Download as PDF, PPTX













![Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
Base RTDraDn sformed RDD
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(‘t’)[2])
messages.cache()
Block 1
Block 2
Block 3
Worker
Worker
Worker
Driver
messages.filter(lambda s: “foo” in s).count()
messages.filter(lambda s: “bar” in s).count()
. . .
results
tasks
Cache 1
Cache 2
Cache 3
Action
Full-text search of Wikipedia in <1 sec
(vs 20 sec for on-disk data)](https://image.slidesharecdn.com/qcon-matei-141127005108-conversion-gate01/75/Unified-Big-Data-Processing-with-Apache-Spark-QCON-2014-19-2048.jpg)







![MLlib
Vectors, Matrices = RDD[Vector]
Iterative computation
points = sc.textFile(“data.txt”).map(parsePoint)
model = KMeans.train(points, 10)
model.predict(newPoint)](https://image.slidesharecdn.com/qcon-matei-141127005108-conversion-gate01/75/Unified-Big-Data-Processing-with-Apache-Spark-QCON-2014-31-2048.jpg)

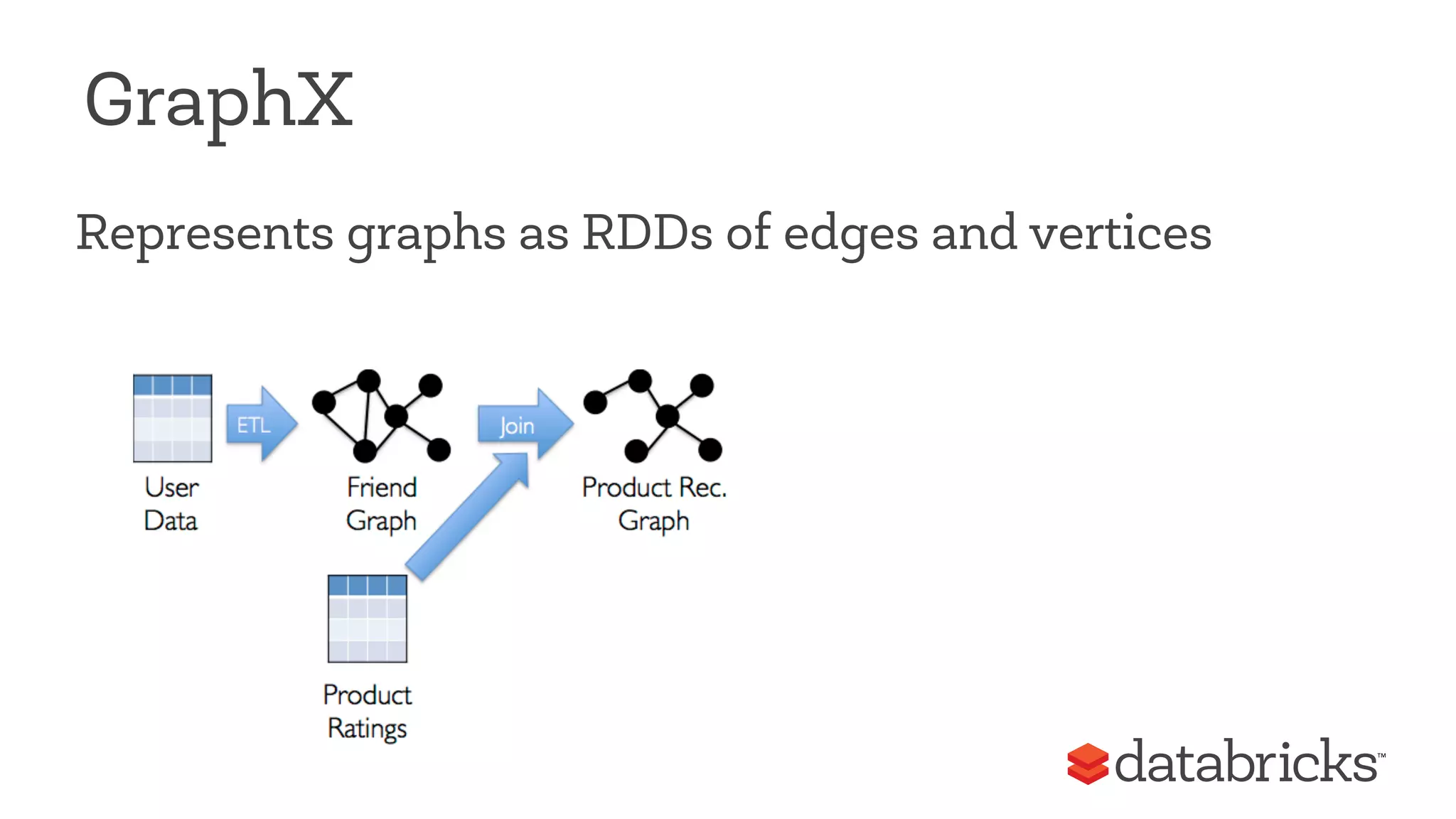
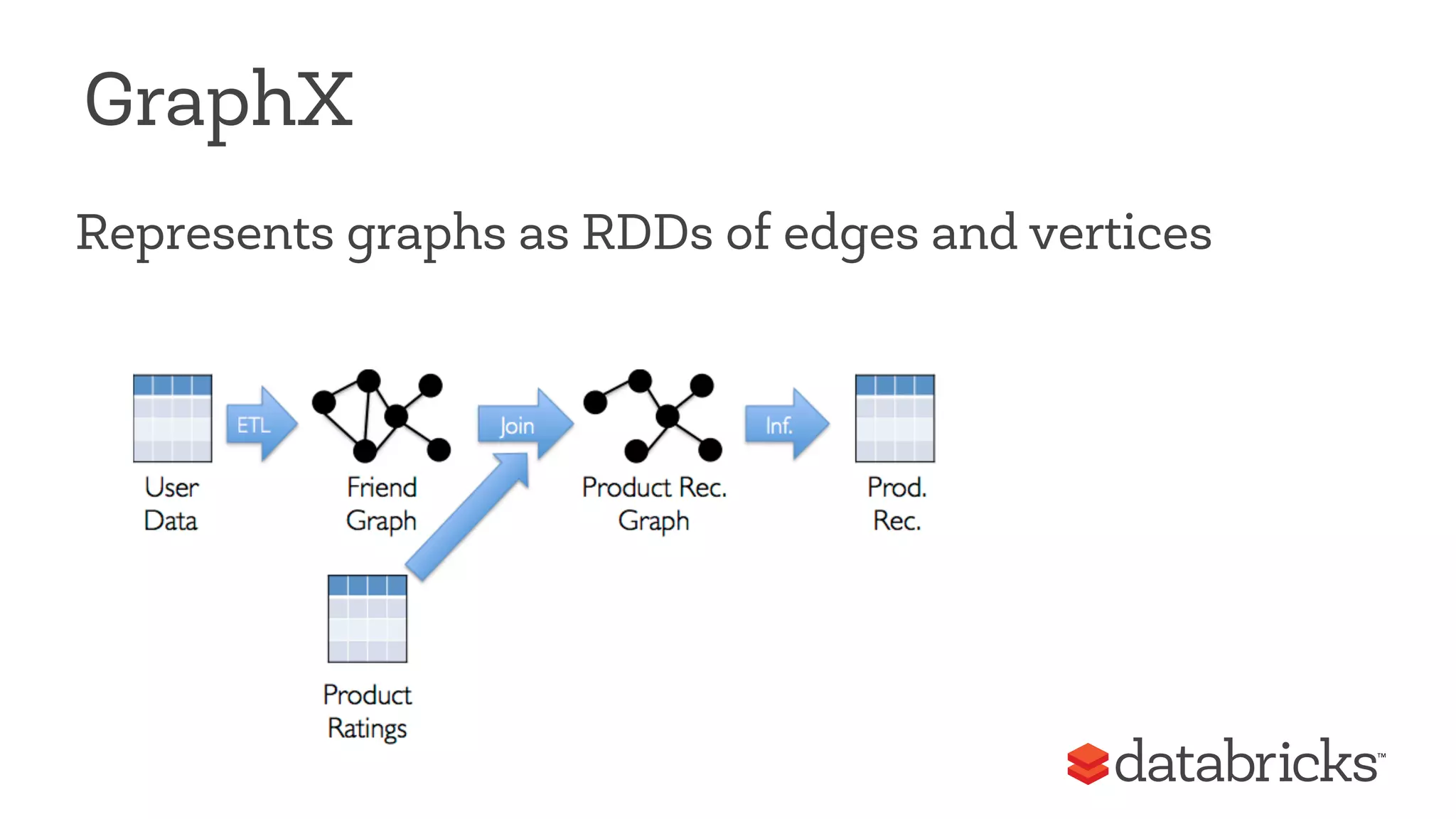

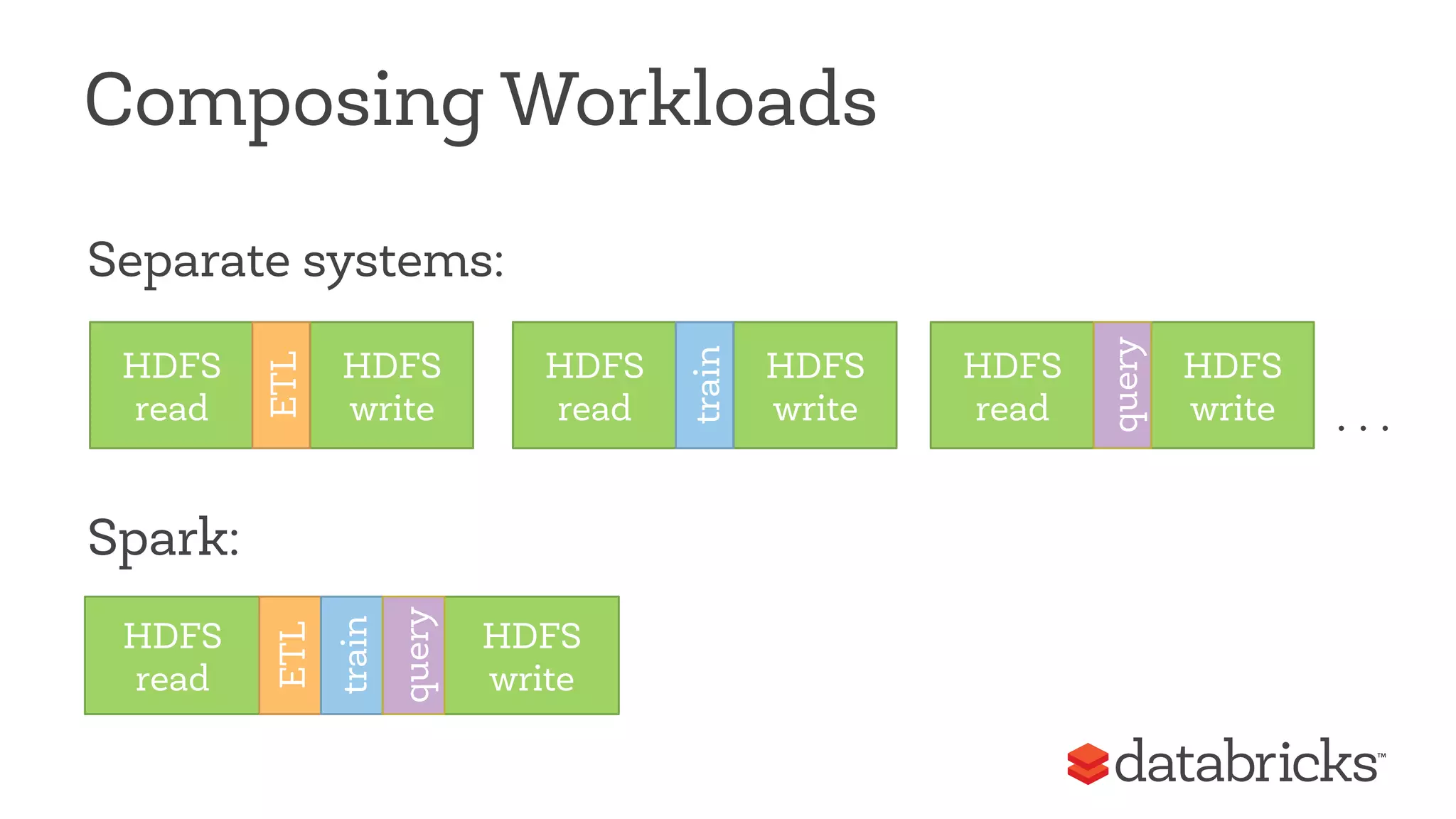
