Downloaded 19 times










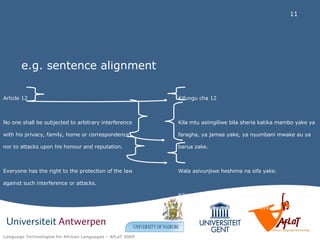


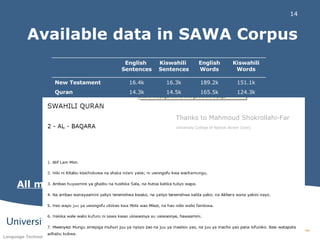



















- The SAWA Corpus is a parallel corpus containing over 50,000 English and Swahili sentence pairs from sources like the Bible, Quran, and news articles. - It was created using a data-driven approach to develop African language technologies by extracting linguistic knowledge from annotated parallel text. - Sentence and word alignment of the parallel texts was performed manually to create the corpus, which aims to help applications like machine translation between English and Swahili.















































