Download as PDF, PPTX




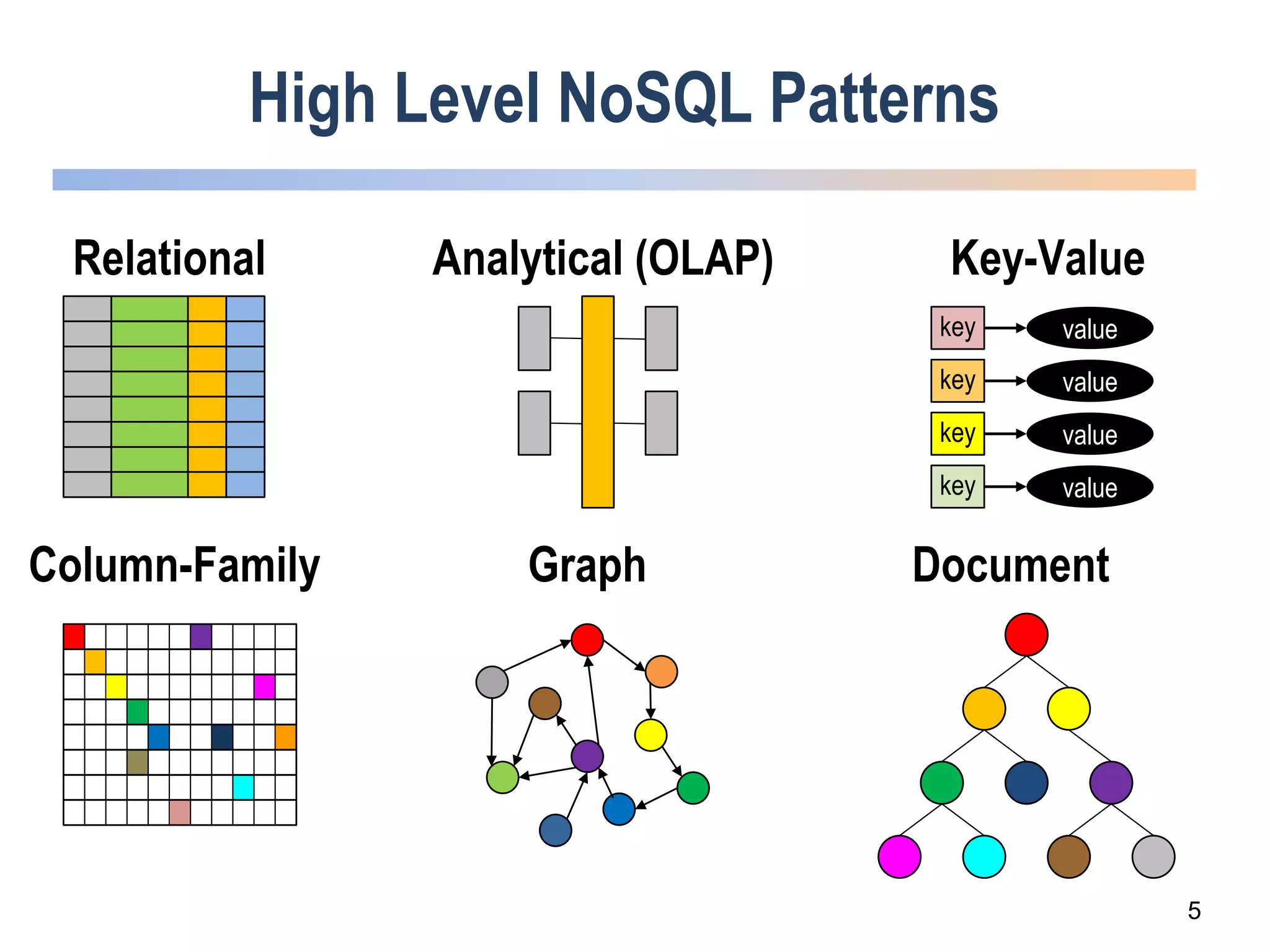

