INTRODUCTION TO ExPASy
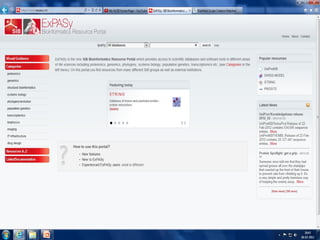
•The ExPASy (Expert Protein Analysis System) proteomics
server of the Swiss Institute of Bioinformatics (SIB) is
designed for the analysis of protein sequences and structures
as well as 2-D PAGE.
• The SIB Swiss Institute of Bioinformatics is an academic, non-
profit foundation established in 1998. SIB coordinates research
and education in bioinformatics throughout Switzerland and
provides high quality bioinformatics services to the national
and international research community.
• www.expasy.ch/
UniProt
• The aimof Universal Protein Resource (UniProt) is to provide
the scientific community with a comprehensive, high quality
and freely accessible resources of protein sequences and
functional information..
• The UniProt Knowledgebase consists of two sections:
– Swiss-Prot - a section containing manually-annotated records
with information extracted from literature and curator evaluated
computational analysis.
– TrEMBL - a section with computationally analyzed records that
await full manual annotation.
7.
SWISS - PROT
•Swiss-Prot is an annotated protein sequence database. It
was established in 1986 and maintained collaboratively by
the group of Amos Bairoch, the Swiss Institute of
Bioinformatics (SIB) and the EMBL Data Library (now
the EMBL Outstation – The European Bioinformatics
Institute (EBI)).
• The Swiss-Prot Protein Knowledgebase consists of
sequence entries. Sequence entries are composed of
different line types, each with their own format. For
standardization purposes the format of Swiss-Prot follows
as closely as possible that of the EMBL Nucleotide
Sequence Database.
• Swiss-Prot distinguishes itself from protein sequence
databases by four distinct criteria:
8.
a) Annotation
• InSwiss-Prot, as in many sequence databases, two
classes of data can be distinguished, the core data
and the annotation.
• For each sequence entry the core data consists of:
– The sequence data.
– The citation information (bibliographical
references).
9.
– The taxonomicdata. The annotation consists of the
description of the following items:
• Function(s) of the protein
• Posttranslational modification(s) such as carbohydrates,
phosphorylation & acetylation .
• Domains and sites, for example, calcium-binding regions,
ATP-binding sites, zinc fingers.
• Secondary structure, e.g. alpha helix, beta sheet.
• Quaternary structure, e.g. homodimer, heterotrimer, etc.
• Similarities to other proteins.
• Disease(s) associated with any number of deficiencies in the
protein.
• Sequence conflicts, variants, etc.
10.
CONTINUED . ..
b) MINIMAL REDUNDANCY
c) INTEGRATION WITH OTHER DATABASES
d) DOCUMENTATION
11.
PROSITE
• PROSITE consistsof documentation entries
describing protein domains, families and
functional sites as well as associated patterns
and profiles to identify them.
12.
COMPLETE PROTEOMES
• Aproteome consists of the complete set of proteins
thought to be expressed by an organism whose
genome has been completely sequenced.
• The taxonomy pages provide links to download
Complete Proteome Sets when available, as well as
links to the HAMAP and/or Integr8 web sites
13.
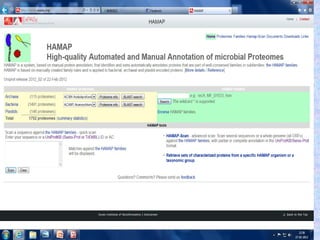
HAMAP
• HAMAP isa system, based on manual protein
annotation, that identifies and semi-
automatically annotates proteins that are part
of well-conserved families or subfamilies: the
HAMAP families. HAMAP is based on manually
created family rules and is applied to bacterial,
archaeal and plastid-encoded proteins.
15.
SWISSVAR
• SwissVar isa portal to search variants in UniProt Knowledgebase
(UniProtKB) entries, and gives direct access to the
UniProtKB/Swiss-Prot Variant pages.
• The UniProtKB/Swiss-Prot Variant pages summarize all the
information related to a particular variant and contain:
• manual annotation on the genotype-phenotype relationship of each
specific variant based on literature;
• pre-computed information (such as conservation scores and a list of
structural features when available) to help assess the effect of the
variant.
16.
MAIN SEARCH CATEGORIES
SEARCH
CATEGORIES
FUNCTIONALITIES
DISEASEEnable search using disease names, OMIM
identifier, as well as MeSH terms or
identifiers of the disease category
GENERAL
CHARACTERISTICS
Enable search using protein or gene names,
UniProt accession number or identifier
FUNCTIONAL/
STRUCTURAL
FEATURES
Enable search using a list of functional and
structural parameters of the variant
SWISS MODEL REPOSITORY
•It is a database of annotated 3-D comparative protein
structure models generated by the fully automated
homology - modelling pipeline SW ISS- MODEL.
