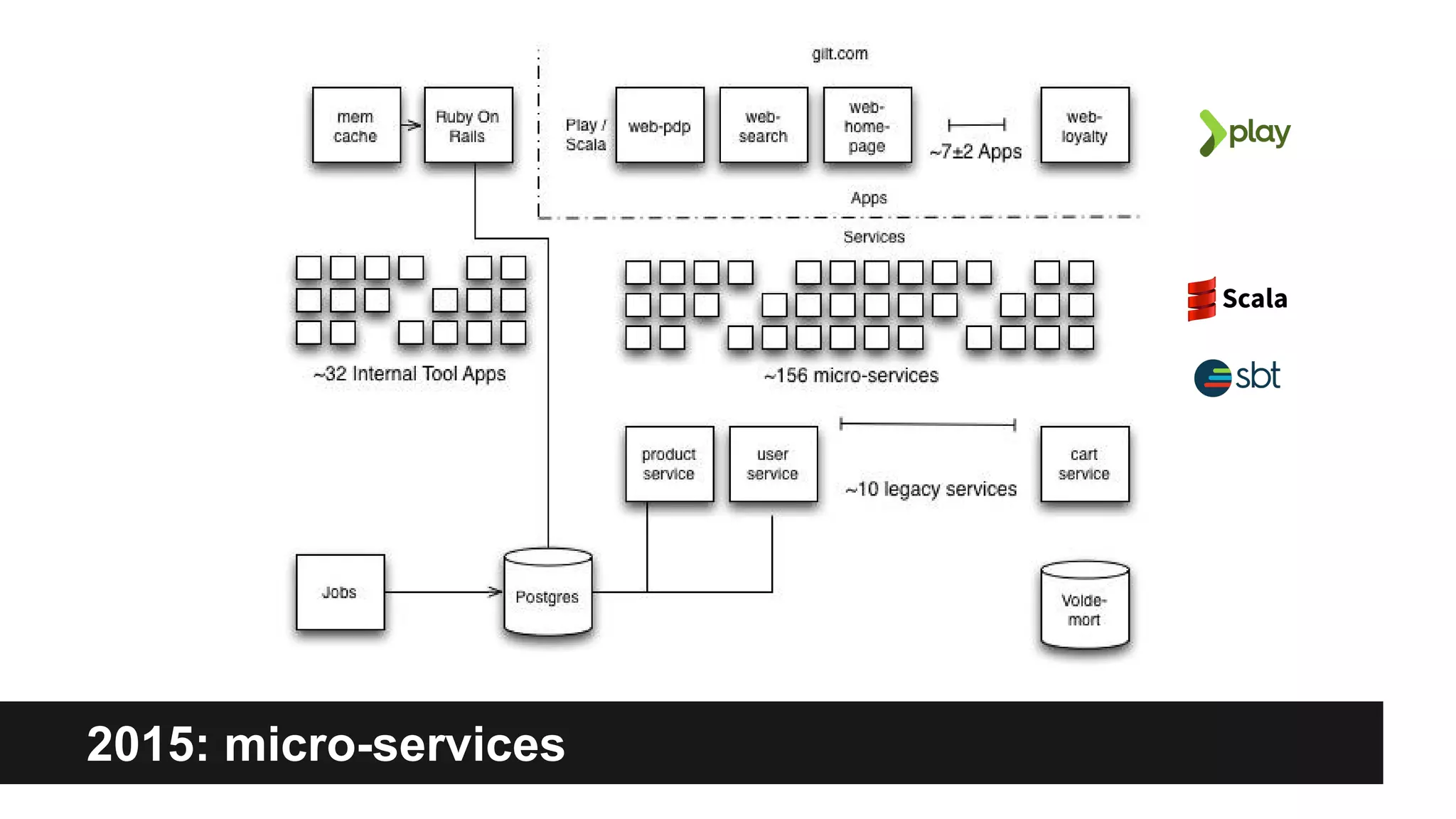
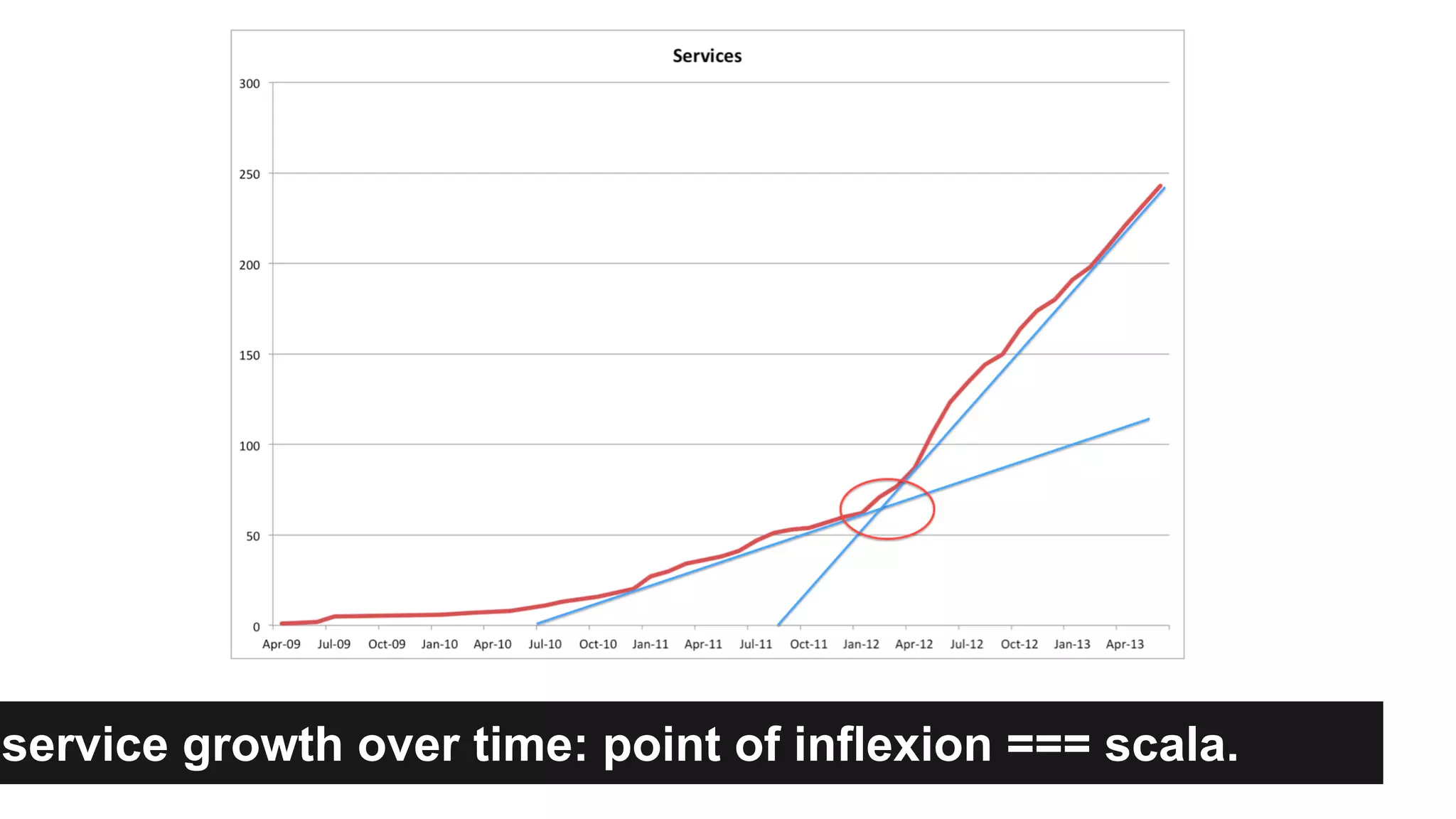
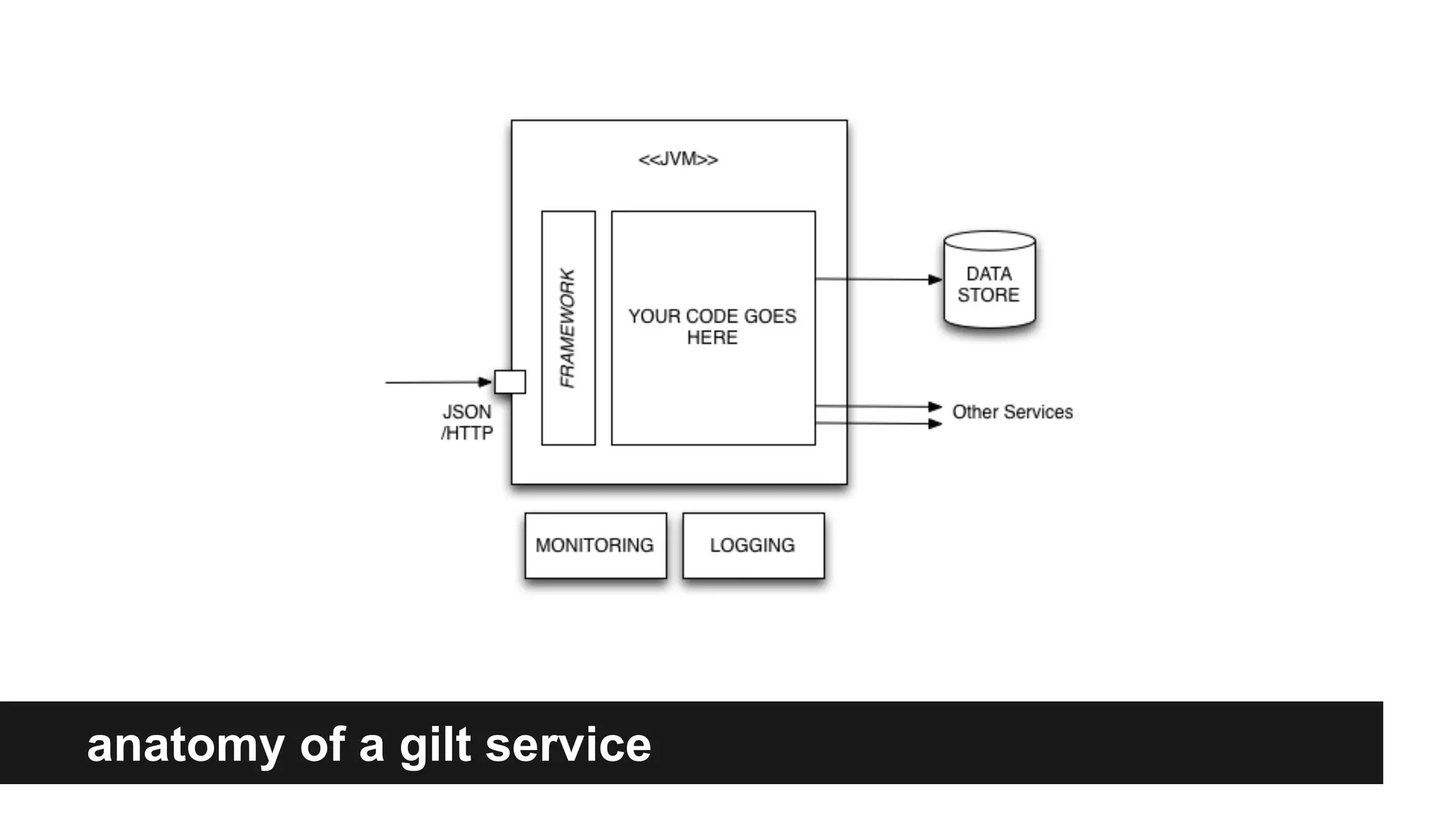
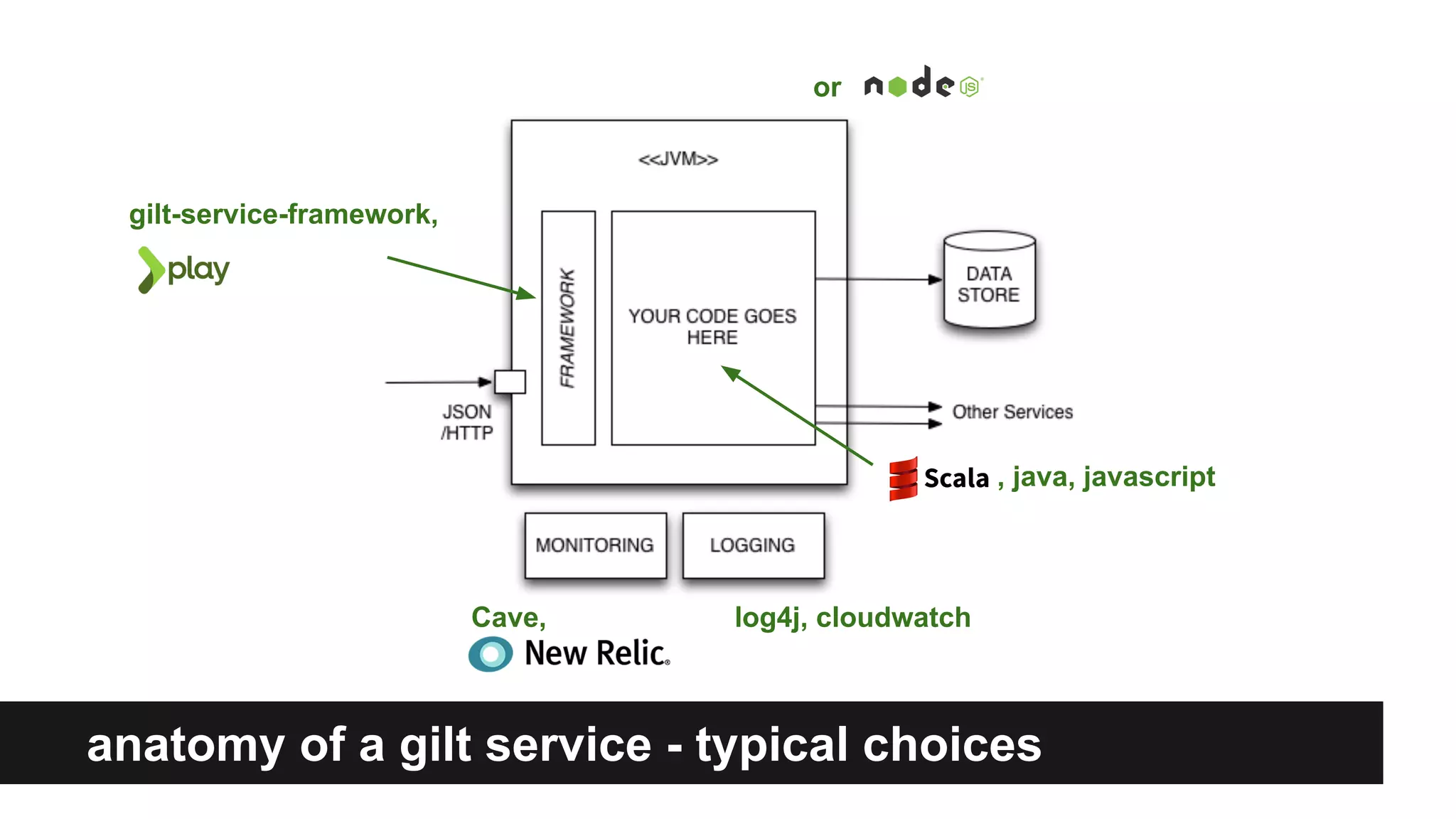
