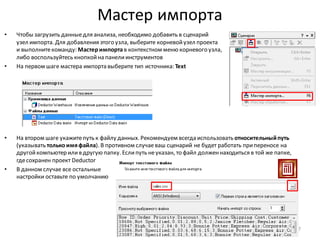
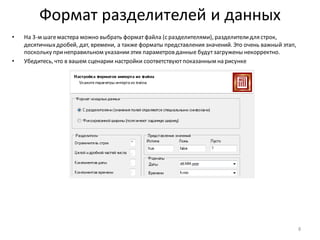
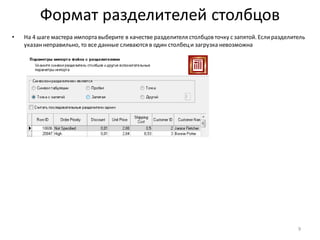
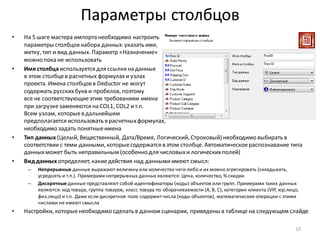
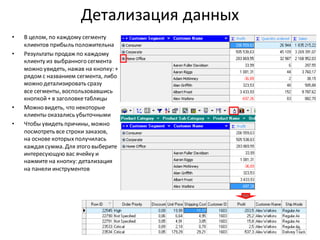
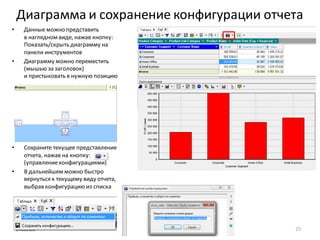
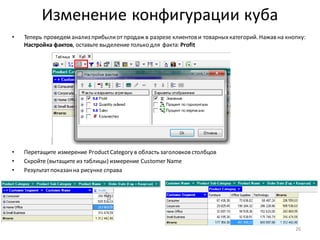
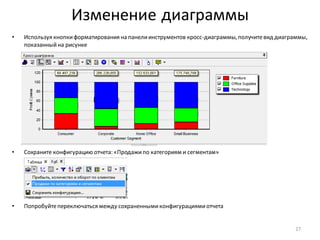
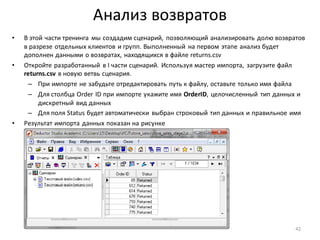
Download as PDF, PPTX







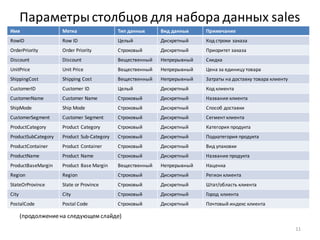





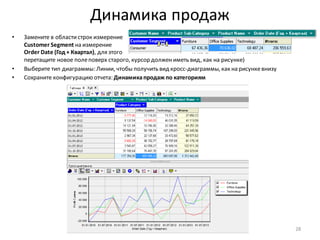
![Вычисляемый столбец
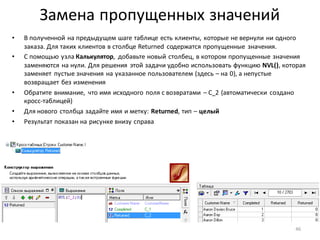
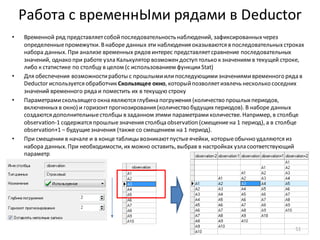
• Введем обозначения групп клиентов: D – убыточные,
A, B, C – прибыльные(по убыванию прибыльности)
• Проще всего определить группу для убыточных
клиентов. Для всех отфильтрованныхклиентов
с отрицательнойприбылью необходимо назначить
одну и ту же группу –D
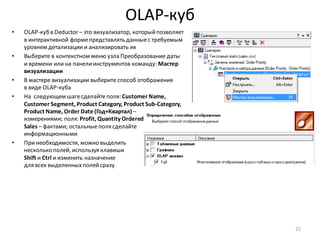
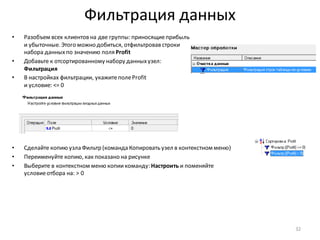
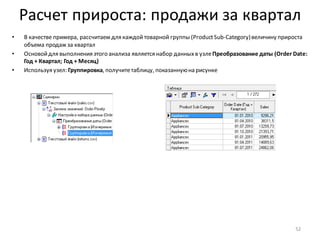
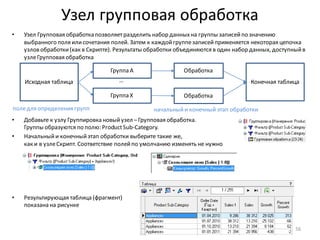
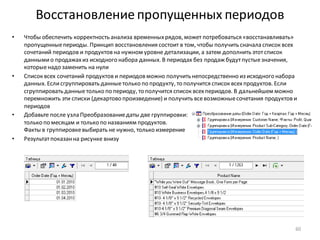
• Добавить новый вычисляемыйстолбецв набор
данныхможно с помощью узла: Калькулятор
• Добавьте после узла: Фильтр ([Profit] <= 0) узел Калькулятор
• В области Выражениевведитеформулу для вычисления нового столбца – строковую константу “D” (в
кавычках)
