Distributed Network,
Computing, and System
Courtesy@Maarten van Steen
VU Amsterdam, Dept. Computer Science Room R4.20, steen@cs.vu.nl
Personal free book download
https://www.distributed-systems.net/index.php/books/ds3/
2022-3-25
Distributed Network,
Computing, andSystem
Chih-Lin Hu (胡誌麟)
clhu@ce.ncu.edu.tw
Dept. Communication Engineering
National Central University
1
Personal free book download
https://www.distributed-systems.net/index.php/books/ds3/
Courtesy@Maarten van Steen
VU Amsterdam, Dept. Computer Science Room R4.20, steen@cs.vu.nl
Distributed System: Definition
❖A distributed system is a piece of software that ensures that:
a collection of autonomous computing elements appears to its users as a single coherent
system
❖ Autonomous computing elements, also referred to as nodes, be they hardware devices or software
processes.
❖ Single coherent system: users or applications perceive a single system ⇒ nodes need to collaborate.
❖ Essence
❖ The collection of nodes as a whole operates the same, no matter where, when, and how interaction
between a user and the system takes place.
❖ Partial failures
❖ It is inevitable that at any time only a part of the distributed system fails. Hiding partial failures and
their recovery is often very difficult and in general impossible to hide.
5.
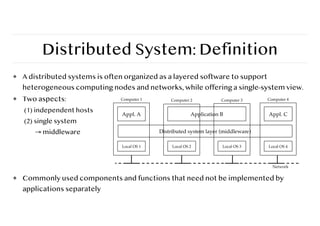
Distributed System: Definition
❖A distributed systems is often organized as a layered software to support
heterogeneous computing nodes and networks, while offering a single-system view.
❖ Two aspects:
(1) independent hosts
(2) single system
→ middleware
❖ Commonly used components and functions that need not be implemented by
applications separately
Appl. A Application B Appl. C
Distributed system layer (middleware)
Local OS 1 Local OS 2 Local OS 3 Local OS 4
Computer 1 Computer 2 Computer 3 Computer 4
Network
6.
Goals of DistributedSystems
❖ Making resources available / Supporting sharing of resources
❖ Distribution transparency
❖ Openness
❖ Scalability
❖
7.
Making Resources Available
❖Accessing and sharing resources in a controlled and efficient way
❖ Resources can be anything
❖ numerous virtual organizations with connectivity of the Internet — groupware
❖ security
❖ privacy
❖ Canonical Examples
❖ Cloud-based shared storage and files
❖ Peer-to-peer assisted multimedia streaming
❖ Shared mail services (outsourced mail systems)
❖ Shared Weg hosting (e.g, content distribution networks)
“The network is the computer”
quote from John Gage, then at
Sun Microsystems
8.
Distributed Transparency
Transp. Descrip
ti
on
AccessHides di
ff
erences in data representa
ti
on and invoca
ti
on mechanisms
Loca
ti
on Hides where an object resides
Migra
ti
on Hides from an object the ability of a system to change the object’s loca on
Reloca
ti
on
Hides from a client the ability of a system to change the loca on of an object to which the
client is bound
Replica
ti
on
Hides the fact that an object or its state may be replicated and that replicas reside at di erent
loca
ti
ons
Concurrency Hides the coordina
ti
on of ac
ti
vi
ti
es between objects to achieve consistency at a higher level
Failure Hides failure and possible recovery of objects
Note: Distribution transparency is a nice a goal, but achieving it is a different story.
9.
Degree of Transparency
Observation
❖Aiming at full distribution transparency may be too much:
❖ Users may be located in different continents
❖ Completely hiding failures of networks and nodes is impossible (theoretically and
practically)
❖ You cannot distinguish a slow computer from a failing one
❖ You can never be sure that a server actually performed an operation before a crash
❖ Full transparency will cost performance, exposing distribution of the system
❖ Keeping Web caches/replicas exactly up-to-date with the master, which takes time
❖ Immediately flushing write operations to disk for fault tolerance
10.
Degree of Transparency
❖Exposing distribution may be good
❖ Making use of location-based services (finding your nearby friends)
❖ When dealing with users in different time zones
❖ When it makes it easier for a user to understand what’s going on (when
e.g., a server does not respond for a long time, report it as failing).
❖ Remark
❖ Distribution transparency is a nice a goal, but achieving it is a different
story, and it should often not even be aimed at.
11.
Openness of DistributionSystems
Open distributed systems
Be able to interact with services from other open systems, irrespective of the
underlying environment:
❖ Systems should conform to well-defined interfaces
❖ Systems should easily interoperate
❖ Systems should support portability of applications
❖ Systems should be capable of extensibility of functions and components
12.
Scale in DistributedSystems
Observation
❖ Many developers of modern distributed systems easily use the adjective “scalable”
without making clear why their system actually scales.
❖ Most systems account only, to a certain extent, for size scalability.
The (non)solution: powerful servers. Today, the challenge lies in geographical and
administrative scalability.
Scalability
❖ Number of users and/or processes (size scalability)
❖ Maximum distance between nodes (geographical scalability)
❖ Number of administrative domains (administrative scalability)
13.
Problems with SizeScalability
❖ Root causes for scalability problems with centralized solutions
❖ The computational capacity, limited by the CPUs
❖ The storage capacity, including the transfer rate between CPUs and disks
❖ The network between the user and the centralized service
Formal analysis using queueing theory
14.
Problems with GeographicalScalability
❖ Cannot simply go from LAN to WAN: many distributed systems assume
synchronous client-server interactions: client sends request and waits for an
answer. Latency may easily prohibit this scheme.
❖ WAN links are often inherently unreliable: simply moving streaming video
from LAN to WAN is bound to fail.
❖ Lack of multipoint communication, so that a simple search broadcast cannot
be deployed. Solution is to develop separate naming and directory services
(having their own scalability problems).
❖
15.
Problems with AdministrativeScalability
❖ Essence
❖ Conflicting policies concerning usage (and thus payment), management, and security
❖ Examples
❖ Computational grids: share expensive resources between different domains.
❖ Shared equipment: how to control, manage, and use a shared radio telescope constructed as
large-scale shared sensor network?
❖ Exception: several peer-to-peer networks
❖ File-sharing systems (based, e.g., on BitTorrent)
❖ Peer-to-peer telephony (Skype)
❖ Peer-assisted audio streaming (Spotify)
❖ Note: end users collaborate and not administrative entities.
16.
Techniques for Scaling
Hidecommunication latencies
Avoid waiting for responses; do something else:
❖ Make use of asynchronous communication
❖ Have separate handlers for incoming response
❖ Problem: not every application fits this model
17.
