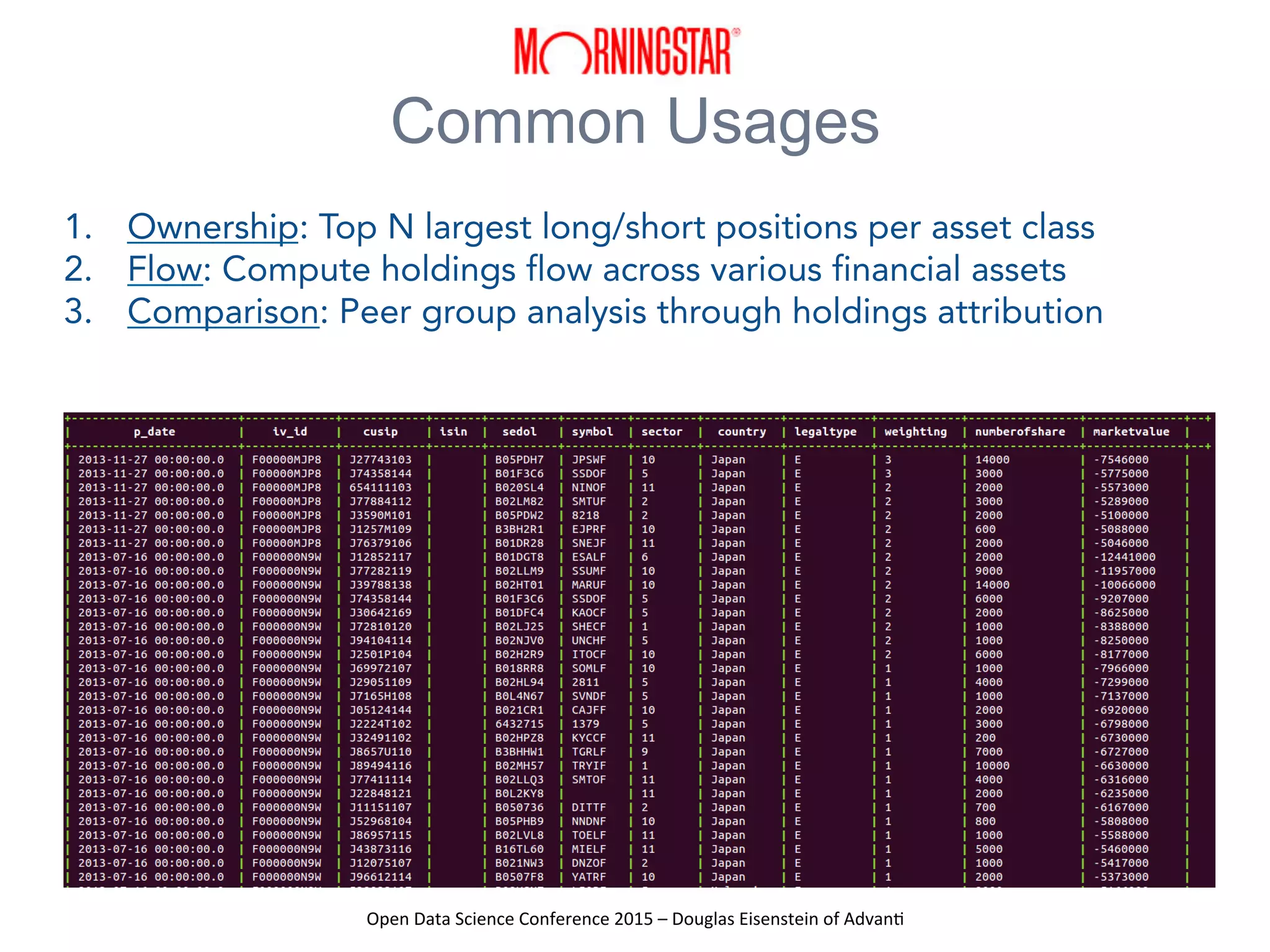
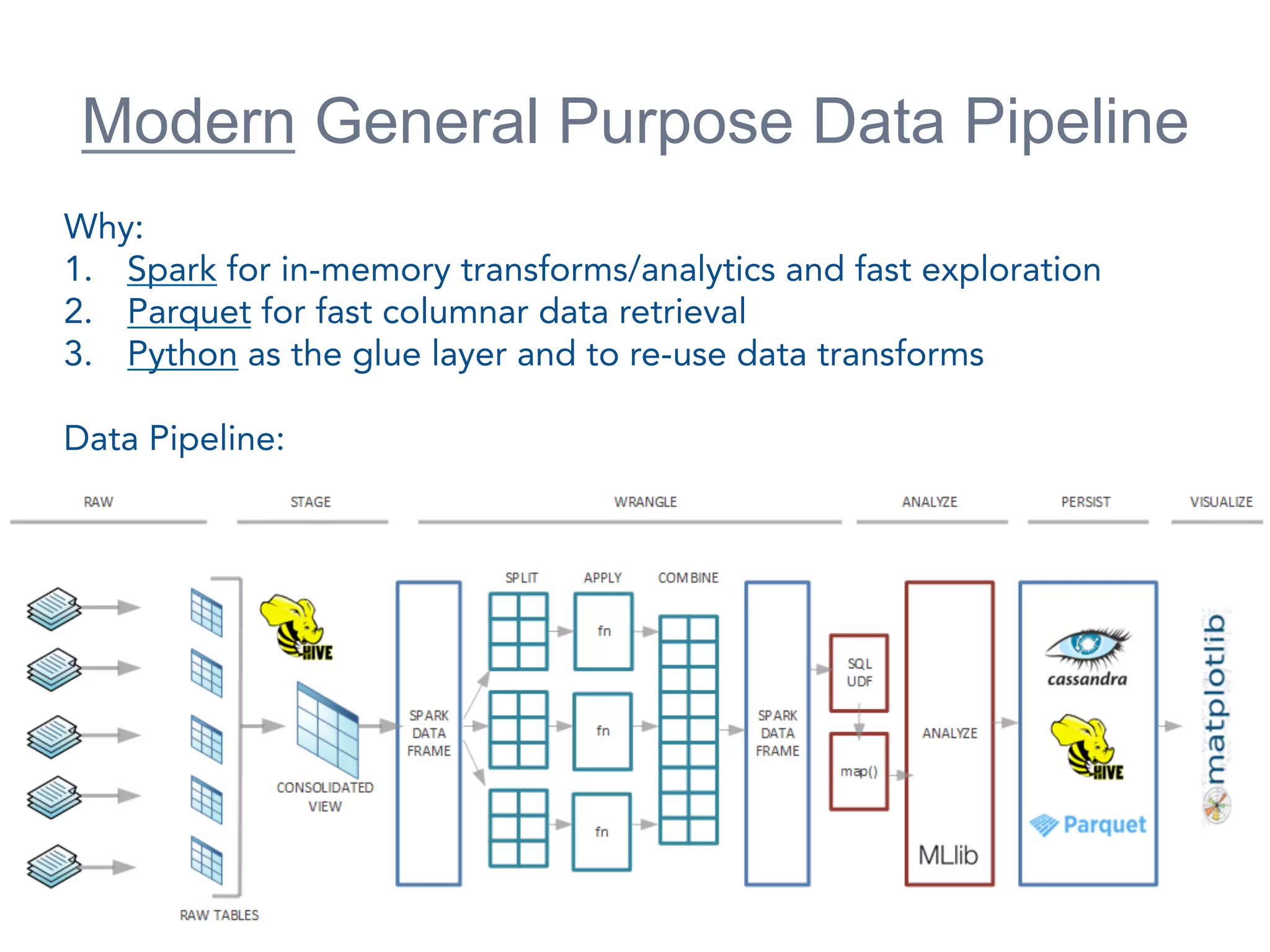
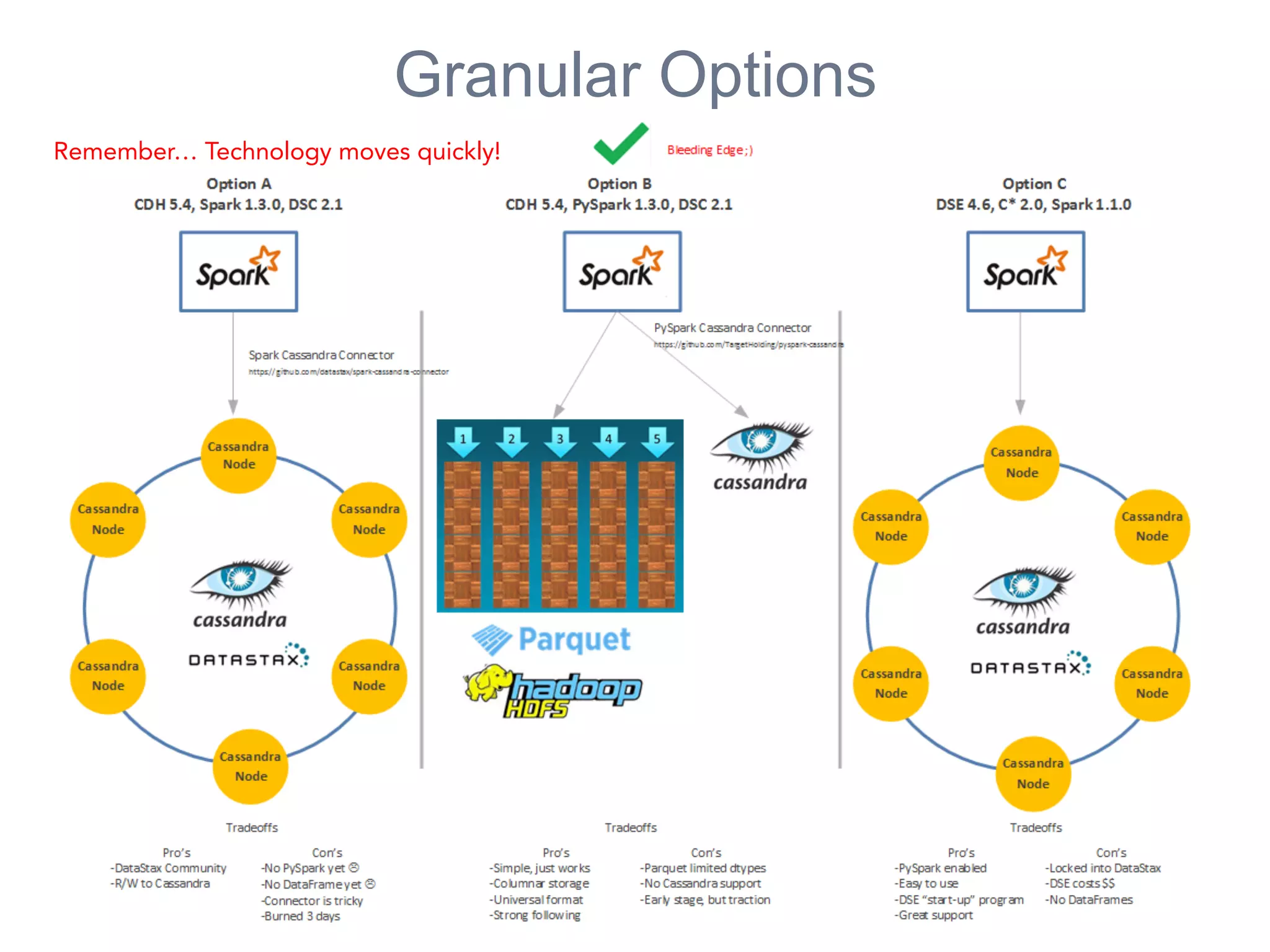