19.
SWISS – 2DPAGE
• SWISS-2DPAGE contains data on proteins identified on
various 2-D PAGE and SDS-PAGE reference maps. We can
locate these proteins on the 2-D PAGE maps or display the
region of a 2-D PAGE map where one might expect to find a
protein from UniProtKB/Swiss-Prot.
20.
WORLD 2D –PAGE REPOSITORY
• A public standards-compliant repository for gel-
based proteomics data from many published
articles..
21.
ENZYME
• ENZYME isa repository of information relative to the
nomenclature of enzymes. It is primarily based on the
recommendations of the Nomenclature Committee of the
International Union of Biochemistry and Molecular Biology
(IUBMB) and it describes each type of characterized enzyme
for which an EC (Enzyme Commission) number has been
provided.
• SEARCH BY CLASS OF ENZYME
DNA PROTEIN
a.Translate:-translates a nucleotide sequence to
protein sequence
b. Reverse translate
POST TRANSLATIONAL MODIFICATION
PREDICTION
a) Terminator:- prediction of N-terminal
modification.
b) Lipo P:-prediction of lipoproteins & signal
peptides in gram negative bacteria.
24.
TOPOLOGY PREDICTION
a)TopPred – Topology prediction of membrane
proteins
PRIMARY STRUCTURE ANALYSIS
a) PROTParam :- physico-chemical parameters of a
protein sequence.
b) 2 ZIP:- prediction of leucine zippers
SECONDARY STRUCTURE ANALYSIS
a) JUFO:- Protein secondary structure prediction
from sequence.
• The BioinformaticsCore Facility for Proteomics is an entity of the
Proteome Informatics Group. Its mission is to provide the best
available technology in bioinformatics for proteomics to contribute to
the research programs of scientists at the Faculties of Medicine and
Sciences from the University of Geneva, in the whole Switzerland or
abroad.
• In doing this, the Bioinformatics Facility for Proteomics provides
a cost-effective means for investigators to have access to
sophisticated data analysis via the latest software. Assistance,
training and access to cutting-edge equipment and software in the
operation of the Bioinformatics Facility for Proteomics, which are
implemented through the following :
27.
CONTINUED . ..
• Help desk - supply skilled personnel to aid in the
analysis and interpretation of proteomics data such as
electrophoresis and mass spectral data;
• Programming - develop and program tailored tools and
databases to help the proteomics analyses;
• Training - teach fundamental and practical aspects of
bioinformatics for proteomics to interested users to
leverage the more efficient use of software and research
objectives;
• Latest technologies - provide up-to-date software and
computers to the research community.
28.
28
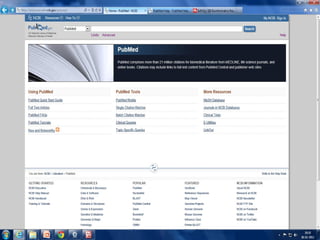
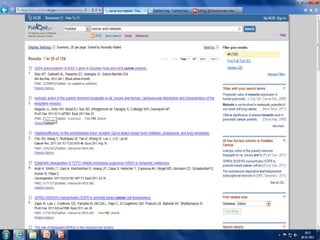
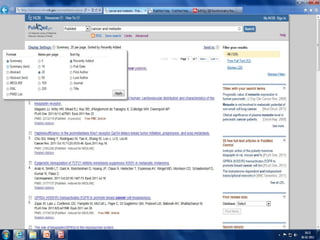
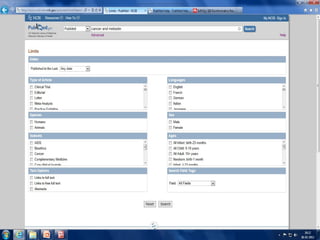
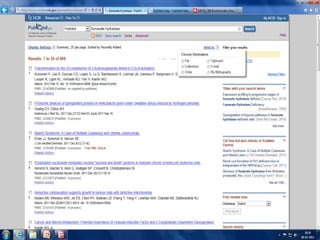
PubMed
PubMed isdatabase of citations and
abstracts for biomedical literature from
MEDLINE and additional life science journals.
Links are provided when full text versions of
the articles are available through PubMed
Central or other websites.
REFERENCES
• JONATHAN PEVSNER– BIOINFORMATICS AND
FUNCTIONAL
GENOMICS
• DAVID W. MOUNT – BIOINFORMATICS SEQUENCE
AND GENOME ANALYSIS
• JEAN MICHEL CLAVERIE & CEDRIC NOTREDAME
– BIOINFORMATICS FOR DUMMIES
• www.expasy.ch/....
• www.ncbi.nlm.nih.gov/pubmed/....
• BIOINFORMATICS – METHODS AND APPLICATIONS
BY S.C.RASTOGI AND P. RASTOGI