Techniques for Scaling
Distribution
Partitiondata and computations across multiple machines:
❖ Move computations to clients (Java applets)
❖ Decentralized naming services (DNS)
❖ Decentralized information systems (WWW)
18.
Techniques for Scaling
Replication/caching
Makecopies of data available at different machines:
❖ Replicated file servers and databases
❖ Mirrored Web sites
❖ Web caches (in browsers and proxies)
❖ File caching (at server and client)
❖
19.
Scaling - TheProblem
Observation
Applying scaling techniques is easy, except for one thing:
❖ Having multiple copies (cached or replicated), leads to inconsistencies:
modifying one copy makes that copy different from the rest.
❖ Always keeping copies consistent and in a general way requires global
synchronization on each modification.
❖ Global synchronization precludes large-scale solutions.
❖
20.
Scaling - TheProblem
Observation
If we can tolerate inconsistencies, we may reduce the need for global
synchronization, but tolerating inconsistencies is application dependent.
21.
Developing Distributed Systems:Pitfalls
Many distributed systems are needlessly complex caused by mistakes that required
patching later on. There are many false assumptions:
❖ The network is reliable
❖ The network is secure
❖ The network is homogeneous
❖ The topology does not change
❖ Latency is zero
❖ Bandwidth is infinite
❖ Transport cost is zero
❖ There is one administrator
22.
Types of DistributedSystems
❖ Distributed Computing Systems
❖ Distributed Information Systems
❖ Distributed Pervasive Systems
❖
23.
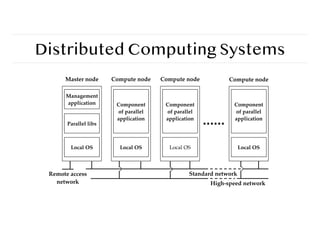
Distributed Computing Systems
Observation
Manydistributed systems are configured for High-Performance Computing
(HPC)
Cluster Computing
Essentially a group of high-end systems connected through a LAN:
❖ Homogeneous: same OS, near-identical hardware
❖ Single managing node
24.
Distributed Computing Systems
Management
application
Parallellibs
Local OS Local OS Local OS Local OS
Component
of parallel
application
Component
of parallel
application
Component
of parallel
application
Master node Compute node Compute node Compute node
Remote access
network
Standard network
High-speed network
25.
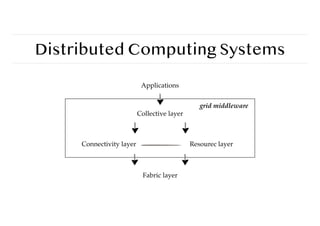
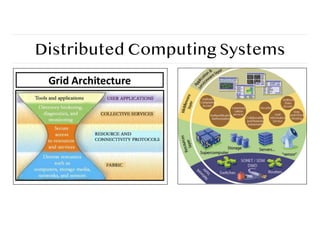
Distributed Computing Systems
Gridcomputing
The next step: lots of nodes from everywhere:
❖ Heterogeneous
❖ Dispersed across several organizations
❖ Can easily span a wide-area network
Note
To allow for collaborations, grids generally use virtual organizations.
In essence, this is a grouping of users (or better: their IDs) that will allow for authorization
on resource allocation.
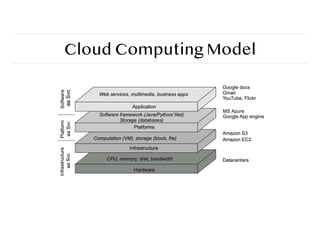
Distributed Computing Systems
Cloudcomputing
Three Flavours of Cloud – the “service models”
❖ Software-as-a-Service (SaaS)
These are usually applications or services that you access via a Web browser. Google Mail and Google Docs
are examples of this kind of cloud computing.
❖ Platform-as-a-Service (PaaS)
This is a set of lower-level services such as an operating system or computer language interpreter or web
server offered by a cloud provider to software developers. Microsoft Windows Azure and Google App Engine
are examples of PaaS.
❖ Infrastructure-as-a-Service (IaaS)
IaaS is the provision of virtual servers and storage that organisations use on a pay-as-you-go basis. Amazon’s
Elastic Compute Cloud (EC2) and Simple Storage Service (S3) are examples of IaaS.
[ref] https://www.katescomment.com/what-is-cloud-computing/
29.
Distributed Computing Systems
Cloudcomputing
❖ Private Compute Utility
An infrastructure physically dedicated to one organisation.
❖ Private Community Cloud
An infrastructure spanning multiple administrative domains that is physically dedicated to a specific
community with shared concerns.
❖ Public Cloud
An infrastructure spanning multiple administrative domains that is made available to the general
public / businesses, without physical partitioning of resource allocations.
❖ Hybrid Cloud
A combination of public public and private compute utilities in order to allow “cloud bursting” for some
requirements, or to allow a private compute utility owner to sell their spare capacity into The Cloud.
A well-managed data centre is not “a Cloud”!
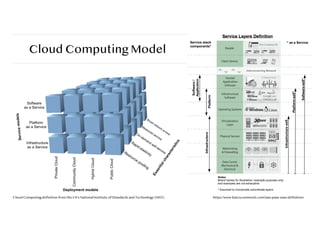
Cloud Computing Model
CloudComputing definition from the US’s National Institute of Standards and Technology (NIST) https://www.katescomment.com/iaas-paas-saas-definition/
32.
Distributed Information Systems
Observation
Thevast amount of distributed systems in use today are forms of traditional information systems, that now
integrate legacy systems.
Example: Transaction processing systems.
BEGIN_TRANSACTION ( server, transaction )
READ(transaction, file-1, data)
WRITE(transaction, file-2, data)
newData := MODIFIED( data )
IF WRONG( mewData ) THEN
ABORT_TRANSACTION(transaction)
ELSE
WRITE( transaction, file-2, newData )
END_TRANSACTION( transaction )
END IF
* Transactions form an atomic operation.
33.
Distributed Information Systems:Transactions
Model
A transaction is a collection of operations on the state of an object (database, object
composition, etc.) that satisfies the following properties (ACID)
❖ Atomicity: All operations either succeed, or all of them fails, the state of the object will remain
unaffected by the transaction.
❖ Consistency: A transaction establishes a valid state transition. This does not exclude the
possibility of invalid, intermediate states the transaction’s execution.
❖ Isolation: Concurrent transactions do not interfere with each other. It appears to each
transaction T that other transactions occur either before T, or after T, but never both.
❖ Durability: After the execution of a transaction, its effects are made permanent: change to the
state survive failure.