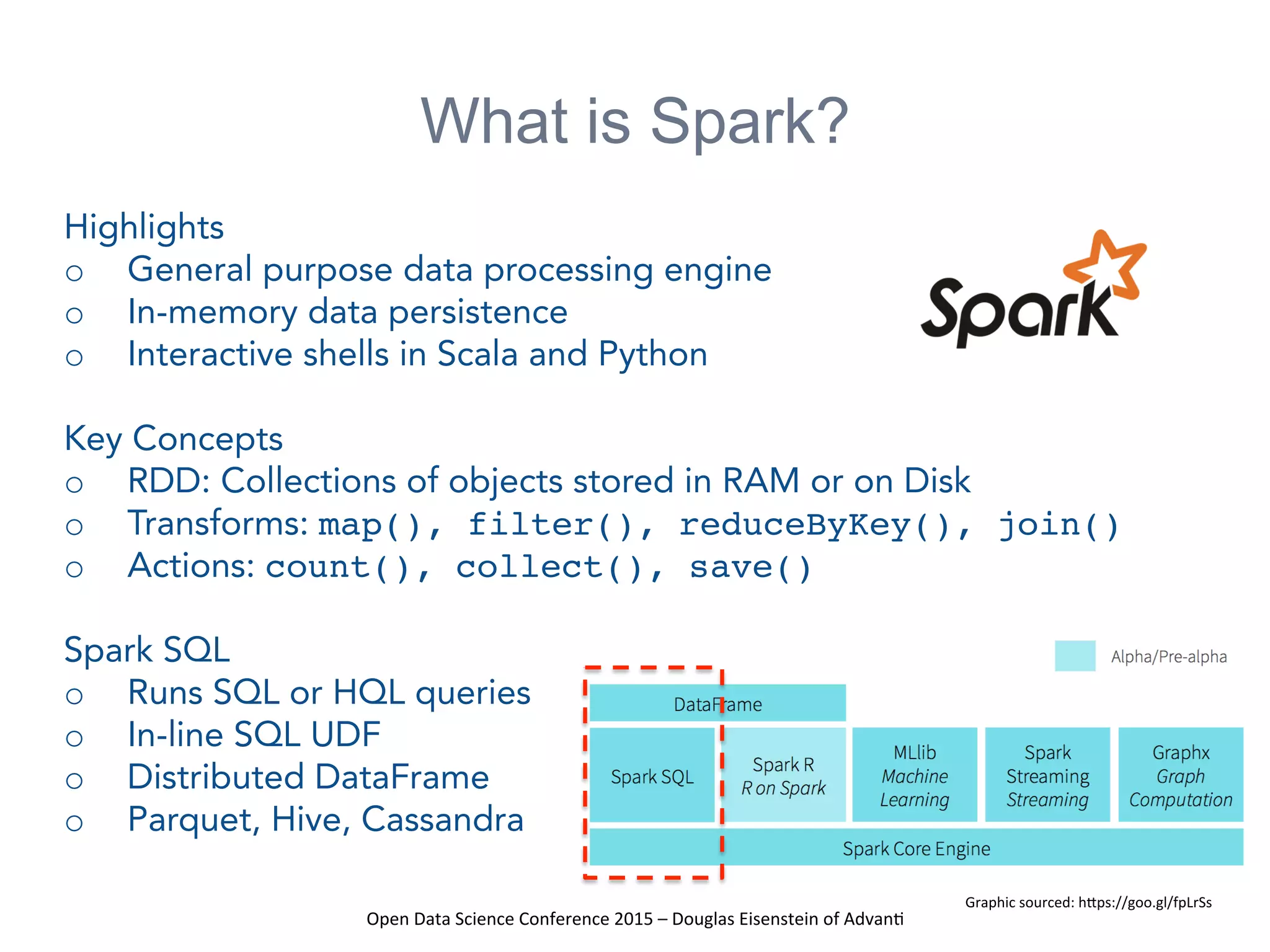
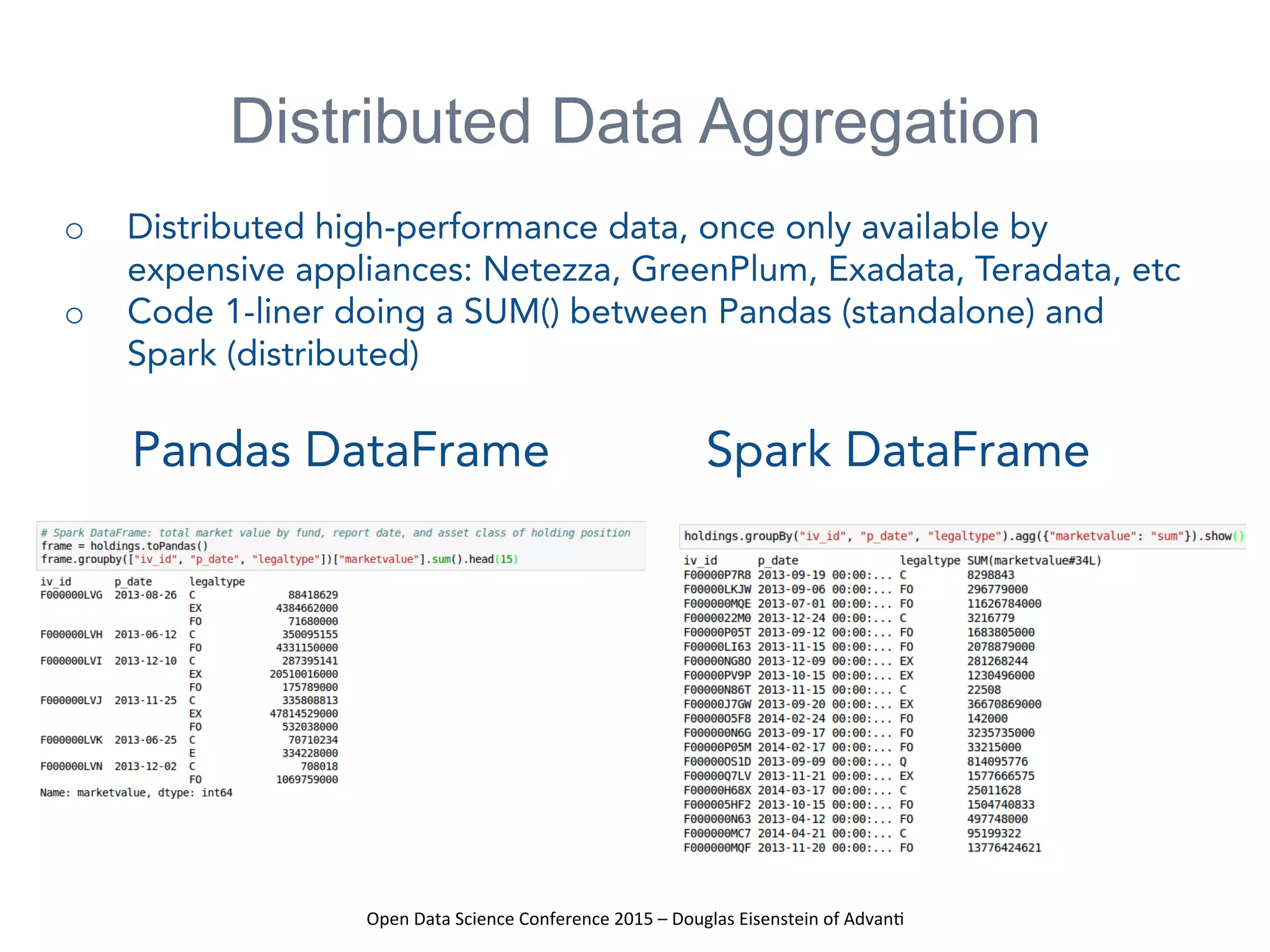
