Download to read offline





















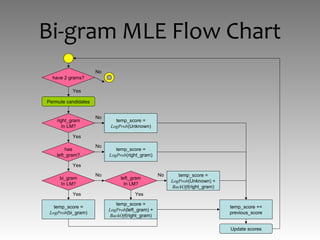
![INPUT input_syllables; len = Length(input_syllables); Load(language_model);
scores[len + 1]; tracks[len + 1]; words[len + 1];
FOR i = 0 TO len
scores[i] = 0.0; tracks[i] = -1; words[i] = "";
FOR index = 1 TO len
best_score = 0.0; best_prefix = -1; best_word = "";
FOR prefix = index - 1 TO 0
right_grams[] = Homophones(Substring(input_syllabes, prefix, index - prefix));
FOR EACH right_gram IN right_grams[]
IF right_gram IN language_model
left = tracks[prefix];
IF left >= 0 AND left != prefix
left_grams[] = Homophones(Substring(input_syllables, left, prefix - left));
FOR EACH left_gram IN left_grams[]
temp_score = 0.0;
bigram = left_gram + " " + right_gram;
IF bigram IN language_model
bigram_score = LogProb(bigram);
temp_score += bigram_score;
ELSE IF left_gram IN language_model
bigram_backoff = LogProb(left_gram) + BackOff(right_gram);
temp_score += bigram_backoff;
ELSE
temp_score += LogProb(Unknown) + BackOff(right_gram);
temp_score += scores[prefix];
Scoring
ELSE
temp_score = LogProb(right_gram);
Scoring
ELSE
temp_score = LogProb(Unknown) + scores[prefix];
Scoring
scores[index] = best_score; tracks[index] = best_prefix_index; words[index] = best_prefix;
IF tracks[index] == -1
tracks[index] = index - 1;
boundary = len; output_words = "";
WHILE boundary > 0
output_words = words[boundary] + output_words;
boundary = tracks[boundary];
RETURN output_words;
SUBROUTINE Scoring
IF best_score == 0.0 OR temp_score > best_score
best_score = temp_score;
best_prefix = prefix;
best_word = right_gram;
Bi-gram Syllable-to-Word](https://image.slidesharecdn.com/elute-150621092506-lva1-app6892/85/ELUTE-24-320.jpg)





This document discusses natural language processing and text segmentation. It introduces ELUTE (Essential Libraries and Utilities of Text Engineering) and some of its Chinese language processing tools. It then discusses word segmentation algorithms like maximum matching, hidden Markov models, and conditional random fields. Finally, it talks about building language models and the importance of having a large corpus to train models on.






















