34.
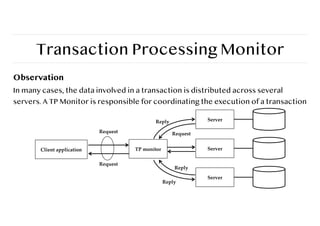
Transaction Processing Monitor
Observation
Inmany cases, the data involved in a transaction is distributed across several
servers. A TP Monitor is responsible for coordinating the execution of a transaction
Reply
Reply
Reply
Request Request
Request
Client application TP monitor
Server
Server
Server
35.
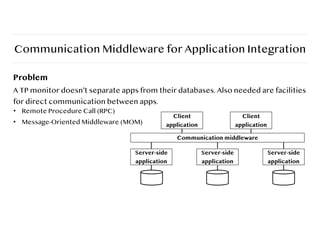
Communication Middleware forApplication Integration
Problem
A TP monitor doesn’t separate apps from their databases. Also needed are facilities
for direct communication between apps.
Client
application
Client
application
Communication middleware
Server-side
application
Server-side
application
Server-side
application
• Remote Procedure Call (RPC)
• Message-Oriented Middleware (MOM)
36.
How to IntegrateApplications
❖ File transfer — technically simple, but not flexible
❖ Figure out file format and layout
❖ Figure out file management
❖ Update propagation, and update notifications
❖ Shared database
❖ Much more flexible, but still requires common data scheme next to risk of bottleneck
❖ Remote procedure call
❖ Effective when execution of a series of actions is needed
❖ Messaging
❖ RPCs require caller and callee to be up and running at the same time. Messaging allows
decoupling in time and space.
37.
Distributed Pervasive Systems
Observation
Emergingnext-generation of distributed systems in which nodes are small, mobile, and often
embedded in a larger system, characterized by the fact that the system naturally blends into
the user’s environment
Some requirements
❖ Contextual change: The system is part of an environment in which changes should be immediately
accounted for.
❖ Ad hoc composition: Each nodes may be used in very different ways by different users. Requires
ease-of-configuration.
❖ Sharing is the default: Nodes come and go, providing sharable services and information. Calls again
for simplicity.
Note: Pervasiveness and distribution transparency: a good match?
38.
Distributed Pervasive Systems
Threesubtypes
❖ Ubiquitous computing systems
❖ pervasive and continuously present, i.e., there is a continuous interaction
between system and user.
❖ Mobile computing system
❖ pervasive, but emphasis is on the fact that devices are inherently mobile.
❖ Sensor systems
❖ pervasive, with emphasis on the actual (collaborative) sensing and actuation
of the environment
39.
Ubiquitous Systems
Core elements
❖(Distribution) Devices are networked, distributed, and accessible in a transparent
manner
❖ (Interaction) Interaction between users and devices is highly unobtrusive
❖ (Context awareness) The system is aware of a user’s context in order to optimize
interaction
❖ (Autonomy) Devices operate autonomously without human intervention, and are thus
highly self-managed
❖ (Intelligence) The system as a whole can handle a wide range of dynamic actions and
interactions
40.
Mobile Computing
Distinctive features
❖A myriad of different mobile devices (smartphones, tablets, GPS
devices, remote controls, active badges.
❖ Mobile implies that a device’s location is expected to change over time
⇒ change of local services, reachability, etc. Keyword: discovery.
❖ Communication may become more difficult: no stable route, but also
perhaps no guaranteed connectivity ⇒ disruption-tolerant networking.
❖
41.
Issues with MobileComputing
❖ What is the relationship between information dissemination and human
mobility? Basic idea: an encounter allows for the exchange of information
(pocket-switched networks)
❖ How to detect your community without having global knowledge
❖ How mobile are people?
❖
42.
Sensor Networks
Characteristics
The nodesto which sensors are attached are:
❖ Many (10s-1000s)
❖ Simple (small memory/compute/
communication capacity)
❖ Often battery-powered (or even battery-less)
❖
43.
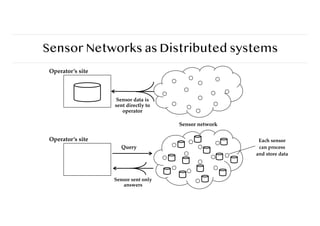
Sensor Networks asDistributed systems
Operator’s site
Sensor data is
sent directly to
operator
Sensor network
Operator’s site
Query
Sensor sent only
answers
Each sensor
can process
and store data
44.
Sensor Networks
Questions concerningsensor networks
❖ How do we (dynamically) set up an efficient tree in a sensor network?
❖ How does aggregation of results take place? Can it be controlled?
❖ What happens when network links fail?
❖ In-network data processing …
❖
45.
Pervasive Systems: Examples
Homesystems
Should be completely self-organizing:
❖ There should be no system administrator
❖ Provide a personal space for each of its users
❖ Simplest solution: a centralized home box?
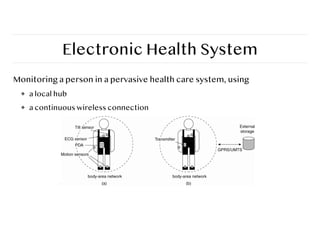
Electronic health systems
Devices are physically close to a person:
❖ Where and how should monitored data be stored?
❖ How can we prevent loss of crucial data?
❖ What is needed to generate and propagate alerts?
❖ How can security be enforced?
❖ How can physicians provide online feedback?
Architectural Styles
Basic idea
❖A style is formulated in terms of (replaceable) components with well-defined interfaces
the way that components are connected to each other
the data exchanged between components
how these components and connectors are jointly configured into a system
❖ Connector
❖ A mechanism that mediates communication, coordination, or cooperation among
components.
❖ Example: facilities for (remote) procedure call, messaging, or streaming.
❖
49
50.
Architectural Styles
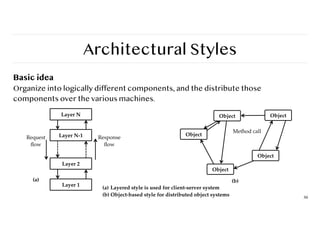
Basic idea
Organizeinto logically different components, and the distribute those
components over the various machines.
50
Layer N
Layer N-1
Layer 2
Layer 1
Response
fl
ow
Request
fl
ow
(a)
Object Object
Object
Object
Object
Method call
(b)
(a) Layered style is used for client-server system
(b) Object-based style for distributed object systems
51.
Architectural Styles
Observation
Decoupling processesin space (“anonymous”) and also time (“asynchronous”) has
led to alternative styles.
