Download to read offline








![Reproduce,
Replicate,
Repeat …
Wait!
Mind your
vocabulary!
Ludäscher & Núñez-Corrales
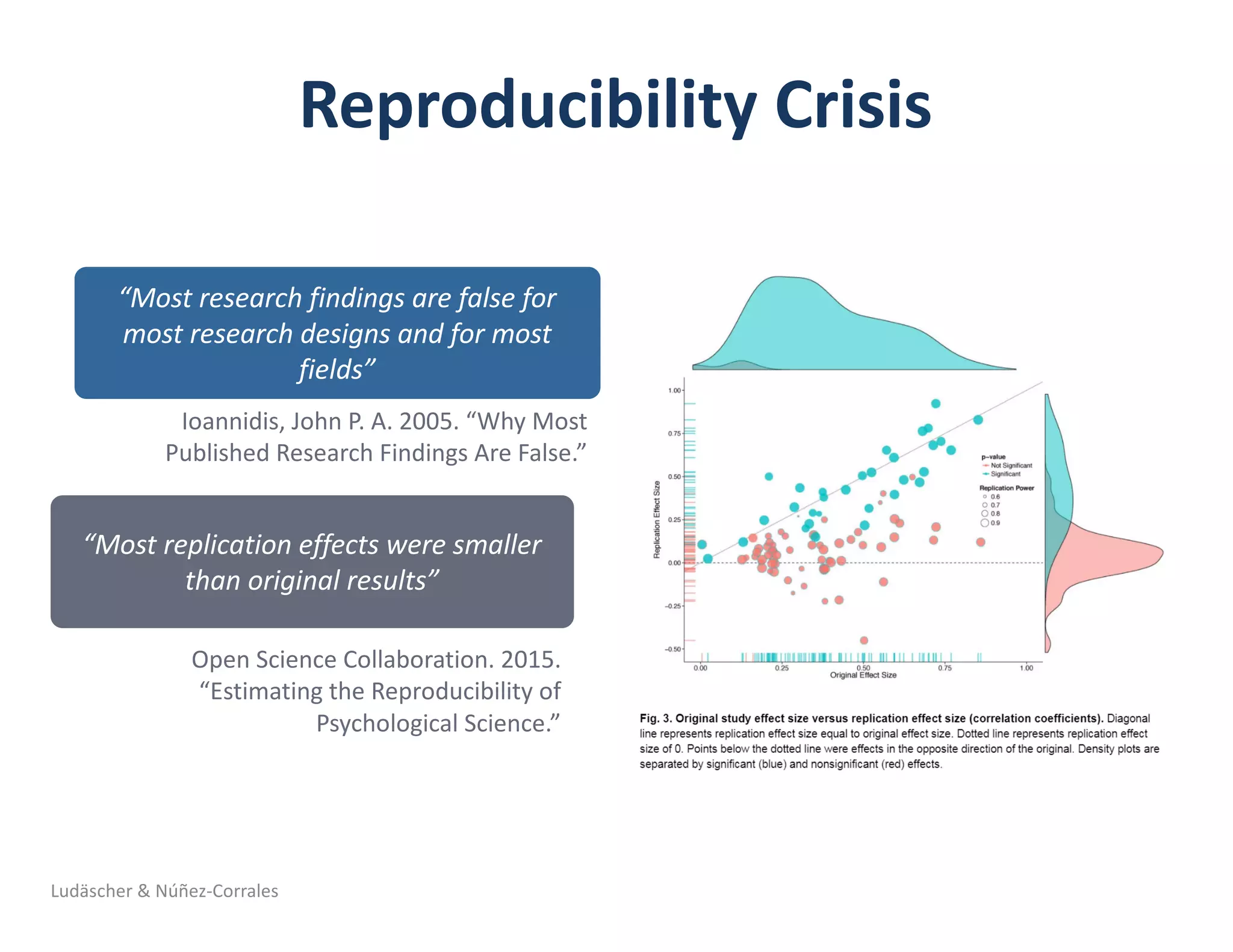
Barba, Lorena A. 2018. “Terminologies for Reproducible Research.”
ArXiv:1802.03311 [Cs], February. http://arxiv.org/abs/1802.03311.](https://image.slidesharecdn.com/2018-10-hoh3-ludaescher-181012092954/75/Dissecting-Reproducibility-A-case-study-with-ecological-niche-models-in-the-Whole-Tale-environment-14-2048.jpg)
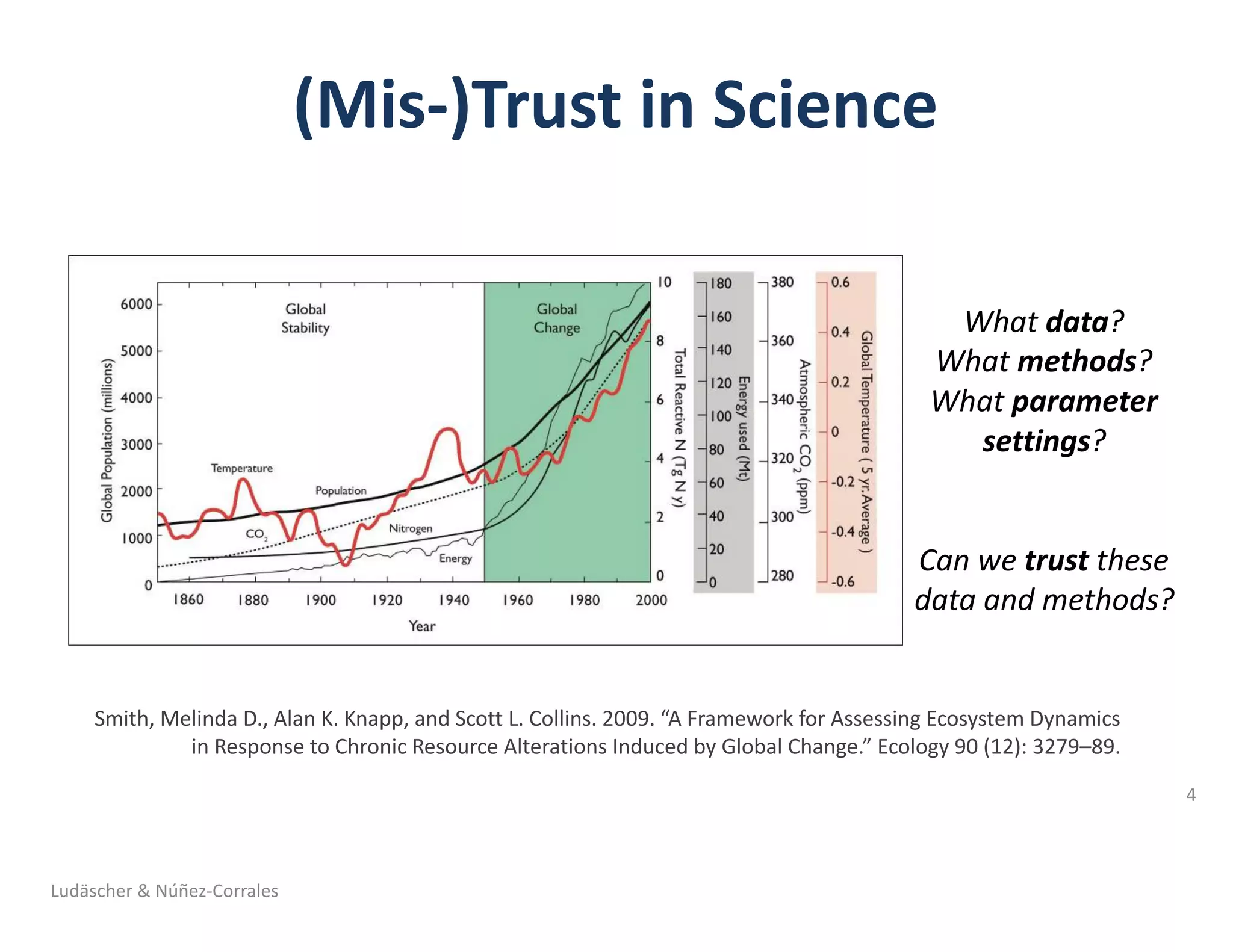
![Ludäscher & Núñez-Corrales
Barba, Lorena A. 2018. “Terminologies for Reproducible Research.”
