9
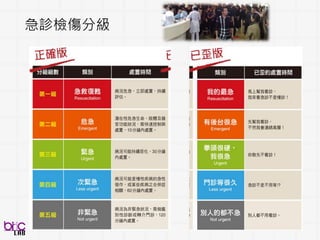
Emotion
Health Care
Education
Voice Recognition
Symptomdiagnosis
Behavior Activity
Image Recogn
Medical
IBM Pathway Genomics
Detection of Diabetic
Retinopathy in Retinal
Fundus Photographs
customer behavior
Medical Imaging
Genomic Medicine
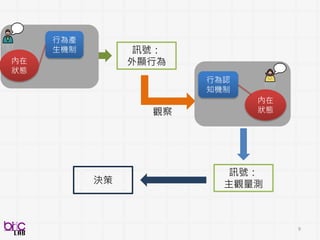
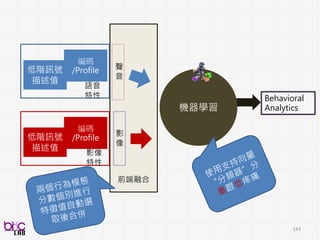
跨領域整合 – 與人相關
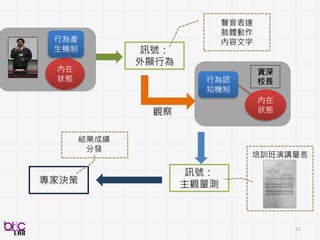
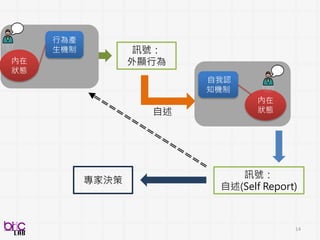
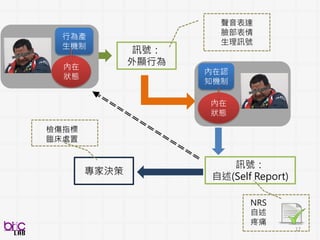
12
Seek a windowinto human mind and traits…
…through engineering approach
S. Narayanan and P. G. Georgiou, “Behavioral signal processing: Deriving human behavioral informatics
from speech and language," Proceedings of the IEEE, vol. 101, no. 5, pp. 1203–1233, 2013.
13.
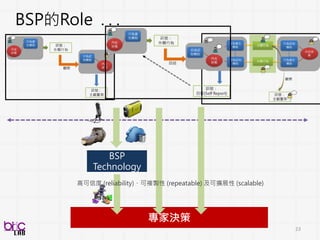
13
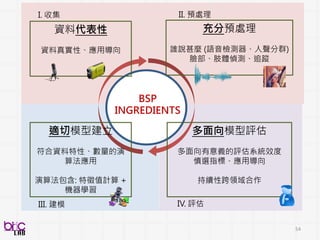
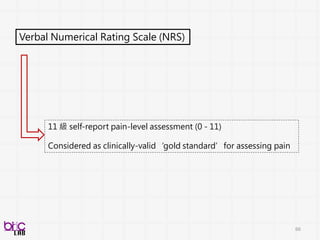
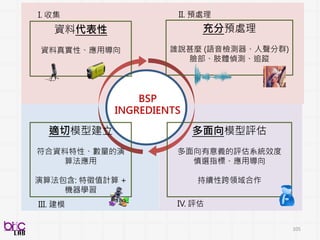
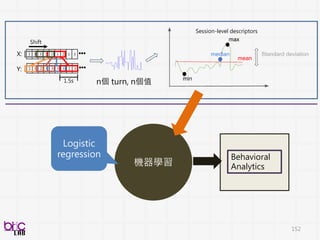
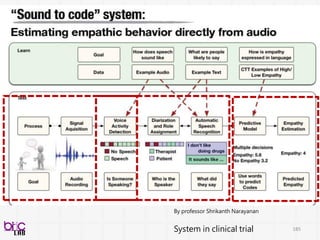
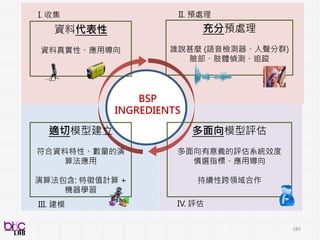
Behavioral Signal Processing(BSP)
Compute Human Behavior Traits and States for Domain Experts Decision Making
• Help experts to do things they know in a more efficient manner at scale
• Develop novel behavioral analytics framework for possible scientific discovery
from qualitative to quantitative . . .
through verbal and non-verbal behavioral cues . . .
