
Recommended
Recommended
More Related Content
What's hot
What's hot (20)
Similar to Evaluating Hype in scala
Similar to Evaluating Hype in scala (20)
Recently uploaded
Recently uploaded (20)
Evaluating Hype in scala
- 1. EVALUATING HYPE IN SCALAPere Villega (@pvillega)
- 2. EVALUATING HYPE IN SCALA - @PVILLEGA
- 3. EVALUATING HYPE IN SCALA - @PVILLEGA
- 4. EVALUATING HYPE IN SCALA - @PVILLEGA • 2016 - Free Monad • 2017 - Recursion Schemes • 2018 - Tagless Final & MTL • 2019 - ???
- 5. EVALUATING HYPE IN SCALA - @PVILLEGA
- 6. EVALUATING HYPE IN SCALA - @PVILLEGA
- 7. EVALUATING HYPE IN SCALA - @PVILLEGA • Free Monad • Tagless Final & MTL • ZIO
- 8. EVALUATING HYPE IN SCALA - @PVILLEGA A long time ago…
- 9. EVALUATING HYPE IN SCALA - @PVILLEGA
- 10. EVALUATING HYPE IN SCALA - @PVILLEGA
- 11. EVALUATING HYPE IN SCALA - @PVILLEGA
- 12. EVALUATING HYPE IN SCALA - @PVILLEGA trait UserRepositoryComponent { val userRepository: UserRepository class UserRepository { ... } } trait UserServiceComponent { this: UserRepositoryComponent => val userService: UserService class UserService { ... } } object ComponentRegistry extends UserServiceComponent with UserRepositoryComponent { val userRepository = new UserRepository val userService = new UserService }
- 13. EVALUATING HYPE IN SCALA - @PVILLEGA
- 14. EVALUATING HYPE IN SCALA - @PVILLEGA
- 15. EVALUATING HYPE IN SCALA - @PVILLEGA
- 16. EVALUATING HYPE IN SCALA - @PVILLEGA /** * Trait declaring methods that can be used to register by-name test functions that * have any result type. */ trait TestRegistration { theSuite: Suite => /** * Registers a test. * * @param testText the test text * @param testTags the test tags * @param testFun the test function */ def registerTest(testText: String, testTags: Tag*)(testFun: => Any /* Assertion */)(implicit pos: source.Position) /** * Registers an ignored test. * * @param testText the test text * @param testTags the test tags * @param testFun the test function */ def registerIgnoredTest(testText: String, testTags: Tag*)(testFun: => Any /* Assertion */)(implicit pos: source.Position) }
- 17. EVALUATING HYPE IN SCALA - @PVILLEGA
- 18. EVALUATING HYPE IN SCALA - @PVILLEGA 2016
- 19. EVALUATING HYPE IN SCALA - @PVILLEGA
- 20. EVALUATING HYPE IN SCALA - @PVILLEGA Free Monad hose domain is the category of Monad
- 21. EVALUATING HYPE IN SCALA - @PVILLEGA Free Monad hat allows us to build a very simple M
- 22. EVALUATING HYPE IN SCALA - @PVILLEGA
- 23. EVALUATING HYPE IN SCALA - @PVILLEGA https://typelevel.org/cats/datatypes/freemonad.html#what-is-free-in-theory
- 24. EVALUATING HYPE IN SCALA - @PVILLEGA • Represent stateful computations as data • Run recursive computations in a stack-safe way • Build an embedded DSL (domain-specific langu • Retarget a computation to another interpreter (u
- 25. EVALUATING HYPE IN SCALA - @PVILLEGA 1. Define an algebra of your primitive operations 2. Define your DSL by lifting your algebra into Fr 3. Write some programs in the DSL 4. Write an interpreter 5. Execute a program using the interpreter
- 26. EVALUATING HYPE IN SCALA - @PVILLEGA 1. Define an algebra of your primitive operations sealed trait KVA[A] case class Put[T](key: String, vl: T) extends KVA[Unit] case class Get[T](key: String) extends KVA[Option[T]] case class Delete(key: String) extends KVA[Unit]
- 27. EVALUATING HYPE IN SCALA - @PVILLEGA 2. Define your DSL by lifting your algebra into Free monad import cats.free.Free import cats.free.Free._ type KV[A] = Free[KVA, A] def put[T](key: String, value: T): KVStore[Unit] = liftF[KVStoreA, Unit](Put[T](key, value)) def get[T](key: String): KVStore[Option[T]] = liftF[KVStoreA, Option[T]](Get[T](key)) def delete(key: String): KVStore[Unit] = liftF(Delete(key))