51
Event bus
Component Component
Component
Event delivery
Publish
(a)
(a) Publish/subscribe [decoupled in space]
(b) Shared data space [decoupled in space and time]
Shared (persistent)
data space
Component Component
Data delivery
(b)
Publish
52.
Centralized Architectures
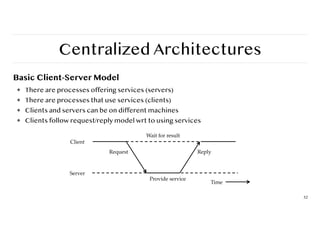
Basic Client-ServerModel
❖ There are processes offering services (servers)
❖ There are processes that use services (clients)
❖ Clients and servers can be on different machines
❖ Clients follow request/reply model wrt to using services
52
Client
Server
Request Reply
Wait for result
Provide service
Time
53.
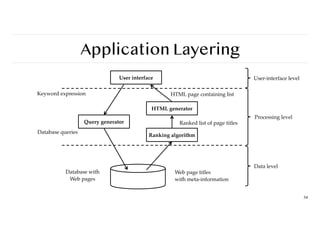
Application layering
Traditional three-layeredview
❖ User-interface layer contains units for an application’s user interface
❖ Processing layer contains the functions of an applications, i.e. without specific data
❖ Data layer contains the data that a client wants to manipulate through the
application components
Observation
This layering is found in many distributed information systems, using traditional
database technology and accompanying applications.
53
54.
Application Layering
54
User interface
Querygenerator
HTML generator
Ranking algorithm
Keyword expression
Database queries
Database with
Web pages
HTML page containing list
Ranked list of page titles
Web page titles
with meta-information
User-interface level
Processing level
Data level
55.
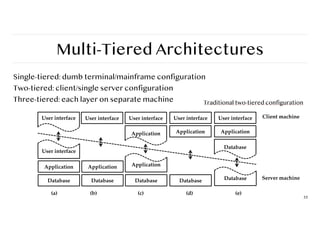
Multi-Tiered Architectures
Single-tiered: dumbterminal/mainframe configuration
Two-tiered: client/single server configuration
Three-tiered: each layer on separate machine
55
Traditional two-tiered configuration
User interface
User interface
User interface
Application
Application
User interface User interface
Application
Database
User interface
Application
Database
Database
Client machine
Server machine
(a) (b) (c) (d) (e)
Application Application
Database
Database
Database
56.
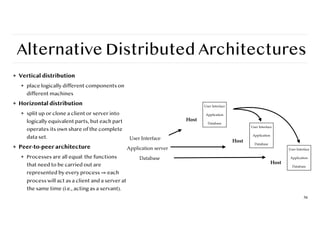
Alternative Distributed Architectures
❖Vertical distribution
❖ place logically different components on
different machines
❖ Horizontal distribution
❖ split up or clone a client or server into
logically equivalent parts, but each part
operates its own share of the complete
data set.
❖ Peer-to-peer architecture
❖ Processes are all equal: the functions
that need to be carried out are
represented by every process ⇒ each
process will act as a client and a server at
the same time (i.e., acting as a servant).
56
User Interface
Application server
Database
Host
Host
Host
User Interface
Application
Database
User Interface
Application
Database
User Interface
Application
Database
57.
Decentralized Architectures
Observation
In thelast couple of years we have been seeing a tremendous growth in peer-to-peer systems.
❖ Structured P2P: nodes are organized following a specific distributed data structure
❖ Unstructured P2P: nodes have randomly selected neighbors
❖ Hybrid-P2P: some nodes are appointed special functions in a well-organized fashion
Note
In virtually all cases, we are dealing with overly networks:
data is routed over connections setup between the nodes (cf. application-level
multicasting)
57
58.
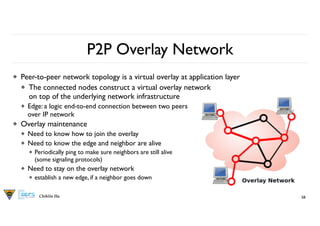
Chihlin Hu
P2P OverlayNetwork
❖ Peer-to-peer network topology is a virtual overlay at application layer
❖ The connected nodes construct a virtual overlay network
on top of the underlying network infrastructure
❖ Edge: a logic end-to-end connection between two peers
over IP network
❖ Overlay maintenance
❖ Need to know how to join the overlay
❖ Need to know the edge and neighbor are alive
❖ Periodically ping to make sure neighbors are still alive
(some signaling protocols)
❖ Need to stay on the overlay network
❖ establish a new edge, if a neighbor goes down
58
59.
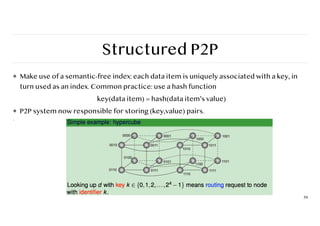
Structured P2P
❖ Makeuse of a semantic-free index: each data item is uniquely associated with a key, in
turn used as an index. Common practice: use a hash function
key(data item) = hash(data item’s value)
❖ P2P system now responsible for storing (key,value) pairs.
❖
59
60.
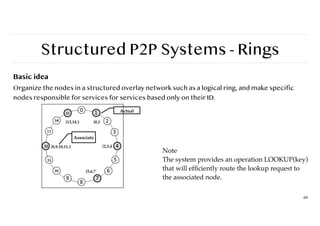
Structured P2P Systems- Rings
Basic idea
Organize the nodes in a structured overlay network such as a logical ring, and make specific
nodes responsible for services for services based only on their ID.
60
Note
The system provides an operation LOOKUP(key)
that will ef
fi
ciently route the lookup request to
the associated node.
{8,9,10,11,1
{13,14,1 {0,1
{2,3,4
{5,6,7
Actual
Associate
61.
Chihlin Hu
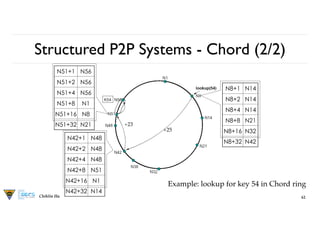
Structured P2PSystems - Chord (1/2)
61
fi
nger[k]: The
fi
rst node on circle that succeeds (n+2k-1) mod 2m, 1≤k≤m
• Nodes are logically organized in a ring.
• Each node has an m-bit identi
fi
er. Each data item is hashed to an m-bit key.
• Data item with key k is stored at node with smallest identi
fi
er id ≥ k , called
the successor of key k.
• The ring is extended with various shortcut links to other nodes.