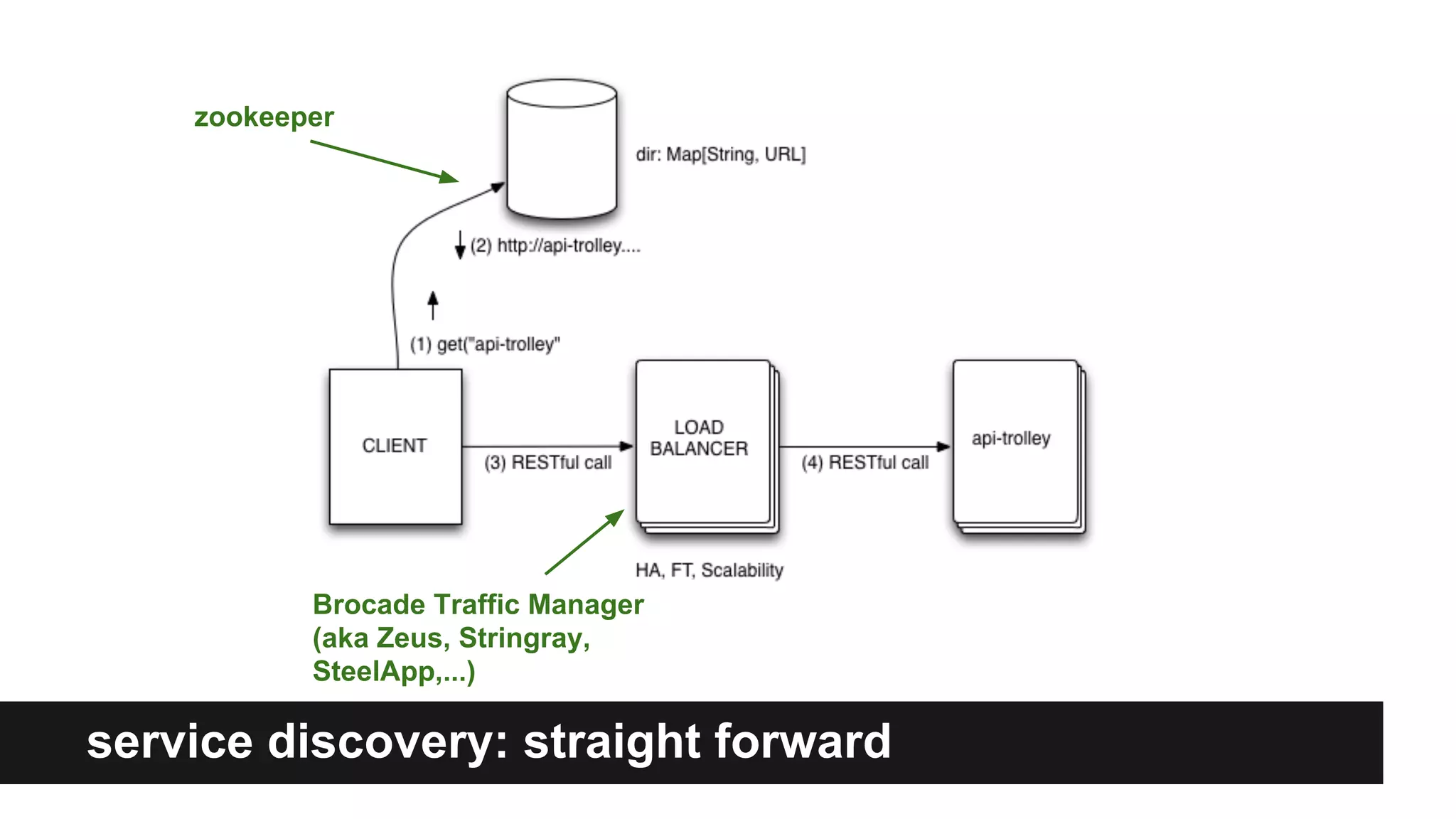
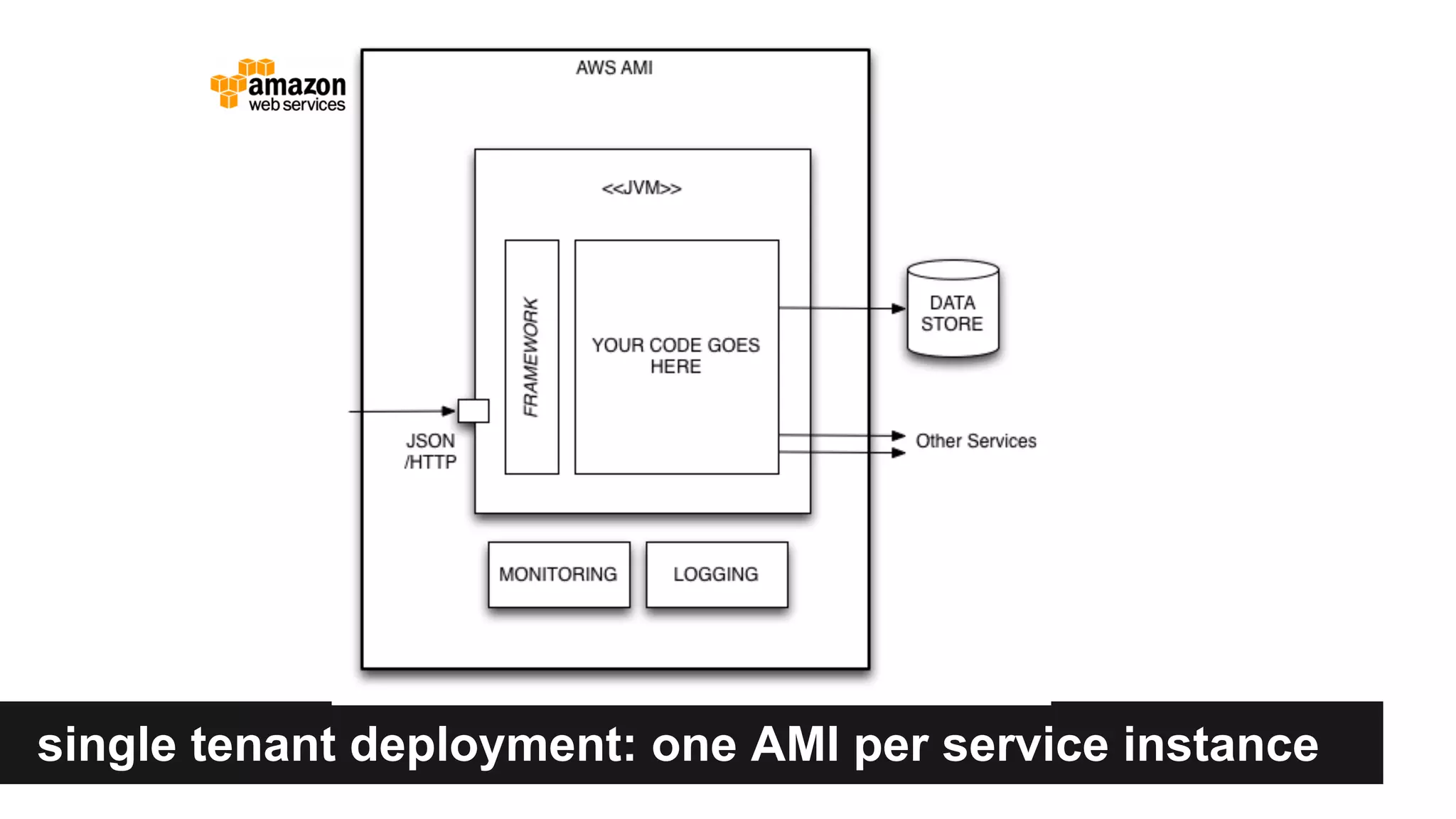
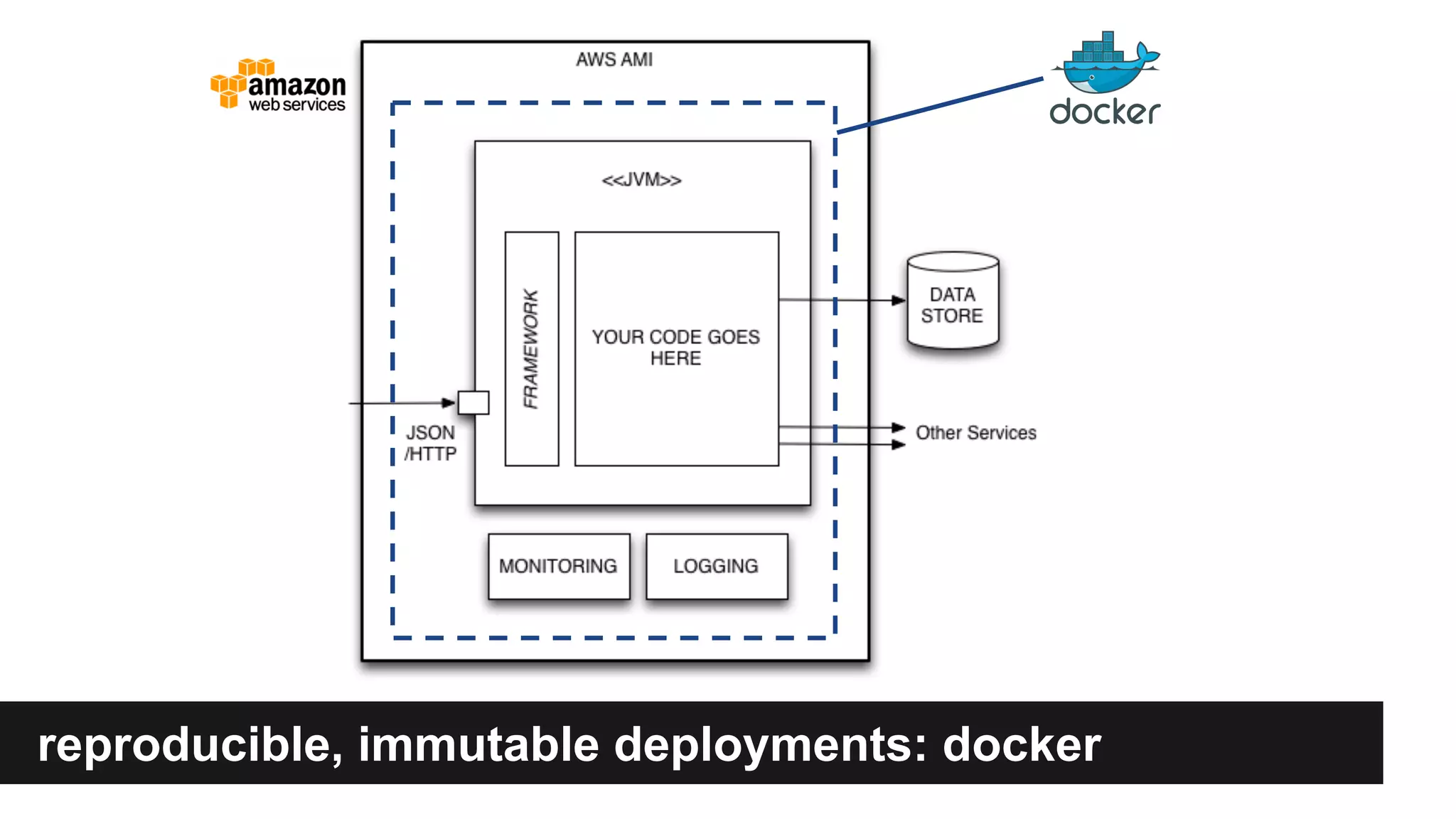
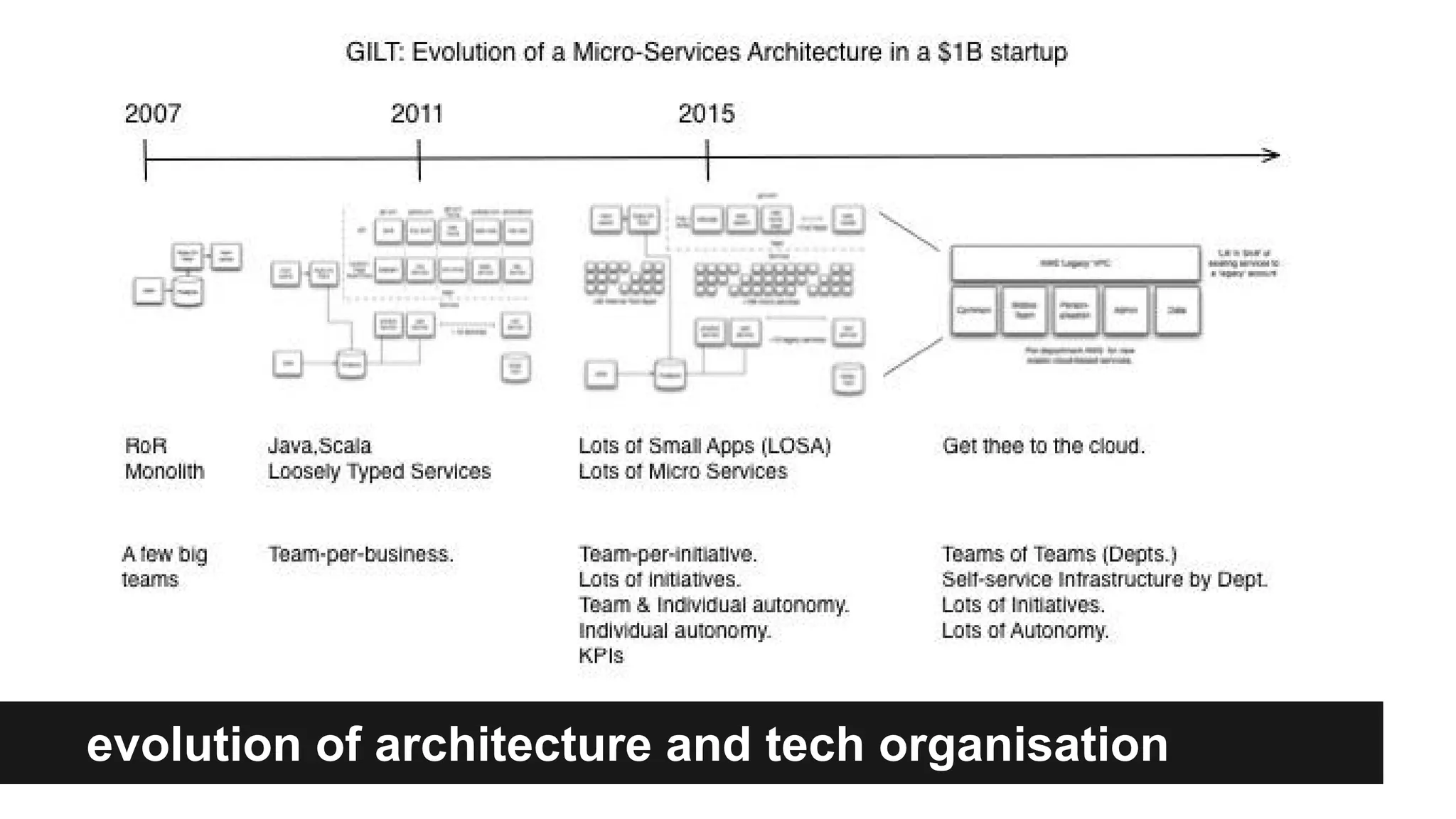