- 28. EVALUATING HYPE IN SCALA - @PVILLEGA 3. Write some programs in the DSL def program: KV[Option[Int]] = for { _ <- put("wild-cats", 2) _ <- update[Int]("wild-cats", (_ + 12)) _ <- put("tame-cats", 5) n <- get[Int]("wild-cats") _ <- delete("tame-cats") } yield n
- 29. EVALUATING HYPE IN SCALA - @PVILLEGA 4. Write an interpreter def impureCompiler: KVA ~> Id = new (KVA ~> Id) { val kvs = mutable.Map.empty[String, Any] def apply[A](fa: KVA[A]): Id[A] = fa match { case Put(key, value) => kvs(key) = value () case Get(key) => kvs.get(key).map(_.asInstanceOf[A]) case Delete(key) => kvs.remove(key) () } }
- 30. EVALUATING HYPE IN SCALA - @PVILLEGA 5. Execute a program using the interpreter val result: Option[Int] = program.foldMap(impureCompiler) // put(wild-cats, 2) // get(wild-cats) // put(wild-cats, 14) // put(tame-cats, 5) // get(wild-cats) // delete(tame-cats) // result: Option[Int] = Some(14)
- 31. EVALUATING HYPE IN SCALA - @PVILLEGA http://frees.io
- 32. EVALUATING HYPE IN SCALA - @PVILLEGA • Amount of boilerplate • Performance • Learning curve (monoid, monad, natural transfo
- 33. EVALUATING HYPE IN SCALA - @PVILLEGA
- 34. EVALUATING HYPE IN SCALA - @PVILLEGA doobie programs are values. You can compose s
- 35. EVALUATING HYPE IN SCALA - @PVILLEGA 2018
- 36. EVALUATING HYPE IN SCALA - @PVILLEGA https://github.com/debasishg/typed-tagless-final
- 37. EVALUATING HYPE IN SCALA - @PVILLEGA • programs are expressions built from generic functions • operations are done directly in the target monad stack • potentially less overhead as operations are not reified as values
- 38. EVALUATING HYPE IN SCALA - @PVILLEGA 1. Define an algebra of your primitive operations 2. No need to lift your algebra, that is your DSL 3. Write some programs in the DSL 4. Write an interpreter 5. Execute a program using the interpreter
- 39. EVALUATING HYPE IN SCALA - @PVILLEGA 1. Define an algebra of your primitive operations trait KVA[F[_]] { def put[T](key: String, value: T): F[Unit] def get[T](key: String): F[Option[T]] def delete(key: String): F[Unit] }
- 40. EVALUATING HYPE IN SCALA - @PVILLEGA 3. Write some programs in the DSL def program[F[_] : Monad](alg: KVA[F]): F[Option[Int]] = for { _ <- alg.put(“wild-cats", 2) _ <- alg.update[Int]("wild-cats", (_ + 12)) _ <- alg.put("tame-cats", 5) n <- alg.get[Int]("wild-cats") _ <- alg.delete("tame-cats") } yield n
- 41. EVALUATING HYPE IN SCALA - @PVILLEGA 4. Write an interpreter class DefaultKVA[F[_]: Monad]() extends KVA[F] { val kvs = mutable.Map.empty[String, Any] def put[T](key: String, value: T): F[Unit] = { kvs(key) = value ().pure[F] } def get[T](key: String): F[Option[T]] = kvs.get(key).map(_.asInstanceOf[A]).pure[F] def delete(key: String): F[Unit]= { kvs.remove(key) ().pure[F] } }
- 42. EVALUATING HYPE IN SCALA - @PVILLEGA 5. Execute a program using the interpreter val result: Option[Int] = program[IO](new DefaultKVA()).unsafeRunSync() // put(wild-cats, 2) // get(wild-cats) // put(wild-cats, 14) // put(tame-cats, 5) // get(wild-cats) // delete(tame-cats) // result: Option[Int] = Some(14)
- 43. EVALUATING HYPE IN SCALA - @PVILLEGA Pawel Szulc - A road trip with Monads: https://www.youtube.com/watch?v=y_QHSDOVJM8
- 44. EVALUATING HYPE IN SCALA - @PVILLEGA def checkState: EitherT[StateT[List, Int, ?], Exception, String] = for { currentState <- EitherT.liftF(StateT.get[List, Int]) result <- if (currentState > 10) EitherT.leftT[StateT[List, Int, ?], String](new Exception("Too large")) else EitherT.rightT[StateT[List, Int, ?], Exception]("All good") } yield result
- 45. EVALUATING HYPE IN SCALA - @PVILLEGA def checkState[F[_]](implicit S: MonadState[F, Int], E: MonadError[F, Exception]): F[String] = for { currentState <- S.get result <- if (currentState > 10) E.raiseError(new Exception("Too large")) else E.pure("All good") } yield result