QUANTITATIVE:
QUANTITATIVE EVIDENCE DIRECTLYFROM MEASURABLE SIGNALS
EFFICIENCY :
HELP DO THINGS THAT EXPERTS KNOW TO DO WELL MORE
EFFICIENTLY, CONSISTENTLY & AT SCALE
SUPPLMENTARY:
COMPLEMENT WITH GOLD STANDARD METHOD WHEN APPROPRIATE
POSSIBILITY:
TOOLS FOR NOVEL ACTIONABLE INSIGHT DISCOVERY
33
COMPUTING BEHAVIORAL TRAITS & STATES FOR DECISION MAKING & ACTION
…aim..
34.
34
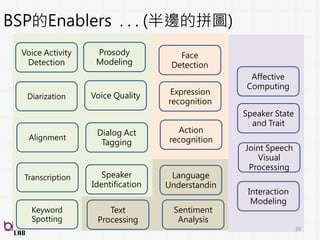
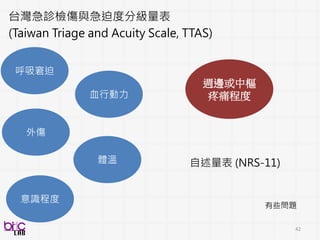
BSP的Enablers . .. (半邊的拼圖)
Text
Processing
Voice Activity
Detection
Alignment
Transcription
Keyword
Spotting
Prosody
Modeling
Voice QualityDiarization
Speaker
Identification
Dialog Act
Tagging
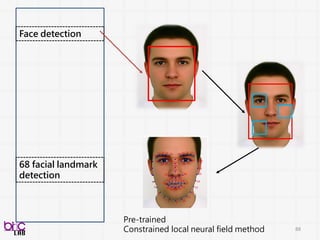
Face
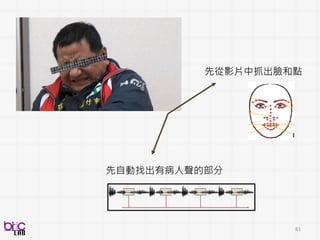
Detection
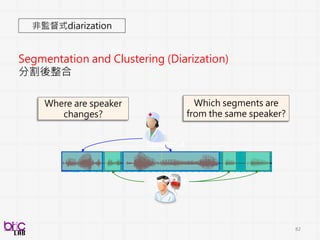
Expression
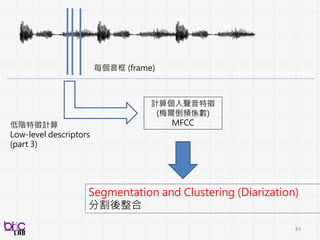
recognition
Action
recognition
Language
Understandin
Affective
Computing
Speaker State
and Trait
Joint Speech
Visual
Processing
Interaction
Modeling
Sentiment
Analysis
35.
35
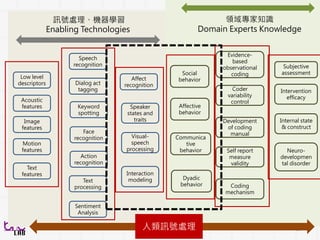
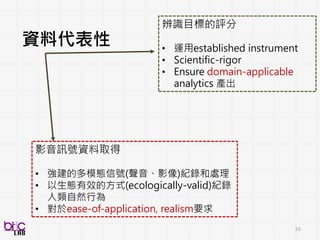
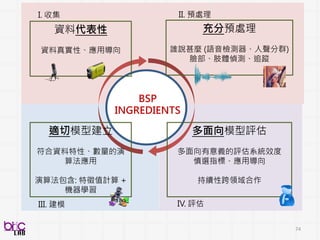
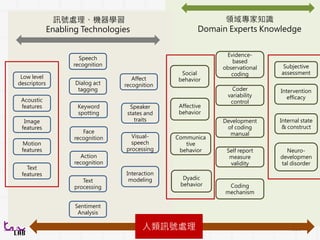
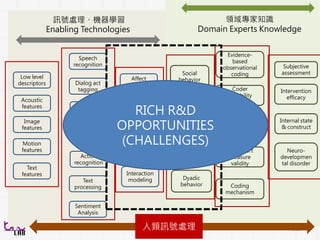
訊號處理、機器學習
Enabling Technologies
領域專家知識
Domain ExpertsKnowledge
Low level
descriptors
Acoustic
features
Motion
features
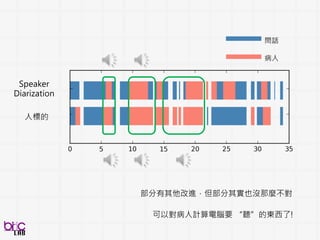
Text
features
Image
features
Speech
recognition
Face
recognition
Action
recognition
Dialog act
tagging
Keyword
spotting
Text
processing
Sentiment
Analysis
Affect
recognition
Speaker
states and
traits
Visual-
speech
processing
Interaction
