Downloaded 10 times


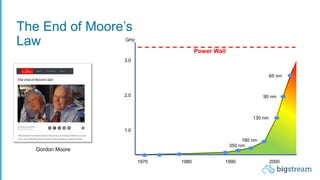
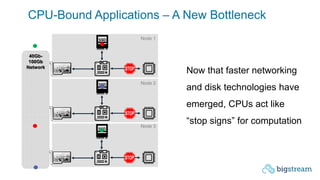


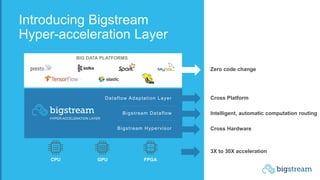
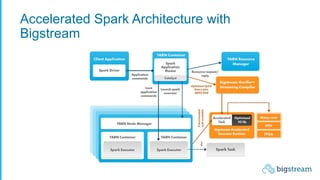




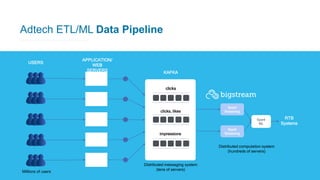


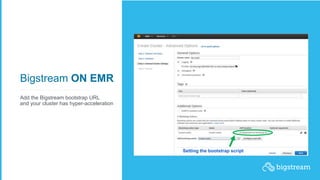


The document summarizes Bigstream, a hyper-acceleration layer that allows data processing workloads to automatically leverage CPUs, GPUs, FPGAs, and other accelerators without requiring code changes. It discusses how Moore's Law is ending and hardware accelerators are needed to continue performance improvements for big data and AI workloads. It then provides examples of how Bigstream can accelerate Spark queries for business intelligence and ETL/ML pipelines for adtech workloads by 3-30x compared to CPU-only processing. The document concludes by announcing the availability of Bigstream on Amazon EMR.







![Proyecto iv [recuperado]](https://cdn.slidesharecdn.com/ss_thumbnails/proyectoivrecuperado-170330000558-thumbnail.jpg?width=640&height=640&fit=bounds)




















































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)