- 46. EVALUATING HYPE IN SCALA - @PVILLEGA class BlazeMetricsExampleApp[F[_]: ConcurrentEffect: Timer] { val metricsRegistry: MetricRegistry = new MetricRegistry() val metrics: HttpMiddleware[F] = Metrics[F](Dropwizard(metricsRegistry, "server")) def app: HttpApp[F] = Router( "/http4s" -> metrics(new ExampleService[F].routes), "/http4s/metrics" -> metricsService[F](metricsRegistry) ).orNotFound def stream: fs2.Stream[F, ExitCode] = BlazeServerBuilder[F] .bindHttp(8080) .withHttpApp(app) .serve }
- 47. EVALUATING HYPE IN SCALA - @PVILLEGA
- 48. EVALUATING HYPE IN SCALA - @PVILLEGA 2019
- 49. EVALUATING HYPE IN SCALA - @PVILLEGA def program[F[_] : Monad](alg: KVA[F]): F[Option[Int]] = for { _ <- alg.put(“wild-cats", 2) _ <- alg.update[Int]("wild-cats", (_ + 12)) _ <- alg.put("tame-cats", 5) n <- alg.get[Int]("wild-cats") _ <- alg.delete("tame-cats") } yield n
- 50. EVALUATING HYPE IN SCALA - @PVILLEGA package object kva { def put[T](key: String, value: T): ZIO[KVA, Nothing, Unit] } def program = for { _ <- put(“wild-cats", 2) _ <- update[Int]("wild-cats", (_ + 12)) _ <- put("tame-cats", 5) n <- get[Int]("wild-cats") _ <- delete("tame-cats") } yield n
- 51. EVALUATING HYPE IN SCALA - @PVILLEGA 1. Define an algebra of your primitive operations trait Console { def console: Console.Service } object Console { trait Service { def println(line: String): UIO[Unit] val readLine: IO[IOException, String] } }
- 52. EVALUATING HYPE IN SCALA - @PVILLEGA 2. Define your helper methods package object console { def println(line: String): ZIO[Console, Nothing, Unit] = ZIO.accessM(_.console println line) val readLine: ZIO[Console, IOException, String] = ZIO.accessM(_.console.readLine) }
- 53. EVALUATING HYPE IN SCALA - @PVILLEGA 3. Write some programs in the DSL val program: ZIO[Console, IOException, String] = for { _ <- println("Good morning, what is your name?") name <- readLine _ <- println(s"Good to meet you, $name!") } yield name
- 54. EVALUATING HYPE IN SCALA - @PVILLEGA 4. Write an interpreter trait Console { def console: Console.Service } object Console { trait Service { def println(line: String): UIO[Unit] val readLine: IO[IOException, String] } trait Live extends Console.Service { import scala.io.StdIn.readLine def println(line: String) = UIO.effectTotal(scala.io.StdIn.println(line)) val readLine = IO.effect(readLine()).refineOrDie(JustIOExceptions) } object Live extends Live }
- 55. EVALUATING HYPE IN SCALA - @PVILLEGA 5. Execute a program using the interpreter val programLive: IO[IOException, String] = program.provide(Console.Live)
- 56. EVALUATING HYPE IN SCALA - @PVILLEGA trait Console { def console: Console.Service } trait Logging { def logging: Logging.Service } trait Persistence { def persistence: Persistence.Service } ... type ProgramEnv = Console with Logging with Persistence val program1: ZIO[ProgramEnv, AppError, Unit] = ... val program2: ZIO[ProgramEnv, AppError, String] = ...
- 57. EVALUATING HYPE IN SCALA - @PVILLEGA
- 58. EVALUATING HYPE IN SCALA - @PVILLEGA https://blog.softwaremill.com/final-tagless-seen-alive-79a8d884691d
- 59. EVALUATING HYPE IN SCALA - @PVILLEGA
- 60. EVALUATING HYPE IN SCALA - @PVILLEGA In conclusion
- 61. EVALUATING HYPE IN SCALA - @PVILLEGA
- 62. EVALUATING HYPE IN SCALA - @PVILLEGA
- 63. EVALUATING HYPE IN SCALA - @PVILLEGA – QUESTIONS PLEASE :)
Editor's Notes
- Hello, I am Pere Villega, a Scala contractor working in London. First of all, thank you all for being here and to Joost and the organisers for inviting me. Much appreciated
- I have to be honest, this talk has been very problematic to assemble. See, initially I wanted to talk about MTL style and Tagless Final. I did a small lightning talk about the subject at Scala Exchange last year, so it was a good topic for a longer talk. Tagless final and MTL are a powerful way to organise your code.