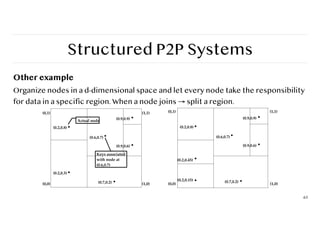
Structured P2P Systems
Otherexample
Organize nodes in a d-dimensional space and let every node take the responsibility
for data in a specific region. When a node joins → split a region.
63
(0.2,0.3)
(0.2,0.8)
(0.6,0.7)
(0.7,0.2)
(0.9,0.6)
(0.9,0.9)
Actual node
Keys associated
with node at
(0.6,0.7)
(0,0) (1,0)
(0,1) (1,1)
(0.2,0.15)
(0.2,0.8)
(0.6,0.7)
(0.7,0.2)
(0.9,0.6)
(0.9,0.9)
(0,0) (1,0)
(0,1) (1,1)
(0.2,0.45)
64.
Unstructured P2P Systems
Observation
Manyunstructured P2P systems attempt to maintain a random graph.
Basic principle
Each node is required to contact a randomly selected other node:
❖ Let each peer maintain a partial view of the network, consisting of c other nodes
❖ Each node P periodically selects a node Q from its partial view
❖ P and Q exchange information and exchange members from their respective partial views
Note
It turns out that, depending on the exchange, randomness, but also robustness of the
network can be maintained.
64
65.
Unstructured P2P Systems
❖Flooding: issuing node u passes request for d to all neighbors. Request is
ignored when receiving node had seen it before. Otherwise, v searches
locally for d (recursively). May be limited by a Time-To-Live: a maximum
number of hops.
❖ Random walk: issuing node u passes request for d to randomly chosen
neighbor, v. If v does not have d, it forwards request to one of its
randomly chosen neighbors, and so on.
❖
65
66.
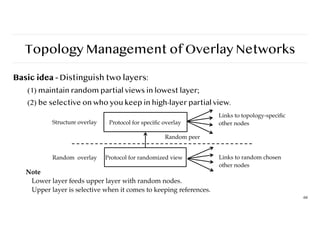
Topology Management ofOverlay Networks
Basic idea - Distinguish two layers:
(1) maintain random partial views in lowest layer;
(2) be selective on who you keep in high-layer partial view.
66
Protocol for speci
fi
c overlay
Protocol for randomized view
Structure overlay
Random overlay
Random peer
Links to topology-speci
fi
c
other nodes
Links to random chosen
other nodes
Note
Lower layer feeds upper layer with random nodes.
Upper layer is selective when it comes to keeping references.
67.
Topology Management ofOverlay Networks
❖ Constructing a torus that consider a NxN grid. Keep only references to
nearest neighbors:
|| (a1, a2) - (b1, b2) || = d1+d2
di = min( N - |ai - bi|, |ai - bi| )
67
time
68.
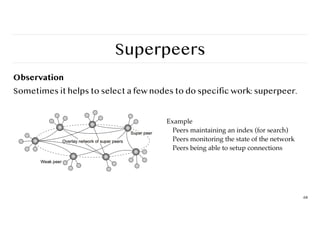
Superpeers
Observation
Sometimes it helpsto select a few nodes to do specific work: superpeer.
68
Example
Peers maintaining an index (for search)
Peers monitoring the state of the network
Peers being able to setup connections
69.
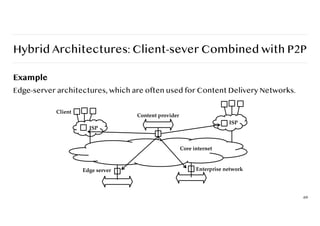
Hybrid Architectures: Client-severCombined with P2P
Example
Edge-server architectures, which are often used for Content Delivery Networks.
69
Content provider
ISP
ISP
Client
Edge server Enterprise network
Core internet
70.
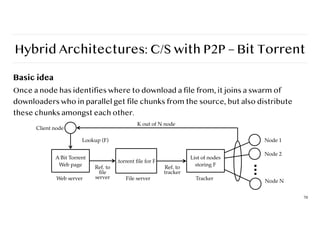
Hybrid Architectures: C/Swith P2P – Bit Torrent
Basic idea
Once a node has identifies where to download a file from, it joins a swarm of
downloaders who in parallel get file chunks from the source, but also distribute
these chunks amongst each other.
70
A Bit Torrent
Web page
.torrent
fi
le for F
List of nodes
storing F
Node 1
Node 2
Node N
K out of N node
Client node
Lookup (F)
Web server
Ref. to
fi
le
server File server
Ref. to
tracker
Tracker
71.
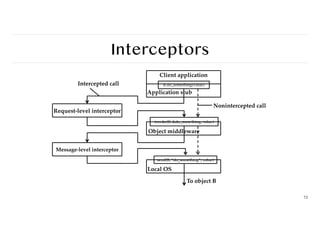
Architectures versus Middleware
❖Problem
In many cases, distributed systems/applications are developed
according to a specific architectural style. The chosen style may not be
optimal in all cases ⇒ need to (dynamically) adapt the behavior of the
middleware.
❖ Interceptors
Intercept the usual flow of control when invoking a remote object.
❖
71
The Need ofAdaptive Software
❖ Dynamics of environment
❖ The fact that the environment where distributed applications are
executed change continuously.
❖ Changes
❖ Variance in network QoS, hardware failing, battery drainage, etc.
❖ Middleware takes care of those
❖ Rather than making applications responsible for reacting to changes
❖
73
74.
Adaptive Middleware
❖ Separationof concerns
❖ Try to separate extra functionalities and later weave them together into a single implementation → only
toy examples so far.
❖ Computational reflection
❖ Let a program inspect itself at runtime and adapt/change its settings dynamically if necessary → mostly
at language level and applicability unclear.
❖ Component-based design
❖ Organize a distributed application through components that cam be dynamically replaced when
needed → highly complex, also many inter-component dependencies.
Fundamental question
Do we need adaptive software at all, or is the issue adaptive systems?
74
75.
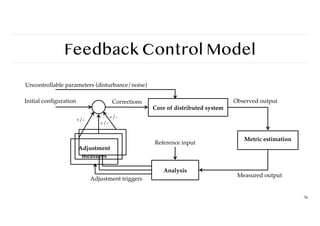
Self-managing Distributed Systems
Observation
Distinctionbetween system and software architectures blurs when automatic adaptivity needs to be taken
into account:
❖ Self-configuration
❖ Self-managing
❖ Self-healing
❖ Self-optimizing
❖ Self-*
Note
In many cases, self-* systems are organized as a feedback control system.
Warning
There is a lot of hype going on in this field of autonomic computing.
75
76.