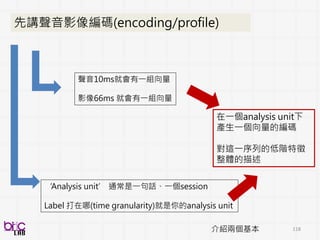
modeling
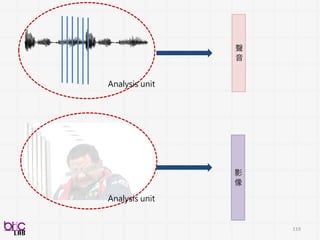
Subjective
assessment
Internal state
& construct
Neuro-
developmen
tal disorder
Evidence-
based
observational
coding
Intervention
efficacy
Coder
variability
control
Development
of coding
manual
Self report
measure
validity
Coding
mechanism
Social
behavior
Affective
behavior
Communica
tive
behavior
Dyadic
behavior
人類訊號處理
40
Computational Methods thatModel Human Behavior Signals
• Manifested in Overt and Covert Cues
• Processed and Used by Humans Explicitly or Implicitly
• Facilitate Human Analysis and Decision Making
Outcome of Behavioral Signal Processing
• Behavioral Analytics
QUANTIFYING HUMAN EXPRESSED BEHAVIOR AND
HUMAN “FELT SENSE”
DERIVING INTERPRETABLE BEHAVIOR ANALYTICS
FROM DATA FOR ACTIONAL INSIGHTS
56
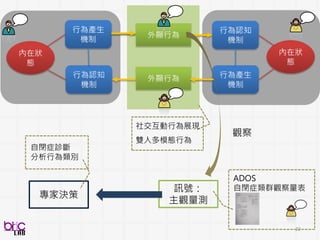
social-communicative neurodevelopmental disorder
•Prevalence: 1 in 68 children (1 in 42 males) diagnosed [CDC2014]
• ASD: “Spectrum” disorder due to the extreme heterogeneity
• Intervention leads to improved outcomes
BSP in Autism 中的角色?
What is Autism?
57.
57
ROLE OF BSP?
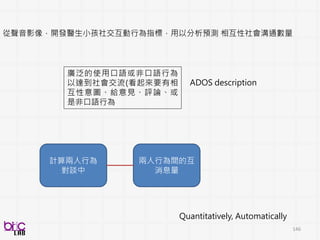
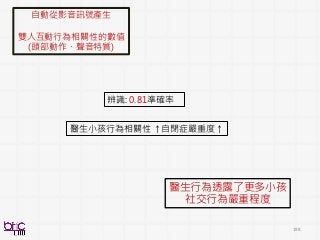
自動的分析醫生小孩在ADOS診斷中互動中social and
interactive 行為
AIM?
• Analysis at scale
• Quantitative evidence from signals
• New finding beyond current status-quo
in psychiatry (?)
60
Can we?
Automatic measuringspontaneous social (verbal/nonverbal) behavior between
clinician and child predicting the child rating of atypical amount of social
reciprocal communication
from qualitative to quantitative . . .
through verbal and non-verbal behavioral cues . . .