- And then John killed tagless final. Thanks John. If you are here you are probably aware of all the noise around ZIO and tagless final, more so as, if I recall correctly, John was here a couple of weeks ago to talk about this. This was a big problem for me, as I prefer to do talks focussed on practical applications of concepts but suddenly I had no concept. :) (Image: https://twitter.com/hmemcpy/status/1104679168720154624?s=20)
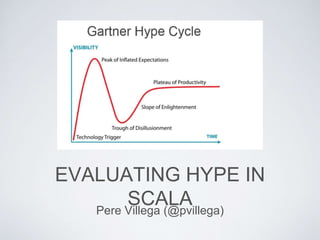
- So, ok, I needed a new talk. The last weeks have had a lot of noise in the scala community about ZIO and tagless final, opinions in favour and against John's arguments. And then I remembered this slide I had in my original talk, about trends in the Scala community. Hey, I predicted the death of tagless first ;) Looking at the dates, we can say that we developers like new toys, we can't deny it. And the community as a whole is jumping from new technique to new technique with enthusiasm, with plenty of blog posts and libraries and documentation for each new trend.
- And the thing is, at a certain level this makes sense. The reason this is happening is the same reason some companies forbid using Cats on their codebases (yes, that is a thing). We want to use idiomatic patterns when we organise our code, so that other developers in our team can identify them and work with them. But, well, as our code grows the patterns we use hit some limitations, things that make our life harder. And we look for solutions in the community, which we get from the better known voices in the community, the ones that talk on each conference and blog weekly and such.
- And there is a dark truth in this whole process. We all agree with a principle that we repeat gain and again: there is no silver bullet. Use the right tool for the job. But let's be honest: we don’t act like it, it seems that we do crave the silver bullet. We got a 1h talk + 2 blogpost about a full replacement to Tagless final and I've seen more people jumping wagon than comparing pros and cons. Guys, seriously… if you think something is not great because you have spent hundreds of hours working with it, wouldn’t you need hundreds of hours on the new concept for a decent evaluation? At least a few dozen hours?
- So what I want to do today is a quick recap on some of these patterns we, as a community, have experimented with. Revisit all these hype moments and see if they are still useful techniques, if we should really forget them and replace them with the new shiny toy in town. Before I continue, a warning: examples for these patterns will use very simplified domains. We are all aware it's with more complex code that you find the limitations of a pattern, but what we want now is a quick review and direct comparison, where complex code would make this difficult and confusing. Luckily none of these concepts (except ZIO) is new, and you can find plenty of resources out there with more complex examples if you want to explore them in depth.
- Let's start with ancient history.
- Let's go back to April 2007, where in the Scala Lounge this question was asked. Someone asking for help on how to structure his code, finding these idiomatic patterns we mentioned. (source http://www.scala-archive.org/Inheriting-static-members-td2010292.html )
- A certain Jon Pretty, whom you may have heard about, came to his rescue.
- The Cake Pattern was created, and history was made
- What is the cake pattern? Let me give you a simplified description. The core idea behind the cake pattern is that we can use the language itself, Scala, to do dependency injection instead of having to rely on half-magical libraries like Guice or Spring for DI. A better way to structure our code. This is achieved is through the use of self-types. In this simplified example, we have two components. One is a User Repository component, which is defined as a trait that has an abstract value (userRepository) and code that relies on that value being present. The second component, User Service Component, depends on another abstract value, a userService value. And it also uses a self-type to say: hey, I am also a UserRepositoryComponent, so you get access to any operations defined in UserRepositoryComponent. You can define several of these components and it is at the ‘edge of the world’ where you say: ok, I have a ComponentRegistry which will extend both traits and in here I’ll define the concrete instances for the abstract values, wiring the dependencies now, at compile time. That’s a (very simplified) explanation of the Cake Pattern
- And the community loved it. Stack overflow alone has 381 questions or answers that reference this pattern under the 'scala' tag, the most recent from January 2019 (this year!).