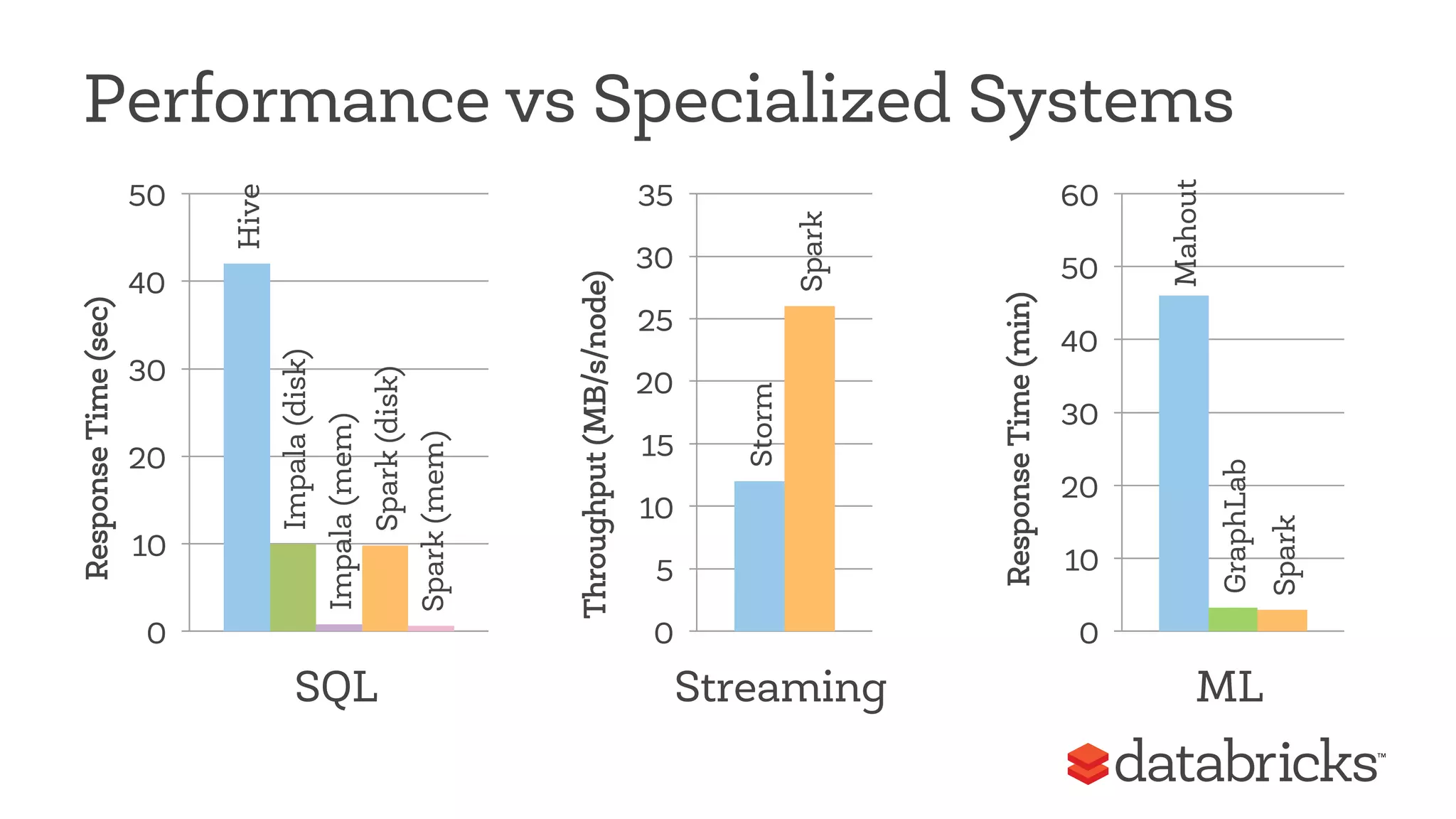
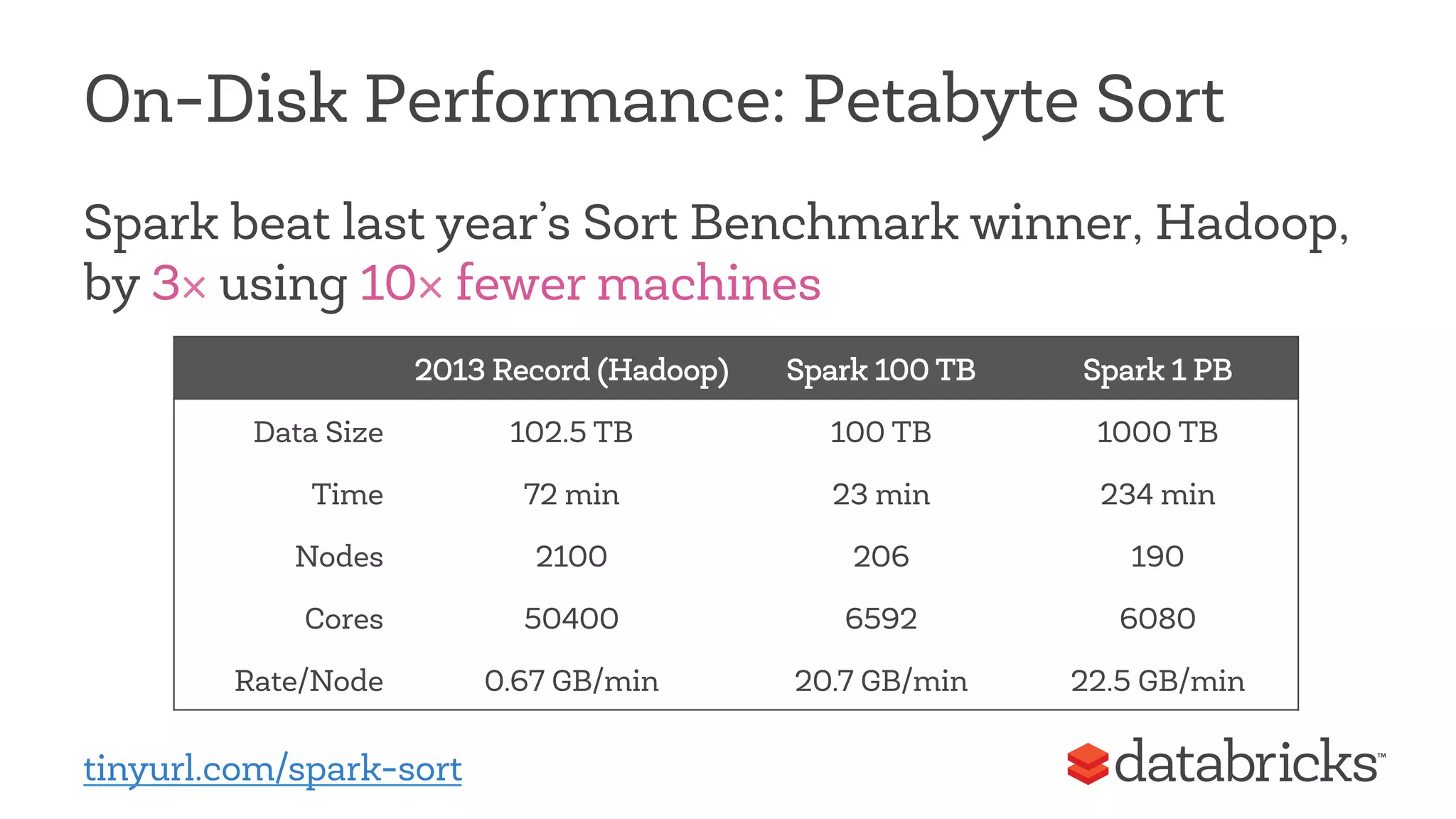


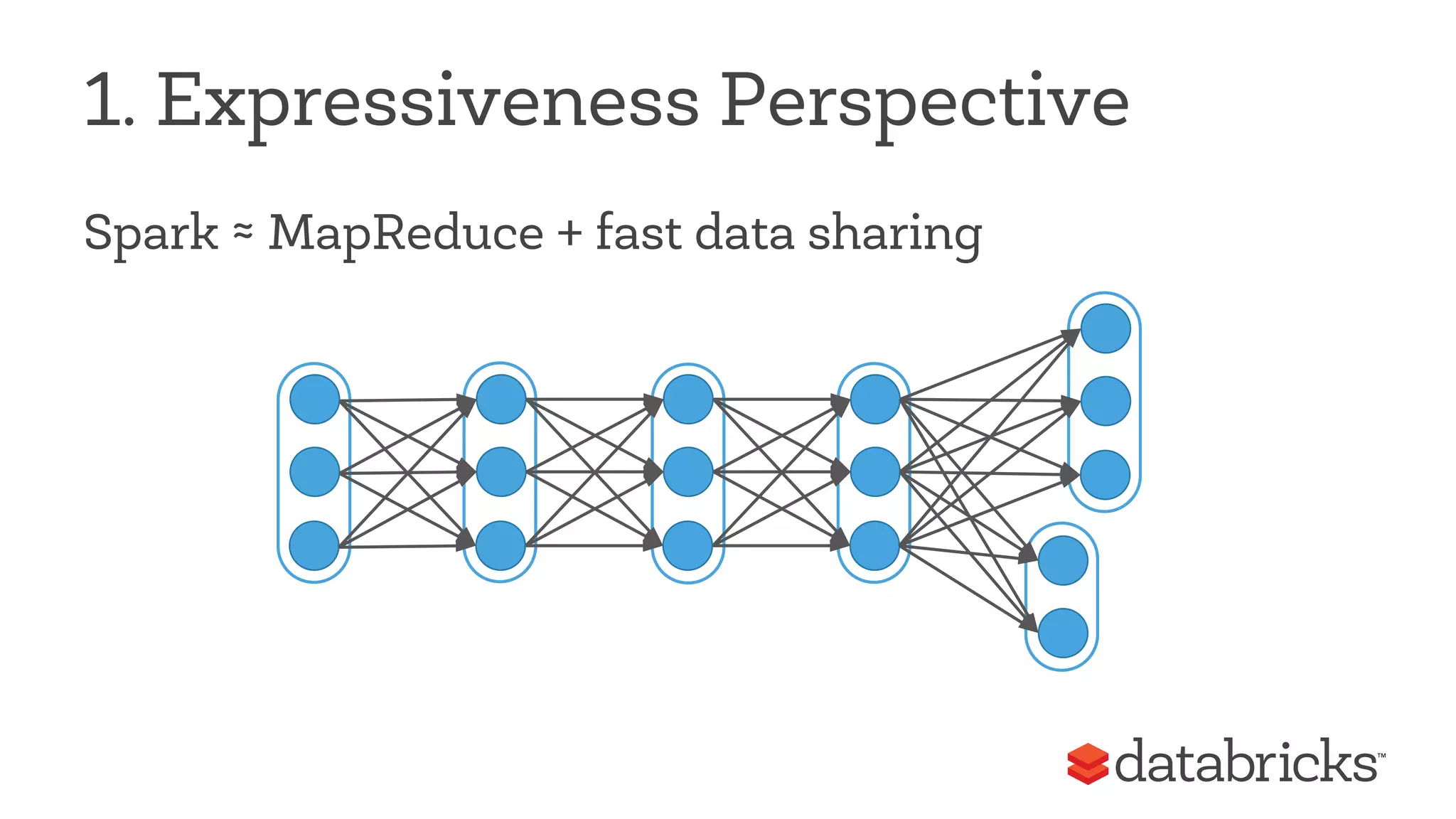
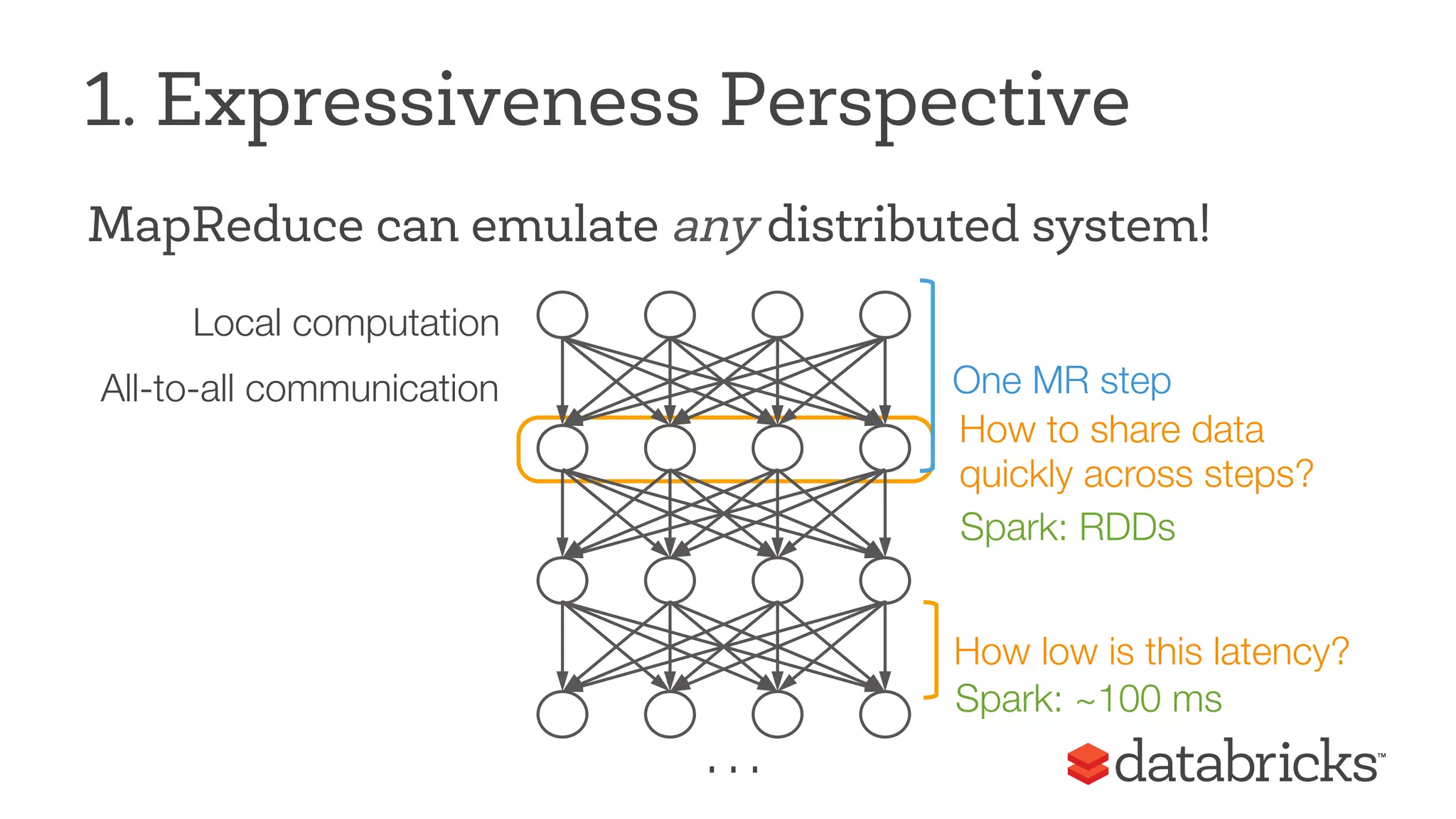






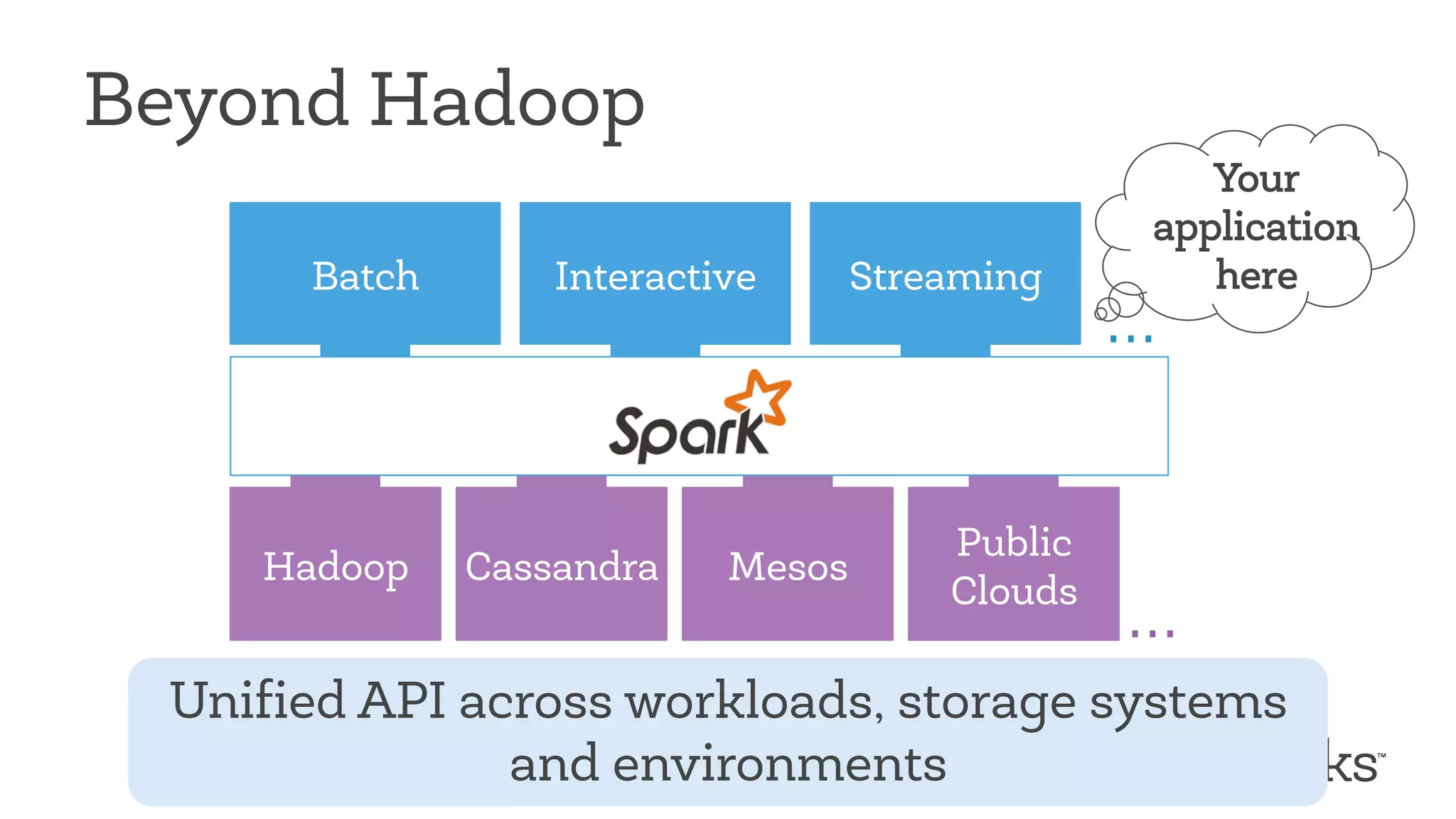




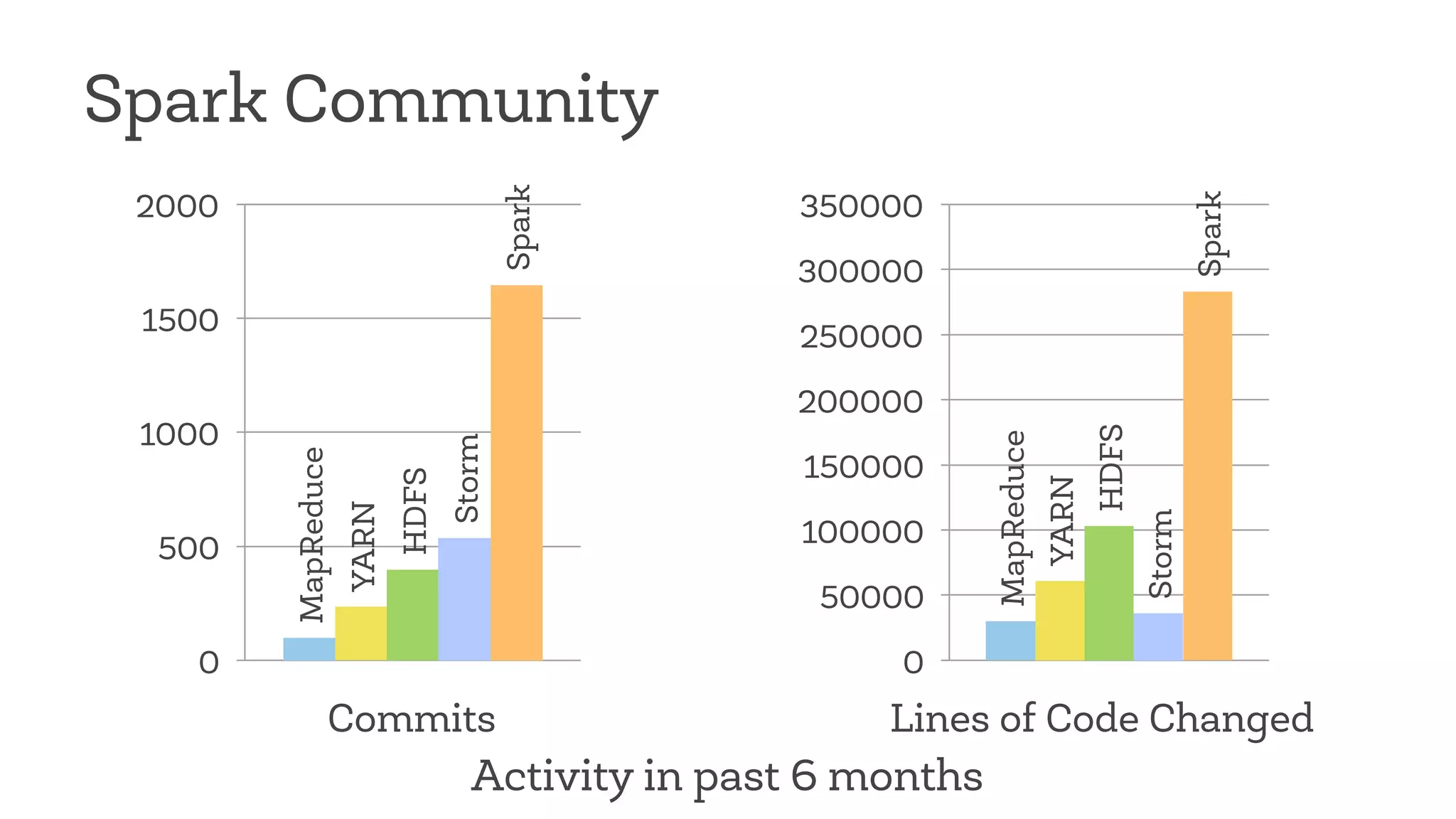