從聲音影像,開發醫生小孩社交互動行為指標,用以分析預測 相互性社會溝通數量
69
where
when
how
BIIC:無聲隔離室
本來:無限制國家教育院的教室
只好:盡量不要發聲的教室
Ensure current systemis not altered too much at the BEGINNING
at-scale, ease-of-application is crucial
在ecological validity & quality control 之中有拿捏
BIIC:每個校長在培訓班中的考試
本來:無
只好:在人力可以範圍內全部錄
BIIC:耳麥、多軌錄音、臉部、肢體動作,
Kinect、全部synchronized
本來:無器材、要可以用簡單人力做
只好:上半身錄影外接麥克風收音
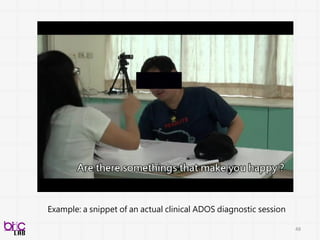
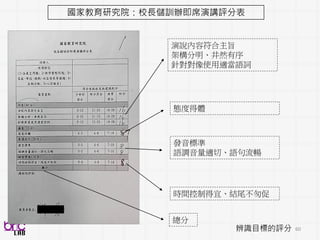
Autism Diagnostic ObservationSchedule [Lord 2001]
• Subject interacts with a psychologist for ~45 minutes
• Current gold standard, research-level observational coding
• Psychologists are trained using stringent training protocol
• Semi-structured assessment in eliciting socio-communicative
behavior of the ASD children for diagnostics
• Multiple subparts events (14) on rating of a wide range number of
socio-communicative behavior (28)
84
98
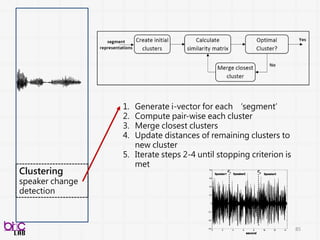
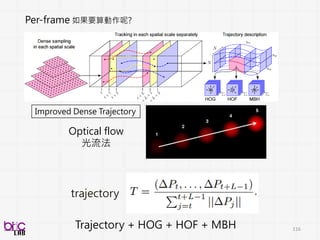
Clustering
speaker change
detection
1. Generatei-vector for each ‘segment’
2. Compute pair-wise similarity each cluster
3. Merge closest clusters
4. Update distances of remaining clusters to
new cluster
5. Iterate steps 2-4 until stopping criterion is
met
126
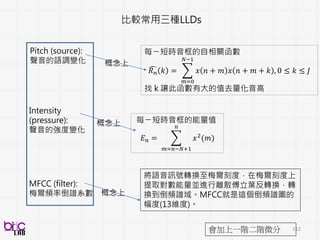
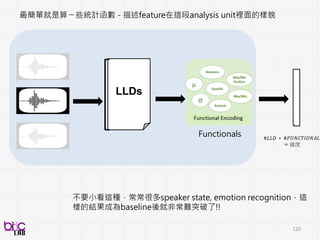
比較快可以上手算
Versatile and FastAudio Feature
Extractor
Open-Source and Cross-platform
Abundant speech-related features
Signal energy Loudness、
Mel-spectra、MFCC、PLP-
CC、Pitch
Audio I/O
Supported A lot I/O formats: WEKA
HTK LibSVM
可直接視覺化
稍微容易一點
PraatOpensmile
其實還很多啦 . . .
127.
127
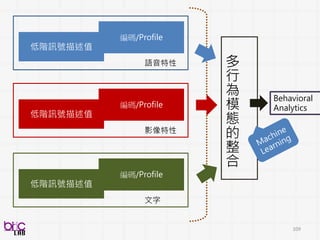
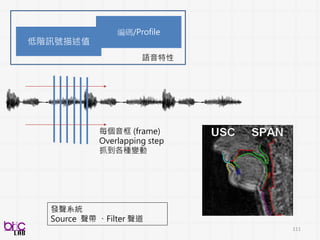
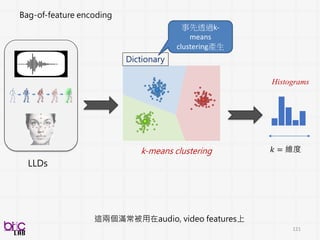
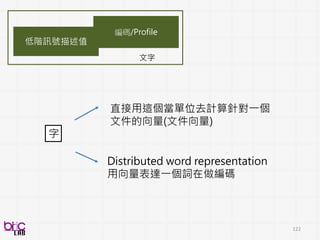
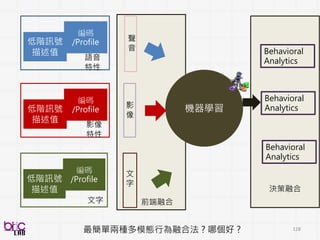
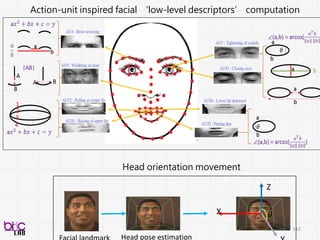
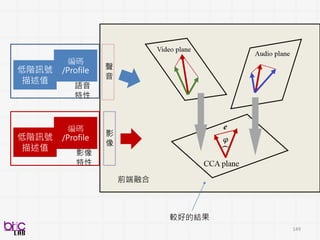
低階訊號描述值
編碼/Profile
影像特性
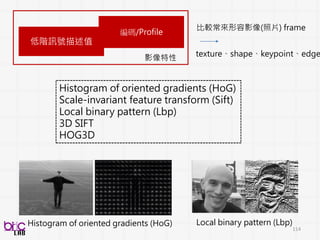
Histogram of orientedgradients (HoG)
Scale-invariant feature transform (Sift)
Local binary pattern (Lbp)
3D SIFT
HOG3D
texture、shape、keypoint、edge
比較常來形容影像(照片) frame
Histogram of oriented gradients (HoG) Local binary pattern (Lbp)
137
Term Weighting Method
asimplifying representation by term count
Term Frequency
How important (or
informative) a word in a document.