ArXiv:1802.03311 [Cs], February. http://arxiv.org/abs/1802.03311.](https://image.slidesharecdn.com/2018-10-hoh3-ludaescher-181012092954/75/Dissecting-Reproducibility-A-case-study-with-ecological-niche-models-in-the-Whole-Tale-environment-15-2048.jpg)
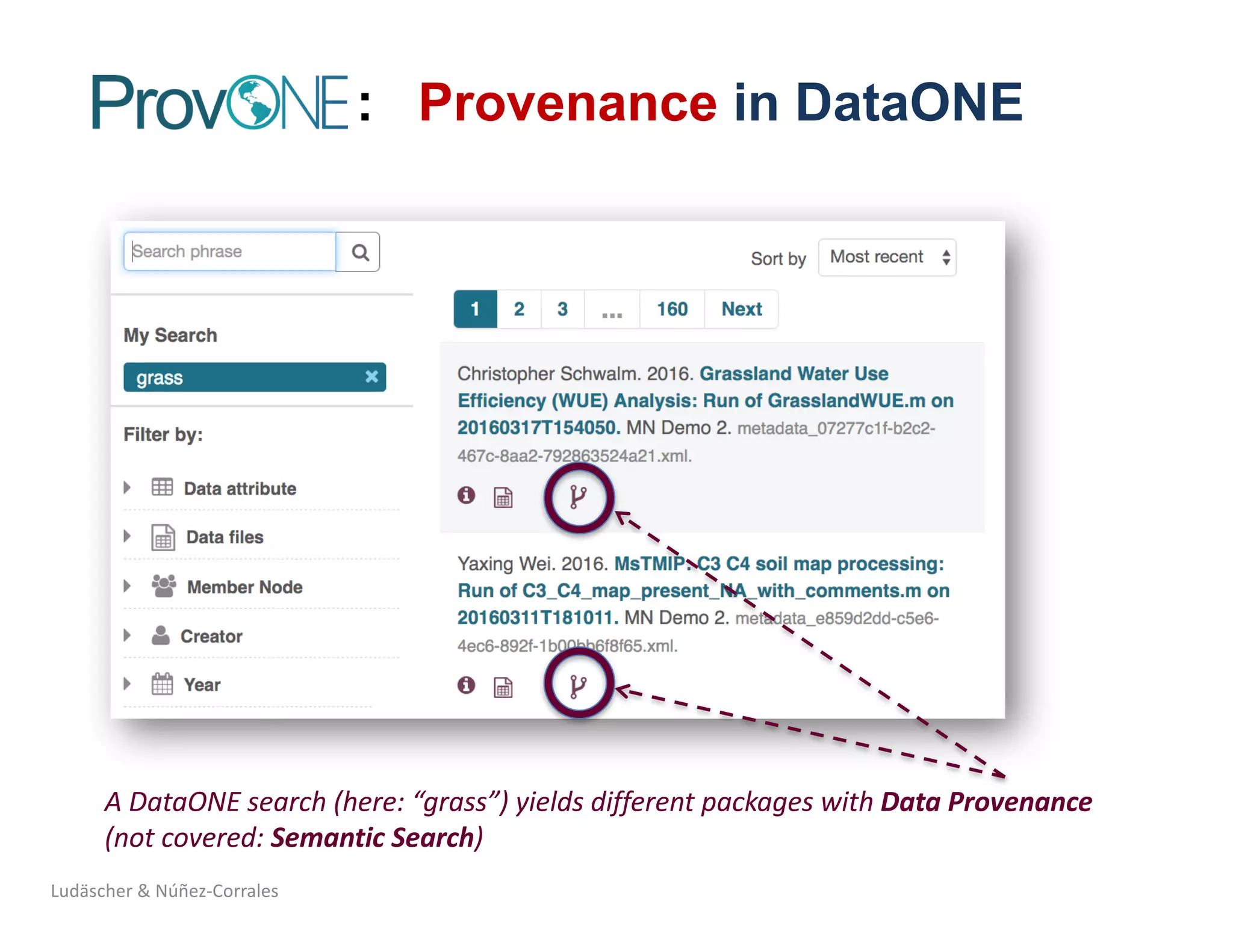
![Ludäscher & Núñez-Corrales
Plesser, Hans E. 2018. “Reproducibility vs.
Replicability: A Brief History of a Confused
Terminology.” Frontiers in Neuroinformatics 11.
https://doi.org/10.3389/fninf.2017.00076.