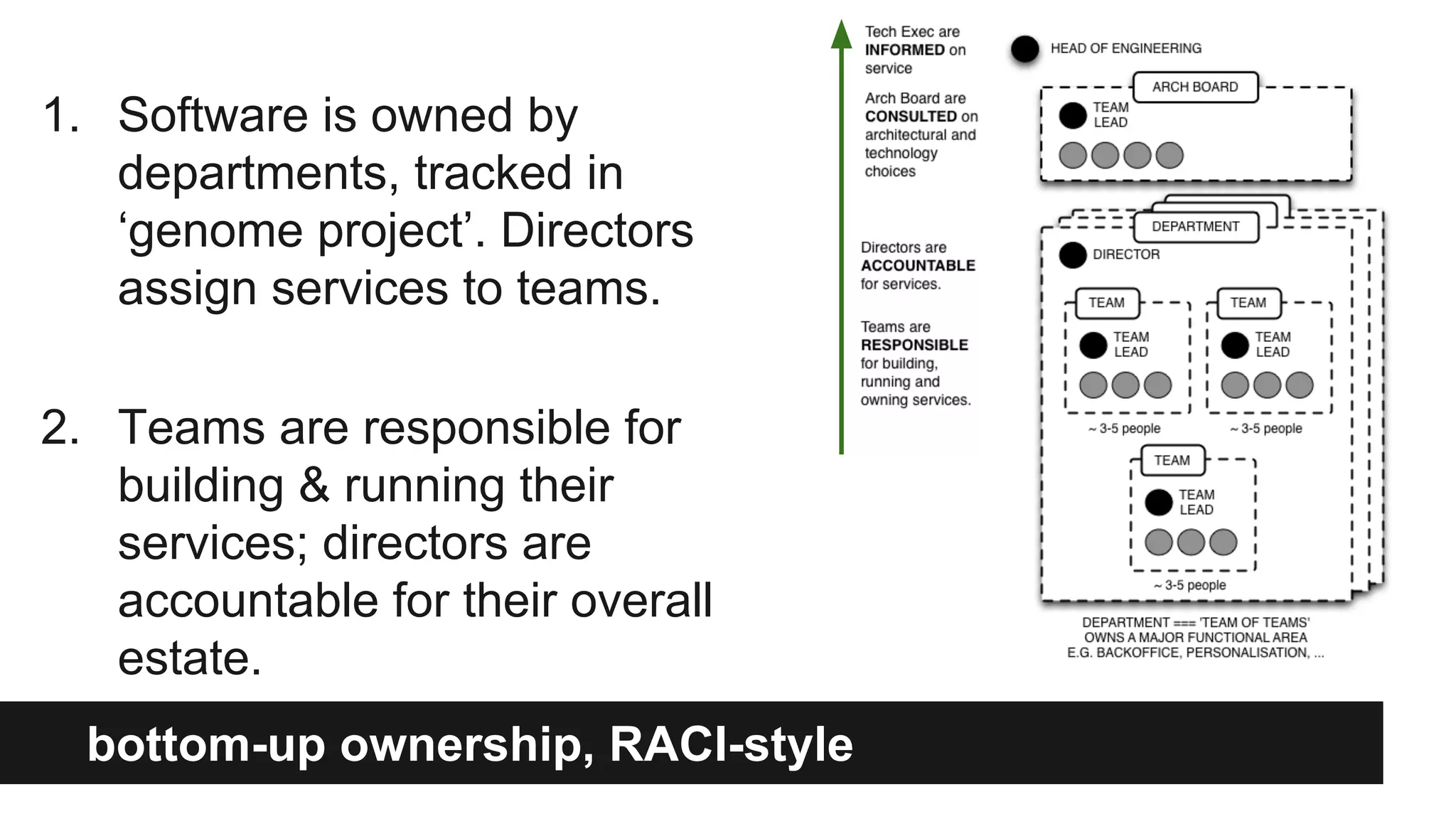
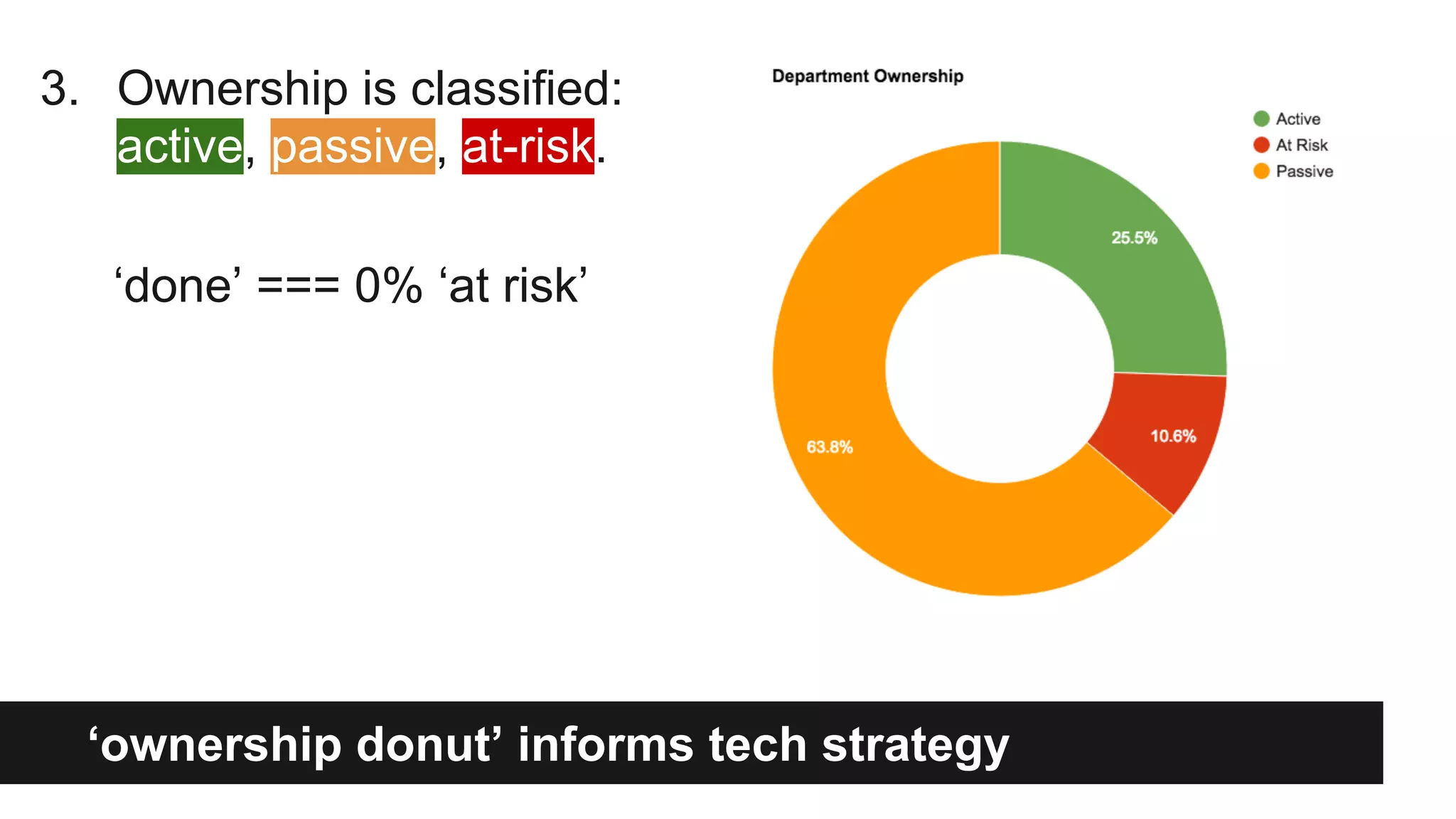
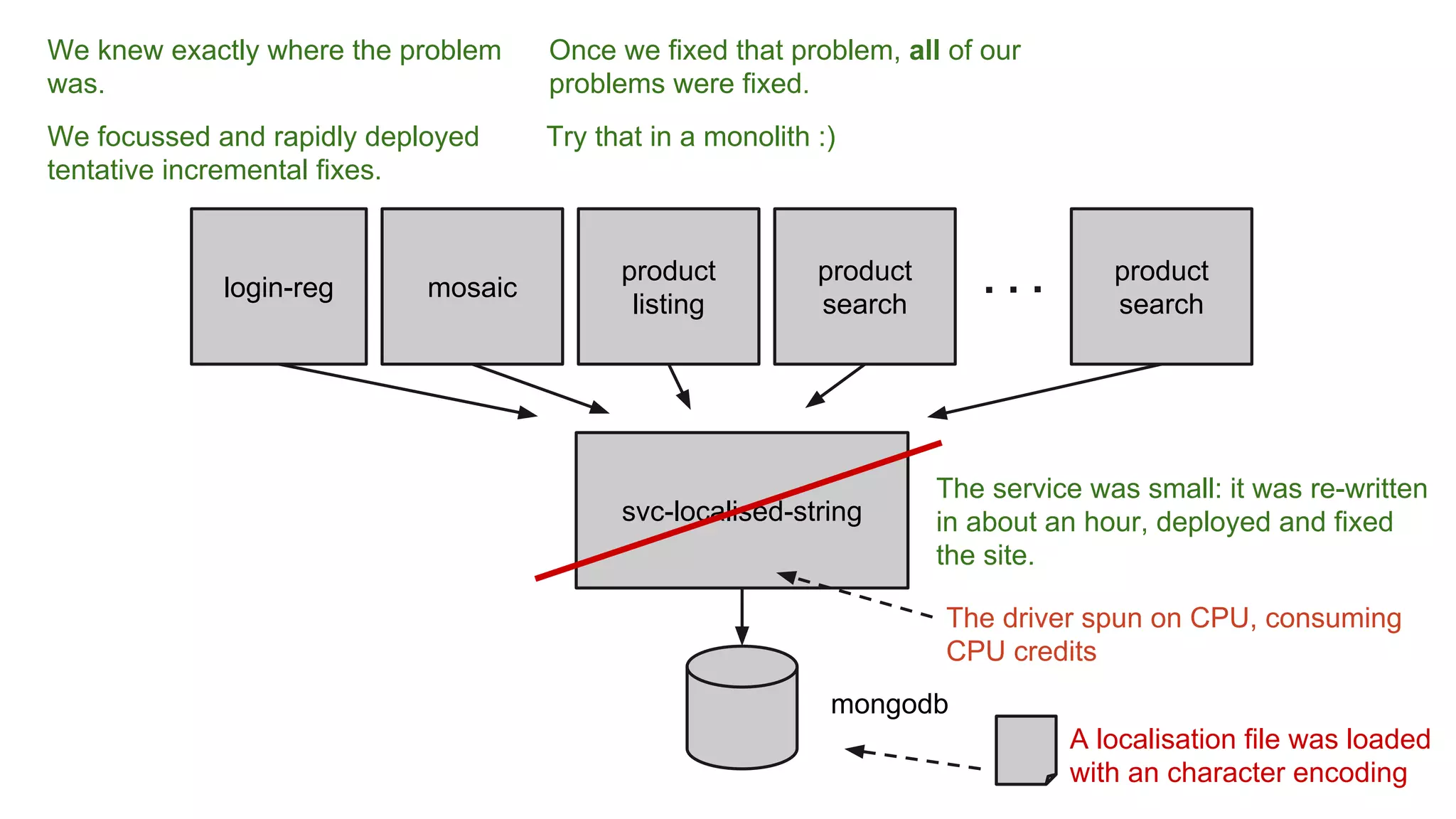
Gilt transitioned from a monolithic architecture to micro-services to enhance team autonomy and innovation while addressing issues like service ownership and deployment challenges. The company adopted practices such as automation and open-source tools to improve service management in a cloud environment. Despite challenges in maintaining staging environments and ensuring compliance, Gilt experienced improved problem resolution and service reliability with micro-services.


















![5. audit + alerting
How do we stay compliant while giving
engineers full autonomy in prod?
Really smart alerting: http://cavellc.github.io
orders[shipTo: US].count.5m == 0](https://image.slidesharecdn.com/geeconmicroservices2015-scalingmicroservicesatgilt-150911124701-lva1-app6891/75/GeeCON-Microservices-2015-scaling-micro-services-at-gilt-42-2048.jpg)























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)