Inverse Document Frequency
How important (or
informative) a word in the corpus.
𝑡𝑓𝑡,𝑑
=
𝑛 𝑡,𝑑
𝑘 𝑛 𝑘,𝑑
𝑖𝑑𝑓𝑡,𝐷
= log
𝑁
1 + 𝑑 ∈ 𝐷 ∶ 𝑡 ∈ 𝑑
X
Term Frequency–Inverse Document Frequency (TF-IDF)
有時候就很有效了
138.
138
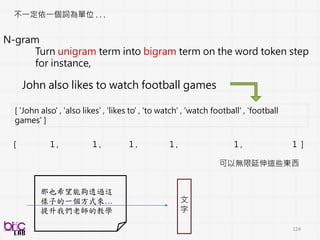
不一定依一個詞為單位 . ..
N-gram
Turn unigram term into bigram term on the word token step
for instance,
John also likes to watch football games
[ 'John also' , 'also likes' , 'likes to' , 'to watch' , 'watch football' , 'football
games' ]
[ 1 , 1 , 1 , 1 , 1 , 1 ]
可以無限延伸這些東西
那也希望能夠透過這
樣子的一個方式來…
提升我們老師的教學
文
字
139.
139
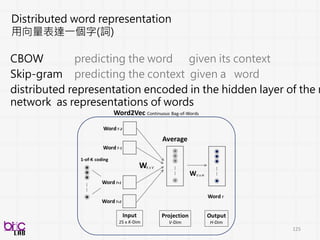
Distributed word representation
用向量表達一個字(詞)
CBOWpredicting the word given its context
Skip-gram predicting the context given a word
distributed representation encoded in the hidden layer of the neural
network as representations of words
164
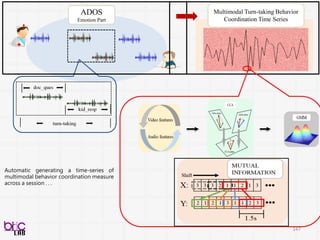
ADOS
Emotion Part
Multimodal Turn-takingBehavior
Coordination Time Series
Automatic generating a time-series of
multimodal behavior coordination measure
across a session . . .
167
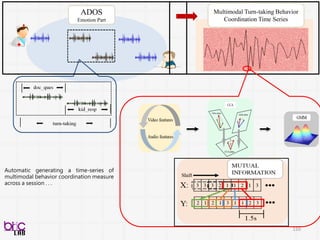
ADOS
Emotion Part
Multimodal Turn-takingBehavior
Coordination Time Series
Automatic generating a time-series of
multimodal behavior coordination measure
across a session . . .
189
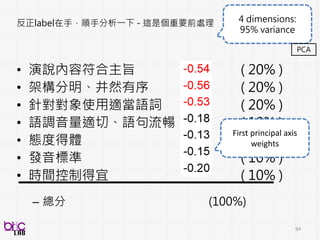
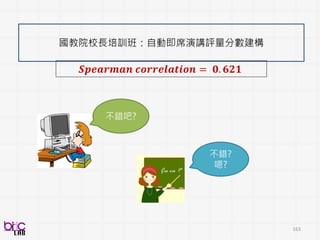
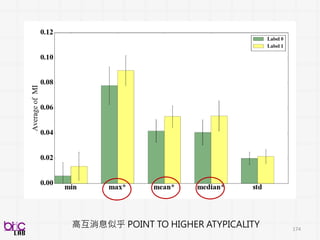
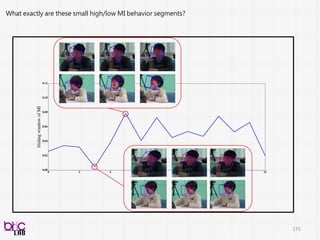
準確率又有明顯提升
• 個案研究
• 學校校務發展計畫
•教育參觀心得
• 生活札記
融入哪些測驗培訓評量對於建構演
講評分會有顯著效果 ?
沒有紙筆測驗
喔!