Barba, Lorena A. 2018. “Terminologies for
Reproducible Research.” ArXiv:1802.03311 [Cs],
February. http://arxiv.org/abs/1802.03311.](https://image.slidesharecdn.com/2018-10-hoh3-ludaescher-181012092954/75/Dissecting-Reproducibility-A-case-study-with-ecological-niche-models-in-the-Whole-Tale-environment-16-2048.jpg)














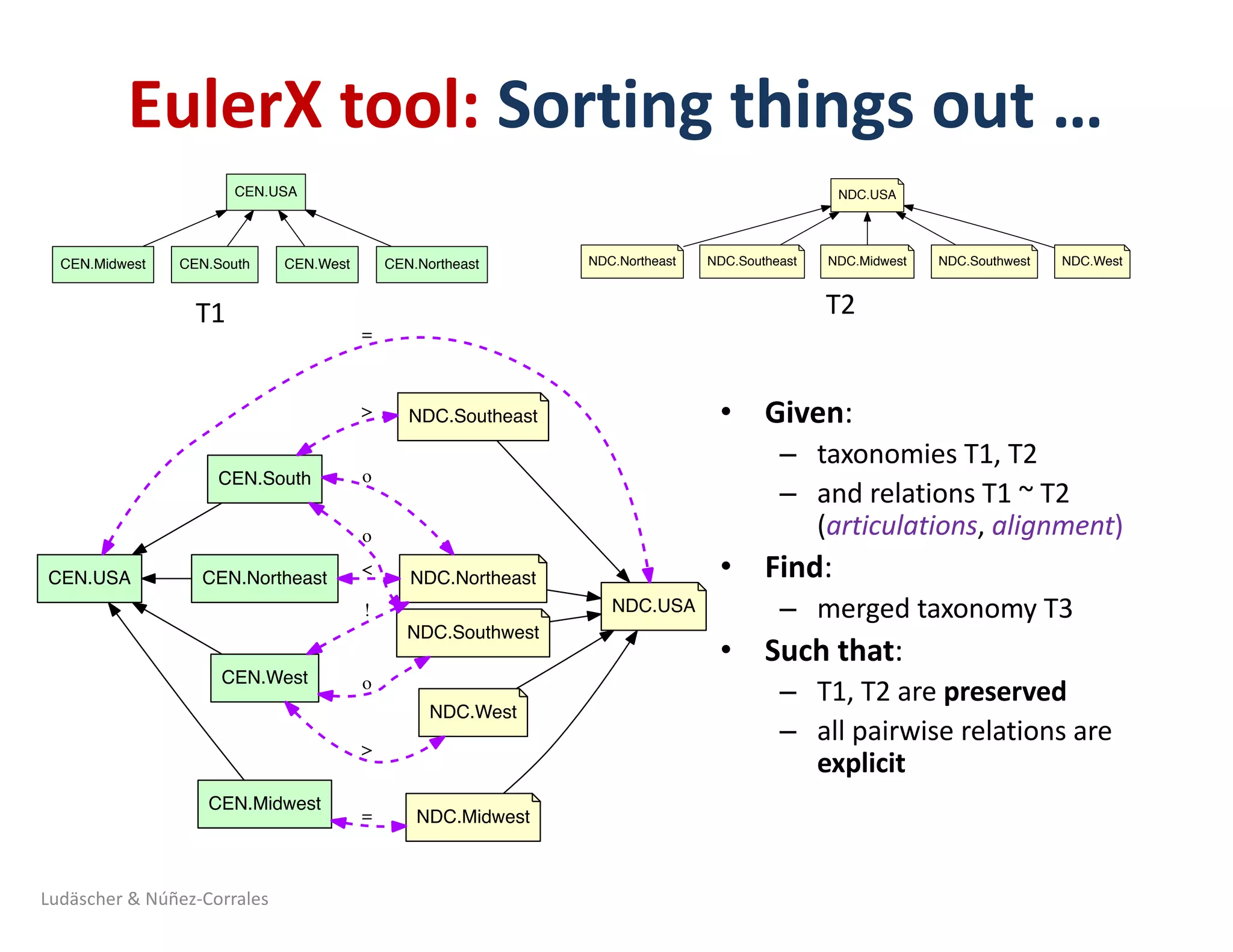
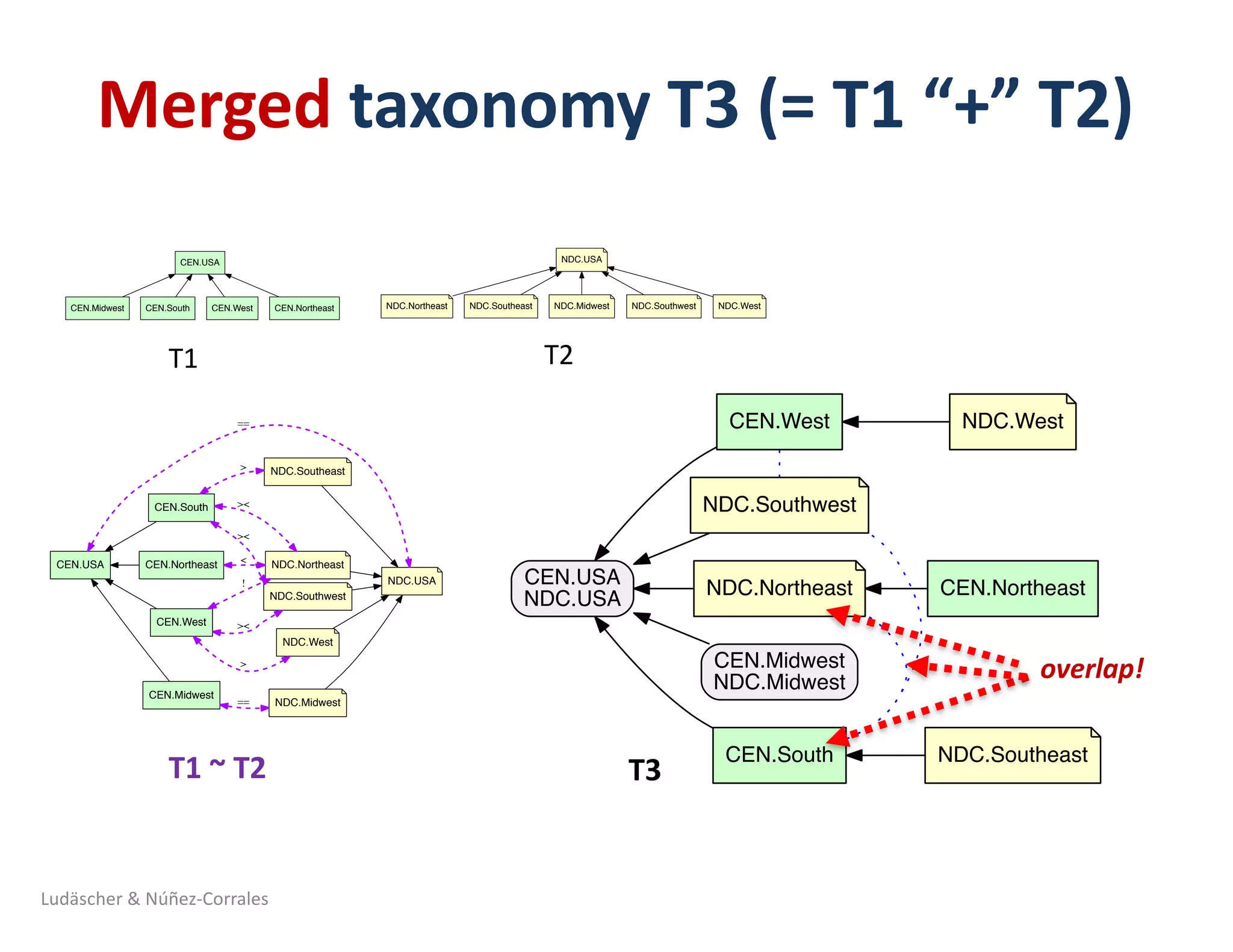
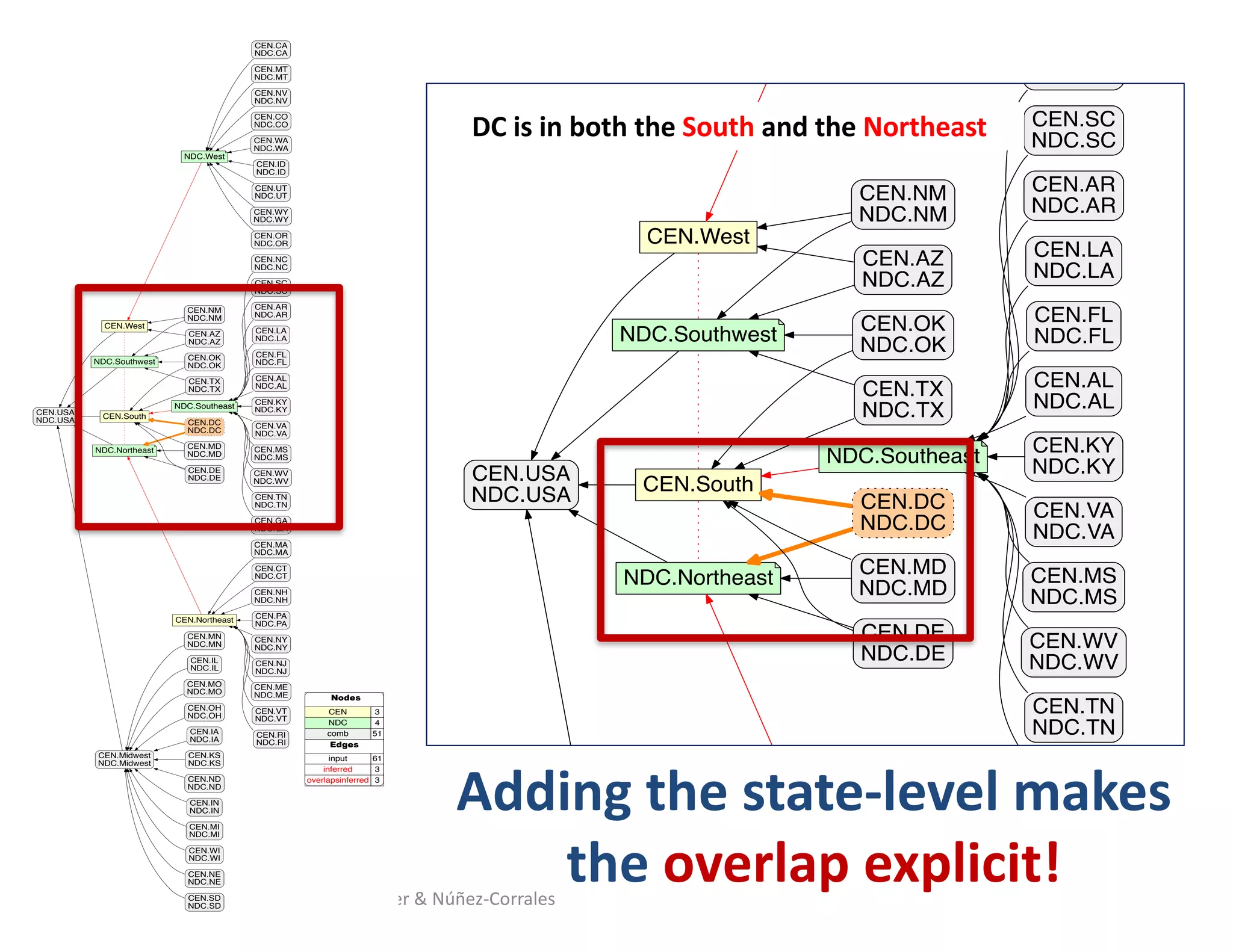
