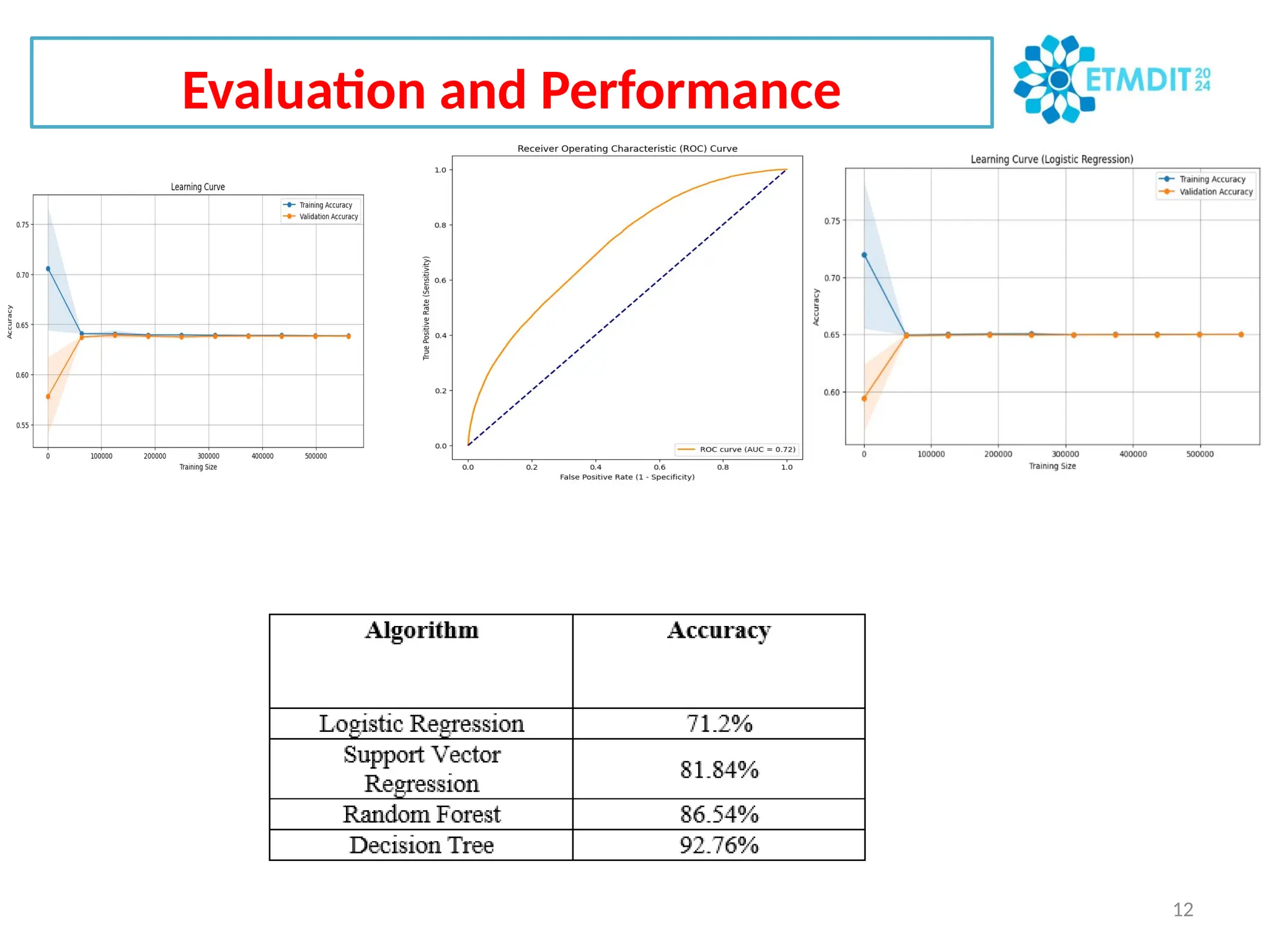
The document outlines a study presented at the ETMDIT 2024 conference focused on Twitter sentiment analysis using various machine learning algorithms. It details the methodology, including data preprocessing, feature extraction, and evaluation metrics, while emphasizing the importance of understanding nuanced emotions and ensuring ethical considerations. Key findings indicate that logistic regression performed well, achieving high accuracy, while other algorithms revealed potential for improvement and challenges such as overfitting.



























![Sentiment-Analysis-on-Twitter-Data[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/sentiment-analysis-on-twitter-data1-250819154942-301b5a33-thumbnail.jpg?width=640&height=640&fit=bounds)









































