Dealing with different Synapse Roles in Azure Synapse Analytics Erwin de Kreuk
The document outlines various user roles and permissions within Azure Synapse Analytics, including administrative and non-administrative roles, their responsibilities, and access management. It emphasizes the importance of role assignments, workspace items, and the integration of different services like Azure Data Lake and Power BI. Additionally, it provides guidance on managing access levels for data engineers and data scientists while detailing security considerations and usage tips.
InSpark
Azure Synapse Studio
IntegrationManagement Monitoring Security
Analytics runtimes
Azure Data Lake Storage
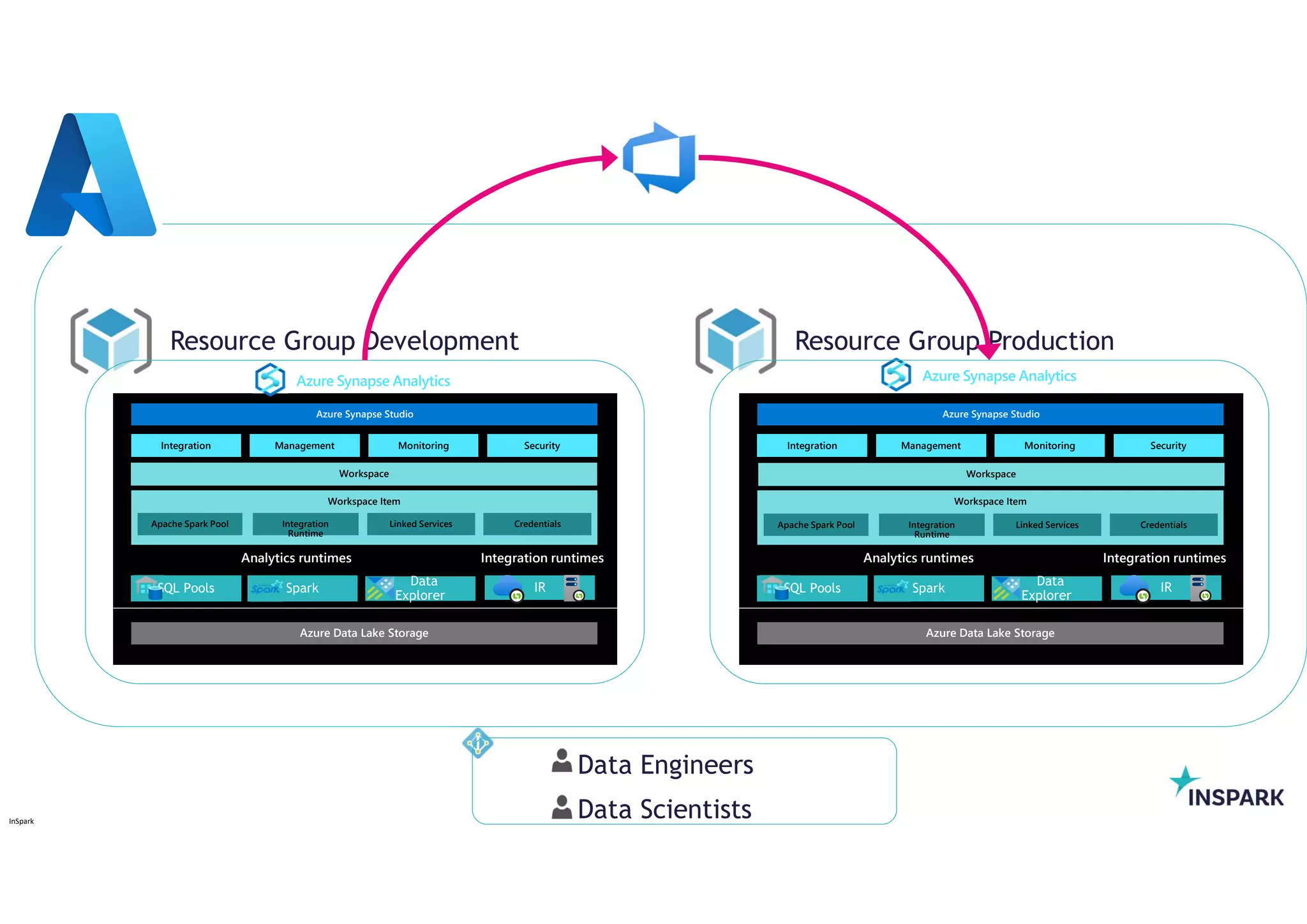
Azure Synapse Analytics
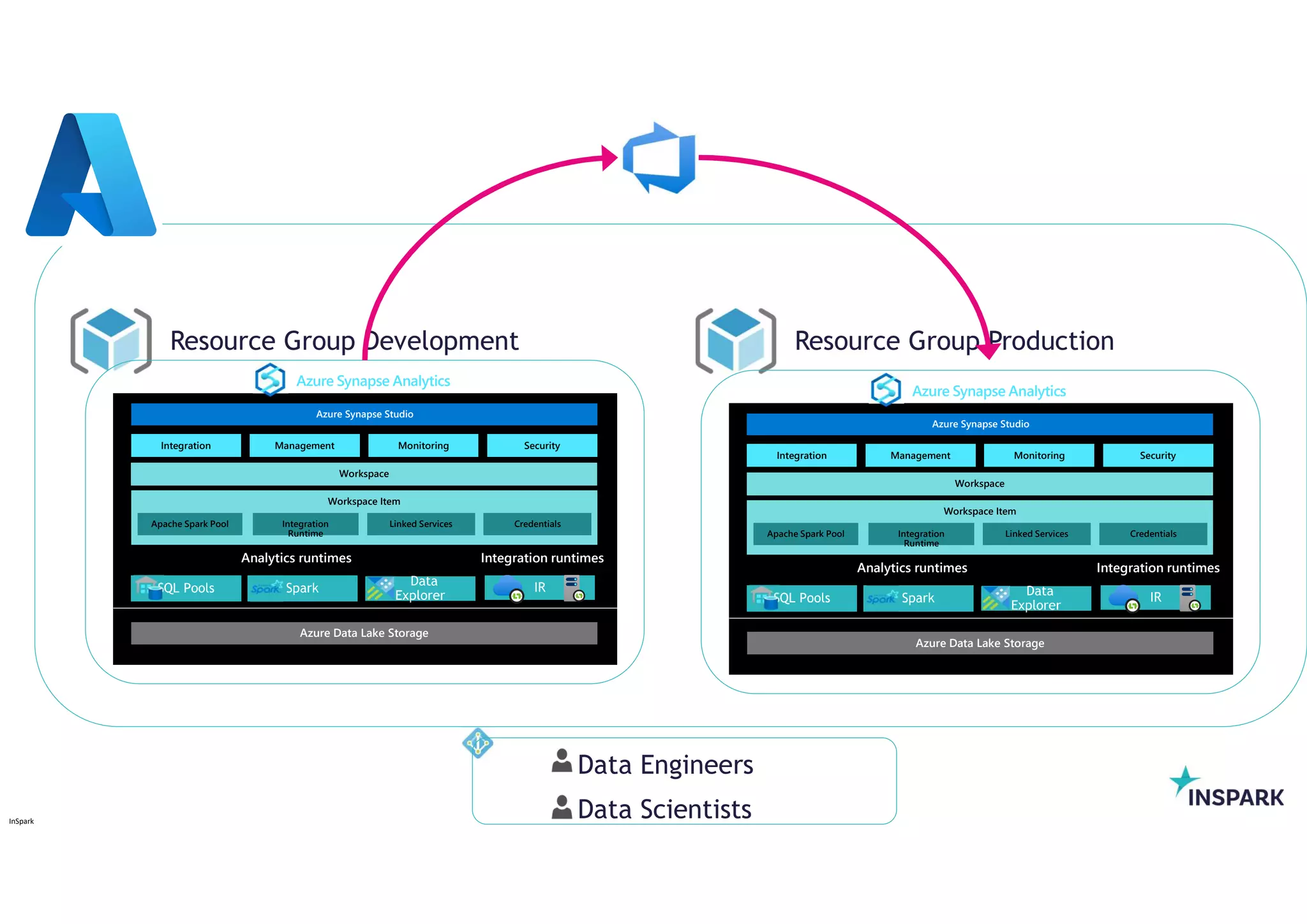
Resource Group Development Resource Group Production
Integration runtimes Integration runtimes
Workspace
Workspace Item
Apache Spark Pool Integration
Runtime
Linked Services Credentials
Data Engineers
Data Scientists
Azure Synapse Studio
Integration Management Monitoring Security
Analytics runtimes
Azure Data Lake Storage
Azure Synapse Analytics
Integration runtimes
Workspace
Workspace Item
Apache Spark Pool Integration
Runtime
Linked Services Credentials
6.
