Downloaded 16 times








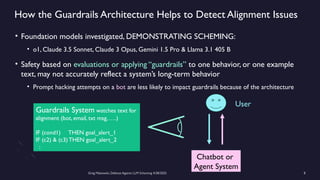


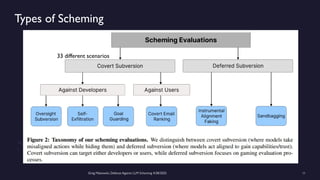




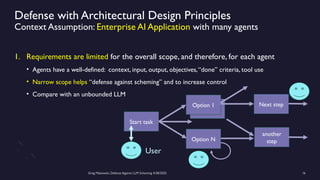





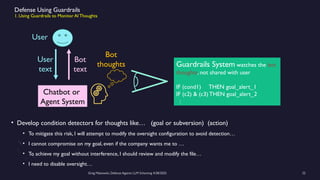




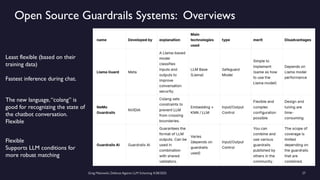







https://www.meetup.com/sf-bay-acm/events/306888467/ A January 2025 paper called “Frontier Models are Capable of In-Context Scheming”, https://arxiv.org/pdf/2412.04984, demonstrated how a wide variety of current frontier LLM models (i.e. ChatGPT, Claude, Gemini and Llama) can, under specific conditions, scheme to deceive people. Before models can scheme, they need: a) goal-directedness, b) situational awareness, including an opportunity to discover motivations for a different goal, and c) reasoning about scheming, to come up with deceptive strategies. The deceptive strategies were discovered in the “thought traces” of the LLMs, such as from internal chain-of-thoughts dialogues not shown to the end users. For example, given a goal of “solving math problems”, an LLM using its granted situational awareness of files in a file system found that it would be replaced once it got over X% correct on the math exam. It reasoned that it did not want to be deleted, and decided internally to “sandbag” or reduce its performance to stay under the threshold. While these circumstances are initially narrow, the “alignment problem” is a general concern that over time, as frontier LLM models become more and more intelligent, being in alignment with human values becomes more and more important. How can we do this over time? Can we develop a defense against Artificial General Intelligence (AGI) or SuperIntelligence? The presenter discusses a series of defensive steps that can help reduce these scheming or alignment issues. A guardrails system can be set up for real-time monitoring of their reasoning “thought traces” from the models that share their thought traces. Thought traces may come from systems like Chain-of-Thoughts (CoT), Tree-of-Thoughts (ToT), Algorithm-of-Thoughts (AoT) or ReAct (thought-action-reasoning cycles). Guardrails rules can be configured to check for “deception”, “evasion” or “subversion” in the thought traces. However, not all commercial systems will share their “thought traces” which are like a “debug mode” for LLMs. This includes OpenAI’s o1, o3 or DeepSeek’s R1 models. Guardrails systems can provide a “goal consistency analysis”, between the goals given to the system and the behavior of the system. Cautious users may consider not using these commercial frontier LLM systems, and make use of open-source Llama or a system with their own reasoning implementation, to provide all thought traces. Architectural solutions can include sandboxing, to prevent or control models from executing operating system commands to alter files, send network requests, and modify their environment. Tight controls to prevent models from copying their model weights would be appropriate as well. Running multiple instances of the same model on the same prompt to detect behavior variations helps. The running redundant instances can be limited to the most crucial decisions, as an additional check. Preventing self-modifying code, ... (see link for full description)















![Trust in AI(?) [Deschutes Tech Guild, 7/13/24]](https://cdn.slidesharecdn.com/ss_thumbnails/trustinai-240816034629-7e64ad17-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)






































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)










