Downloaded 14 times


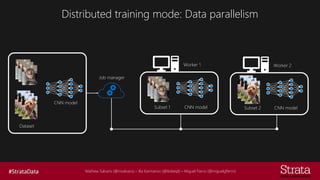
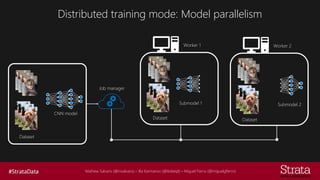

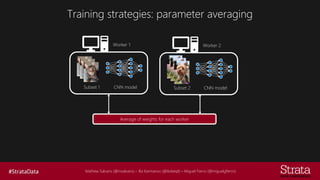
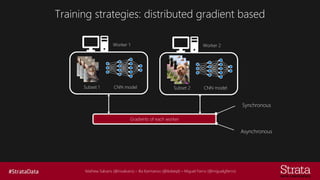


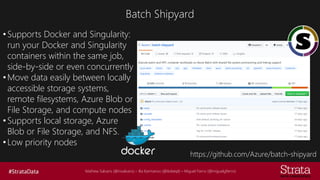
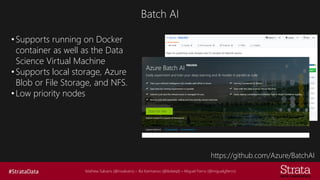
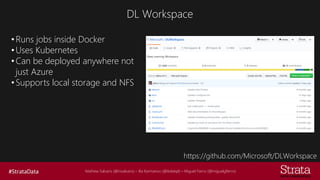

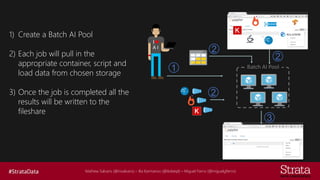


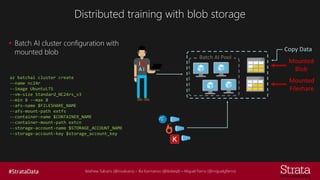
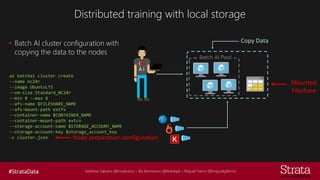
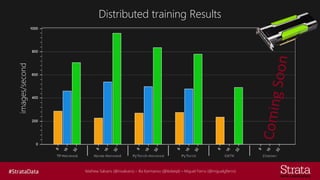
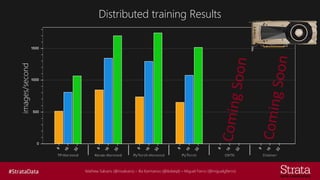
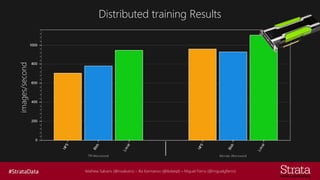






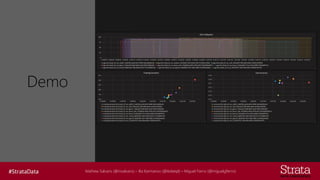



The document discusses distributed training of deep learning models, detailing methods like data parallelism and model parallelism for optimizing performance. It outlines various training strategies, such as parameter averaging and distributed gradient methods, while highlighting platforms and tools for implementing distributed training, including Azure Batch AI and Horovod. Additionally, it provides practical configurations for batch AI clusters, emphasizing their scalability and efficiency in handling large datasets.







































