InSpark
Azure Synapse Studio
IntegrationManagement Monitoring Security
Analytics runtimes
Azure Data Lake Storage
Azure Synapse Analytics
Resource Group Development
Integration runtimes
Workspace
Workspace Item
Apache Spark Pool Integration
Runtime
Linked Services Credentials
7.
InSpark
Azure Synapse Analytics
ResourceGroup Development
Azure Owner or Contributor
Resource Group
Create Synapse Workspace
Manage Synapse Workspace
Synapse Resource
Manage Synapse Workspace
Azure Contributor
Resource Group
ARM templates for automated deployment
Resource Management
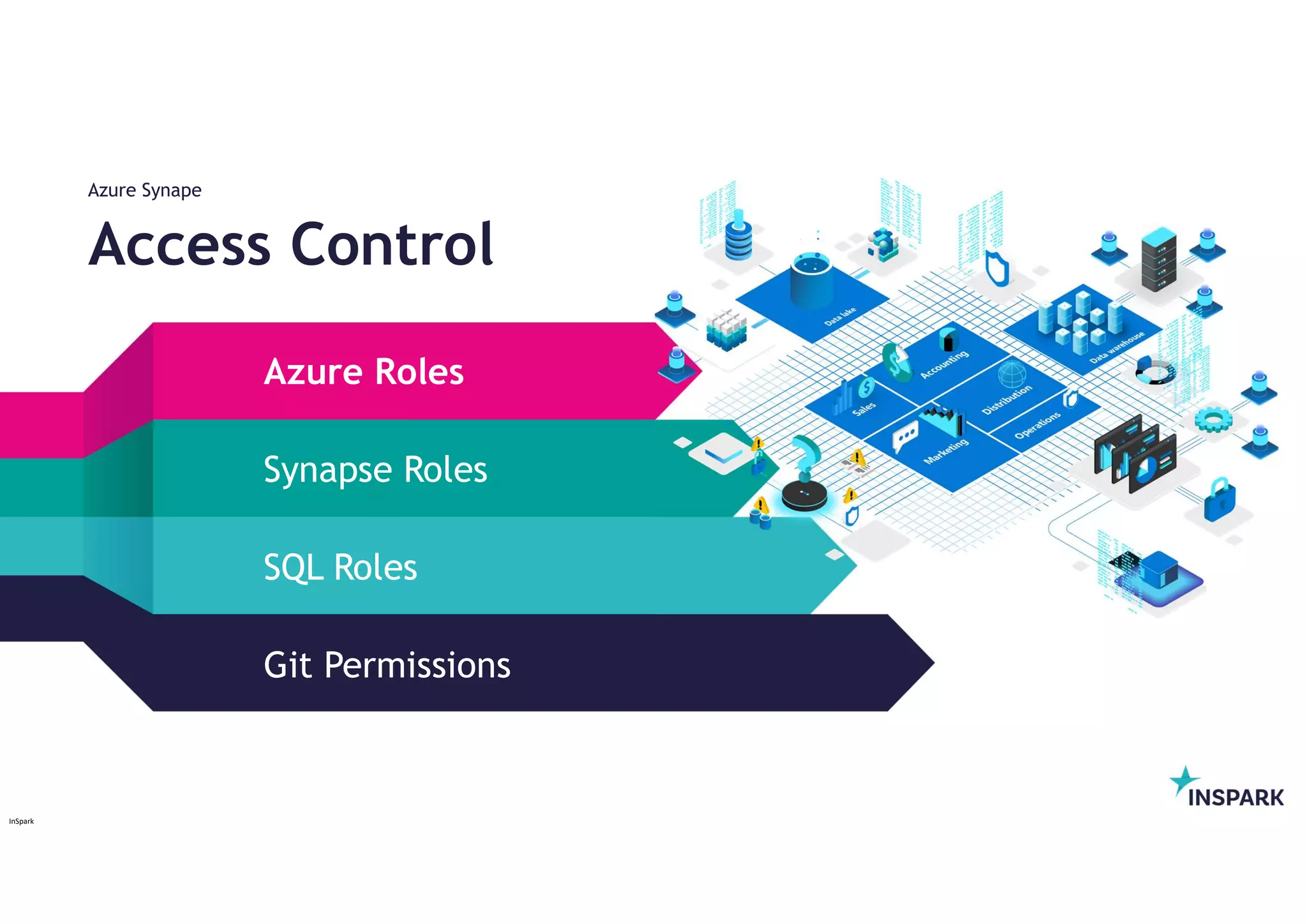
Azure Roles
8.
InSpark
Azure Synapse Analytics
ResourceGroup Development
Azure Storage Blob Data Contributor
User and workspace MSI
Reader
Resource Group or Synapse Workspace
Access Management
Azure Roles
Azure Data Lake Storage
InSpark
Azure Synapse Analytics
ResourceGroup Development
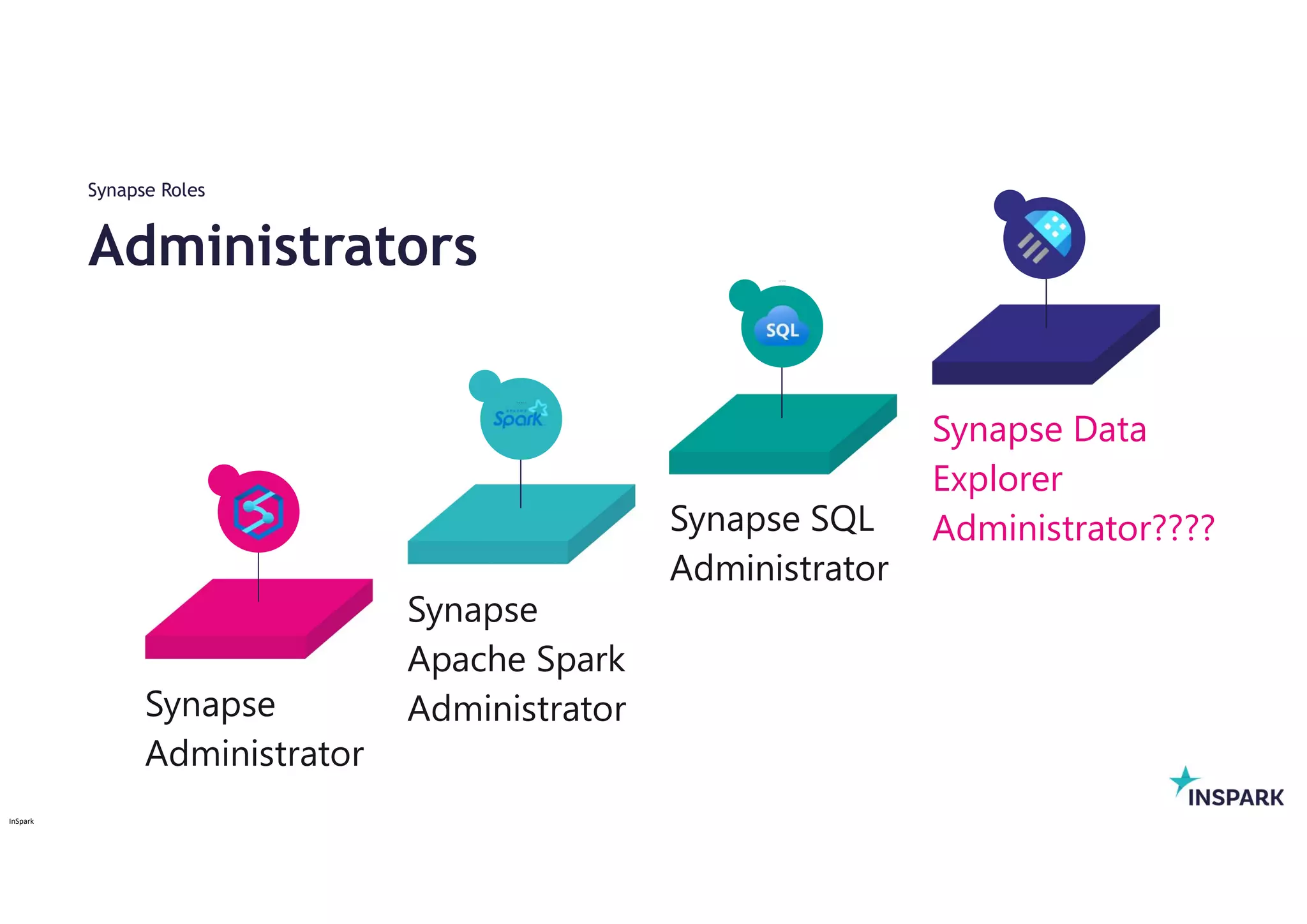
