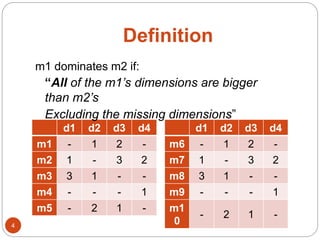
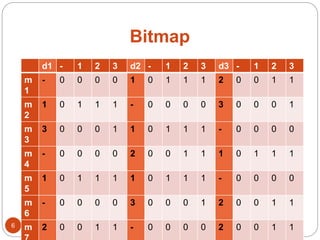
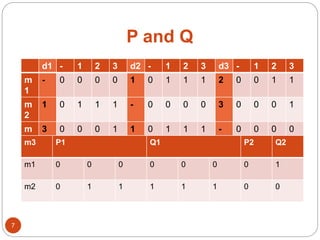
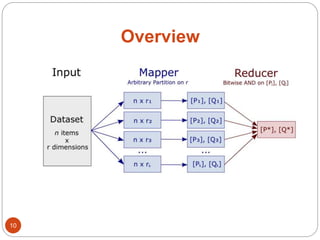
The document discusses a methodology for finding top-k dominance in incomplete big data using a MapReduce framework. It introduces algorithms like skyband-based and bitmap index guided algorithms to handle missing values and improve data evaluations. The paper includes technical definitions, evaluation metrics, and performance data across various user and movie datasets.






![References
13
Finding Top- k Dominance on Incomplete Big
Data Using MapReduce Framework [link]
Top-k dominating queries on incomplete data
[link]](https://image.slidesharecdn.com/top-k-181223194810/85/Finding-Top-k-Dominance-on-Incomplete-Big-Data-Using-MapReduce-Framework-13-320.jpg)






























![[DSC Europe 25] Mikhail Rozhkov - AI Product Canvas: From Business Goals to T...](https://cdn.slidesharecdn.com/ss_thumbnails/d53doddtpgfqivmzqel6-mikhail-rozhkov-ai-product-canvas-v1-260121115910-9dd517a7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Gordana Milutinovic Dumbelovic - From Insight to Oversight: A...](https://cdn.slidesharecdn.com/ss_thumbnails/t7dkjsfxqwwzceropjv4-gordana-milutinovicdumbelovic-from-insight-to-oversight-ai-driven-power-bi-moni-260119121559-9e0bf11b-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Tamas Srancsik - How To Teach Your AI Football? An Argument f...](https://cdn.slidesharecdn.com/ss_thumbnails/bcjh1m9xtbosv20ucftb-tamas-srancsik-how-to-teach-your-ai-football-260121115910-08b53e9e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Ratko Nikolic - BI with AI: Automating Business Intelligence ...](https://cdn.slidesharecdn.com/ss_thumbnails/ecd7hahhq6qiwefuoiyw-dsc2025-ratko-nikolic-ai-data-analyst-260119101519-54d52956-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bojan Banjac - AI is always right when it comes to the matter...](https://cdn.slidesharecdn.com/ss_thumbnails/syoxtqierpydwxm5srcb-4-bojan-banjac-ai-is-always-right-when-it-comes-to-the-matters-of-taste-260119101519-694ee7d7-thumbnail.jpg?width=640&height=640&fit=bounds)