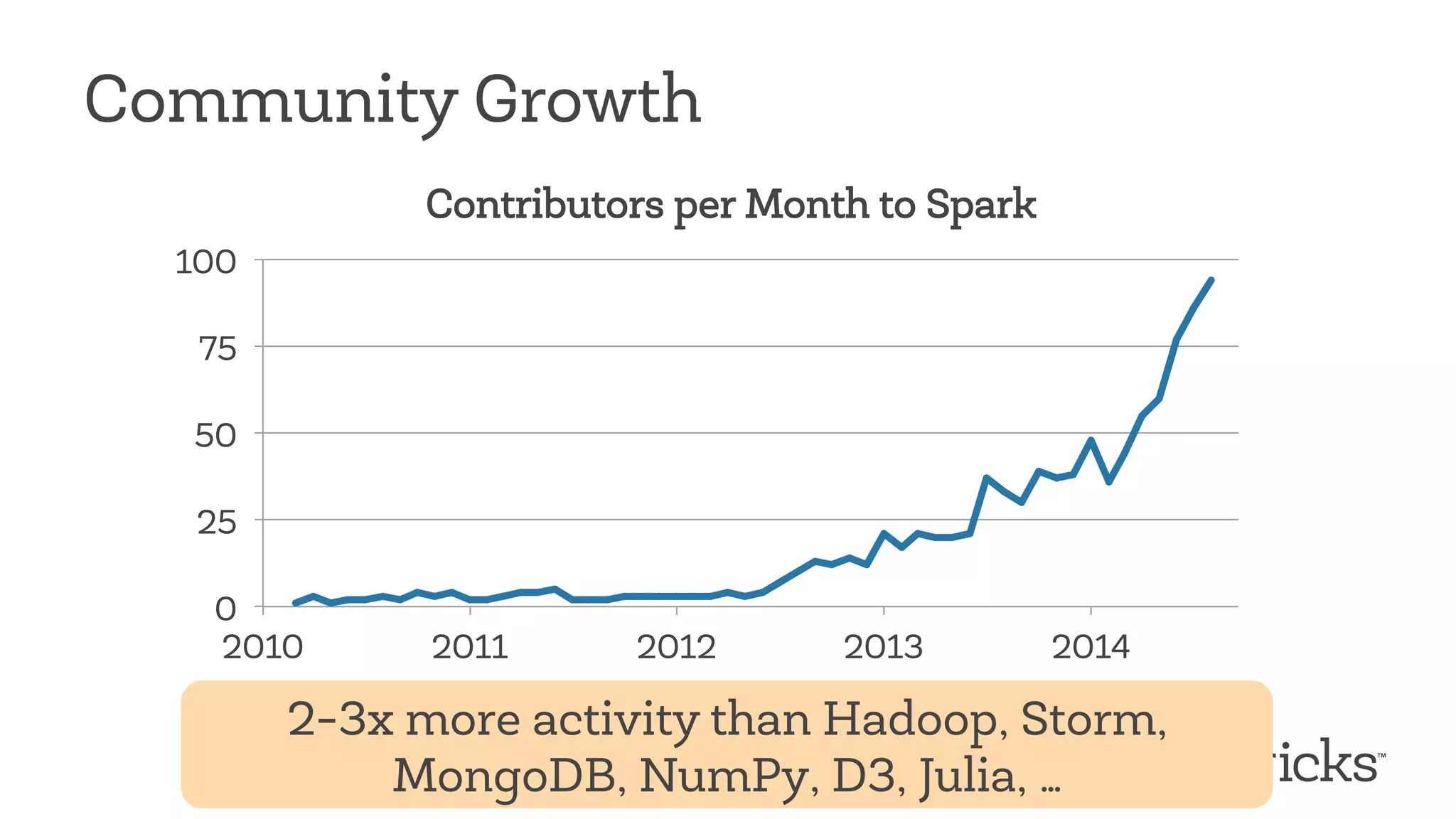
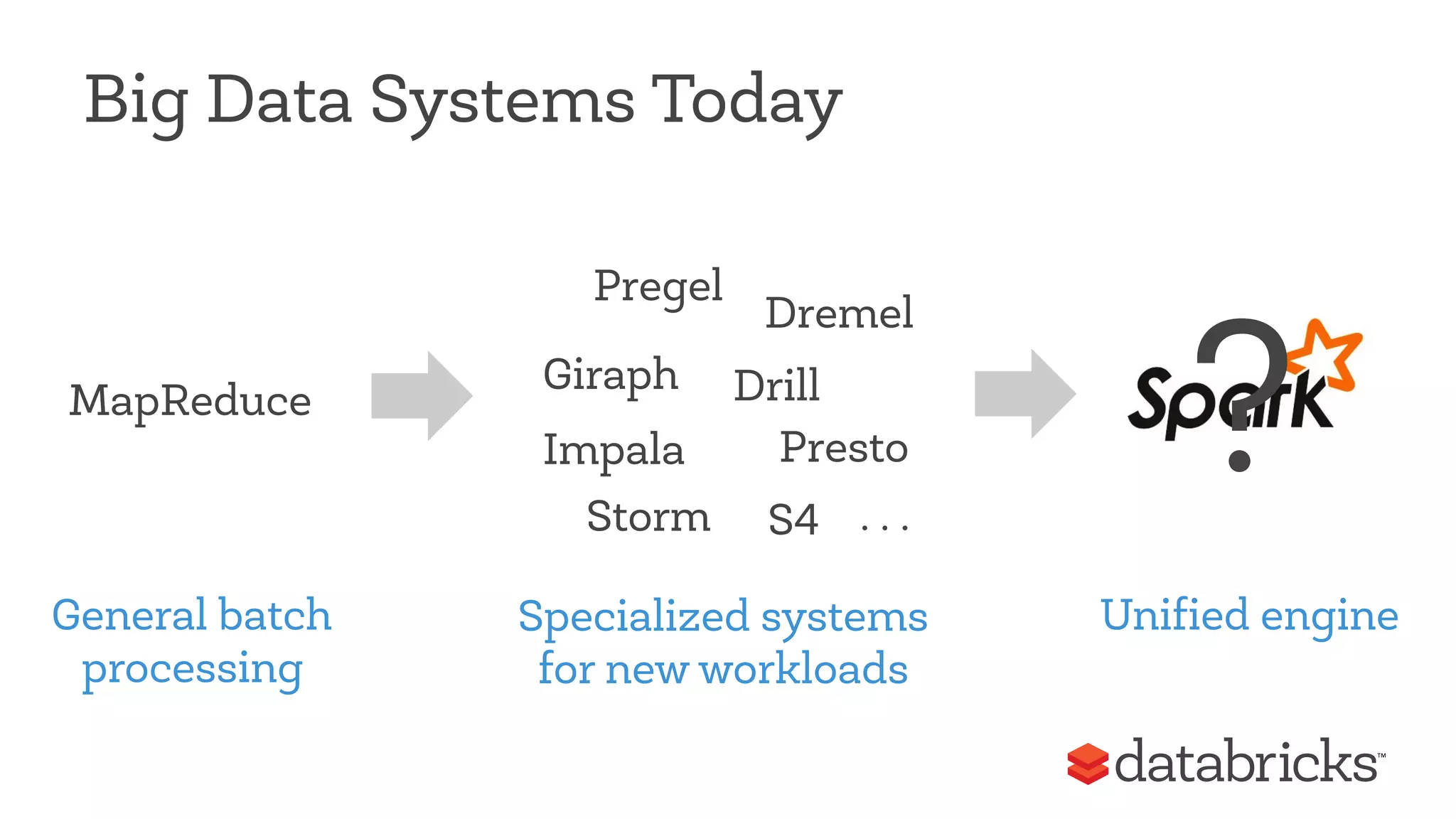
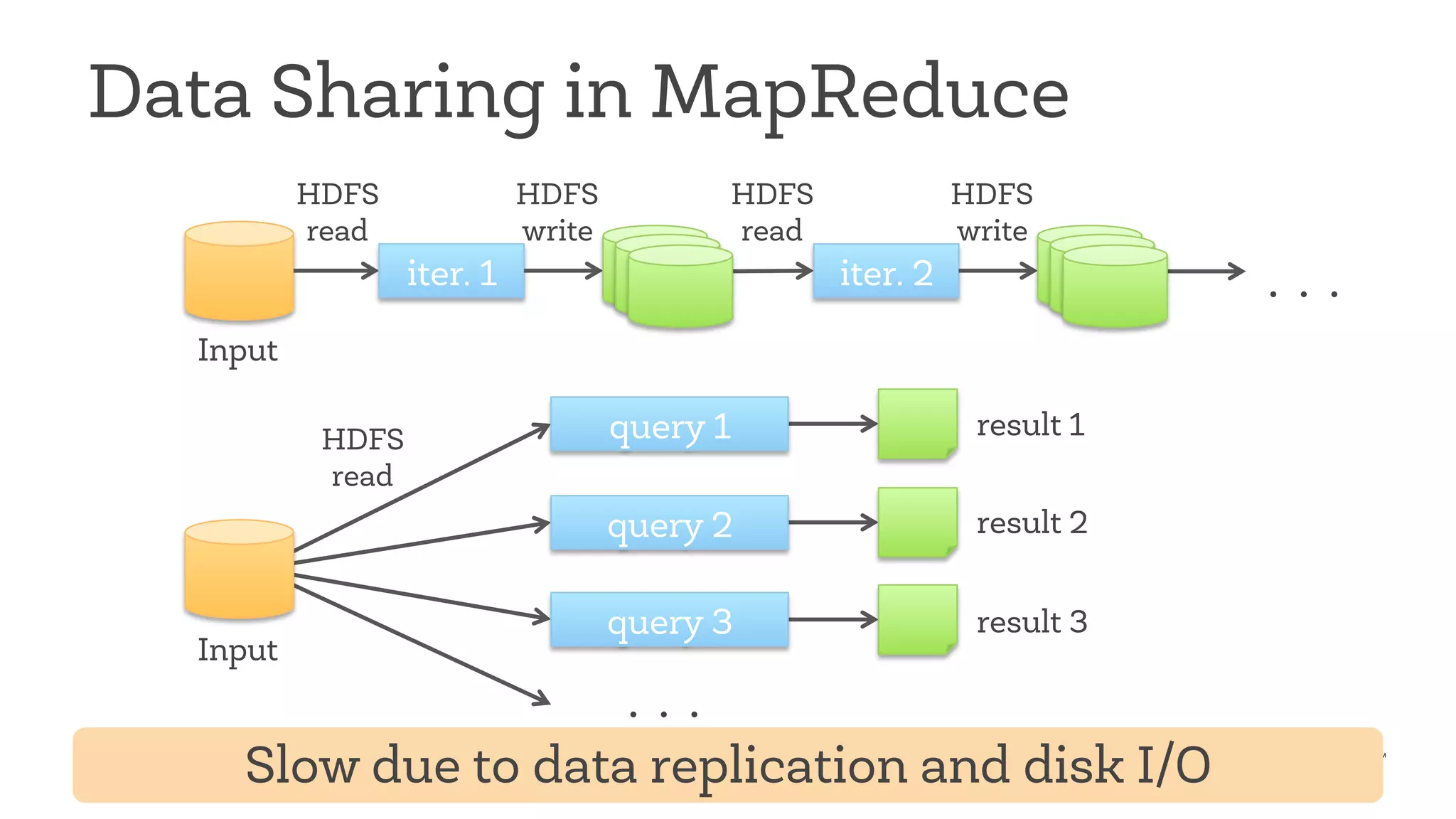
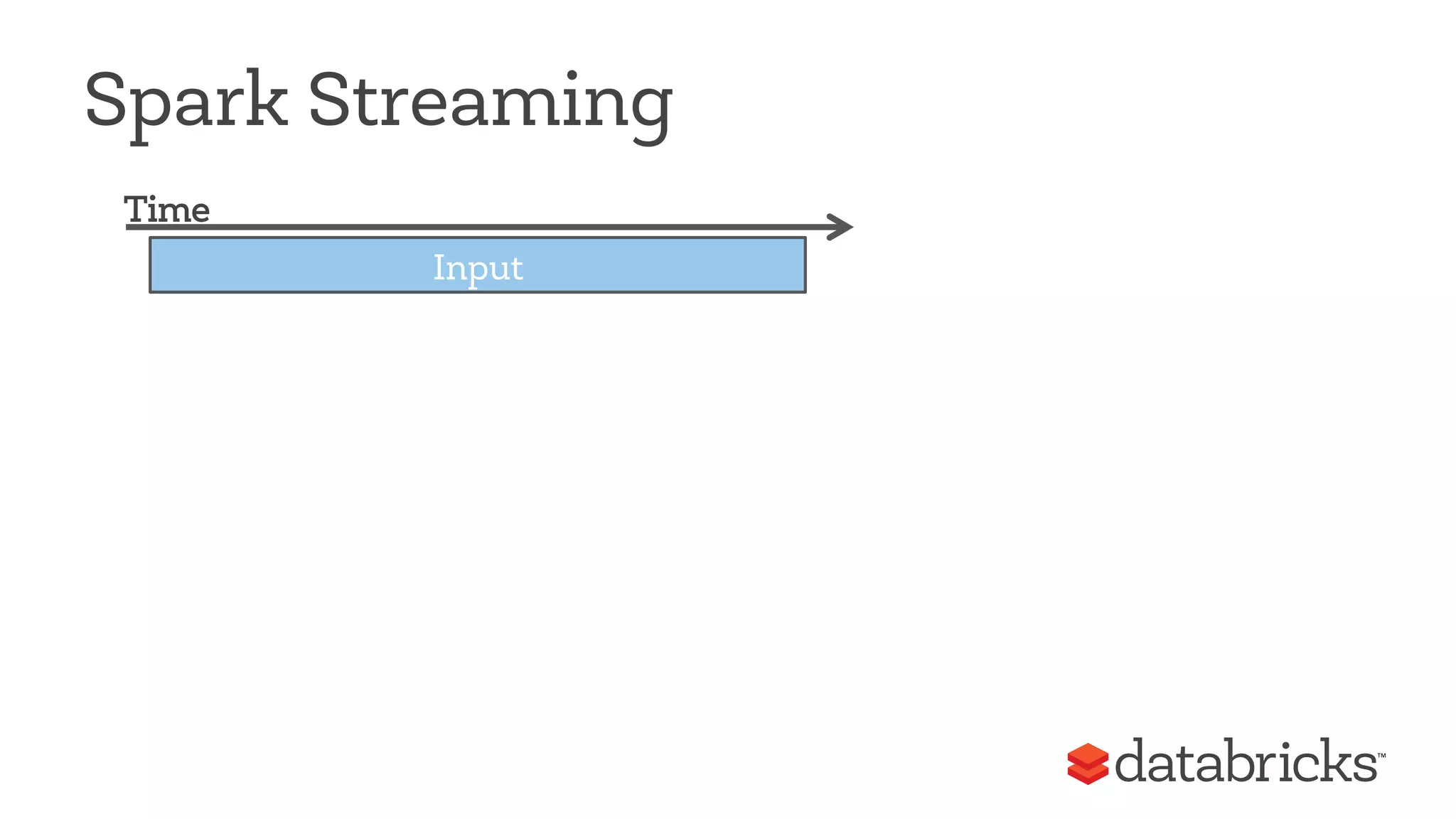
This document discusses Apache Spark, a fast and general engine for big data processing. It describes how Spark generalizes the MapReduce model through its Resilient Distributed Datasets (RDDs) abstraction, which allows efficient sharing of data across parallel operations. This unified approach allows Spark to support multiple types of processing, like SQL queries, streaming, and machine learning, within a single framework. The document also outlines ongoing developments like Spark SQL and improved machine learning capabilities.











































































































