Downloaded 25 times

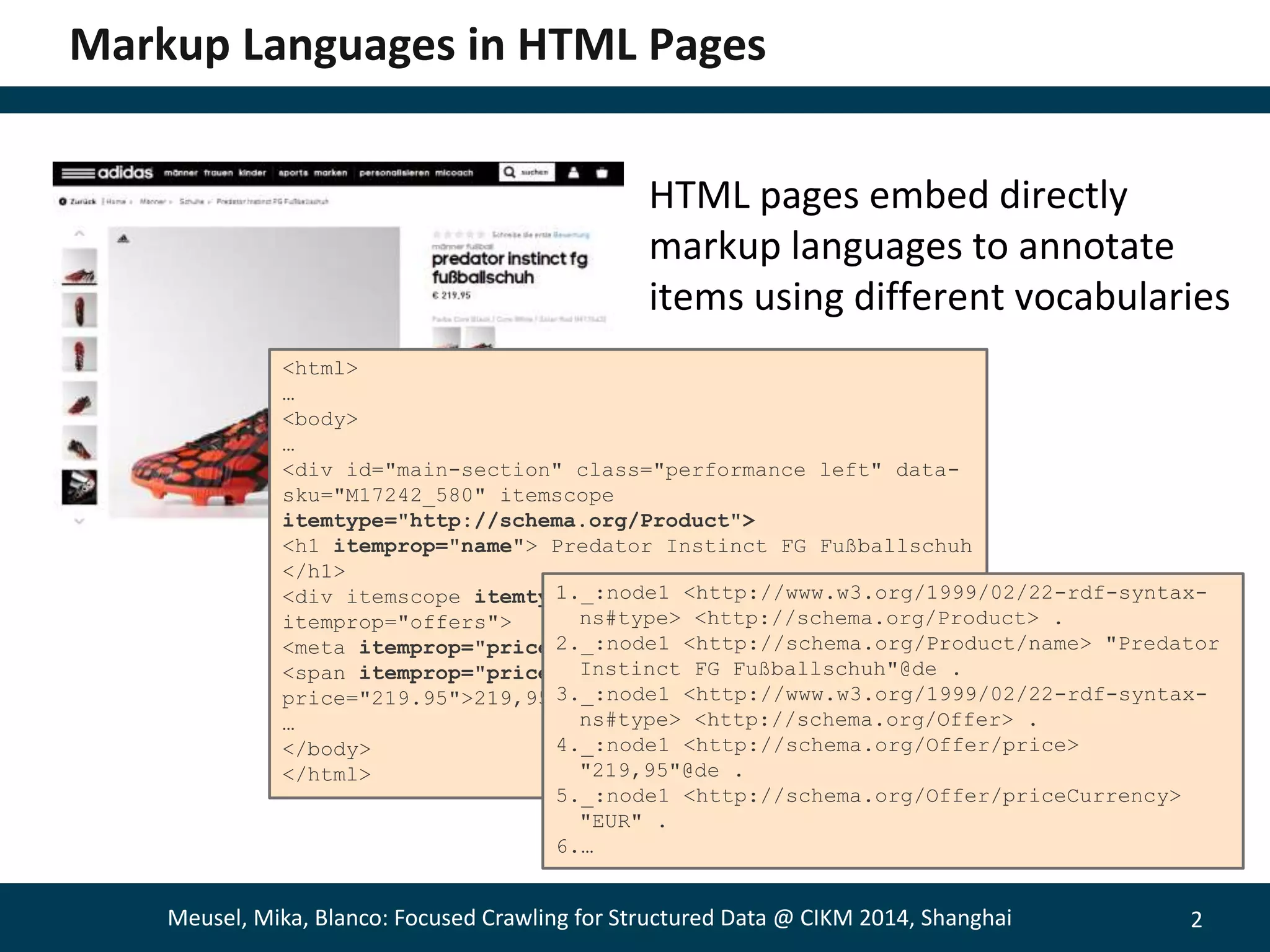
![3
Deployment of Markup Languages
14% of all sites use markup languages to annotate
their data (status 2013) [Meusel2014]
• Broad topical variations from Articles over Products to
Recipe [Bizer2013]
• Multiple strong drivers pushing the deployment