- You had blog posts from influential people in the community, like Jonas Boner, explaining how to use the cake pattern for dependency injection
- But when Jon celebrated the 10th anniversary, these were some of the answers. Cake Pattern is now a days considered an anti pattern. It has many downsides: Adding a new dependency may mean having to modify all the stack of traits as self-types are not inherited You end up at the edge with an object with an extremely large number of traits where you are combining everything together at once: infrastructure, domain services, persistence, business logic… it’s not initialised on a ‘peer need’ basis, but all at once. (sources https://kubuszok.com/2018/cake-antipattern/ and http://www.warski.org/blog/2011/04/di-in-scala-cake-pattern-pros-cons/ )
- Note that self-types are a valid solution for some problems. For example, this code belongs to a trait in Scala Test. It relies on self-types for its suites. The pattern is not bad per-se. There is a lesson to be learned that we will see repeated again. Cake was a staple for the Scala community for years, the solution to DI. A compile time solution vs the magic of Spring wiring so prevalent at that time, it was refreshing, new, useful. The community leaders, the ruling voices at the time thought it was a good tool and it was mass adopted, without questions, and it took long for us to realise it was not worth it, that forcing the pattern to embrace the full application and not specific cases (like ScalaTest does) wasn’t a correct solution. As a side note, I’d like to put some kind of ‘bookmark’ in your brains here, don't forget the cake pattern, we may come back to it.
- As a bonus, if you ever wondered why was it named 'the cake pattern' I'll leave you with John's explanation here.
- Let's move forward in time, to 2016. Better times where Brexit and Trump weren't the only subject in the news.
- Free Monads enter the 'mainstream' is the Scala community, appearing in most (if not all) the conferences. I'm guilty as charged to falling into that hype, too! I wrote a long blog post showing a practical approach on using Free with Cats (may be a bit outdated for the current cats version, you have been warned) Why such popularity? Because it was a novel technique (in the Scala world) which helped people organise the code. At a moment in which FP was becoming more mainstream, a way to organise your code boundaries that was ‘compliant’ with FP principles was very appreciated. Remember, we want patterns for our code structure which are useful and other developers can easily identify and work with. (see https://perevillega.com/understanding-free-monads)
- What’s a Free Monad? A Free Monad "is a construction that is left adjoint to a forgetful functor whose domain is the category of Monads and whose co-domain is the category of Endofunctors" Yeah, I don't get it either.
- A Free Monad is just a clever construction that allows us to build a very simple Monad from any functor. As a consequence, if you can get a Functor, you get a Monad. This is important.
- Monads, as well as burritos, are a way to represent and chained computations. If you can represent something as a Functor, you can then obtain for free a monad on it (Free Monad). Which means it can become part of a chain of computations. A Functor is a very simple structure, easy to create. But there is an additional magic trick in play: using Coyoneda (see https://medium.com/@olxc/yoneda-and-coyoneda-trick-f5a0321aeba4 - don’t make me explain it) you can turn any F[_] into a Functor. You can turn any F[_] in your code into a monad and use it in chains of computations, to represent business logic.
- This is the non-category-theory explanation. You can get more detailed theory behind the concept in the cats documentation at https://typelevel.org/cats/datatypes/freemonad.html#what-is-free-in-theory
- Ok, so a Free Monad is a way to turn an F[_] into a Monad. Why is that useful? Why did it become popular? Because Free provides is separation between the program definition and its execution. In particular, free monads provide a practical way to: • represent stateful computations as data, and run them • run recursive computations in a stack-safe way • build an embedded DSL (domain-specific language) • retarget a computation to another interpreter using natural transformations (see https://typelevel.org/cats/datatypes/freemonad.html) Those are things we, as FP followers, want. Separate execution of a computation from declaration allows us to reason better about it, and we can even do some optimizations before execution. Stack safety is good. Retargeting helps a lot with testing, where we can stub interactions with an external system without 3rd party libraries nor reflection magic.
- Now the question is, how do you use it? You can create your Free Monad with these easy 5 steps listed in the slide. So let’s do one, so we can see how it works. (see https://typelevel.org/cats/datatypes/freemonad.html)
- We will use the standard example used for Free monads, a key-value store. The first step is to define an algebra for our operations. We define our operations (put, get, delete) as data (case classes). We represent computations as data. Note the trait KVA (our algebra) has a ‘hole’ to look like a Functor, so we can use the magic Coyoneda trick we mentioned and obtain a Functor from it.