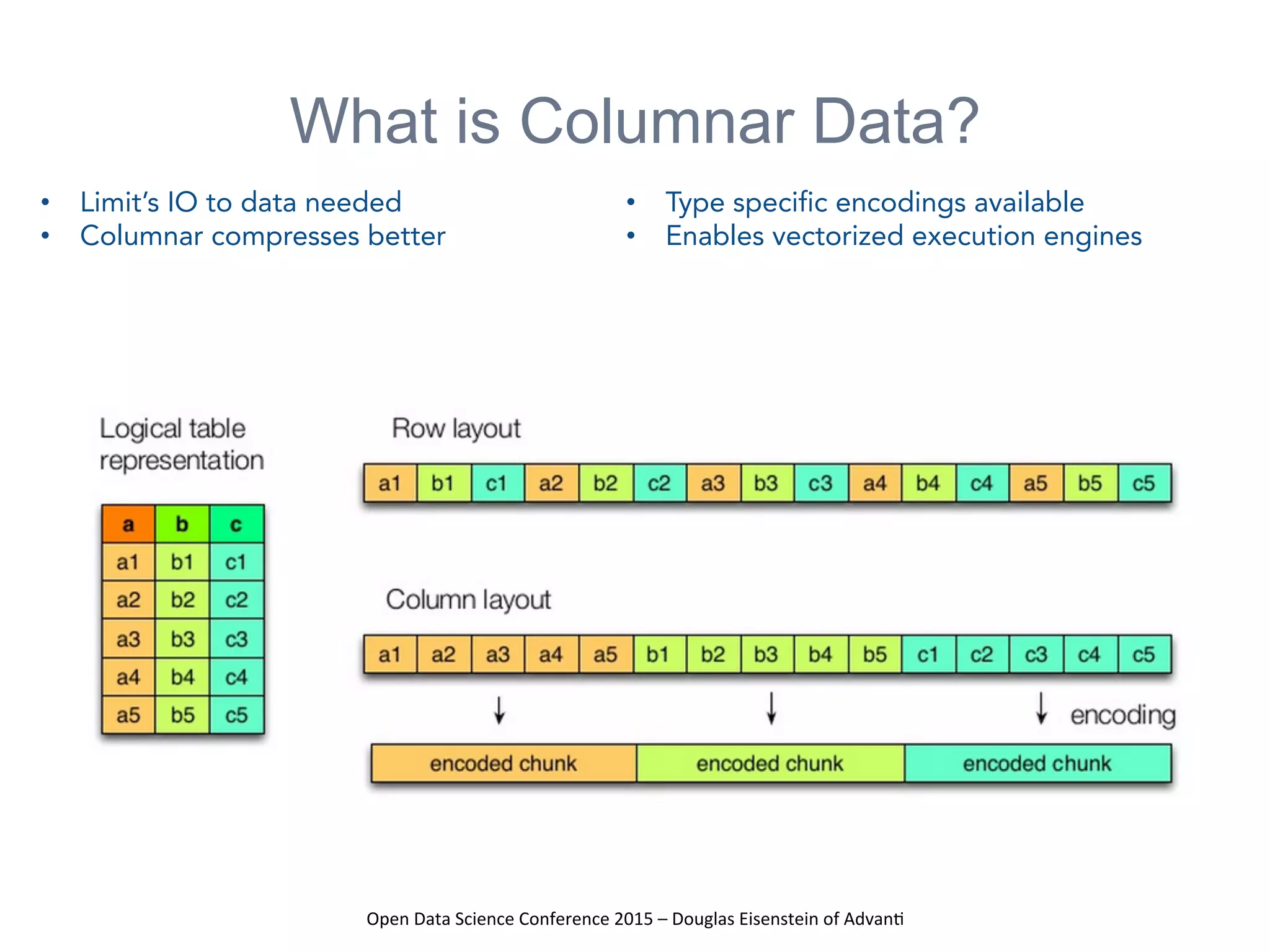
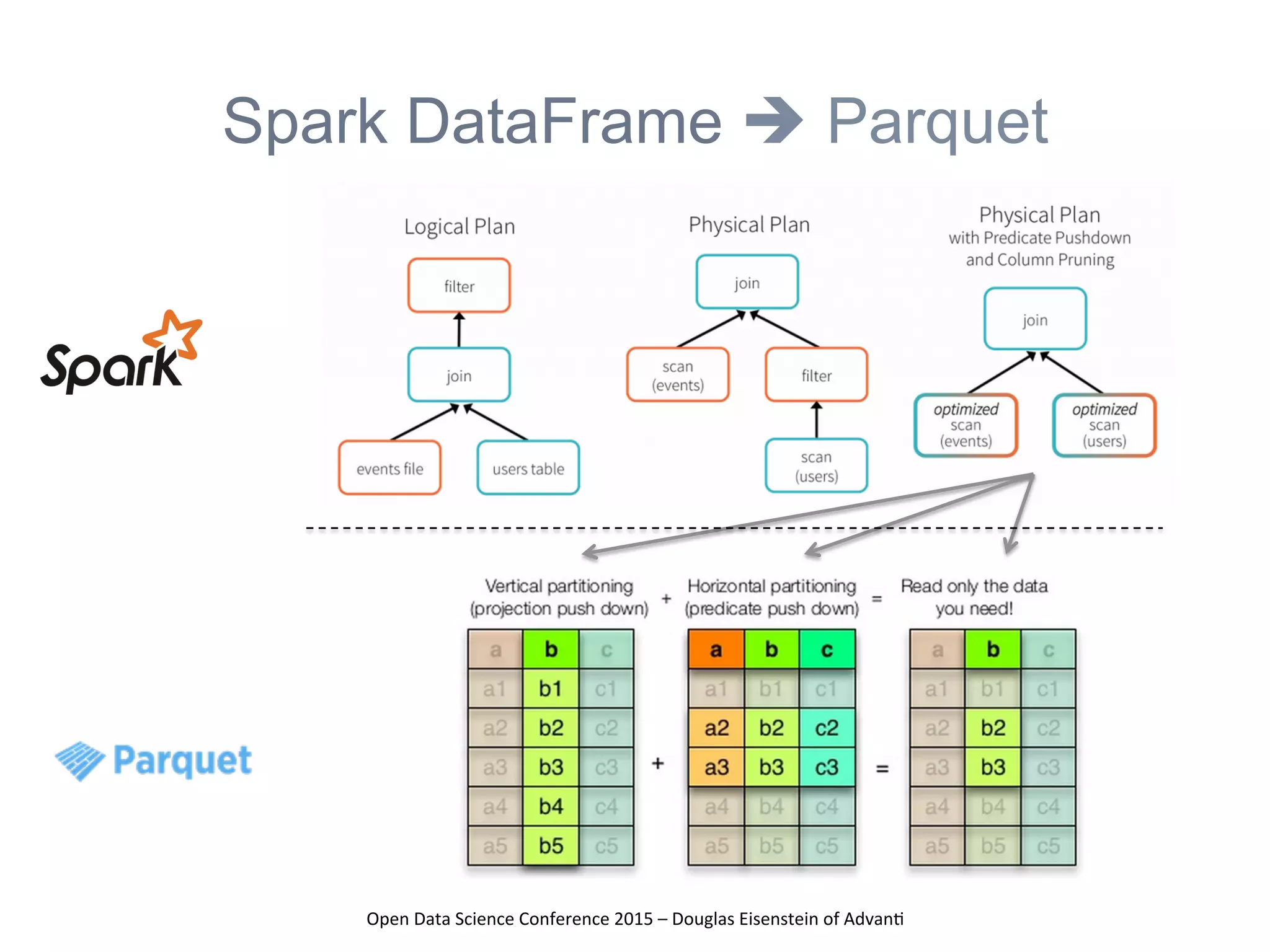
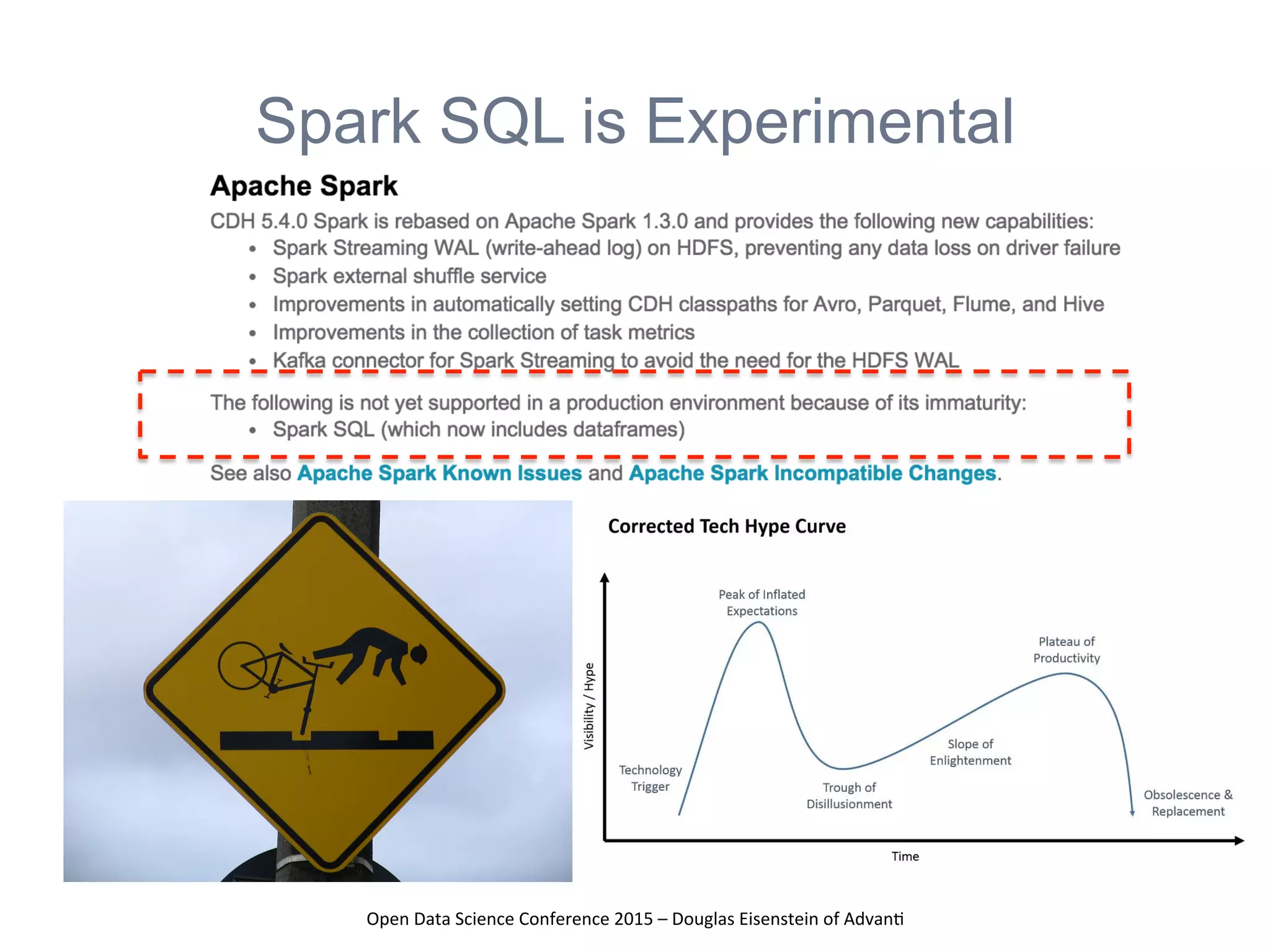
