Downloaded 23 times














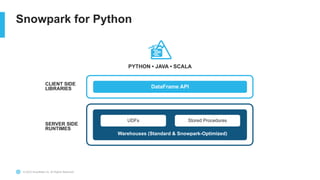
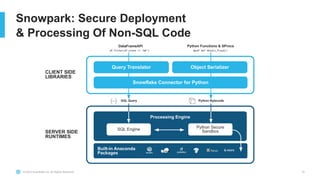

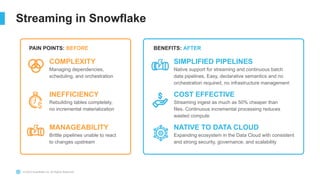
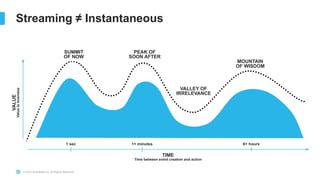
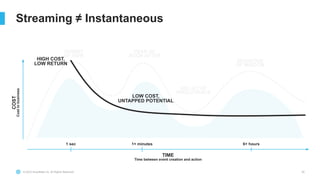
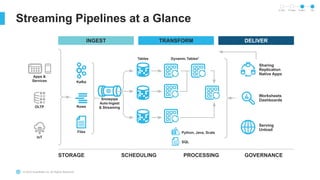

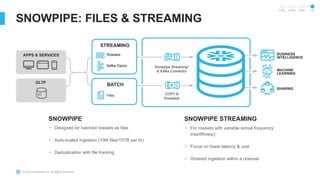
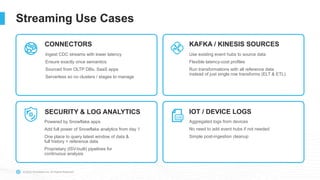
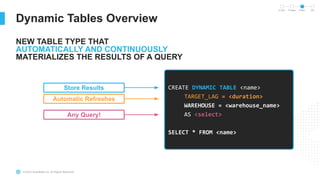
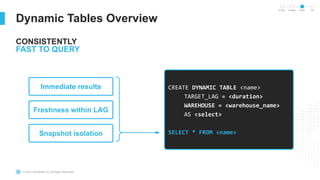






The document outlines the challenges involved in developing data pipelines, especially troubleshooting and debugging failed jobs related to Spark and infrastructure setup. It introduces Snowpark for Python, which simplifies the deployment and processing of non-SQL code, and highlights the benefits of data streaming with dynamic tables in Snowflake. Additionally, it details various ingestion options and the use of dynamic tables for efficient and continuous data management.

![[B31,32]SQL Server Internal と パフォーマンスチューニング by Yukio Kumazawa](https://cdn.slidesharecdn.com/ss_thumbnails/sqlserverinternalupload-140204185245-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)









