Downloaded 52 times
![DBIx::DataModel 2.0 in detail YAPC::EU::2011, Riga [email_address] Département Office](https://image.slidesharecdn.com/dbixdatamodelendetail-100613033643-phpapp01/85/DBIx-DataModel-v2-0-in-detail-1-320.jpg)




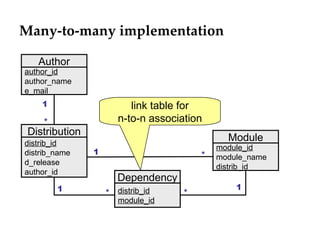
![All definitions in one single file use DBIx::DataModel; DBIx::DataModel-> Schema ("My::DB") -> Table (qw/Author author author_id /) ->Table(qw/Distribution distribution distrib_id/) ->Table(qw/Module module module_id /) -> Association ([qw/Author author 1 /], [qw/Distribution distribs 0..* /]) -> Composition ([qw/Distribution distrib 1 /], [qw/Module modules 1..* /]); creates package My::DB creates package My::DB::Author adds methods into both packages](https://image.slidesharecdn.com/dbixdatamodelendetail-100613033643-phpapp01/85/DBIx-DataModel-v2-0-in-detail-11-320.jpg)




![Fetching a list of records # select multiple records my $recent_distribs = My::DB->table('Distribution') -> select ( -columns => [qw/ distrib_name d_release /], -where => { d_release => {'>' => $some_date}}, -order_by => [qw/ -d_release +distrib_name /], ); foreach my $distrib (@$recent_distribs) { ... }](https://image.slidesharecdn.com/dbixdatamodelendetail-100613033643-phpapp01/85/DBIx-DataModel-v2-0-in-detail-17-320.jpg)



![SQL::Abstract::More : extensions -columns => [qw/col1 |alias1 max(col2) |alias2 /] SELECT col1 AS alias1, max(col2) AS alias2 -columns => [ -DISTINCT => qw/col1 col2 col3/] SELECT DISTINCT col1, col2, col3 -order_by => [qw/col1 + col2 – col3/] SELECT … ORDER BY col1, col2 ASC, col3 DESC -for => "update" || "read only" SELECT … FOR UPDATE](https://image.slidesharecdn.com/dbixdatamodelendetail-100613033643-phpapp01/85/DBIx-DataModel-v2-0-in-detail-21-320.jpg)
![Grouping -group_by => [qw/col1 col2 …/] -having => { col1 => {"<" => val1} , col2 => ... } SELECT … GROUP BY col1, col2 HAVING col1 < ? AND col2 … separate call to SQL::Abstract and re-injection into the SQL](https://image.slidesharecdn.com/dbixdatamodelendetail-100613033643-phpapp01/85/DBIx-DataModel-v2-0-in-detail-22-320.jpg)


![Polymorphic result -result_as => 'rows' (default) : arrayref of row objects 'firstrow' : a single row object (or undef) 'hashref' : hashref keyed by primary keys [hashref => @cols] : cascaded hashref 'flat_arrayref' : flattened values from each row 'statement' : a statement object (iterator) 'fast_statement' : statement reusing same memory 'sth' : DBI statement handle 'sql' : ($sql, @bind_values) 'subquery' : \["($sql)", @bind] don't need method variants : select_hashref(), select_arrayref(), etc.](https://image.slidesharecdn.com/dbixdatamodelendetail-100613033643-phpapp01/85/DBIx-DataModel-v2-0-in-detail-25-320.jpg)



![Navigation to associated tables Method names come from association declarations Exactly like a select () automatically chooses –result_as => 'rows' || 'firstrow' from multiplicity information # ->Association([qw/Author author 1 /], # [qw/Distribution distribs 0..* /]) my $author = $distrib-> author (); my $other_distribs = $author-> distribs ( -columns => [qw/. . ./], -where => { . . . }, -order_by => [qw/. . ./], );](https://image.slidesharecdn.com/dbixdatamodelendetail-100613033643-phpapp01/85/DBIx-DataModel-v2-0-in-detail-29-320.jpg)