• Search engine companies initiative on Schema.org
• Open Graph Protocol used by Facebook
Meusel, Mika, Blanco: Focused Crawling for Structured Data @ CIKM 2014, Shanghai](https://image.slidesharecdn.com/crawlingforstructureddataslideshare-141112072447-conversion-gate02/75/Focused-Crawling-for-Structured-Data-3-2048.jpg)
![4
Motivation
• Existing datasets/crawls do not focus on structured data
• Common Crawl Foundation uses PageRank and Breadth-First Search
• Datasets, as the WebDataCommons corpus extracted from these
corpora, are likely to miss large amounts of data [Meusel2014]
• Structured information
• Hundreds of million pages
• Up-to-date information
• Publicly available
Meusel, Mika, Blanco: Focused Crawling for Structured Data @ CIKM 2014, Shanghai](https://image.slidesharecdn.com/crawlingforstructureddataslideshare-141112072447-conversion-gate02/75/Focused-Crawling-for-Structured-Data-4-2048.jpg)





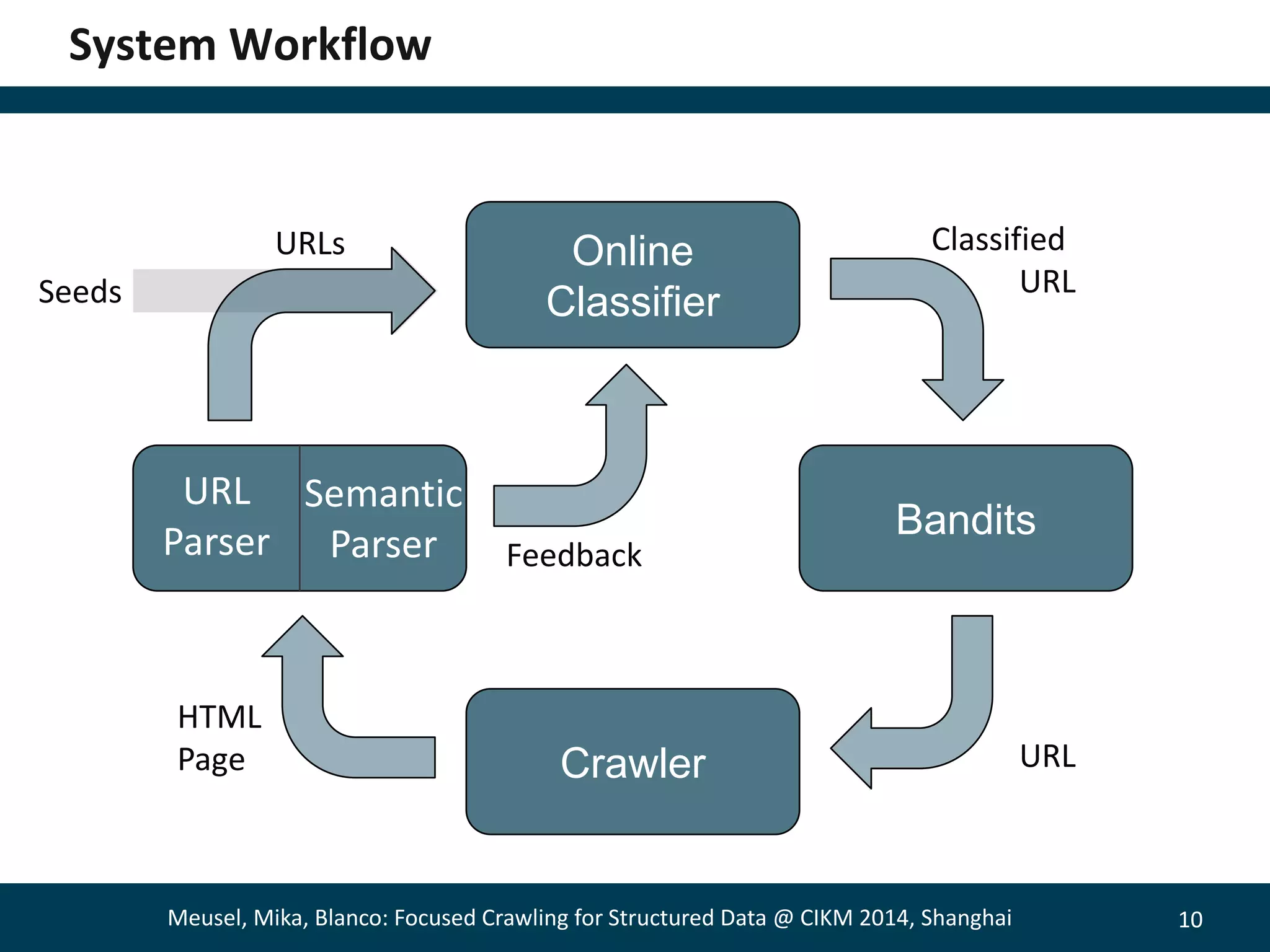


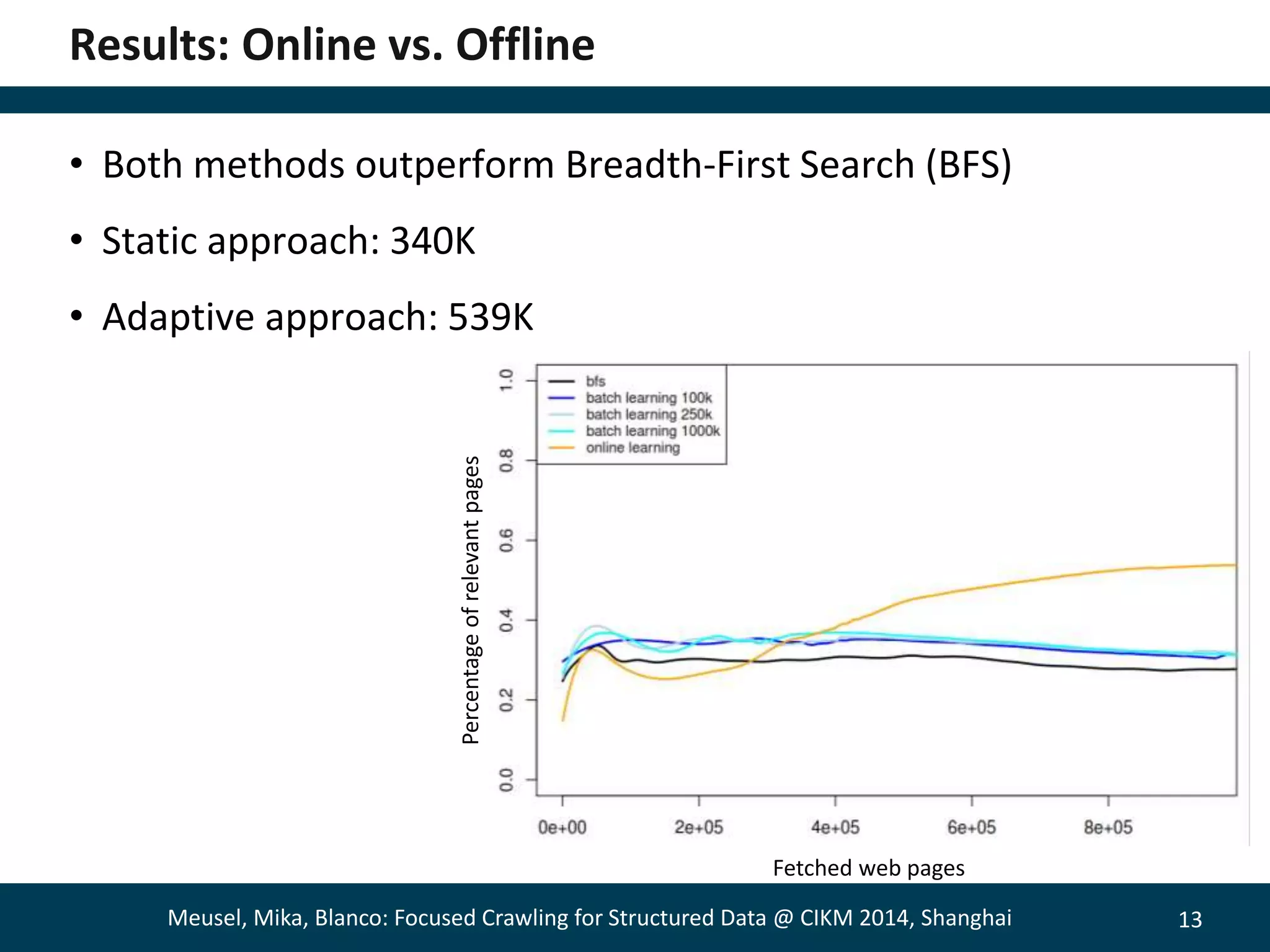
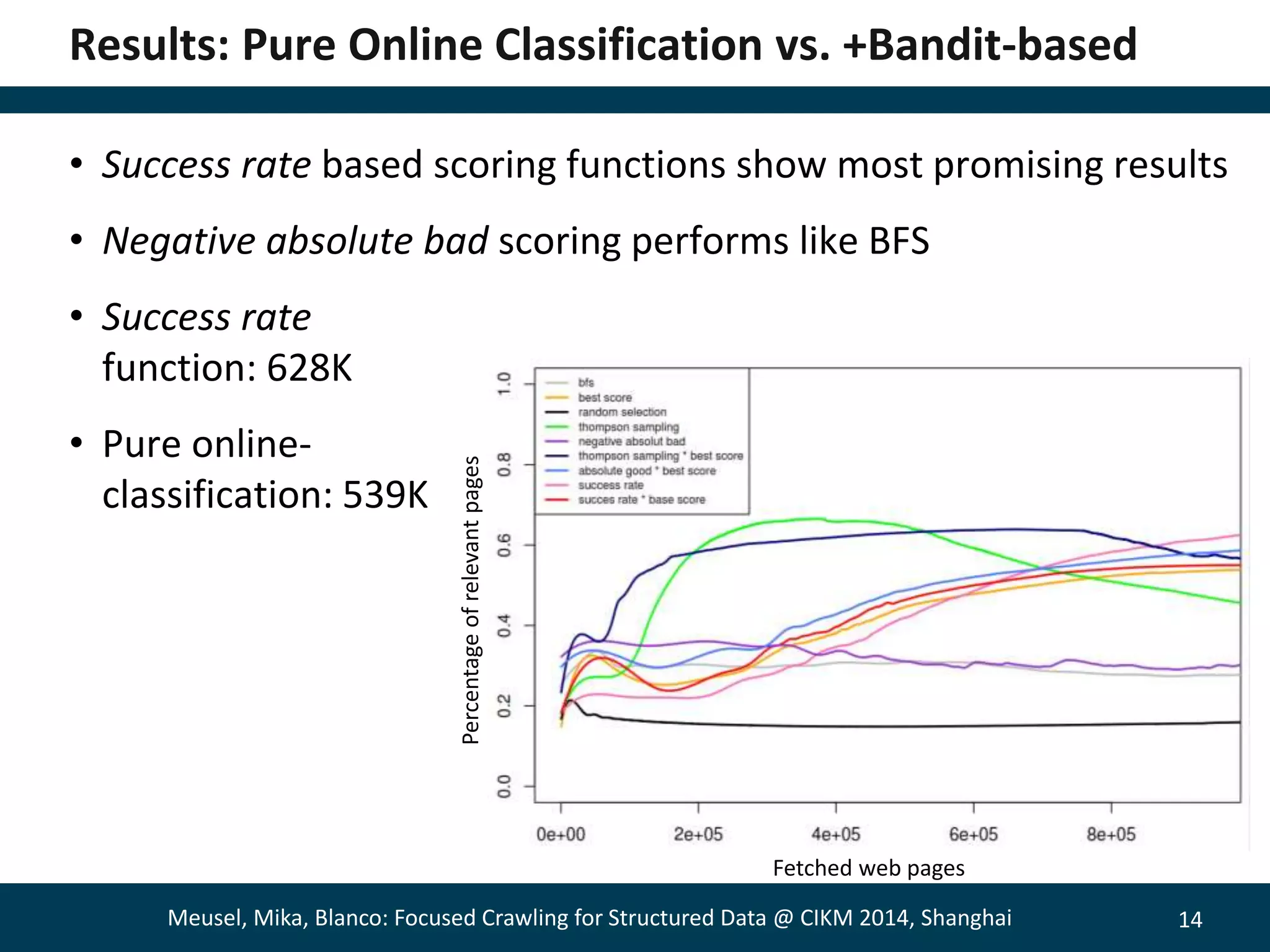
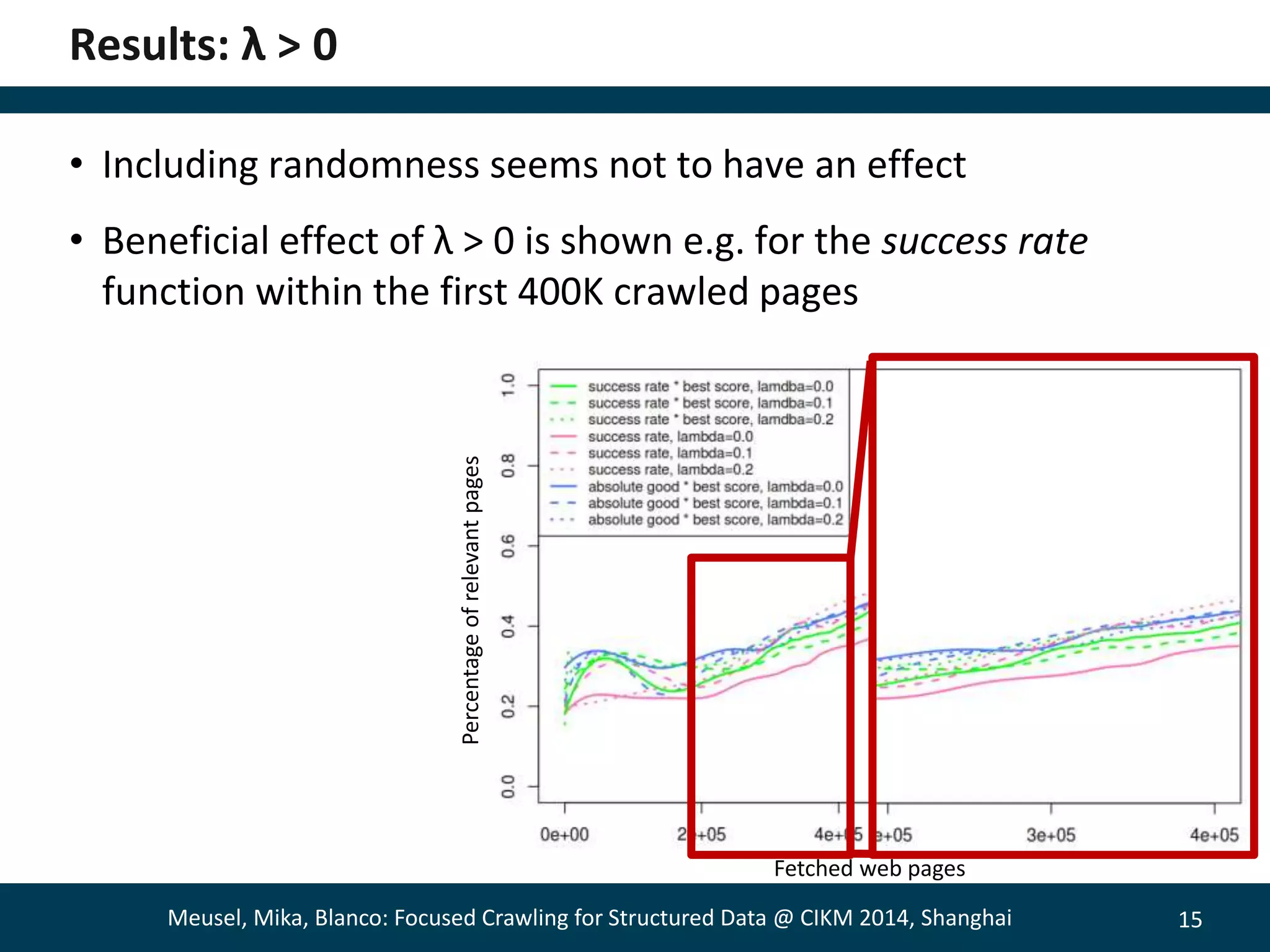
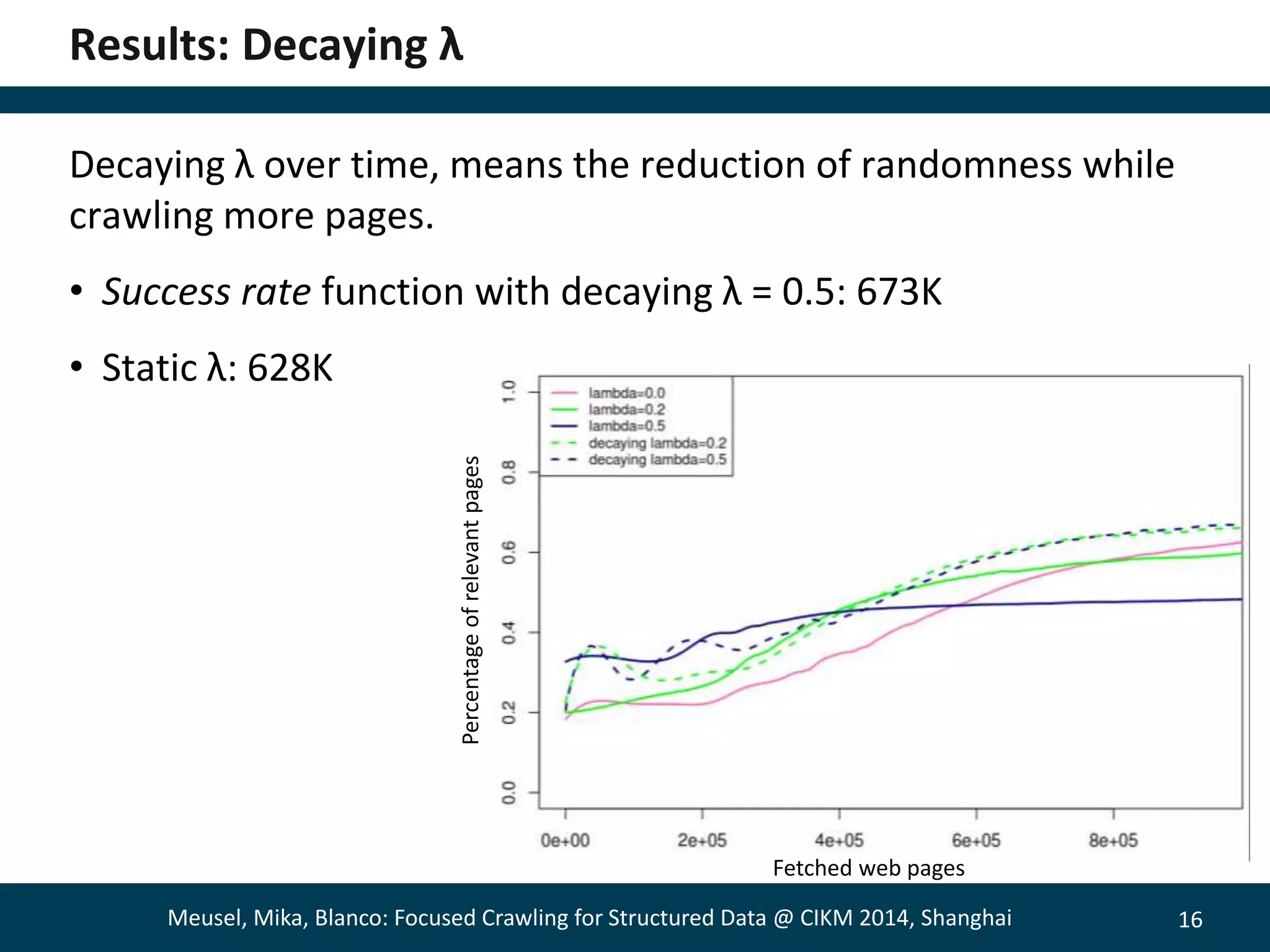

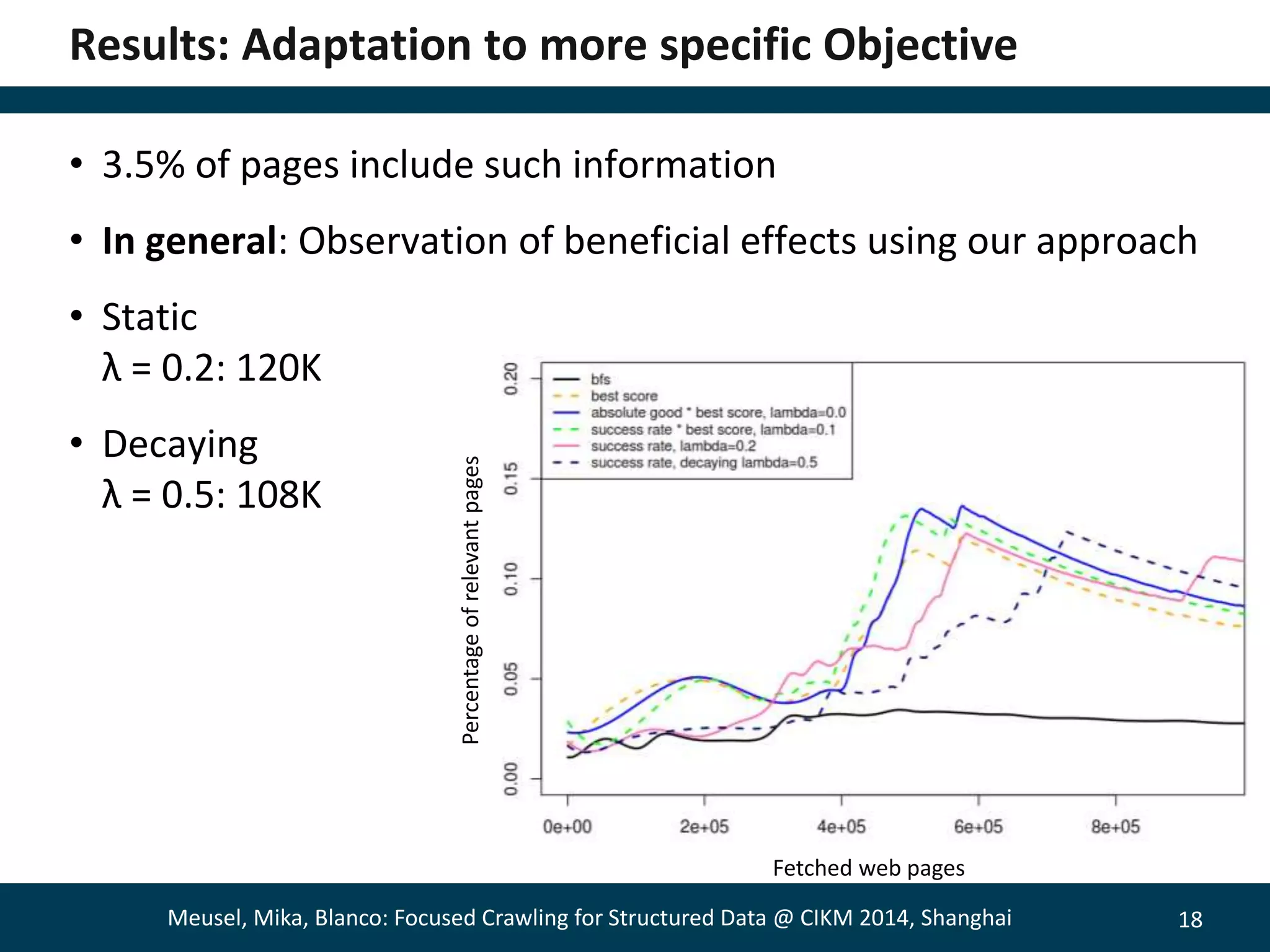




The document describes a method for focused crawling to retrieve structured data from web pages. It involves using an online classifier trained on URL features to identify pages containing structured data. A bandit-based selection strategy is used to balance exploration and exploitation. Experiments show the adaptive approach retrieves 26% more relevant pages than static classification, and 66% more when focused on a specific objective. Decaying the bandit randomness over time improved results further. The method was able to retrieve hundreds of millions of structured data pages from billions of web pages.





















