![Half-Smokes in DC: Typical for the Northeast?
… or the South !? (A tale of two taxonomies: NDC vs CEN)
“…in the face of incompatible information or data structures among users or among those specifying
the system, attempts to create unitary knowledge categories are futile. Rather, parallel or multiple
representational forms are required” [Bowker & Star, 2000, p.159]
West
Southwest Southeast
Midwest North-
east
West
South
Midwest North-
east
National Diversity Council map (NDC) US Census Buero map (CEN)
Source: Yi-Yun (Jessica) Cheng (PhD student, iSchool @ Illinois)
Ludäscher & Núñez-Corrales](https://image.slidesharecdn.com/2018-10-hoh3-ludaescher-181012092954/75/Dissecting-Reproducibility-A-case-study-with-ecological-niche-models-in-the-Whole-Tale-environment-45-2048.jpg)



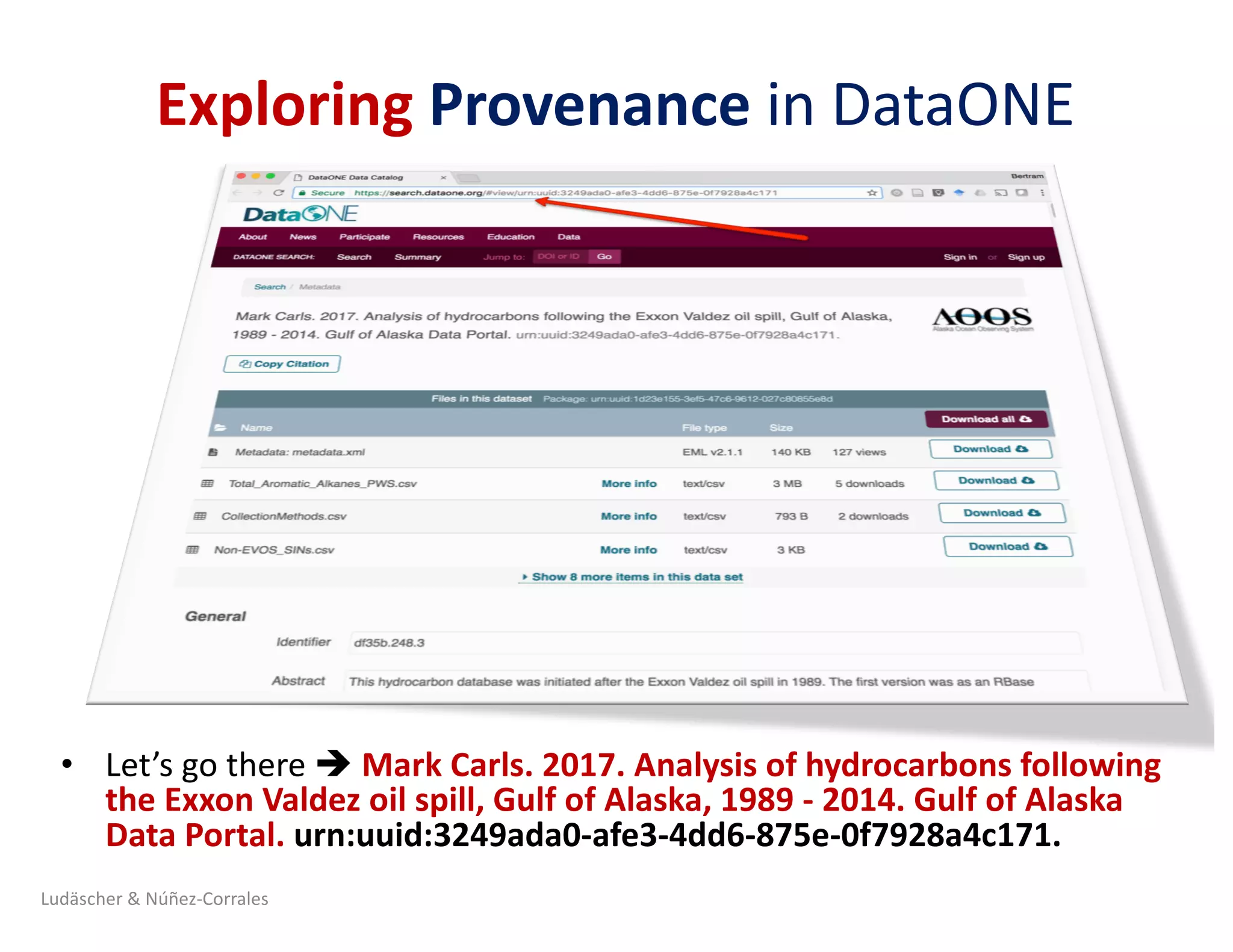
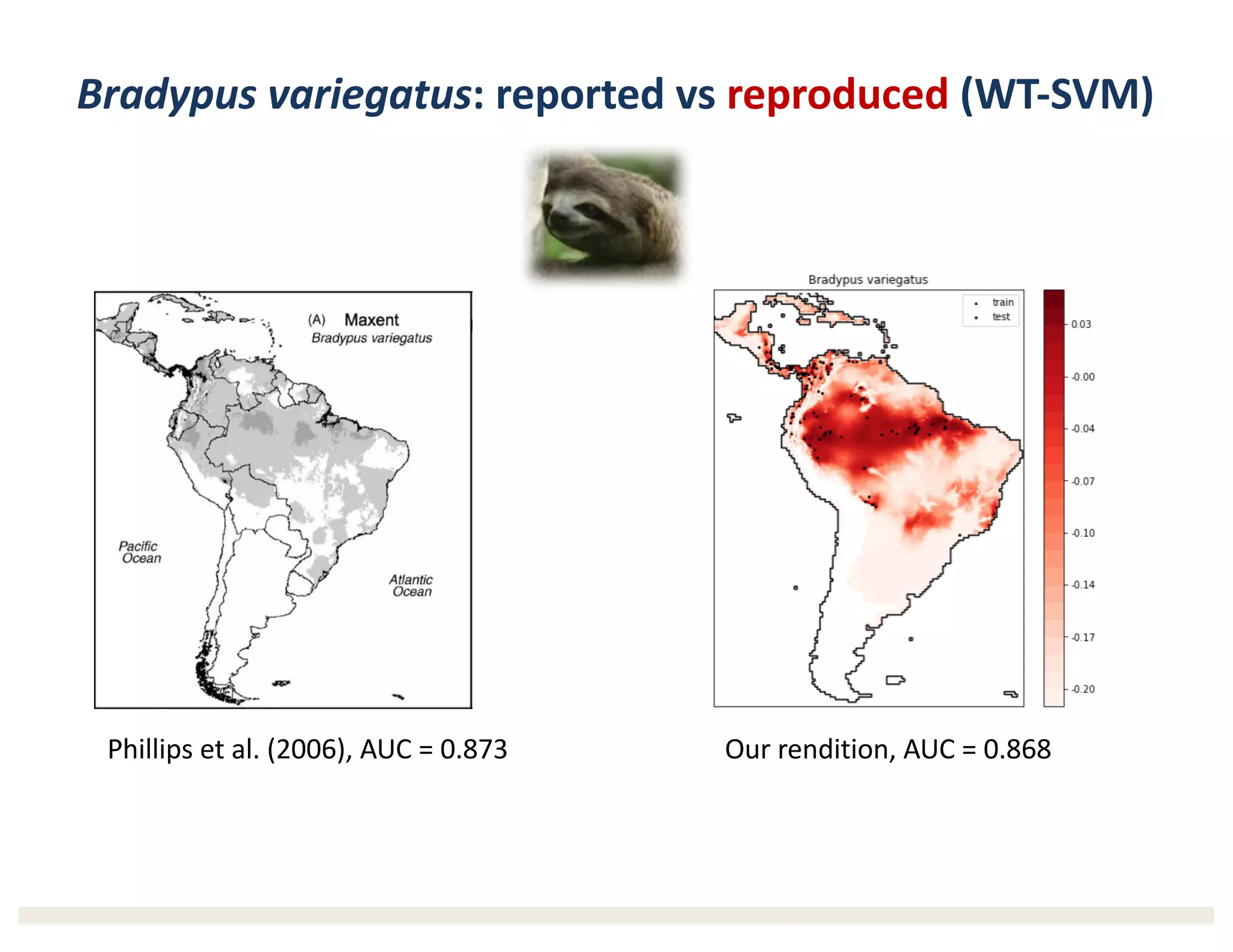