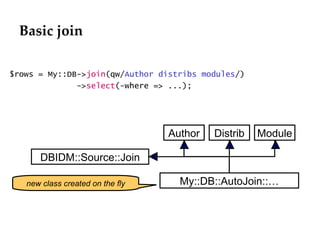
![Left / inner joins ->Association([qw/Author author 1 /], [qw/Distribution distribs 0..* /]) # default : LEFT OUTER JOIN ->Composition([qw/Distribution distrib 1 /], [qw/Module modules 1..* /]); # default : INNER JOIN # but defaults can be overridden My::DB->join([qw/Author <=> distribs/)-> . . . My::DB->join([qw/Distribution => modules /)-> . . .](https://image.slidesharecdn.com/dbixdatamodelendetail-100613033643-phpapp01/85/DBIx-DataModel-v2-0-in-detail-37-320.jpg)
![Join from an instance $rows = $author-> join (qw/ distribs modules /)->select( -columns => [qw/distrib_name module_name/], -where => { d_release => {'<' => $date} }, ); SELECT distrib_name, module_name FROM distribution INNER JOIN module ON distribution.distrib_id = module.distrib_id WHERE distrib.author_id = $author->{author_id} AND d_release < $date](https://image.slidesharecdn.com/dbixdatamodelendetail-100613033643-phpapp01/85/DBIx-DataModel-v2-0-in-detail-38-320.jpg)


![Bulk insert @ids = MyDB::Author-> insert ( [qw/firstname lastname/], [qw/Larry Wall /], [qw/Damian Conway /], );](https://image.slidesharecdn.com/dbixdatamodelendetail-100613033643-phpapp01/85/DBIx-DataModel-v2-0-in-detail-41-320.jpg)
![Insert into / cascaded insert @id_trees = $author-> insert_into_distribs ( {distrib_name => 'DBIx-DataModel', modules => [ {module_name => 'DBIx::DataModel', ..}, {module_name => 'DBIx::DataModel::Statement', ..}, ]}, {distrib_name => 'Pod-POM-Web', … }, -returning => {}, );](https://image.slidesharecdn.com/dbixdatamodelendetail-100613033643-phpapp01/85/DBIx-DataModel-v2-0-in-detail-42-320.jpg)




![Types (inflate/deflate) # declare a Type My::DB -> Type ( Multivalue => from_DB => sub {$_[ 0 ] = [split /;/ , $_[ 0 ]] } , to_DB => sub {$_[ 0 ] = join ";" , @$_[ 0 ] }, ); # apply it to some columns in a table My::DB::Author->metadm-> define_column_type ( Multivalue => qw/hobbies languages/, );](https://image.slidesharecdn.com/dbixdatamodelendetail-100613033643-phpapp01/85/DBIx-DataModel-v2-0-in-detail-47-320.jpg)











![ORM: What for ? [catalyst list] On Thu, 2006-06-08, Steve wrote: Not intending to start any sort of rancorous discussion, but I was wondering whether someone could illuminate me a little? I'm comfortable with SQL, and with DBI. I write basic SQL that runs just fine on all databases, or more complex SQL when I want to target a single database (ususally postgresql). What value does an ORM add for a user like me?](https://image.slidesharecdn.com/dbixdatamodelendetail-100613033643-phpapp01/85/DBIx-DataModel-v2-0-in-detail-59-320.jpg)


![Callback example WITH RECURSIVE nodetree(level, id, pid, sort) AS ( SELECT 1, id, parent, '{1}'::int[] FROM nodes WHERE parent IS NULL UNION SELECT level+1,p.id, parent, sort||p.id FROM nodetree pr JOIN nodes p ON p.parent = pr.id ) SELECT * FROM nodetree ORDER BY sort; my $with_clause = "WITH RECURSIVE …"; DBIx::DataModel->Schema('Tst') ->Table(qw/Nodetree nodetree id/); my $result = Tst::Nodetree-> select ( -post_SQL => sub {my $sql = shift; $sql =~ s/^/$with_clause/; return $sql, @_ }, -orderBy => 'sort', );](https://image.slidesharecdn.com/dbixdatamodelendetail-100613033643-phpapp01/85/DBIx-DataModel-v2-0-in-detail-64-320.jpg)





The document details the architecture and functionalities of dbix::datamodel 2.0, focusing on object-relational mappings and schema modeling in Perl. It covers data row objects, statement objects, and the process of joins, inserts, and updates, along with comparisons to other database interaction models. The document also discusses schema localization, data retrieval techniques, transactions, and various configuration options available to developers.



















































