- The second step is to define our DSL to build applications using our algebra. This is done by lifting our KVA algebra into a Free structure, in a single line. The remaining methods are helpers for our DSL, so it is nicer to use: for example, we will call ‘put’ instead of creating the instance of case class Put[T] in the code
- Now that we have the DSL, we can use it to create a program. Note that this is a for-comprehension (requires a Monad, which we lifted our Algebra to) Also note that this code, by itself, does nothing. It just stacks case classes in a sequence of nested flatMaps. That is all. As we said, we are separating declaration of intent from execution
- We want that program to do something, so we need an interpreter (or compiler). These are implemented as Natural transformations (the ~>) which are functions that convert from one monad to another. This example maps to the Id monad, but we could map to IO for example As you can see we are pattern matching over the ADT of our algebra. We could apply nice optimisations here, like preprocessing all input and removing redundant Puts (ones with same key and value) or other changes. I mention this one as there is a talk from Luka from Typelevel (see https://typelevel.org/blog/2017/12/27/optimizing-final-tagless.html) where he shows something similar, and it seems to be a common example on capabilities of Free
- The last step is to use the interpreter to execute the program we wrote. If we executed this we would execute the operations you see in screen and return Some(14). Execution is basically a `foldMap` using our natural transformation, which means we iterate over the flatMaps of our program and we map each instance of our algebra via the natural transformation we defined before. OK, so this works, but that was a lot of code, a big chunk of boilerplate code. And it get worse if you want to use multiple algebras in your programs, which is what you usually want to do. You can see Free feels a bit cumbersome.
- There's been efforts to reduce this boilerplate. For example, FreeStyle (http://frees.io) from 47 Degrees which generates a lot of that boilerplate for you. Unfortunately the last release was on 7th Jun 2018, there’s been low activity in the repo since then, and 47 deg seems focussed on Kotlin, so we can consider it in maintenance mode
- As you can expect with Free being mentioned in this talk, after a long while of blog posts, demos, and conference talks, the bad points were pointed out. Kelley Robinson had a talk named ‘Why the Free Monad isn’t Free’ (link in the notes, I’ll share it later) and it summarised some of the negatives of Free. Boilerplate, specially when you are using multiple algebras in your programs. Performance, given you are lifting data types to operations again and again, inside a nested flatMap structure. Stack safe, but slow. And the concepts needed to use it. Yes, you can use it without knowing them all, but you will soon hit a ceiling when the compiler throws some errors at your face. We said we are trying to find "idiomatic patterns when we organise our code, so that other developers in our team can identify and work with”. Steep learning curve defeats the purpose. (see https://www.slideshare.net/KelleyRobinson1/why-the-free-monad-isnt-free-61836547)
- All that, the fact the community started pointing the flaws in Free, plus the fact that FreeStyle entered something like maintenance mode last year seems to point that the hype on Free is over. We were shown something new, we were bombarded with blog posts by community leaders, we adopted it, and we discovered it wasn’t a silver bullet. Free Monad is dead, long live Free?
- No. Free doesn’t suck. Free is a perfectly useful technique which probably you are using without knowing. How many of you use Slick, or Doobie? They are Free Monads behinds the scenes. Free is useful, but, again, is not a silver bullet and hype won’t make it one. It has its own niche where it excels, but it also has weaknesses.
- Let's move forward again, to 2018. 2 years since Free was in the spotlight, we were ready for more hype. The year of Tagless final and MTL style. Yes, you killed a 1 year old baby.
- Well, not really 1 year. In 2012 a paper was published: Typed Tagless Final Interpreters (see http://okmij.org/ftp/tagless-final/course/lecture.pdf) along a corresponding course. ``Tagless-final'' style is a general method of embedding domain-specific languages (DSL) in a typed functional language, an alternative to using ADT for this purpose (that is, an alternative to Free Monad). And the Haskell community loved it. And, as it happens, what was loved in Haskell found its way into Scala, as it seemed a better way to organise code than Free. Mind you, both Tagless final and Free Monad are equivalent on expressive power. But, as we will see (and you probably know) Tagless has some advantages By the way, the link at the bottom is not to the course itself but a Scala version Debasish created based on the original one. In case you want to go to the source of all this. (see http://okmij.org/ftp/tagless-final/index.html and https://github.com/debasishg/typed-tagless-final for scala version)
- So how does Tagless final work? How does it differ from Free? In Tagless programs are expressions, functions, instead of an ADT In Tagless the operations are executed over a Monad of your choice (IO, Task, etc) instead of having a series of natural transformations Note that in Tagless execution is still separate from program declaration. There is less overhead as you are not operating over values that you pattern match, but executing functions directly.