• Полеимеет строковый
тип данных, поэтому,
нажав на кнопку:
Редактировать параметры
выражения, укажите
этот тип данных и
задайте имя и метку поля,
показанныена рисунке
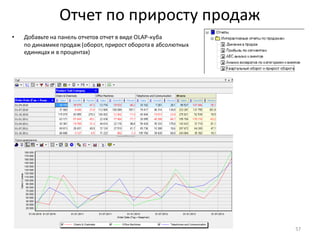
• Всегда задавайте понятные
имена и метки для
вычисляемыхстолбцов!
33](https://image.slidesharecdn.com/transformation-160603114959/85/Deductor-Studio-33-320.jpg)
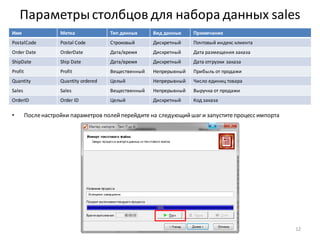
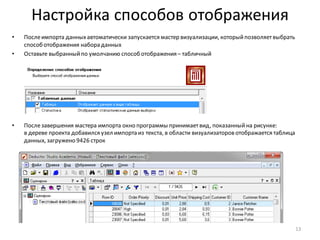
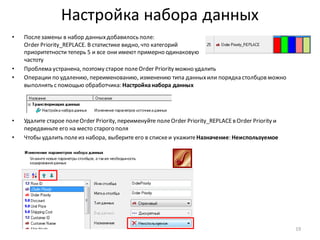
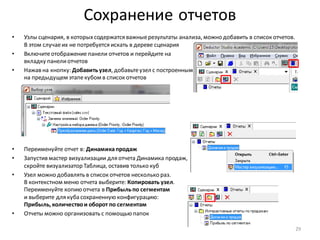
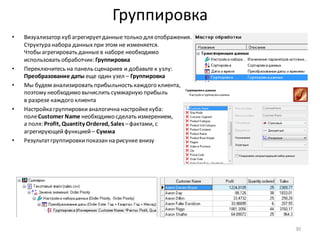
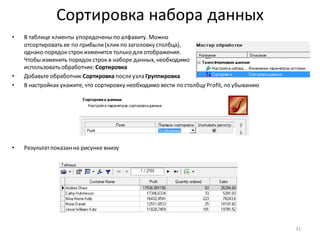
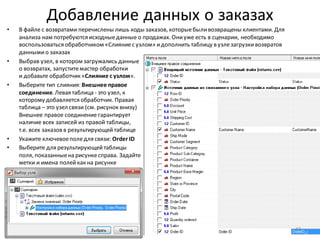
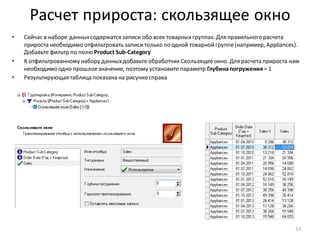
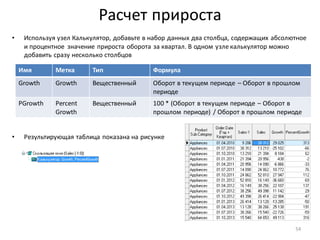
![Нарастающий итог и сумма по столбцу
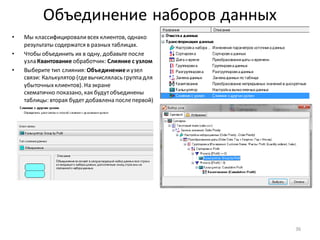
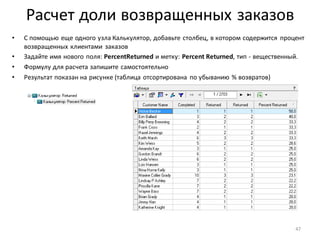
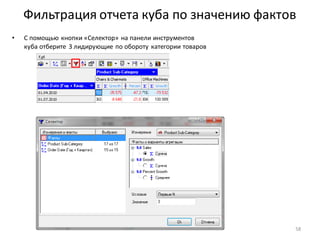
• Для разделения прибыльныхклиентов на группы A, B, C, используем принцип Парето и нарастающий итог
по полю Profit
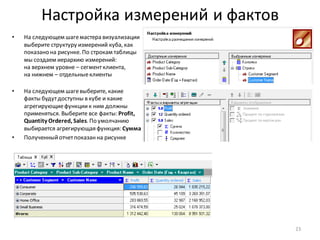
• Добавьте к узлу: Фильтр ([Profit] > 0) обработчик Калькулятор
• Задайте для нового поля тип данных: Вещественный,
имя: CumulativeProfitи метку: Cumulative Profit
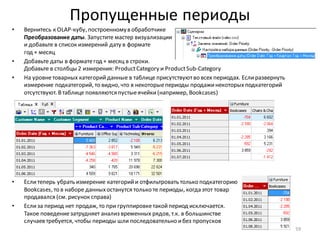
• Формула, показанная на рисунке внизу, вычисляетпроцентныйвклад каждого клиента в общую прибыль.
Поскольку, как ив SQL, для вычисления доступны только значения из текущей строки набора данных, для
расчета вклада с нарастающим итогом приходится использовать специальную функцию –
CumulativeSum(). Также, чтобы посчитать общий итог в знаменателедроби, нужна еще одна функция –
Stat(), которая вычисляетстатистику по столбцу (в данном случае– сумму).
• Список функций по категориям доступенв правой части окна калькулятора.
• Для предотвращения опечаток рекомендуем принаборе формул всегда использовать функцию
автодополнения (Ctrl-пробел), которая позволяетбыстро выбирать из списка имена полей и функцийпо
нескольким начальным символам
• Убедитесь, что в рассчитанном столбцеCumulative Profitпоследнеезначение - 100
34](https://image.slidesharecdn.com/transformation-160603114959/85/Deductor-Studio-34-320.jpg)








Документ описывает тренинг по трансформации данных в Deductor Studio, включая задачи анализа результатов продаж компании-дистрибьютора. Освещаются этапы загрузки, предварительного анализа и настройки данных, а также важные функции, такие как замена и преобразование данных. Обсуждаются методы работы с файлами CSV и схема импорта, что позволяет эффективно анализировать продажи и сегментаризацию клиентов.















