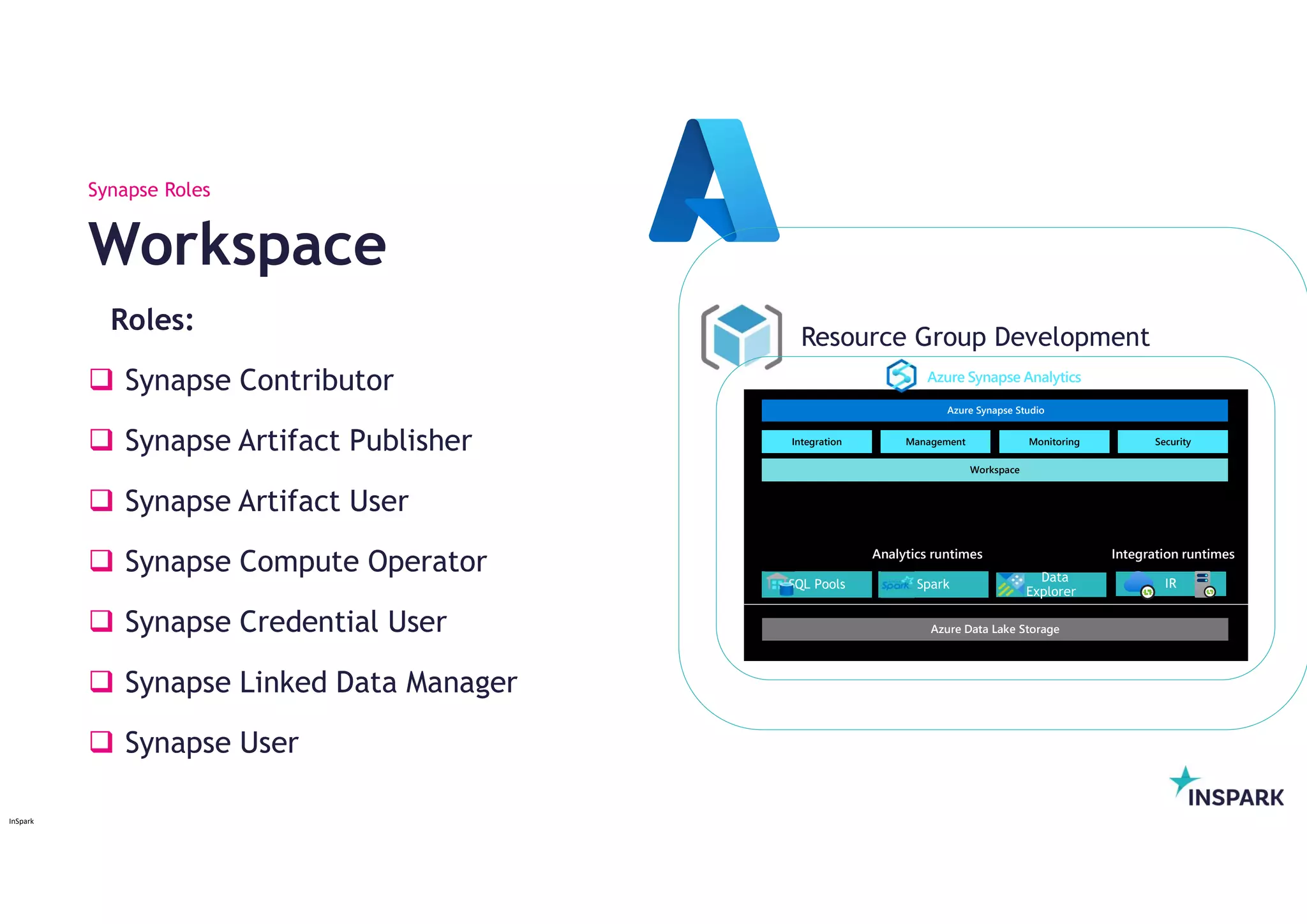
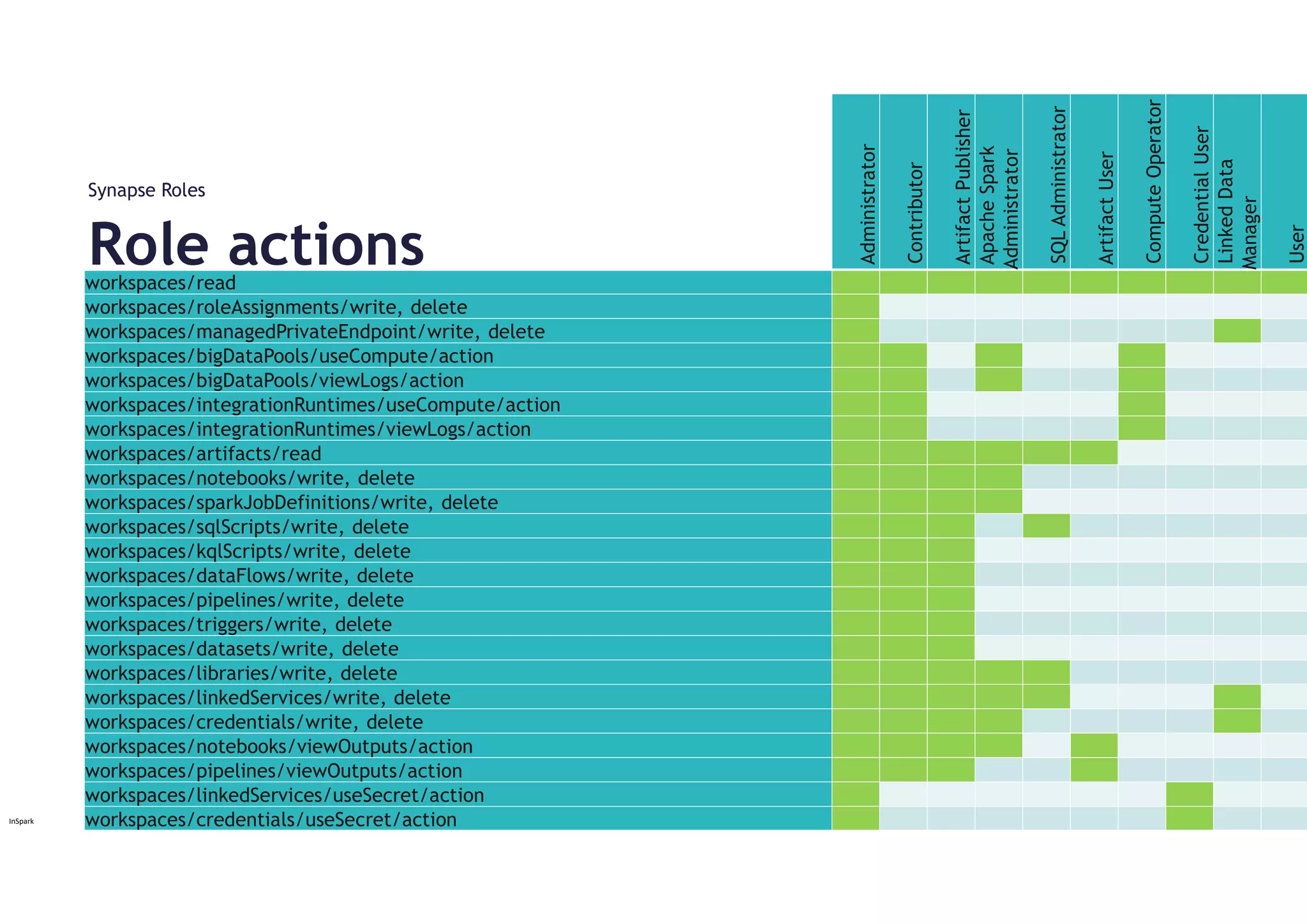
Roles:
Synapse Administrator
Synapse SQL Administrator
Synapse Apache Spark Administrator
SQL Active Directory Admin
Administrators
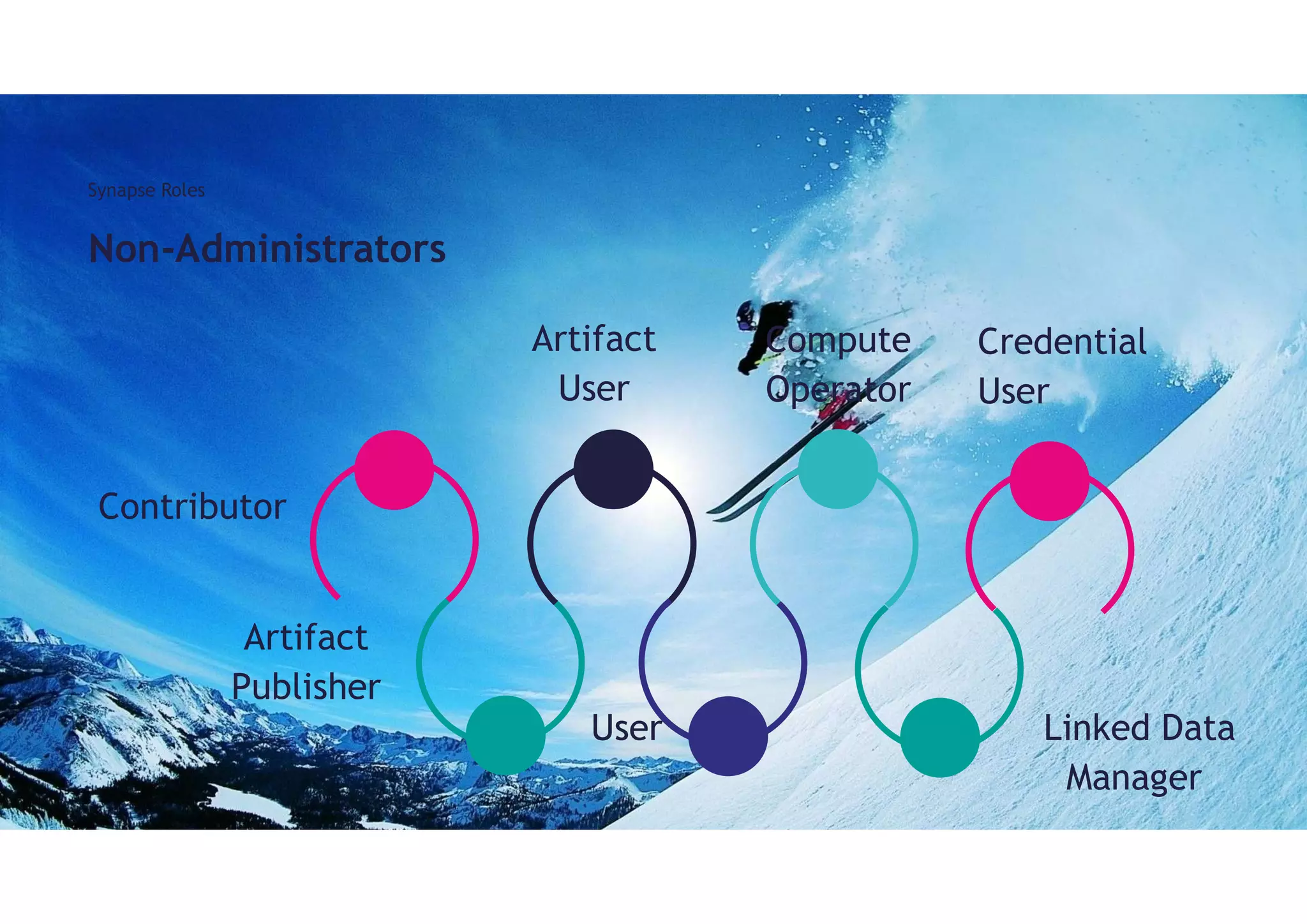
Synapse Roles
Azure Data Lake Storage
Analytics runtimes Integration runtimes
11.
InSpark
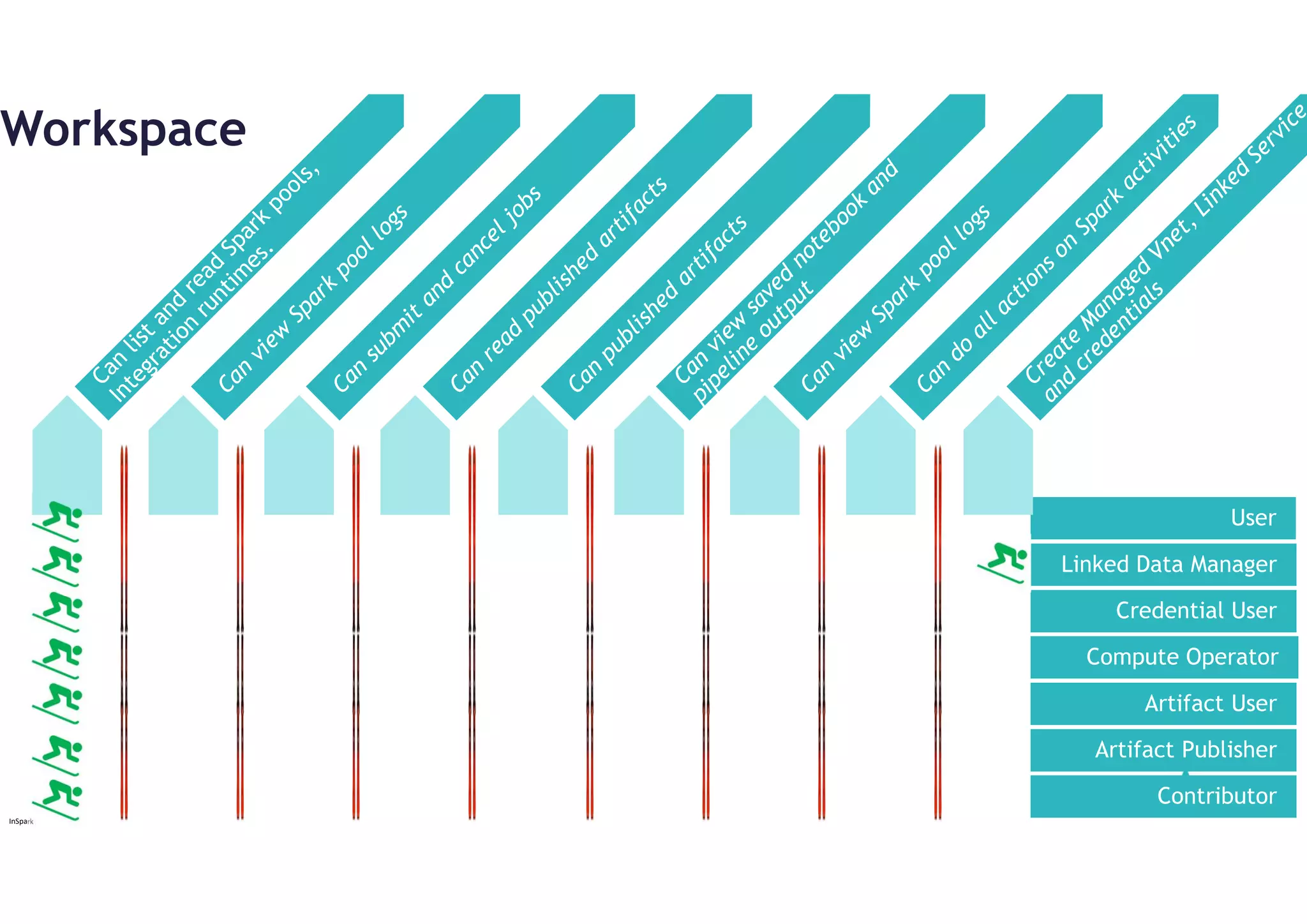
Activities:
Can readand write artifacts
Can do all actions on Spark activities.