Feedback Control Model
76
+/-
+/-
+/-
Analysis
Coreof distributed system
Metric estimation
Uncontrollable parameters (disturbance/noise)
Observed output
Measured output
Adjustment triggers
Initial con
fi
guration Corrections
Reference input
Adjustment
measures
77.
Example: Globule
❖ Globule
CollaborativeCDN that analyzes traces to decide where replicas of Web
content should be placed. Decisions are driven by a general cost model:
cost = (w1× m1)+(w2× m2) + ··· + (wn× mn)
❖
77
78.
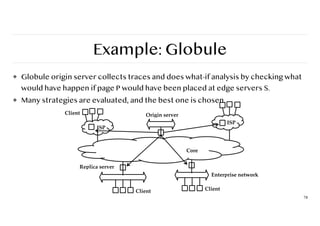
Example: Globule
❖ Globuleorigin server collects traces and does what-if analysis by checking what
would have happen if page P would have been placed at edge servers S.
❖ Many strategies are evaluated, and the best one is chosen.
78
Origin server
ISP
ISP
Client
Replica server
Enterprise network
Core
Client Client
79.
Prediction Accuracy versusTrace Length
❖ Dependency b/w prediction accuracy and trace length
❖ As a result of a very long trace that captures so many changes in access
pattern, predicting the best policy to follow become difficult somewhat.
79
Low-level layers
Recap
❖ Physicallayer: contains the specification and implementation
of bits, and their transmission between sender and receiver
❖ Data link layer: prescribes the transmission of a series of a
series of bits into a frame to allow for error and flow control
❖ Network layer: describes how packets in a network of
computers are to be routed.
Observation
For many distributed systems, the lowest-level interface is that
of the network layer.
82
83.
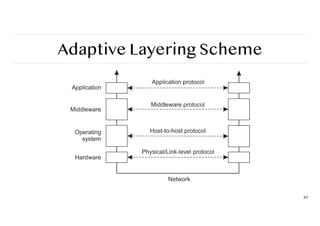
Transport Layer
Important
The transportlayer provides actual communication facilities for most distributed systems.
Standard Internet protocols
❖ TCP: connection-oriented, reliable, stream-oriented communication
❖ UDP: unreliable (best-effort) datagram communication
Note
IP multicasting is often considered a standard available service (which may be dangerous to
assume).
83
84.
Middleware Layer
Observation
Middleware isinvented to provide common services and protocols that can be used by many
different applications
❖ A rich set of communication protocols
❖ (Un)marshaling of data, necessary for integrated systems
❖ Naming protocols, to allow easy sharing of resources
❖ Security protocols for secure communication
❖ Scaling mechanisms, such as for replication and caching
Note
What remains are truly application-specific protocols… such as?
84
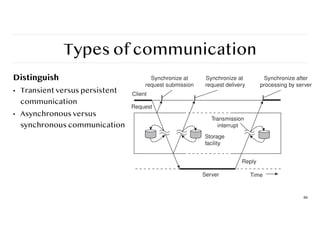
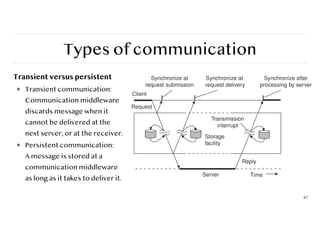
Types of communication
Transientversus persistent
❖ Transient communication:
Communication middleware
discards message when it
cannot be delivered at the
next server, or at the receiver.
❖ Persistent communication:
A message is stored at a
communication middleware
as long as it takes to deliver it.
87
88.
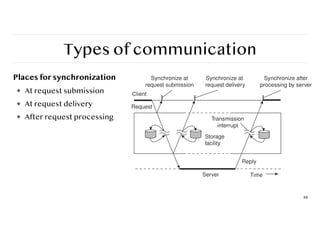
Types of communication
Placesfor synchronization
❖ At request submission
❖ At request delivery
❖ After request processing
88
Synchronize at Synchronize at Synchronize after
89.
Client/Server
Some observation
Client/server computingis generally based on a model of transient synchronous communication:
❖ Client and server have to be active at time of communication
❖ Client issues request and blocks until it receives reply
❖ Servers essentially waits only for incoming requests, and subsequently processes them
Drawbacks synchronous communication
❖ Client cannot do any other work while waiting for reply
❖ Failures have to be handled immediately: the client is waiting
❖ The model may simply not be appropriate (mail, news)
89
90.
Messaging
Message-oriented middleware
Aims athigh-level persistent asynchronous communication:
❖ Processes send each other messages, which are queued
❖ Sender need not wait for immediate reply, but can do other things
❖ Middleware often ensure fault tolerance
90
91.
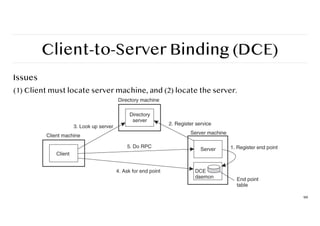
Remote Procedure Call(RPC)
Observations
❖ Application developers are familiar with a simple procedure model
❖ Well-engineered procedures operate in isolation (black box)
❖ There is no fundamental reason not to execute procedures on separate machine
Conclusion
Communication between caller & callee
can be hidden by using
procedure-call machine
91
Wait for result
Client
Request Reply
Call local procedure
and return results
Time →
Server
Call remote
procedure
Return from
call
92.
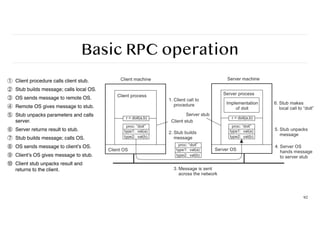
Basic RPC operation
92
①Client procedure calls client stub.
② Stub builds message; calls local OS.
③ OS sends message to remote OS.
④ Remote OS gives message to stub.
⑤ Stub unpacks parameters and calls
server.
⑥ Server returns result to stub.
⑦ Stub builds message; calls OS.
⑧ OS sends message to client’s OS.
⑨ Client’s OS gives message to stub.
⑩ Client stub unpacks result and
returns to the client.
93.
RPC: Parameter passing
Parametermarshaling
There’s more than just wrapping parameters into a message:
❖ Client and server machines may have different data representations (think of byte ordering)
❖ Wrapping a parameter means transforming a value into a sequence of bytes
❖ Client and server have to agree on the same encoding:
❖ How are basic data values represented (integers, floats, characters)
❖ How are complex data values represents (arrays, unions)
❖ Client and server need to properly interpret messages, transforming them into machine-
dependent representations.
93
94.