- So, as we did with Free, how do we use Tagless? You just follow these 4 steps. Wait, 4, there are 5 bullet points? Yes, they are the same as with free, but #2 is suddenly ‘Free’ as algebra and DSL are the same, no lifting needed. So, right out of the bat, less work to do :)
- We will implement the same logic as before to see the differences with Free more clearly. With Free we defined an ADT for our algebra, which we lifted to more user-friendly operations in step 2. Here we have a single trait with the operations defined. In Free we used an ADT with ‘a hole’ to take advantage of the Coyoneda trick, in here F represents the Monad we will use to execute
- We define our program. This is very similar to how we defined our program for Free. But in here we need to pass the algebra as a parameter (alg) and let Scala know that F is a Monad so we can flatMap over the values. The rest is almost identical.
- We want that program to do something, so we need an interpreter, as in Free. In Tagless though an interpreter is just a particular implementation of our trait. As seen in the slide. No natural transformation in play, we just execute the operations, only knowing that F is a Monad.
- The last step is to use the interpreter to execute the program we wrote. If we executed this we would execute the operations you see in screen and return Some(14). Execution means passing our interpreter (instance of the class that implement the trait) to the program, and selecting a target monad (IO) for execution. OK, so this works, and it was much less code than Free. It has its limitations, like the fact stack safety depends on the monad you use. But using multiple algebras is much simpler than with Free as we have removed all the boilerplate for lifting algebras. In Tagless it is as seamless as when Java coders program against the interface, just pass the definitions of your algebras around and use them. A lower learning curve, which means we are getting closer to the aim of having some patterns for our code structure which are useful and other developers can easily identify and work with. Which is why we tried Free on the first place.
- That said, we talked about Tagless, wherea is that MTL part we mentioned at the start? Remember? MTL (monad transformer layer) is the historical name of a concept in Haskell (where else?) that has evolved to now mean 'a final tagless encoding of common effects like state, reading from an environment, and so on.’ Just like Functor abstracts over ‘things that can be mapped’, MTL provides typeclasses abstracting over many useful patterns involving different sorts of “effects”, like ‘reading configuration’. I’d recommend you to watch this talk by Pawel as it provides a very good explanation on the concepts behind it. (see Pawel Szulc - A road trip with Monads: https://www.youtube.com/watch?v=y_QHSDOVJM8 )
- In practice, this means that code like the one in this slide which uses stacks of monads can be improved by using MTL. Monad stacks are troublesome for many reasons. The most important one is that some monads can’t compose, which causes a mine field when stacking them, to ensure it’s all proper and lawful. Another issue is code legibility, but you could fix that with some helper functions, just means more boilerplate. Another criticism is performance (each flatMap operation has to unwrap and rewrap the stack). That said, performance arguably is the less relevant issue for most of the code we write, where the slowest component is by far network or data storage. It’s generally cumbersome to use them, at least in Scala, that is why there’s been active effort to replace them.
- MTL allows us to write instead this code, in which we replace the monad stack by constraints on our effect F. The functionality is equivalent, but with clearer and more performant code.
- Tagless final is very popular. The code above belong to one of the examples of Http4s, a Scala web server in the Typelevel ecosystem. The documentation of many libraries guide you towards working in this way. It’s more user friendly for junior developers than Free. No wonder it got popular. If we want a pattern to structure programs, that is a good one.
- Does this mean Tagless has killed Free? No. We already discussed as Free is used in Doobie, for example. In Doobie we take advantage of the fact that programs are values to combine multiple ConnectionIO until we decide to execute them all at once in a single transaction at the end. This would be harder to implement with Tagless (possible as they are equivalent, but probably less convenient for the library author). Tagless is easier to implement, with less boilerplate. Being so convenient it is a great choice for mapping higher level business concepts, in areas where we want to combine multiple algebras easily to define the business rules. With free doing that is painful, but Tagless, it is trivial. That’s why libraries like Http4s, which you’d use as underlying library to implement your business rules onto, use Tagless Final in their examples and not Free. There is no silver bullet. Each technique has its niche.
- During all the previous slides we were still in 2018, following the 'pattern of the year'. But John decided 2019 needed a new concept. Tagless was boring after being talked so much about, so he killed it.