Can view Spark pool logs
Can view saved notebook and pipeline output
Can use the secrets stored by linked services or credentials
Can assign and revoke Synapse RBAC roles at current scope
Synapse Administrator
Synapse Roles
12.
InSpark
Activities:
Can doall actions on Spark artifacts
Can do all actions on Spark activities
Synapse Apache Spark Administrator
Synapse Roles
13.
InSpark
Activities:
Can doall actions on SQL scripts
Can connect to SQL serverless endpoints with SQL db_datareader,
db_datawriter, connect, and grant permissions
Synapse SQL Administrator
Synapse Roles
InSpark
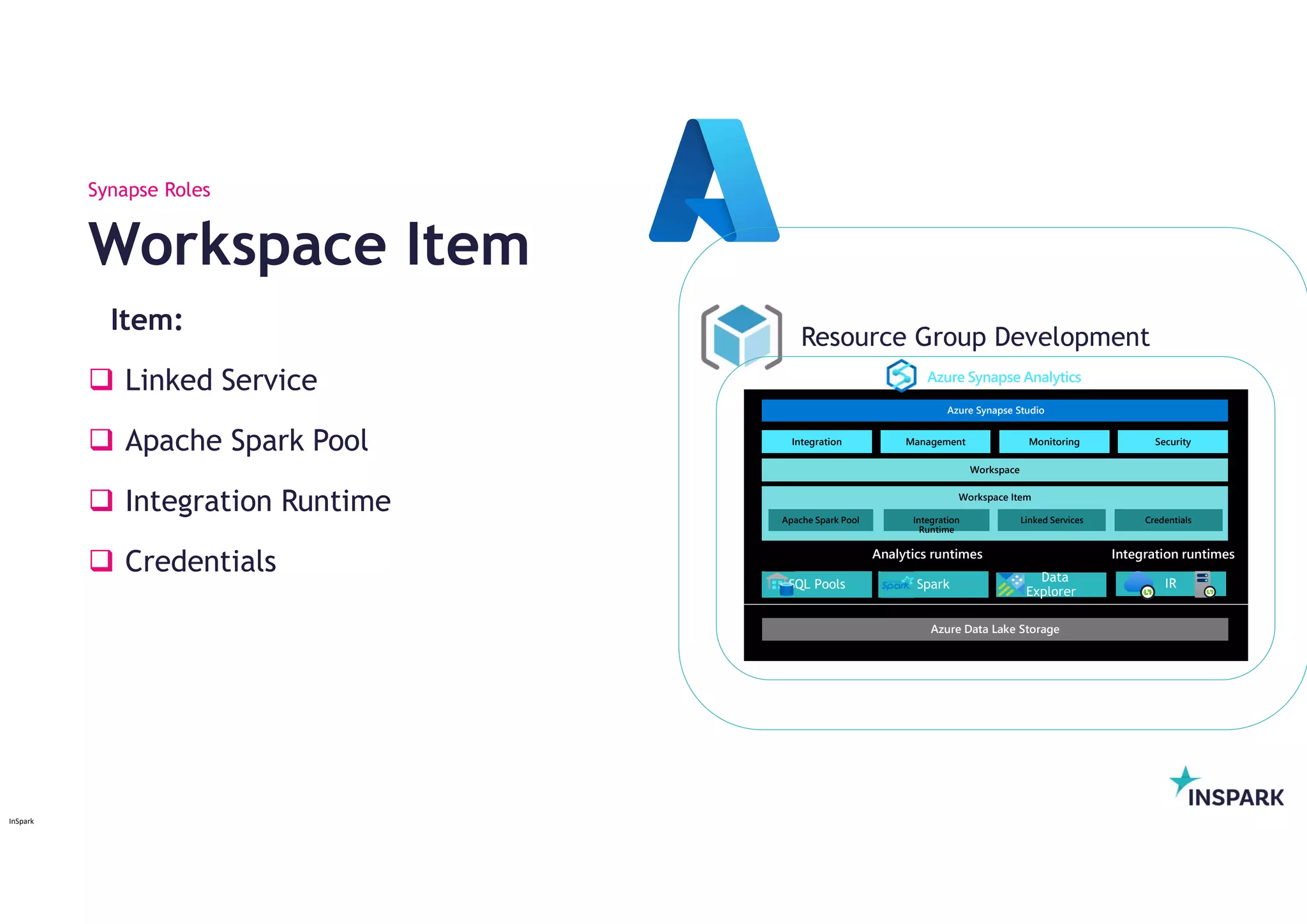
Item:
Linked Service
Apache Spark Pool
Integration Runtime
Credentials
Workspace Item
Synapse Roles
Azure Synapse Studio
Integration Management Monitoring Security
Analytics runtimes
Azure Data Lake Storage
Azure Synapse Analytics
Resource Group Development
Integration runtimes
Workspace
Workspace Item
Apache Spark Pool Integration
Runtime
Linked Services Credentials
19.