RPC: Parameter passing
Someassumptions
❖ Copy in/copy out semantics: while procedure is executed, nothing can be assumed about parameter values.
❖ All data that is to be operated on is passed by parameters.
Excludes passing references to (global) data.
Conclusion
Full access transparency cannot be realized.
Observation
A remote reference mechanism enhances access transparency:
❖ Remote reference offers unified access to remote data
❖ Remote reference can be passed as parameter in RPCs
94
*call by reference can be replaced by copy/store
95.
RPC: stub generation
❖Message format
❖ Encoding
❖ Transport protocol of message exchange
❖ IDL interfaces b/w client and server stubs
95
96.
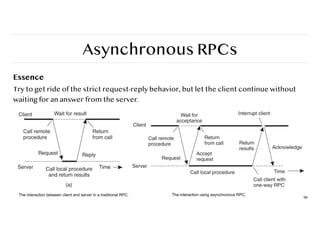
Asynchronous RPCs
Essence
Try toget ride of the strict request-reply behavior, but let the client continue without
waiting for an answer from the server.
96
The interaction using asynchronous RPC.
The interaction between client and server in a traditional RPC.
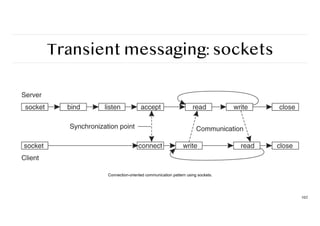
Transient messaging: sockets
Berkeleysocket interface
101
STOCKET Create a new communica
ti
on endpoint
BIND A
tt
ach a local address to a socket
LISTEN Announce willingness to accept N connec
ti
ons
ACCEPT Block un
ti
l request to establish a connec
ti
on
CONNECT A
tt
empt to establish a connec
ti
on
SEND Send data over a connec
ti
on
RECEIVE Receive data over a connec
ti
on
CLOSE Release the connec
ti
on
Making sockets easierto work with
Observation
❖ Sockets are rather low level and programming mistakes are easily made. However, the way that they are
used is often the same (such as in a client-server setting).
Alternative: ZeroMQ
❖ Provides a higher level of expression by pairing sockets: one for sending messages at process P
and a corresponding one at process Q for receiving messages. All communication is
asynchronous.
Three patterns
❖ Request-reply
❖ Publish-subscribe
❖ Pipeline
103
104.
Message-oriented middleware
Essence
Asynchronous persistentcommunication by support of middleware-level queues.
Queues correspond to buffers at communication servers.
104
PUT Append a message to a speci
fi
ed queue
GET
Block un
ti
l the speci
fi
ed queue is nonempty, and
remove the
fi
rst message
POLL
Check a speci
fi
ed queue for messages, and remove
the
fi
rst. Never block
NOTIFY
Install a handler to be called when a message is put
into the speci
fi
ed queue
105.
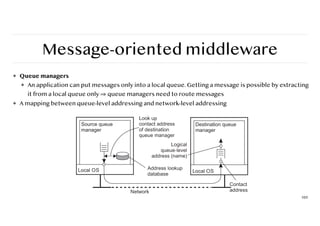
Message-oriented middleware
❖ Queuemanagers
❖ An application can put messages only into a local queue. Getting a message is possible by extracting
it from a local queue only ⇒ queue managers need to route messages
❖ A mapping between queue-level addressing and network-level addressing
105
106.
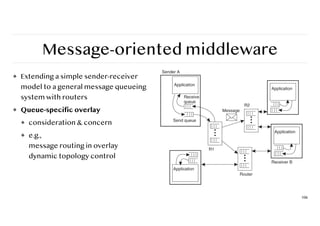
Message-oriented middleware
❖ Extendinga simple sender-receiver
model to a general message queueing
system with routers
❖ Queue-specific overlay
❖ consideration & concern
❖ e.g.,
message routing in overlay
dynamic topology control
106
107.
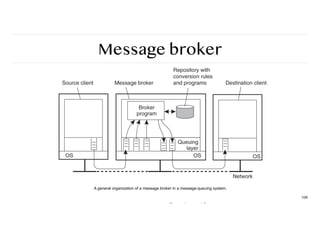
Message broker
Observation
Message queuingsystems assume a common messaging protocol:
all applications agree on message format (i.e., structure and data representation)
Message broker
Centralized component that takes care of application heterogeneity in an MQ system:
❖ Transforms incoming messages to target format
❖ Very often acts as an application gateway
❖ May provide subject-based routing capabilities → Enterprise Application Integration
107
that is, a publish/subscribe model
IBM’s WebSphere MQ
Basicconcepts
❖ Application-specific messages are put into, and removed from queues
❖ Queues reside under the regime of a queue manager
❖ Processes can put messages only in local queues, or through an RPC mechanism
Message transfer
❖ Messages are transferred between queues
❖ Message transfer between queues at different processes, requires a channel
❖ At each endpoint of channel is a message channel agent
❖ Message channel agents are responsible for:
❖ Setting up channels using lower-level network communication facilities (e.g., TCP/IP)
❖ (Un)wrapping messages from/in transport-level packets
❖ Sending/receiving packets
109
110.
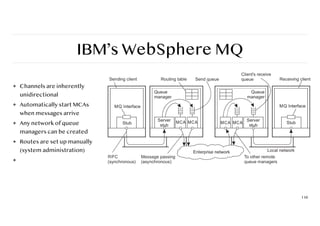
IBM’s WebSphere MQ
❖Channels are inherently
unidirectional
❖ Automatically start MCAs
when messages arrive
❖ Any network of queue
managers can be created
❖ Routes are set up manually
(system administration)
❖
110
111.
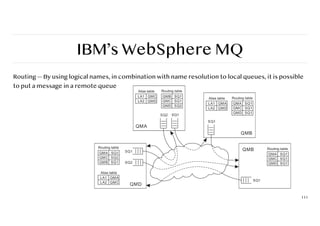
IBM’s WebSphere MQ
Routing— By using logical names, in combination with name resolution to local queues, it is possible
to put a message in a remote queue
111
Stream-oriented communication
Observation
All communicationfacilities discussed so far are essentially based on a discrete, that is
time-independent exchange of information
Continuous media
Characterized by the fact that value are time independent:
❖ Audio
❖ Video
❖ Animations
❖ Sensor data (temperature, pressure, etc.)
113
114.
Continuous media
Transmission modes
Differenttiming guarantees with respect to data transfer:
❖ Asynchronous: no restrictions with respect to when data is to be delivered
❖ Synchronous: define a maximum end-to-end delay for individual data packets
❖ Isochronous: define a maximum and minimum end-to-end delay (jitter is
bounded)
114
115.