An actionable insights that were not clear before
Hence, project continue…
197
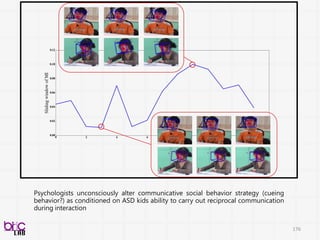
Psychologists unconsciously altercommunicative social behavior strategy (cueing
behavior?) as conditioned on ASD kids ability to carry out reciprocal communication
during interaction
200
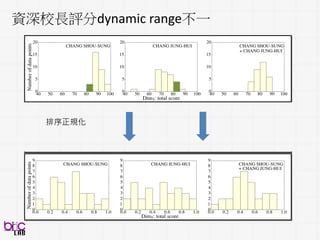
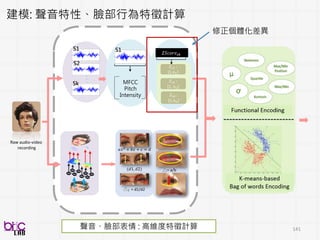
Descriptor’s
Included
Child Prosody PsychProsody Child and Psych
Prosody
Spearman’s ρ 0.64*** 0.79*** 0.67***
Psychologists acoustics at least as predictive of child ASD severity ratings
跟以前英文ADOS發現有類似!
[1] Daniel Bone, Chi-Chun Lee, Matthew P. Black, Marian E. Williams, Pat Levitt, Sungbok Lee, and Shrikanth Narayanan, "The Psychologist as
an Interlocutor in Autism Spectrum Disorder Assessment: Insights from a Study of Spontaneous Prosody", Journal of Speech, Language, and
Hearing Research, 2014, 57(4), 1162-1177.
Hard to obtained scientific insights without such behavioral analytics for
domain experts
NEED MORE VERIFICATION
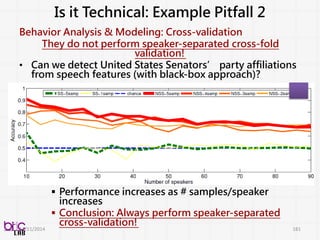
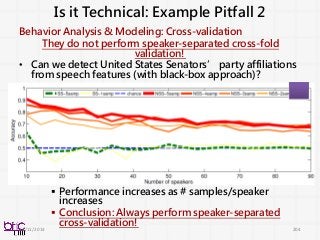
Is it Technical:Example Pitfall 2
Behavior Analysis & Modeling: Cross-validation
They do not perform speaker-separated cross-fold
validation!
• Can we detect United States Senators’ party affiliations
from speech features (with black-box approach)?
Performance increases as # samples/speaker
increases
Conclusion: Always perform speaker-separated
cross-validation!
20411/11/2014
212
Behavioral Signal Processing(BSP)
Compute Human Behavior Traits and States for Domain Experts Decision Making
• Help experts to do things they know in a more efficient manner at scale
• Develop novel behavioral analytics framework for possible scientific discovery
from qualitative to quantitative . . .
through verbal and non-verbal behavioral cues . . .
Transformative effort . . .
213.
213
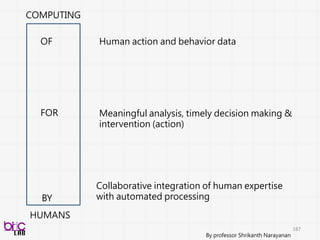
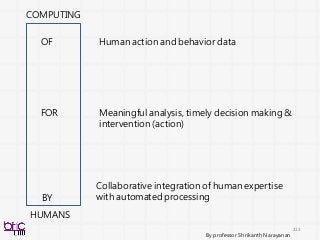
OF
FOR
BY
COMPUTING
HUMANS
Human action andbehavior data
Meaningful analysis, timely decision making &
intervention (action)
Collaborative integration of human expertise
with automated processing
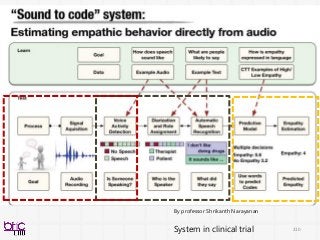
By professor Shrikanth Narayanan
214.