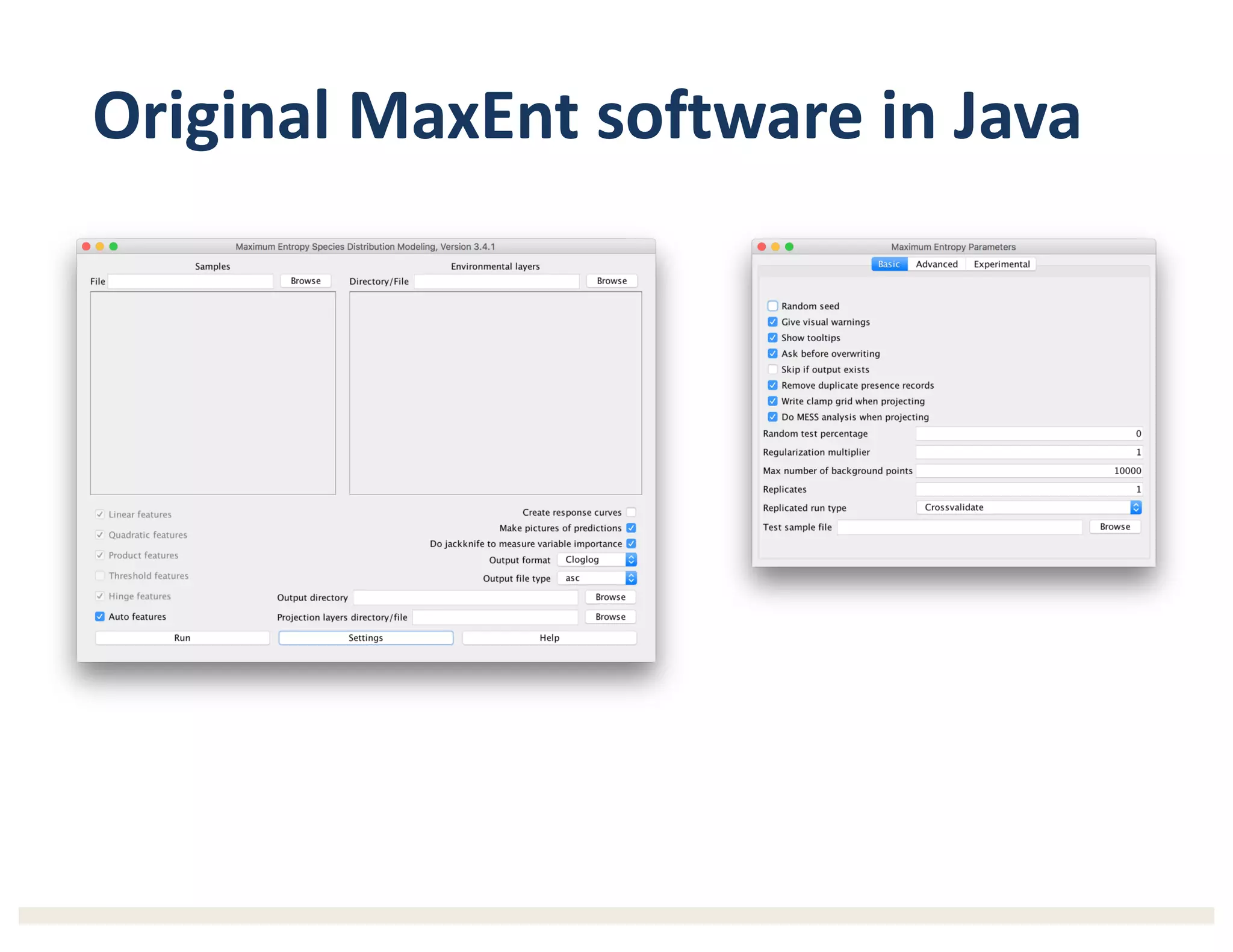
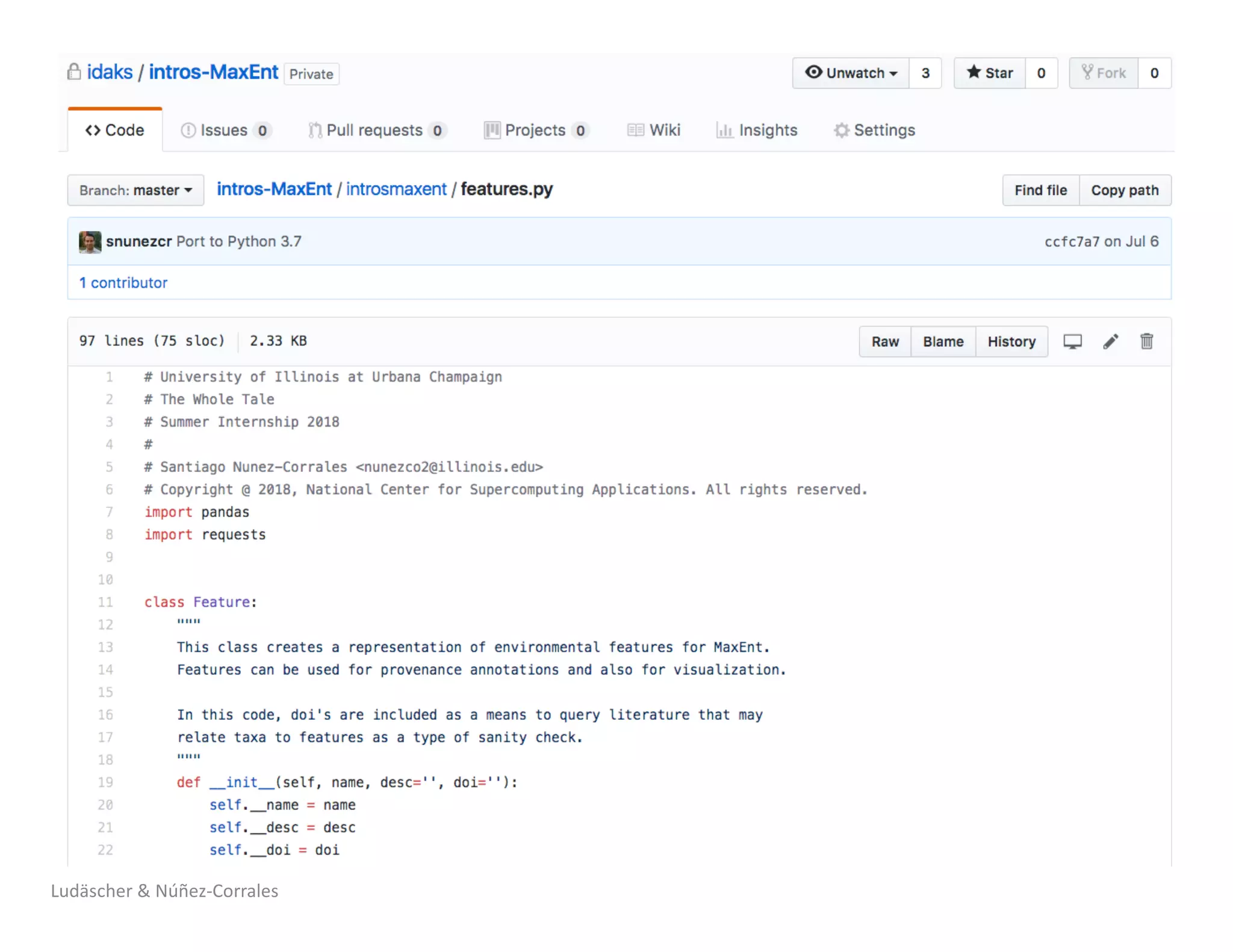
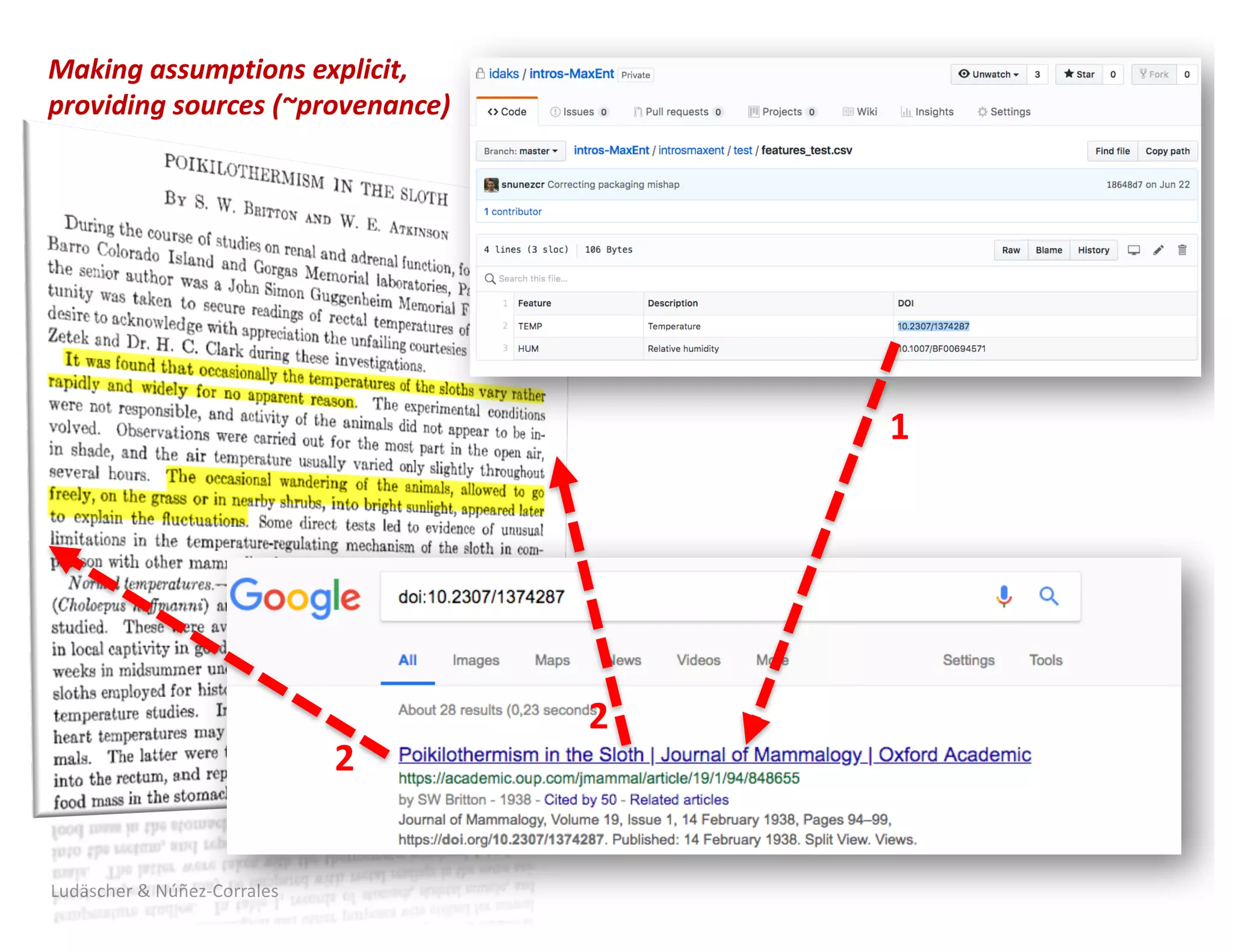
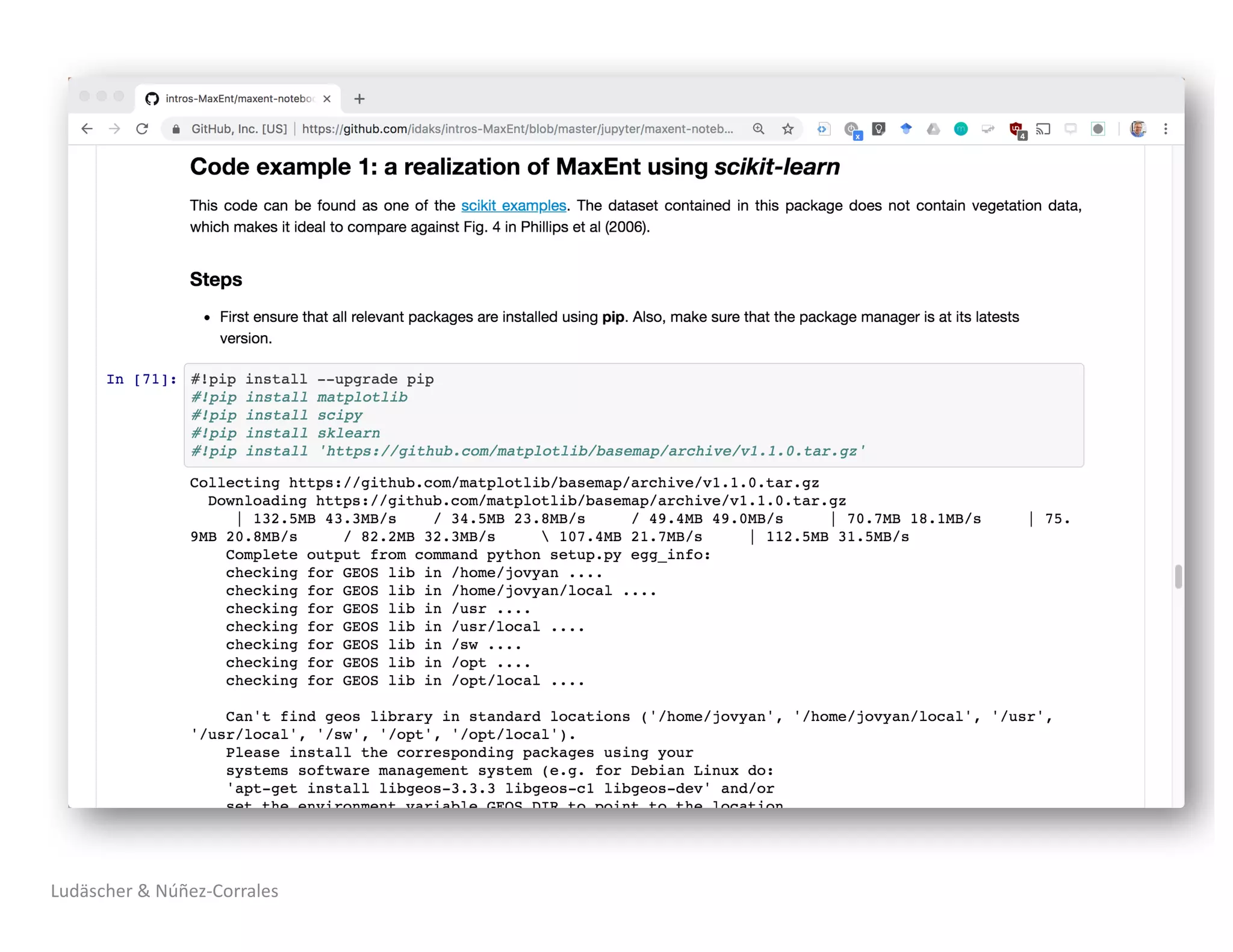
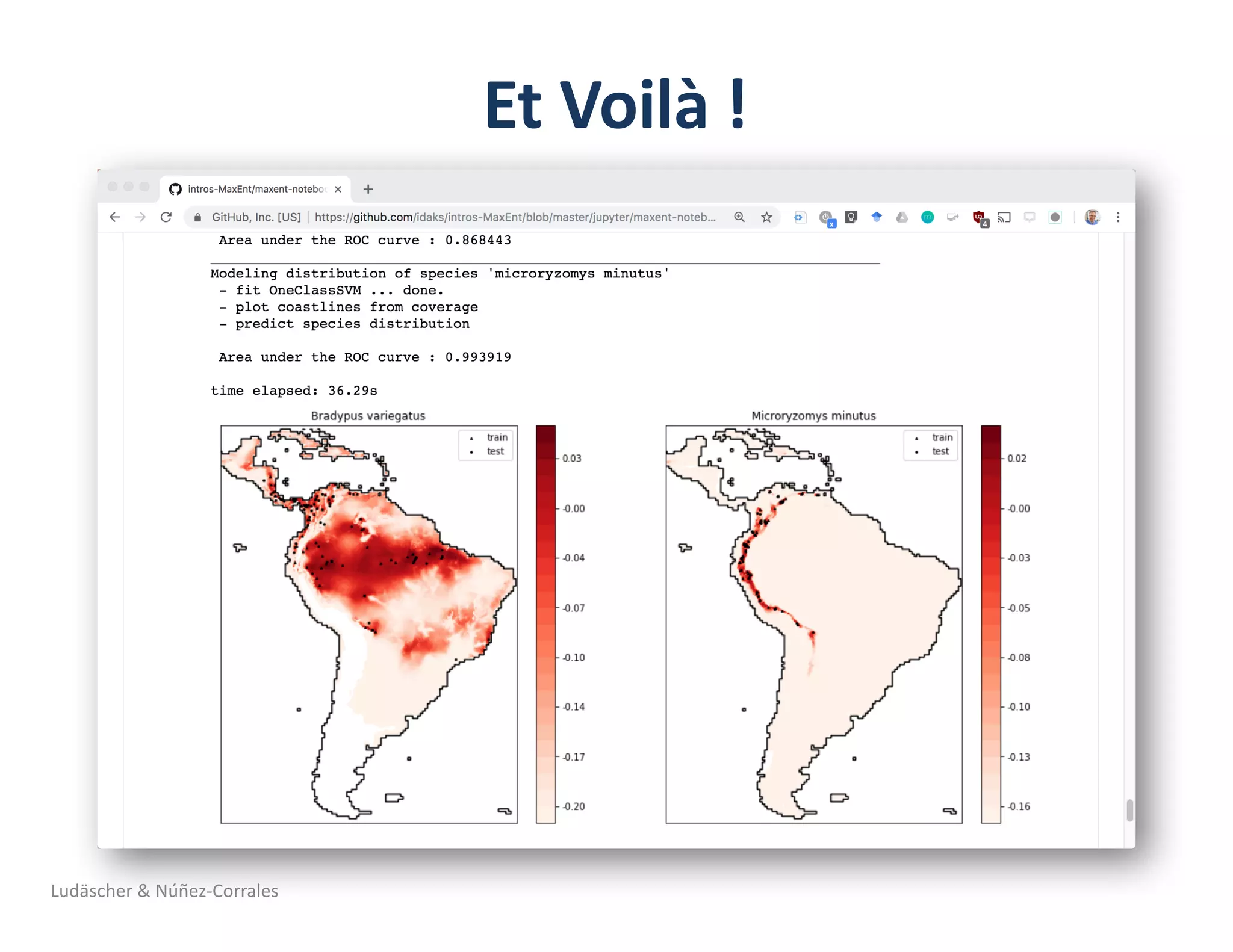
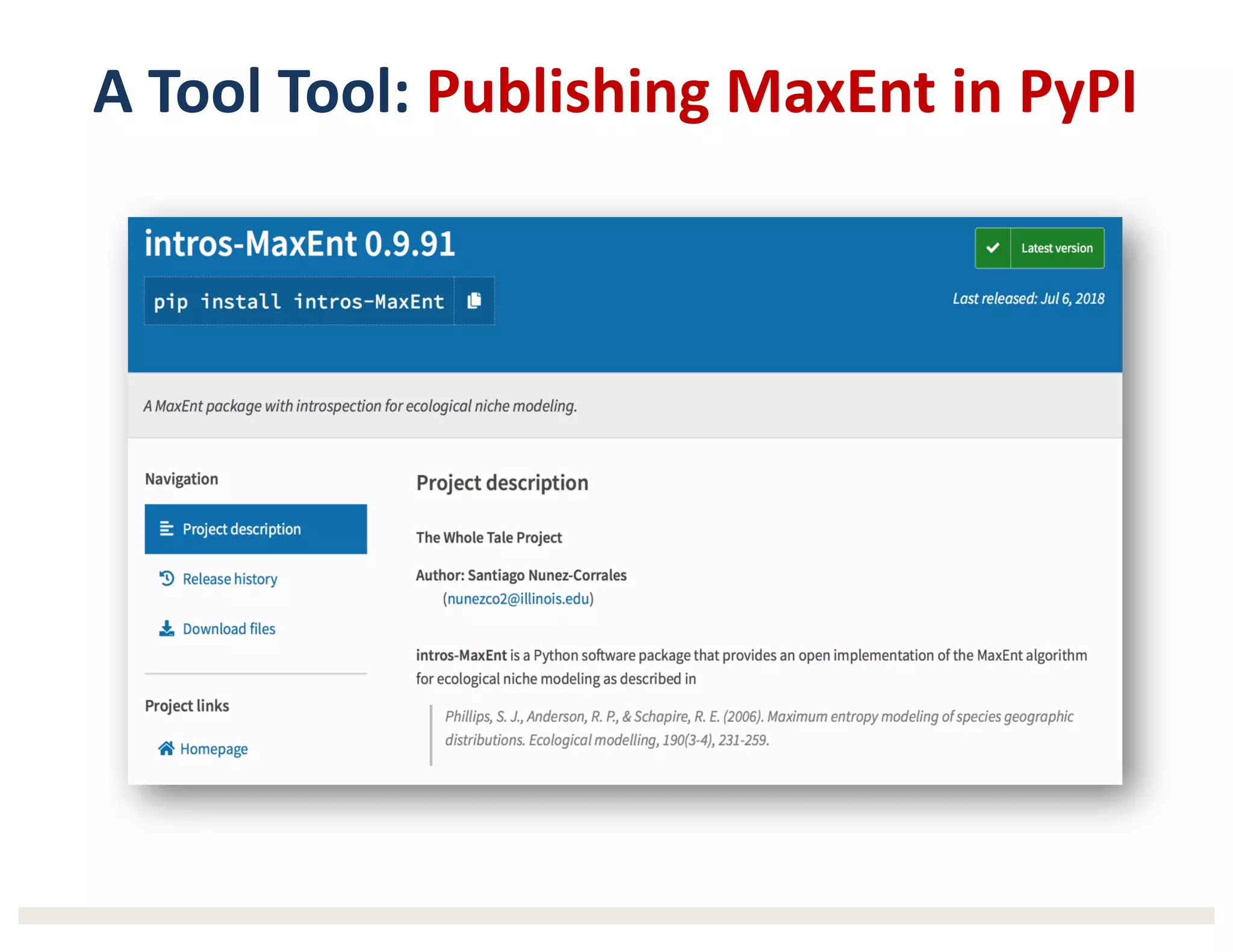
1) The document describes a workshop on research synthesis and reproducibility. 2) It discusses challenges with reproducibility in science and proposes provenance and conceptual tools like PRIMAD to help address these challenges. 3) The document presents a case study where an intern was able to reproduce results from a 2006 ecological niche modeling paper using the Whole Tale environment and MaxEnt software, demonstrating computational reproducibility.






![[Flashback] Integration of Active and Deductive Database Rules](https://cdn.slidesharecdn.com/ss_thumbnails/diss-slides1-230522182923-96084cd5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Flashback] Statelog: Integration of Active & Deductive Database Rules](https://cdn.slidesharecdn.com/ss_thumbnails/statelog-reloaded-230522181916-295d09d0-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Flashback 2005] Managing Scientific Data: From Data Integration to Scientifi...](https://cdn.slidesharecdn.com/ss_thumbnails/goetting-kolloq-07-05-181228005612-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)