Stream
Definition
A (continuous) datastream is a connection-oriented communication facility that supports
isochronous data transmission.
Some common stream characteristics
❖ Streams are unidirectional
❖ There is generally a signal source, and one or more sinks
❖ Often, either the sink and/or source is a wrapper around hardware (e.g., camera, CD device, TV
monitor)
❖ Simple stream: a single flow of data, e.g., audio or video
❖ Complex stream: multiple data flows, e.g., stereo audio or combination audio/video
115
116.
Streams and QoS
Essence
Streamsare all about timely delivery of data. How do you specify this Quality of Service
(QoS)?
Basics:
❖ The required bit rate at which data should be transported.
❖ The maximum delay until a session has been set up (i.e., when an application can start sending
data).
❖ The maximum end-to-end delay (i.e., how long it will take until a data unit makes it to a recipient).
❖ The maximum delay variance, or jitter.
❖ The maximum round-trip delay.
116
117.
Enforcing QoS
Observation
There arevarious network-level tools, such as differentiated services by which certain packets can
be prioritized
Also
Use buffers to reduce jitter:
117
118.
Enforcing QoS
❖ Problem
Howto reduce the effects of packet loss (when multiple samples are in a
single packet)?
118
Application-level multicasting
Essence
Organize nodesof a distributed system into an overlay network and use that network to deliver data.
Chord-based tree building
1. Initiator generates a multicast identifier mid.
2. Lookup succ(mid), the node responsible for mid.
3. Request is routed to succ(mid), which will become the root.
4. If P wants to join, it sends a join request to the root.
5. When request arrives at Q:
❖ Q has not seen a join request before → it becomes forwarder; P becomes child of Q. Join request
continues to be forward.
❖ Q knows about tree → P becomes child of Q. No need to forward join request anymore.
121
122.
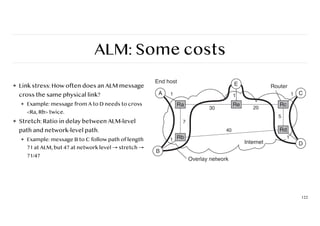
ALM: Some costs
❖Link stress: How often does an ALM message
cross the same physical link?
❖ Example: message from A to D needs to cross
<Ra, Rb> twice.
❖ Stretch: Ratio in delay between ALM-level
path and network-level path.
❖ Example: message B to C follow path of length
71 at ALM, but 47 at network level → stretch →
71/47
122
123.
Epidemic Algorithms
Basic idea
Assumethere are no write-write conflicts:
❖ Update operations are performed at a single server
❖ A replica passes updated state to only a few neighbors
❖ Update propagation is lazy, i.e., not immediate
❖ Eventually, each update should reach every replica
Two forms of epidemics
❖ Anti-entropy: Each replica regularly chooses another replica at random, and exchanges state
differences, leading to identical states at both afterwards
❖ Gossiping: A replica which has just been update (i.e., has been contaminated), tells a number of other
replica about its update (contaminating them as well)
123
124.
Anti-entropy
Principle operations
❖ Anode P selects another node Q from the system at random.
❖ Push: P only sends its updates to Q
❖ Pull: P only retrieves updates from Q
❖ Push-Pull: P and Q exchange mutual updates (after which they hold the same
information).
Observation
For push-pull it takes O(log(N)) rounds to disseminate updates to all N nodes (round =
when every node as taken the initiative to start an exchange).
124
125.
Gossiping
Basic model
❖ Aserver S having an update to report, contacts other servers. If a server
is contacted to which the update has already propagated, S stops
contacting other servers with probability 1/k.
Observation
If s is the fraction of ignorant servers (i.e., which are unaware of the update),
it can be shown that with many servers
s = e^-(k+1)(1-s)
125
126.
Deleting values
Fundamental problem
Wecannot remove an old value from a server and expect the removal to
propagate. Instead, more removal will be undone in due time using epidemic
algorithms
Solution
Removal has to be registered as a special update by inserting a death
certificate
126
127.
Deleting values
Next problem
Whento remove a death certificate (it is not allowed to stay for ever):
❖ Run a global algorithm to detect whether the removal is known
everywhere, and then collect the death certificates (looks like garbage
collection)
❖ Assume death certificates propagate in finite time, and associate a
maximum lifetime for a certificate (can be done at risk of not reaching all
servers)
127
























![Distributed Computing Systems
Cloud computing
Three Flavours of Cloud – the “service models”
❖ Software-as-a-Service (SaaS)
These are usually applications or services that you access via a Web browser. Google Mail and Google Docs
are examples of this kind of cloud computing.
❖ Platform-as-a-Service (PaaS)
This is a set of lower-level services such as an operating system or computer language interpreter or web
server offered by a cloud provider to software developers. Microsoft Windows Azure and Google App Engine
are examples of PaaS.
❖ Infrastructure-as-a-Service (IaaS)
IaaS is the provision of virtual servers and storage that organisations use on a pay-as-you-go basis. Amazon’s
Elastic Compute Cloud (EC2) and Simple Storage Service (S3) are examples of IaaS.
[ref] https://www.katescomment.com/what-is-cloud-computing/](https://image.slidesharecdn.com/lecturenoteii0325-250519064153-31f9b7c2/85/Distributed-Network-Computing-and-System-28-320.jpg)















![Architectural Styles
Observation
Decoupling processes in space (“anonymous”) and also time (“asynchronous”) has
led to alternative styles.
51
Event bus
Component Component
Component
Event delivery
Publish
(a)
(a) Publish/subscribe [decoupled in space]
(b) Shared data space [decoupled in space and time]
Shared (persistent)
data space
Component Component
Data delivery
(b)
Publish](https://image.slidesharecdn.com/lecturenoteii0325-250519064153-31f9b7c2/85/Distributed-Network-Computing-and-System-51-320.jpg)


![Chihlin Hu
Structured P2P Systems - Chord (1/2)
61
fi
nger[k]: The
fi
rst node on circle that succeeds (n+2k-1) mod 2m, 1≤k≤m
• Nodes are logically organized in a ring.
• Each node has an m-bit identi
fi
er. Each data item is hashed to an m-bit key.
• Data item with key k is stored at node with smallest identi
fi
er id ≥ k , called
the successor of key k.
• The ring is extended with various shortcut links to other nodes.](https://image.slidesharecdn.com/lecturenoteii0325-250519064153-31f9b7c2/85/Distributed-Network-Computing-and-System-61-320.jpg)