214
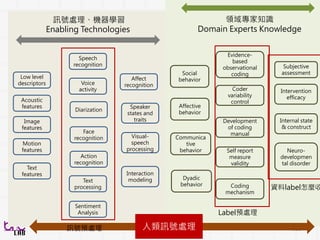
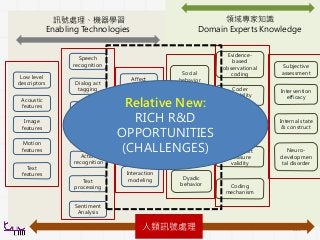
訊號處理、機器學習
Enabling Technologies
領域專家知識
Domain ExpertsKnowledge
Low level
descriptors
Acoustic
features
Motion
features
Text
features
Image
features
Speech
recognition
Face
recognition
Action
recognition
Dialog act
tagging
Keyword
spotting
Text
processing
Sentiment
Analysis
Affect
recognition
Speaker
states and
traits
Visual-
speech
processing
Interaction
modeling
Subjective
assessment
Internal state
& construct
Neuro-
developmen
tal disorder
Evidence-
based
observational
coding
Intervention
efficacy
Coder
variability
control
Development
of coding
manual
Self report
measure
validity
Coding
mechanism
Social
behavior
Affective
behavior
Communica
tive
behavior
Dyadic
behavior
人類訊號處理
Relative New:
RICH R&D
OPPORTUNITIES
(CHALLENGES)






































![56
social-communicative neurodevelopmental disorder
• Prevalence: 1 in 68 children (1 in 42 males) diagnosed [CDC2014]
• ASD: “Spectrum” disorder due to the extreme heterogeneity
• Intervention leads to improved outcomes
BSP in Autism 中的角色?
What is Autism?](https://image.slidesharecdn.com/bspdatasci2016-jeremy-161029145502/85/DSC-2016-56-320.jpg)


















![Autism Diagnostic Observation Schedule [Lord 2001]
• Subject interacts with a psychologist for ~45 minutes
• Current gold standard, research-level observational coding
• Psychologists are trained using stringent training protocol
• Semi-structured assessment in eliciting socio-communicative
behavior of the ASD children for diagnostics
• Multiple subparts events (14) on rating of a wide range number of
socio-communicative behavior (28)
84](https://image.slidesharecdn.com/bspdatasci2016-jeremy-161029145502/85/DSC-2016-84-320.jpg)





















![138
不一定依一個詞為單位 . . .
N-gram
Turn unigram term into bigram term on the word token step
for instance,
John also likes to watch football games
[ 'John also' , 'also likes' , 'likes to' , 'to watch' , 'watch football' , 'football
games' ]
[ 1 , 1 , 1 , 1 , 1 , 1 ]
可以無限延伸這些東西
那也希望能夠透過這
樣子的一個方式來…
提升我們老師的教學
文
字](https://image.slidesharecdn.com/bspdatasci2016-jeremy-161029145502/85/DSC-2016-138-320.jpg)







![Raw audio-video
recording
S1
S2
Sk ... MFCC
Pitch
Intensity
𝑍 𝑠1 :
[1,𝑛1]
𝑍𝑆𝑐𝑜𝑟𝑒𝑠𝑘
𝑍 𝑠2 :
[1, 𝑛2]
𝑍 𝑠𝑘 :
[1,𝑛 𝑘]
156
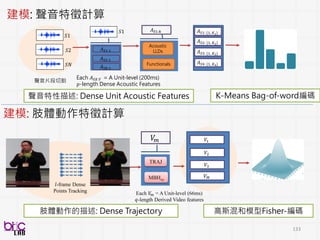
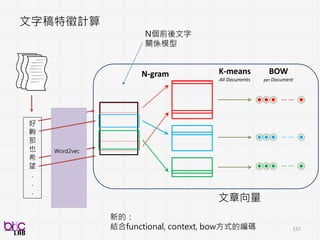
建模: 聲音特性、臉部行為特徵計算
聲音、臉部表情 : 高維度特徵計算
S1
修正個體化差異](https://image.slidesharecdn.com/bspdatasci2016-jeremy-161029145502/85/DSC-2016-156-320.jpg)























![200
Descriptor’s
Included
Child Prosody Psych Prosody Child and Psych
Prosody
Spearman’s ρ 0.64*** 0.79*** 0.67***
Psychologists acoustics at least as predictive of child ASD severity ratings
跟以前英文ADOS發現有類似!
[1] Daniel Bone, Chi-Chun Lee, Matthew P. Black, Marian E. Williams, Pat Levitt, Sungbok Lee, and Shrikanth Narayanan, "The Psychologist as
an Interlocutor in Autism Spectrum Disorder Assessment: Insights from a Study of Spontaneous Prosody", Journal of Speech, Language, and
Hearing Research, 2014, 57(4), 1162-1177.
