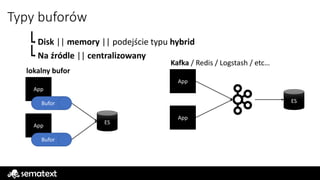
Typy buforów
Disk ||memory || podejście typu hybrid
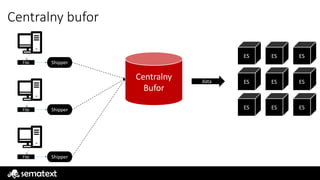
Na źródle || centralizowany
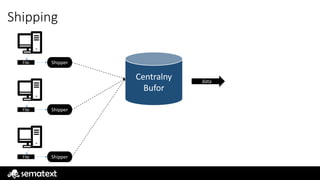
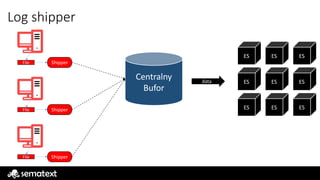
App
Bufor
App
Bufor
lokalny bufor
App
App
Kafka / Redis / Logstash / etc…
ES
ES
Dlaczego Apache Kafka?
Szybkai łatwa w użyciu
Łatwość skalowania
Fault tolerant & highly available
Wsparcie streamingu
Działa w modelu publish/subscribe
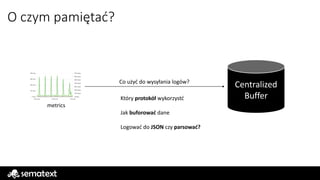
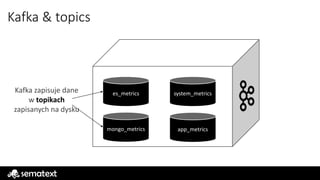
O czym pamiętaćkorzystając z Kafki
Skaluje się poprzez dodawanie partycji nie wątków
Więcej IOPS == lepiej
Liczba konsumentów powinna być równa liczbie partycji
Repliki wyorzystywane tylko do HA & FT
Offset zapisywany jest per konsumer
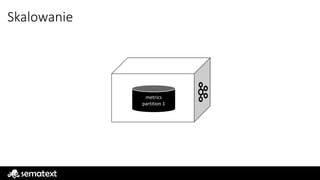
Elasticsearch – architekturaklastra
client
client
client
data
data
data
data
data
data
master
master
master
ingest
ingest
ingest
25.
Pamiętaj o dedykowanychmasterach
client
client
client
data
data
data
data
data
data
master
master
master
discovery.zen.minimum_master_nodes -> N/2 + 1 master eligible nodes
ingest
ingest
ingest
26.
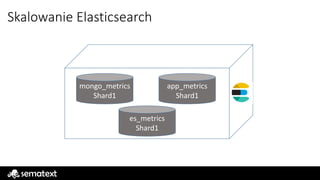
Elasticsearch – Indeksy
Index– logiczne miejsce dla danych
Index – może być porównany do tabeli w DB
Index – zbudowany z jednego lub więcej shardów
Index – może by rozproszony
Jeden duży indexto zły pomysł
Niewystarczająca wydajność dla timebased data
Indeksowanie zwalnia wraz ze wzrostem ilości danych
Coraz większy koszt merge
Delete by query konieczne do kontroli retencji danych
33.
Dzienne indeksy todobry start
2017.11.16 2017.11.17 2017.11.20 2017.11.21. . .
Indeksowanie jest szybsze na małych indeksach
Usuwanie danych jest tanie
Wyszukiwanie tylko na danych które chcemy
Statyczne indeksy są “cache friendly”
indexing
most searches
34.
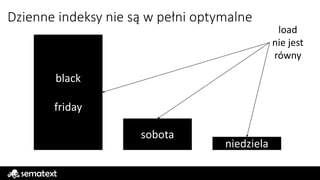
Dzienne indeksy niesą w pełni optymalne
black
friday
sobota
niedziela
load
nie jest
równy
35.
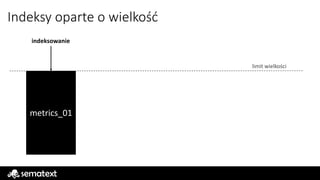
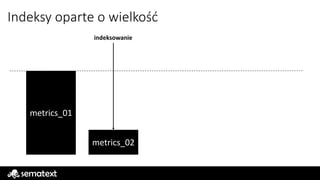
Indeksy oparte owielkość
limit wielkości
metrics_01
indeksowanie
36.