- Now, I'll be honest: I've not had time to play with ZIO and John's examples since release. It’s been too recent and fiscal year in UK finishes at the end of March (plus Brexit, d’oh). The consequence is that I can’t have an opinion on ZIO, because I’ve not been able to use it as to build one. I understand that ZIO looks interesting as initially it feels like a mechanism to reduce some boilerplate even more. We go from the code above, using Tagless…
- … to this code. The program code is much simpler, easier to read. Granted, we are cheating a bit by using some helper methods defined in a package object, like when we lifted our DSL in step 2 in Free, but this step is easier than in Free. It may still be a worthy trade vs Tagless. As I said I didn’t have time to build anything with it, but we can try to follow the 5 step pattern I did before with the code John published in his blog post. Note this may not be 100% correct due to lack of experience with it.
- Using John’s example of writing to Console, our algebra would be this one, a service to interact with the Console with 2 methods: println and readLine. I put the code as John shows it in the blog post, thus the nesting in the object. Not trying to make it look more complex by nesting it, it’s a direct copy paste :)
- The code itself doesn’t need any lifting, but John explains there is an optional step to make the service easier to use, defining some helper methods. This looks to me similar to step #2 when we use Free, in which we create helper methods to avoid using the ADT algebra directly. Granted, they are much more necessary in Free, but if we count boilerplate this may be equivalent as you will probably end up creating these methods to have cleaner code.
- Now that we have the DSL, we can use it to create a program. We use the helper methods to define a program that interact with the console.
- Step 4 is to write an interpreter. In the example John writes the interpreter inside the companion object of Console, so I copy the code as is. I would expect this is just a preference, but I am not sure.
- The last step is to use the interpreter to execute the program we wrote. This returns a IO monad we can then run, as we get with Tagless Final implementation. From this small experiment, it seems we may need to write some more boilerplate than with Tagless Final (step 2), but that is not mandatory. They feel quite equivalent, and not having to pass F[_] across the algebra may really be a win.
- That said, I was reading both of John’s blog posts on ZIO to get some opinion on it, and something caught my eye. This code is from the blog John wrote. Rings a bell? It should. A hint, remember when I said at the start of the talk that I’d like you to put a bookmark on a section of the talk? Yes, it was about this. The stack in ProgramEnv is pretty darn similar to the Cake Pattern. (see http://degoes.net/articles/zio-environment and http://degoes.net/articles/testable-zio) something caught my eye.
- And it seems I am not the only one to see it this way. Adam Warski of Software Mill fame also mentioned this in his last blog post. We may have come full circle, Tagless died at the hands of the Cake Pattern. Jon Pretty was right all along.
- Don't take me wrong, I'm not saying ZIO is bad, as at the very least ZIO is making people rethink Tagless and the limitations it may have, and how to improve on it. Adam Warski in his excellent post has pointed how ZIO is great for detailed effect tracking, while Tagless Final is great at constraining effect wrappers. Each one is a choice with consequences. For example, as people have pointed out, Using only ZIO types you can not restrict ZIO capabilities. Every method has access to everything, be it concurrency, configuration, etc. On the other hand, ZIO provides capabilities Tagless doesn’t. It’s a trade off. (see https://blog.softwaremill.com/final-tagless-seen-alive-79a8d884691d)
- We should stop being driven by hype and looking for silver bullets. John’s talk was released on 25th February 2019. That was Monday, 2 weeks ago (today is 14th March 2019). His tweets about the subject raised a wave of excited developers proclaiming this was a revolution and we should all use it right now. We want to use idiomatic patterns when we organise our code, so that other developers in our team can identify and work with. But, as history has shown (hello Cake Pattern) it may take a while for us to realise the downsides of an approach. We should slow down a bit and devote some time to use this before forming strong opinions. If you have an opinion on Tagless after hundreds of hours of use, maybe you need at least some tens of hours of use of ZIO to understand where it works and where it doesn’t
- So, to finish this
- If we want to kill something, we should be killing hype and our silver bullet obsession. ZIO may be an amazing library which will change the way we structure applications. And the rotating environment may become a de facto way of coding in Scala. Or maybe (most likely) it will find a niche in which it excels, like Free has done with lower level libraries, or Tagless for domain modelling. And outside of which we won't use it. There is no need to fall onto the hype and rewrite your code base. It's a tool. A new one. Probably a great one. Experiment with it, learn about it, and decide if it fits your needs. Use ZIO as much as you want. But don't dismiss tagless final. Or Free. Don’t limit yourself and stop using them just because ZIO exists. Or because I say so. There is no silver bullet, each tool has a place.
- And I’m done, but before I finish, usually people in here they say they are hiring. I am not as I am a freelancer, but we have a team of experienced contractors in UK, some of which you may know. If your company wants expert developers and is open to remote work, contact me and I’ll put you in touch :)
- And, now we are done.