Hard to obtained scientific insights without such behavioral analytics for
domain experts
NEED MORE VERIFICATION](https://image.slidesharecdn.com/bspdatasci2016-jeremy-161029145502/85/DSC-2016-200-320.jpg)

























![[系列活動] Python 程式語言起步走](https://cdn.slidesharecdn.com/ss_thumbnails/python20170812-170808043244-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 使用 R 語言建立自己的演算法交易事業](https://cdn.slidesharecdn.com/ss_thumbnails/rtradingbusiness-170115010649-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 一天搞懂對話機器人](https://cdn.slidesharecdn.com/ss_thumbnails/onedaybot0422-170421235605-170422003351-thumbnail.jpg?width=640&height=640&fit=bounds)








![[系列活動] 資料探勘速遊](https://cdn.slidesharecdn.com/ss_thumbnails/0114ycchendmquicktour-170110050658-thumbnail.jpg?width=640&height=640&fit=bounds)








![[台灣人工智慧學校] 人工智慧技術發展與應用](https://cdn.slidesharecdn.com/ss_thumbnails/version5-final-190319060225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 執行長報告](https://cdn.slidesharecdn.com/ss_thumbnails/openingsw-190315170512-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 工業 4.0 與智慧製造的發展趨勢與挑戰](https://cdn.slidesharecdn.com/ss_thumbnails/20190316jyh-horngchou-190315170336-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 開創台灣產業智慧轉型的新契機](https://cdn.slidesharecdn.com/ss_thumbnails/aiotforaiabytedchangho-190227081005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 開創台灣產業智慧轉型的新契機](https://cdn.slidesharecdn.com/ss_thumbnails/aiinhealthcare-20190216victoria-v6-190227081004-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 台北總校第三期結業典禮 - 執行長談話](https://cdn.slidesharecdn.com/ss_thumbnails/tp3closingsw-190126030359-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA台中分校] AI 引爆新工業革命,智慧機械首都台中轉型論壇](https://cdn.slidesharecdn.com/ss_thumbnails/aia-chen-190116063635-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA台中分校] 2019 台灣數位轉型 與產業升級趨勢觀察](https://cdn.slidesharecdn.com/ss_thumbnails/to-sheng-190116063620-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA台中分校] 智慧製造成真! 產線導入AI的致勝關鍵](https://cdn.slidesharecdn.com/ss_thumbnails/thu-hsu-190116063619-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 從經濟學看人工智慧產業應用](https://cdn.slidesharecdn.com/ss_thumbnails/1-the-application-of-ai-industry-from-economics-190108064940-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] 台中分校第二期開學典禮 - 執行長報告](https://cdn.slidesharecdn.com/ss_thumbnails/tc2-opening1-compressed-190107034100-thumbnail.jpg?width=640&height=640&fit=bounds)

![[台中分校] 第一期結業典禮 - 執行長談話](https://cdn.slidesharecdn.com/ss_thumbnails/sw-ppt-181217031715-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] 工業4.0潛力新應用! 多模式對話機器人](https://cdn.slidesharecdn.com/ss_thumbnails/20181206004-181210031031-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] AI整合是重點! 竹科的關鍵轉型思維](https://cdn.slidesharecdn.com/ss_thumbnails/20181206002-181210031031-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] 2019 台灣數位轉型與產業升級趨勢觀察](https://cdn.slidesharecdn.com/ss_thumbnails/20181206-001-181210031002-thumbnail.jpg?width=640&height=640&fit=bounds)
![[TOxAIA新竹分校] 深度學習與Kaggle實戰](https://cdn.slidesharecdn.com/ss_thumbnails/20181206003-181210031001-thumbnail.jpg?width=640&height=640&fit=bounds)
![[台灣人工智慧學校] Bridging AI to Precision Agriculture through IoT](https://cdn.slidesharecdn.com/ss_thumbnails/hc-2nd-openingai-school-181206104858-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 台灣人工智慧學校校友年會] 產業經驗分享: 如何用最少的訓練樣本,得到最好的深度學習影像分析結果,減少一半人力,提升一倍品質 / 李明達](https://cdn.slidesharecdn.com/ss_thumbnails/lee-181130104127-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 台灣人工智慧學校校友年會] 啟動物聯網新關鍵 - 未來由你「喚」醒 / 沈品勳](https://cdn.slidesharecdn.com/ss_thumbnails/20181117shengfn-181130083931-thumbnail.jpg?width=640&height=640&fit=bounds)