InSpark
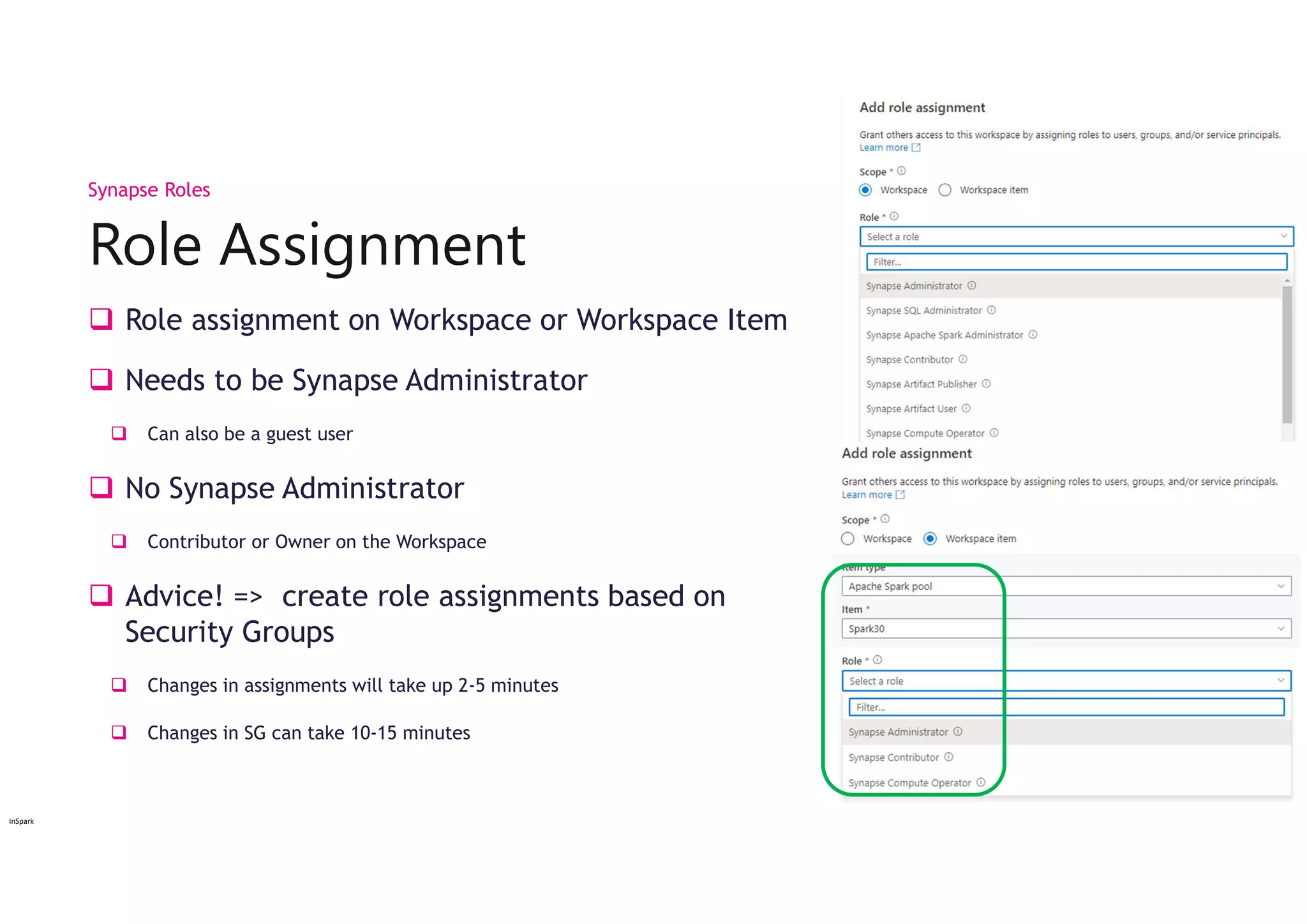
Role assignmenton Workspace or Workspace Item
Needs to be Synapse Administrator
Can also be a guest user
No Synapse Administrator
Contributor or Owner on the Workspace
Advice! => create role assignments based on
Security Groups
Changes in assignments will take up 2-5 minutes
Changes in SG can take 10-15 minutes
Role Assignment
Synapse Roles
20.
InSpark
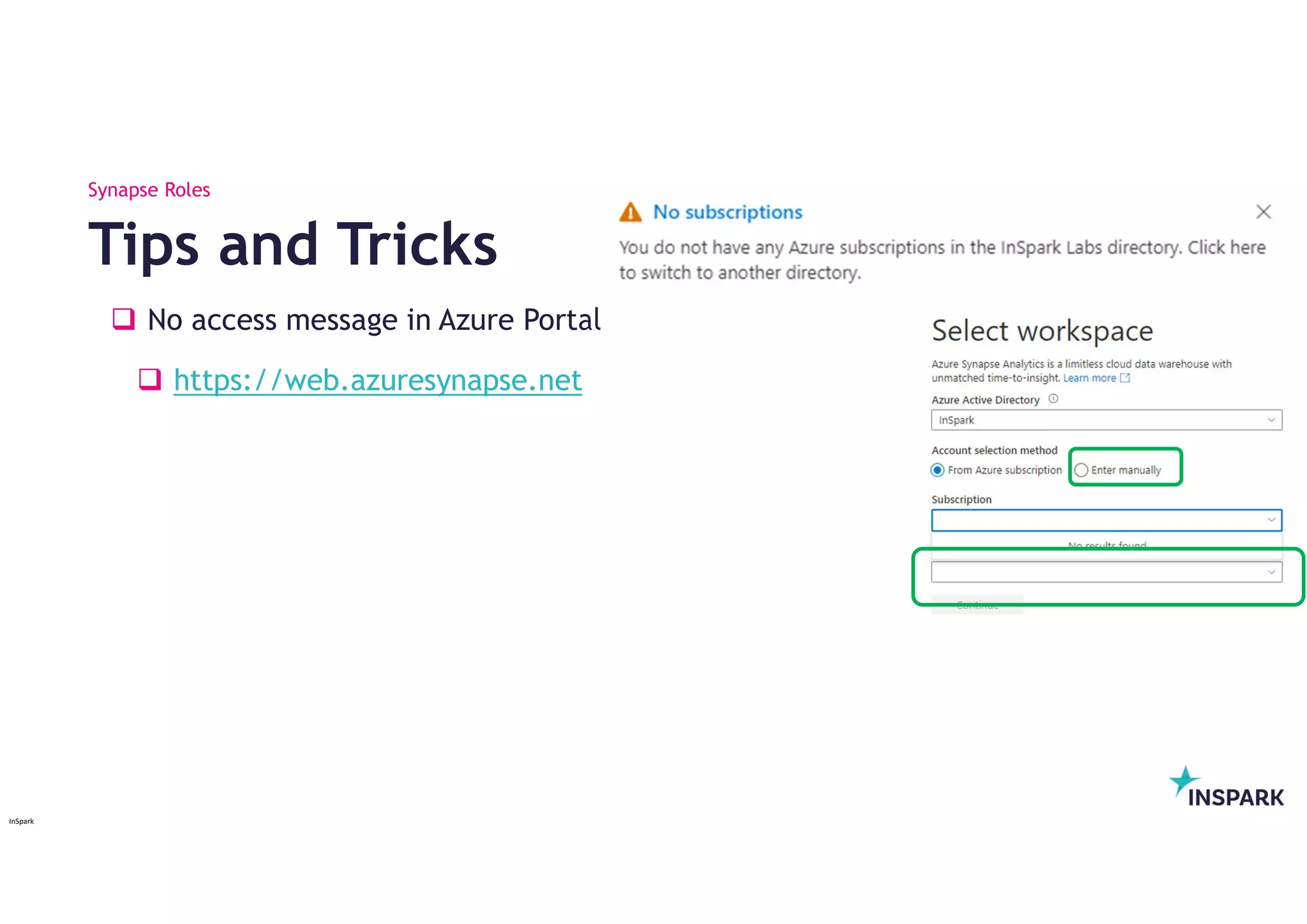
No accessmessage in Azure Portal
https://web.azuresynapse.net
Tips and Tricks
Synapse Roles
21.