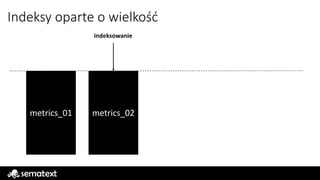
Indeksy oparte owielkość
limit wielkości
metrics_01
indeksowanie
Indeksy oparte owielkość
Przewidywalna wydajność
Lepszy balans danych
Mniej shardów
Łatwiejsza obsługa nagłego wzrostu danych
Mniejsze koszty poprzez lepsze wykorzystanie sprzętu
41.
Elasticsearch - konfiguracja
Trzymajindex.refresh_interval na wartości maksymalnej
1 sec -> 100%, 5 sec -> 125%, 30 sec -> 175%
Tuning merge policy:
- możliwy ze względu na use-case
- segments_per_tier -> wyżej
- max_merge_at_once-> wyżej
- max_merged_segment -> niżej
Prefiks do powyższych
index.merge.policy
} szybsze
indeksowanie
42.
Elasticsearch - optymalizacja
Zewzględu na dane oparte o czas możemy optymalizować
client
client
client
data
data
data
data
data
data
master
master
master
ingest
ingest
ingest
43.
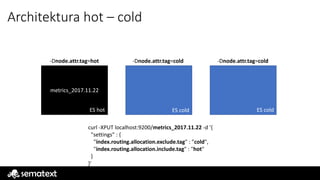
Architektura hot –cold
ES hot ES cold ES cold
-Dnode.attr.tag=hot -Dnode.attr.tag=cold -Dnode.attr.tag=cold
44.
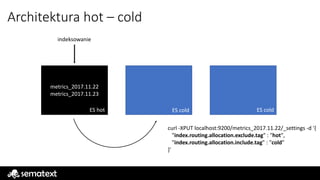
Architektura hot –cold
metrics_2017.11.22
ES hot ES cold ES cold
-Dnode.attr.tag=hot -Dnode.attr.tag=cold -Dnode.attr.tag=cold
curl -XPUT localhost:9200/metrics_2017.11.22 -d '{
"settings" : {
"index.routing.allocation.exclude.tag" : "cold",
"index.routing.allocation.include.tag" : "hot"
}
}'
45.
Architektura hot –cold
metrics_2017.11.22
ES hot ES cold ES cold
indeksowanie
46.
Architektura hot –cold
metrics_2017.11.22
metrics_2017.11.23
ES hot ES cold ES cold
indeksowanie
47.
Architektura hot –cold
metrics_2017.11.22
metrics_2017.11.23
ES hot ES cold ES cold
indeksowanie
curl -XPUT localhost:9200/metrics_2017.11.22/_settings -d '{
"index.routing.allocation.exclude.tag" : "hot",
"index.routing.allocation.include.tag” : "cold"
}'
48.
Architektura hot –cold
metrics_2017.11.23 metrics_2017.11.22
ES hot ES cold ES cold
indeksowanie
49.
Hot – coldarchitecture
metrics_2017.11.23
metrics_2017.11.24
metrics_2017.11.22
ES hot ES cold ES cold
indeksowanie
50.
Hot – coldarchitecture
metrics_2017.11.23
metrics_2017.11.24
metrics_2017.11.22
ES hot ES cold ES cold
indeksowanie
51.
Hot – coldarchitecture
metrics_2017.11.24 metrics_2017.11.22 metrics_2017.11.23
ES hot ES cold ES cold
indeksowanie
52.
Hot – coldarchitecture
Hot ES Tier
CPU
I/O
Cold ES Tier
RAM
I/O
ES cold
Cold ES Tier
RAM
I/O
53.
Wymagania Elasticsearch clientnode
client
client
client
data
data
data
data
data
data
master
master
master
ingest
ingest
ingest
54.
Wymagania Elasticsearch ingestnode
client
client
client
data
data
data
data
data
data
master
master
master
ingest
ingest
ingest
55.
Wymagania Elasticsearch masternode
client
client
client
data
data
data
data
data
data
master
master
master
ingest
ingest
ingest