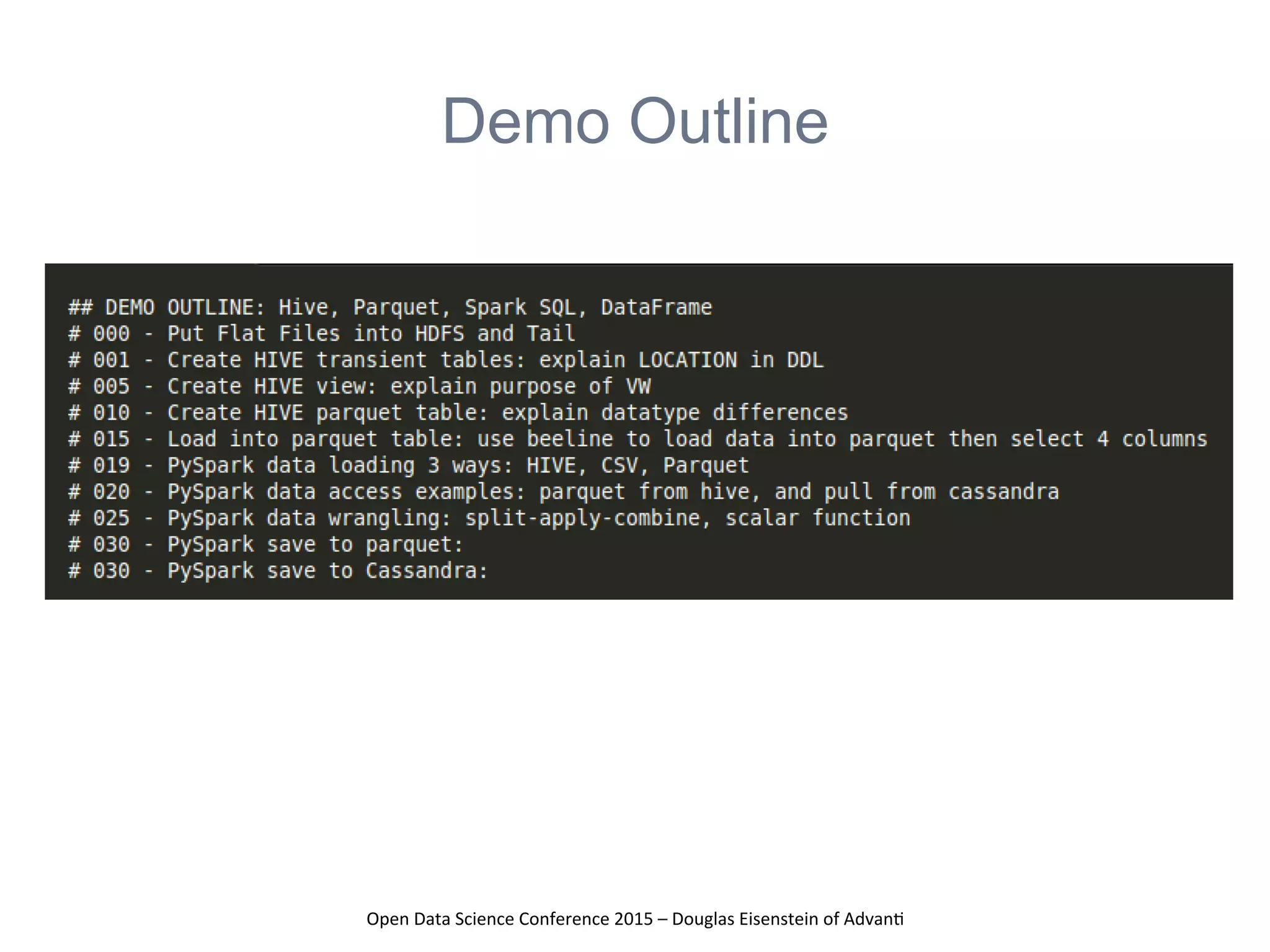
The presentation at the Open Data Science Conference 2015 by Douglas Eisenstein covers the use of Spark, Python, and Parquet for data loading and transformations. Key takeaways include understanding Spark and Parquet, seeing live demos of data transformations, and gaining insights into handling large financial datasets. The session emphasizes the importance of modern data pipelines for financial analytics and provides several resources for further learning.