InSpark
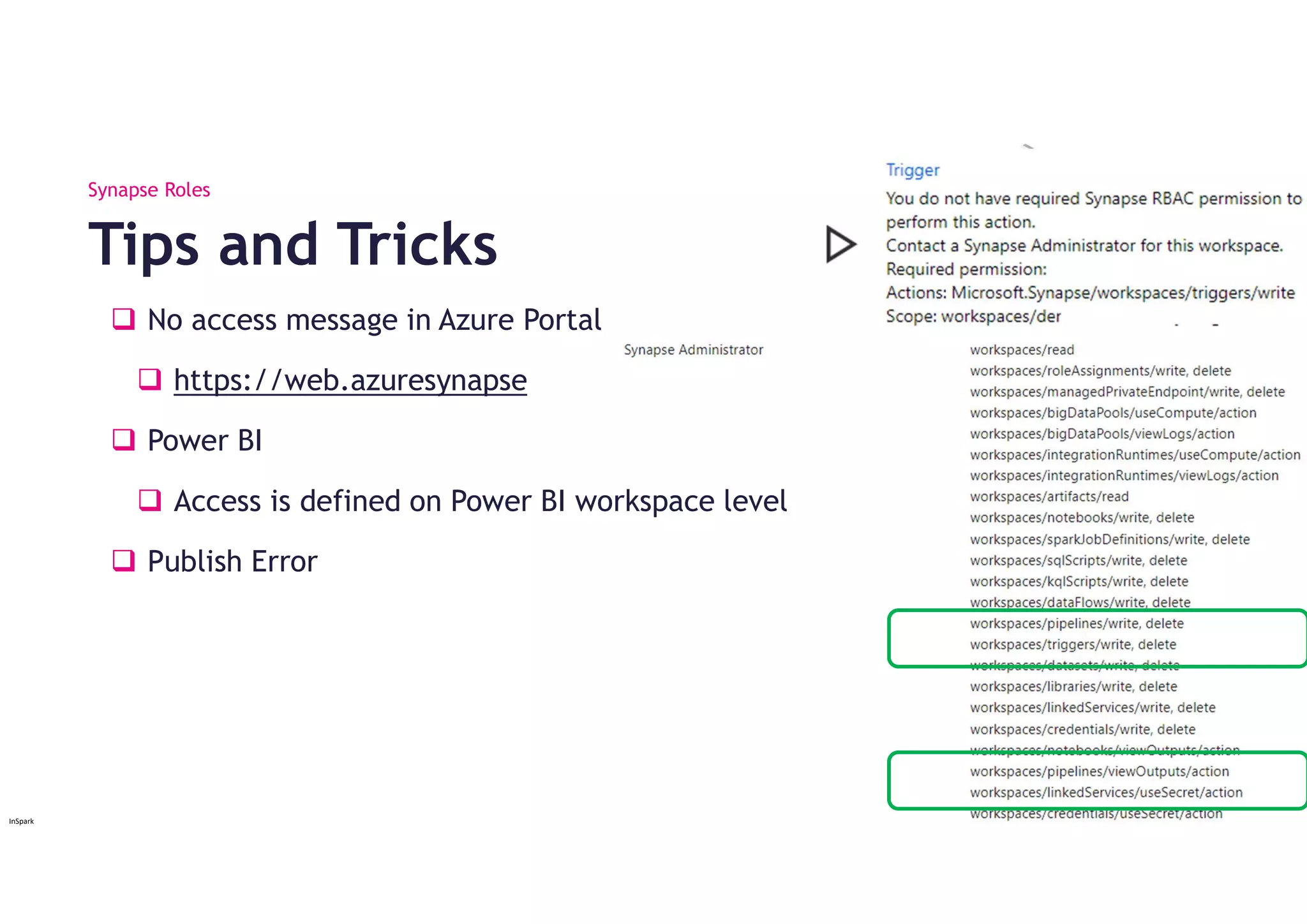
No accessmessage in Azure Portal
https://web.azuresynapse
Power BI
Access is defined on Power BI workspace level
Tips and Tricks
Synapse Roles
22.
InSpark
No accessmessage in Azure Portal
https://web.azuresynapse
Power BI
Access is defined on Power BI workspace level
Publish Error
Tips and Tricks
Synapse Roles
InSpark
Synapse Administrator:
db_owner(DBO) permissions on the ‘Built-In’
serverless SQL pool
Synapse SQL Administrator:
Can do all actions on SQL scripts
Can connect to SQL serverless endpoints with SQL
db_datareader, db_datawriter, connect, and grant
permissions
Serverless SQL Pool
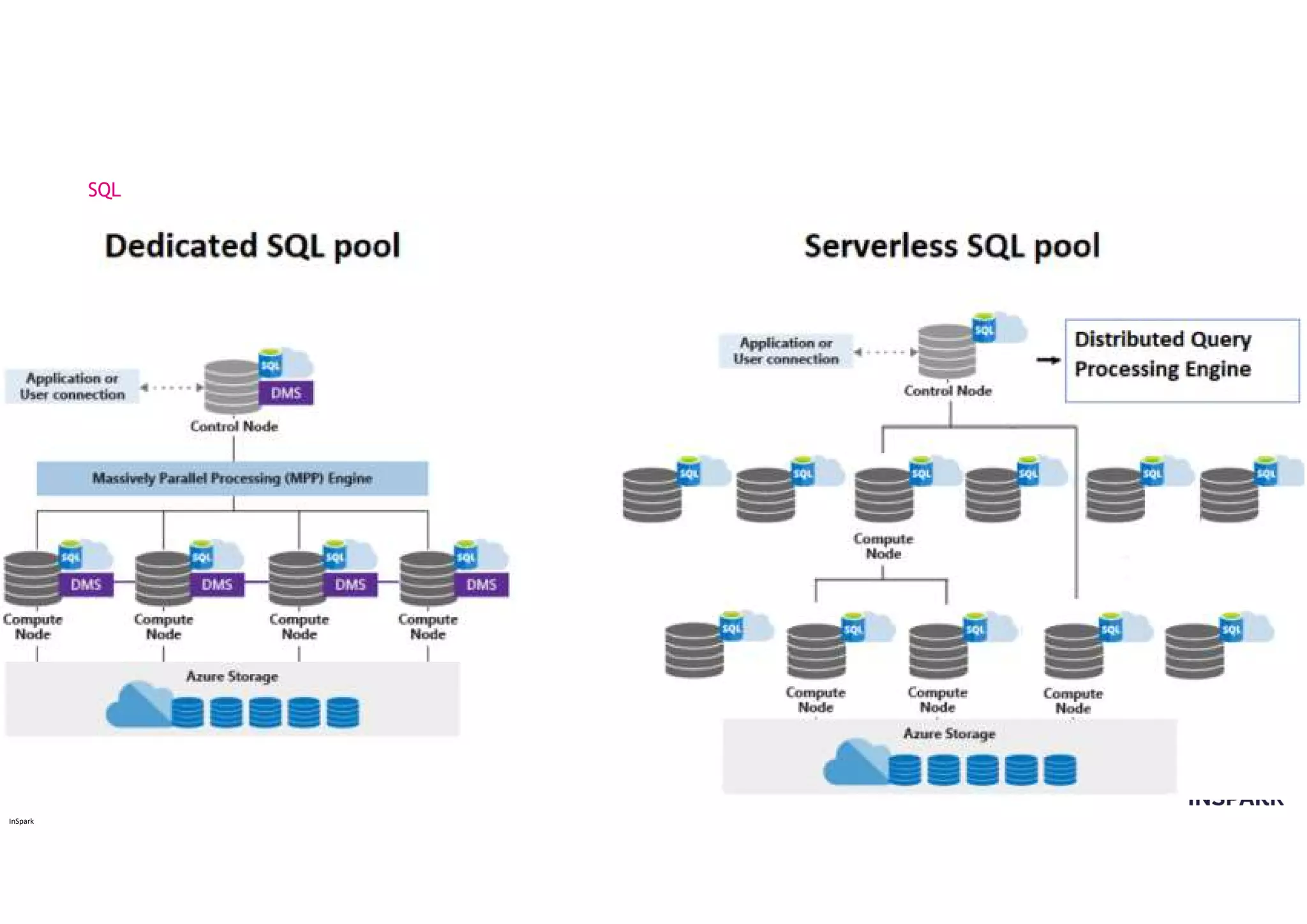
SQL
Serverless
27.
InSpark
Synapse Administrator:
Fullaccess to data in dedicated SQL pools
Grant access to other users
Perform configuration and maintenance activities
Can't drop dedicated SQL pools
Synapse SQL Administrator:
No access by default
Active Directory Admin:
Full access
Dedicated SQL Pool
SQL
Dedicated
28.
InSpark
Serverless SQL pool:
DedicatedSQL pool:
SQL Pools
SQL
Dedicated
Serverless
use master
go
CREATE LOGIN [erwin.de.kreuk@demo.com] FROM EXTERNAL PROVIDER;
go
use yourdb -- Use your database name
go
CREATE USER demouser FROM LOGIN [erwin.de.kreuk@demo.com];
use yourdb -- Use your database name
go
alter role db_owner Add member demouser
--Create user in the database
CREATE USER [erwin.dekreuk@gmail.com] FROM EXTERNAL PROVIDER;
--Grant role to the user in the database
EXEC sp_addrolemember 'db_owner', 'erwin.dekreuk@gmail.com';
InSpark
Azure Dev Ops:
Basic user settings
Azure Artifact Publisher
Azure Contributor (Azure RBAC) or higher role on
the Synapse workspace
Dev Ops Service Connection:
Azure Contributor (Azure RBAC) or higher role on
the Resource Group
Azure Synapse Administrator
Azure Dev Ops
GIT Integration
31.
InSpark
Azure Synapse Studio
IntegrationManagement Monitoring Security
Analytics runtimes
Azure Data Lake Storage
Azure Synapse Analytics
Azure Synapse Studio
Integration Management Monitoring Security
Azure Data Lake Storage
Azure Synapse Analytics
Resource Group Development Resource Group Production
Integration runtimes Analytics runtimes Integration runtimes
Workspace
Workspace Item
Apache Spark Pool Integration
Runtime
Linked Services Credentials
Workspace Item
Apache Spark Pool Integration
Runtime
Linked Services Credentials
Workspace
Data Engineers
Data Scientists
32.
InSpark
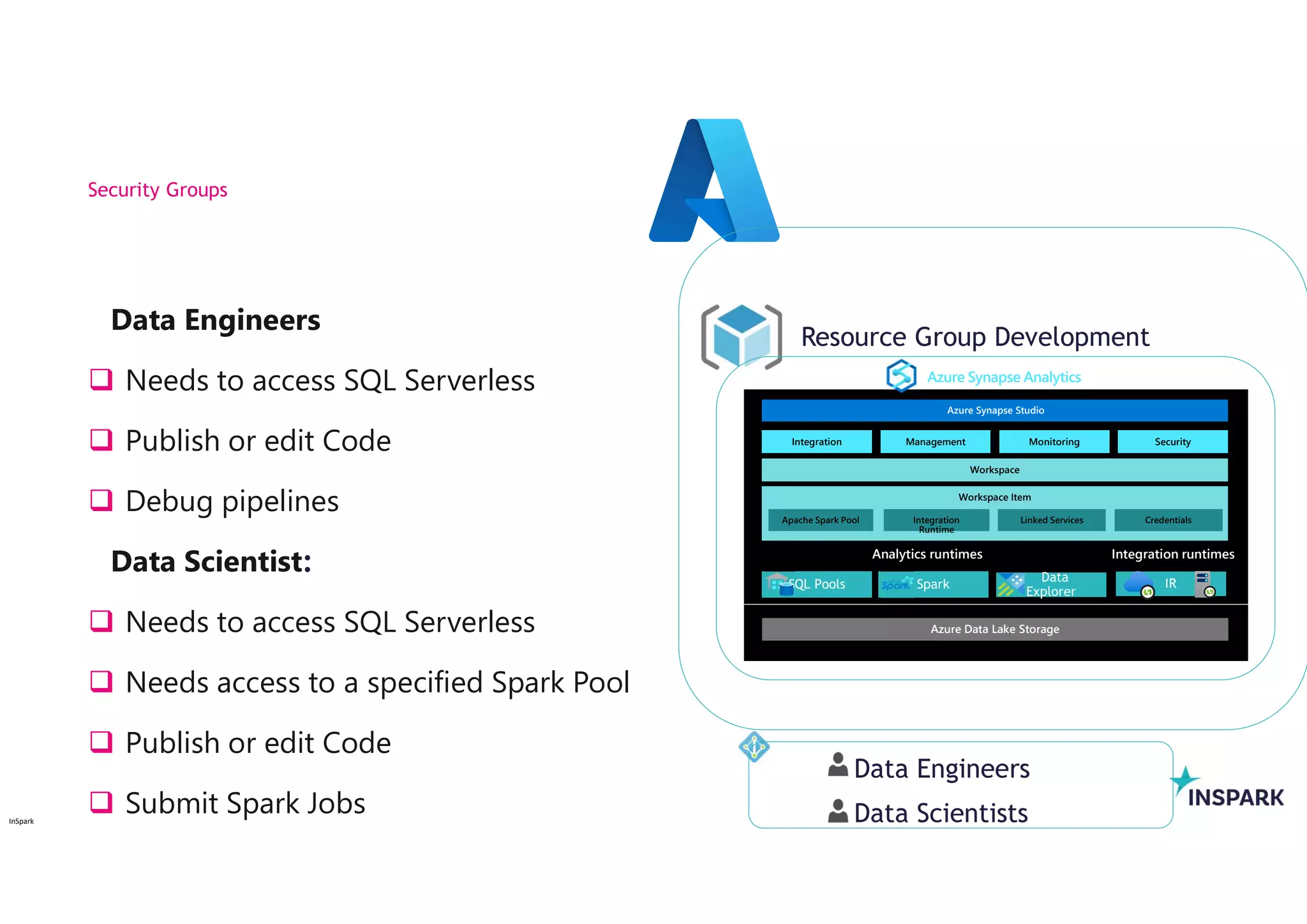
Data Engineers
Needsto access SQL Serverless
Publish or edit Code
Debug pipelines
Data Scientist:
Needs to access SQL Serverless
Needs access to a specified Spark Pool
Publish or edit Code
Submit Spark Jobs
Security Groups
Azure Synapse Studio
Integration Management Monitoring Security
Analytics runtimes
Azure Data Lake Storage
Azure Synapse Analytics
Resource Group Development
Integration runtimes
Workspace
Workspace Item
Apache Spark Pool Integration
Runtime
Linked Services Credentials
Data Engineers
Data Scientists














![InSpark
Serverless SQL pool:
Dedicated SQL pool:
SQL Pools
SQL
Dedicated
Serverless
use master
go
CREATE LOGIN [erwin.de.kreuk@demo.com] FROM EXTERNAL PROVIDER;
go
use yourdb -- Use your database name
go
CREATE USER demouser FROM LOGIN [erwin.de.kreuk@demo.com];
use yourdb -- Use your database name
go
alter role db_owner Add member demouser
--Create user in the database
CREATE USER [erwin.dekreuk@gmail.com] FROM EXTERNAL PROVIDER;
--Grant role to the user in the database
EXEC sp_addrolemember 'db_owner', 'erwin.dekreuk@gmail.com';](https://image.slidesharecdn.com/dealingwithdifferentsynapseroleserwindekreuk-220129124436/75/Dealing-with-different-Synapse-Roles-in-Azure-Synapse-Analytics-Erwin-de-Kreuk-28-2048.jpg)





























































![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Dobrica Cosic - Savings by the Second: How Dynamic Pricing an...](https://cdn.slidesharecdn.com/ss_thumbnails/znp09f3smtqz3w2sq6wn-1-dobrica-cosic-savings-by-the-second-how-dynamic-pricing-and-smart-data-are-bu-251208151905-26e6f41e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Sara Polak - The Archaeology of Innovation: AI as the Next Cr...](https://cdn.slidesharecdn.com/ss_thumbnails/7ecbscdnt8mlcuqbd2ln-2-sara-polak-ai-creative-industries-251208152533-aa1fcf54-thumbnail.jpg?width=640&height=640&fit=bounds)