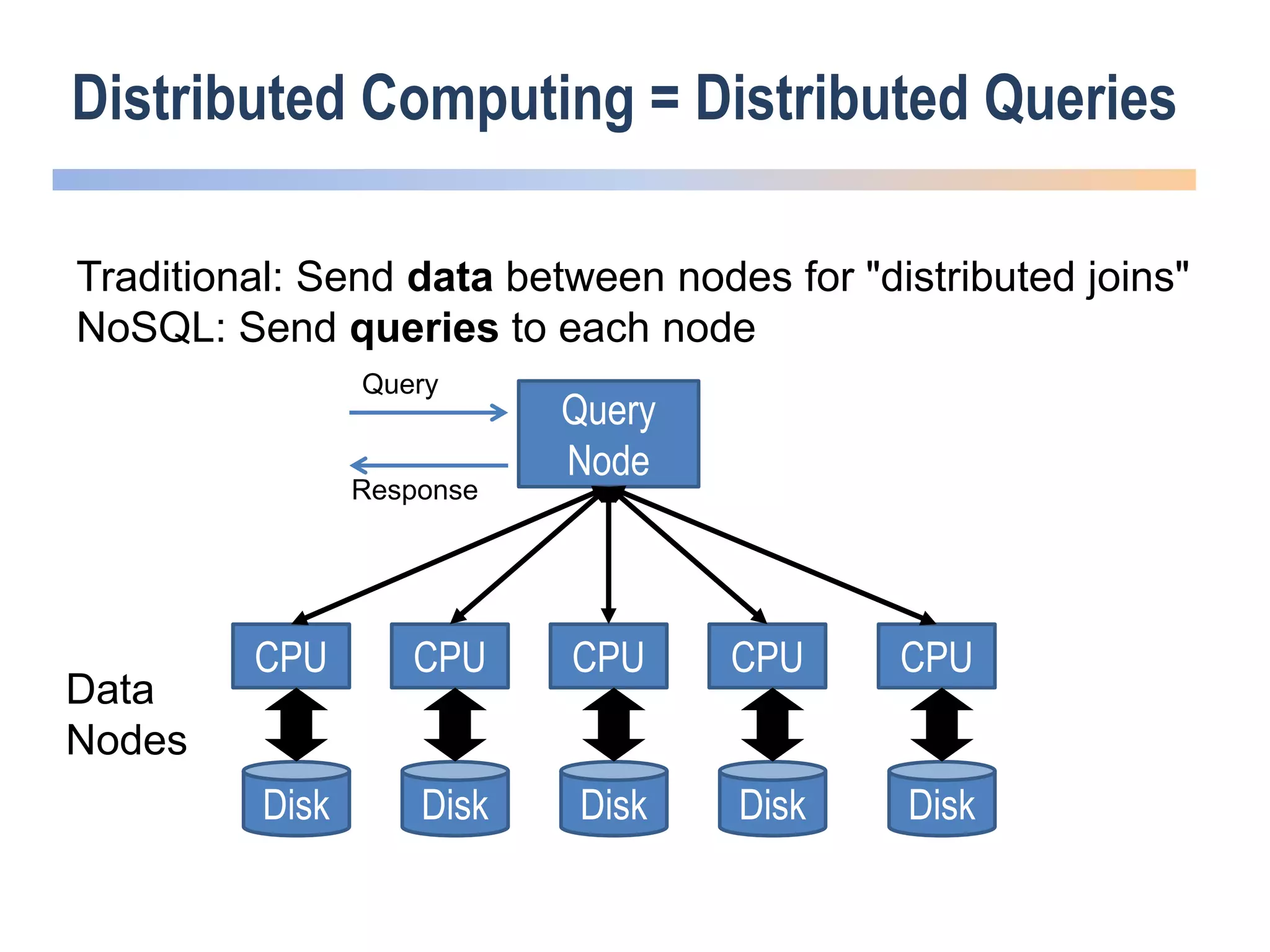

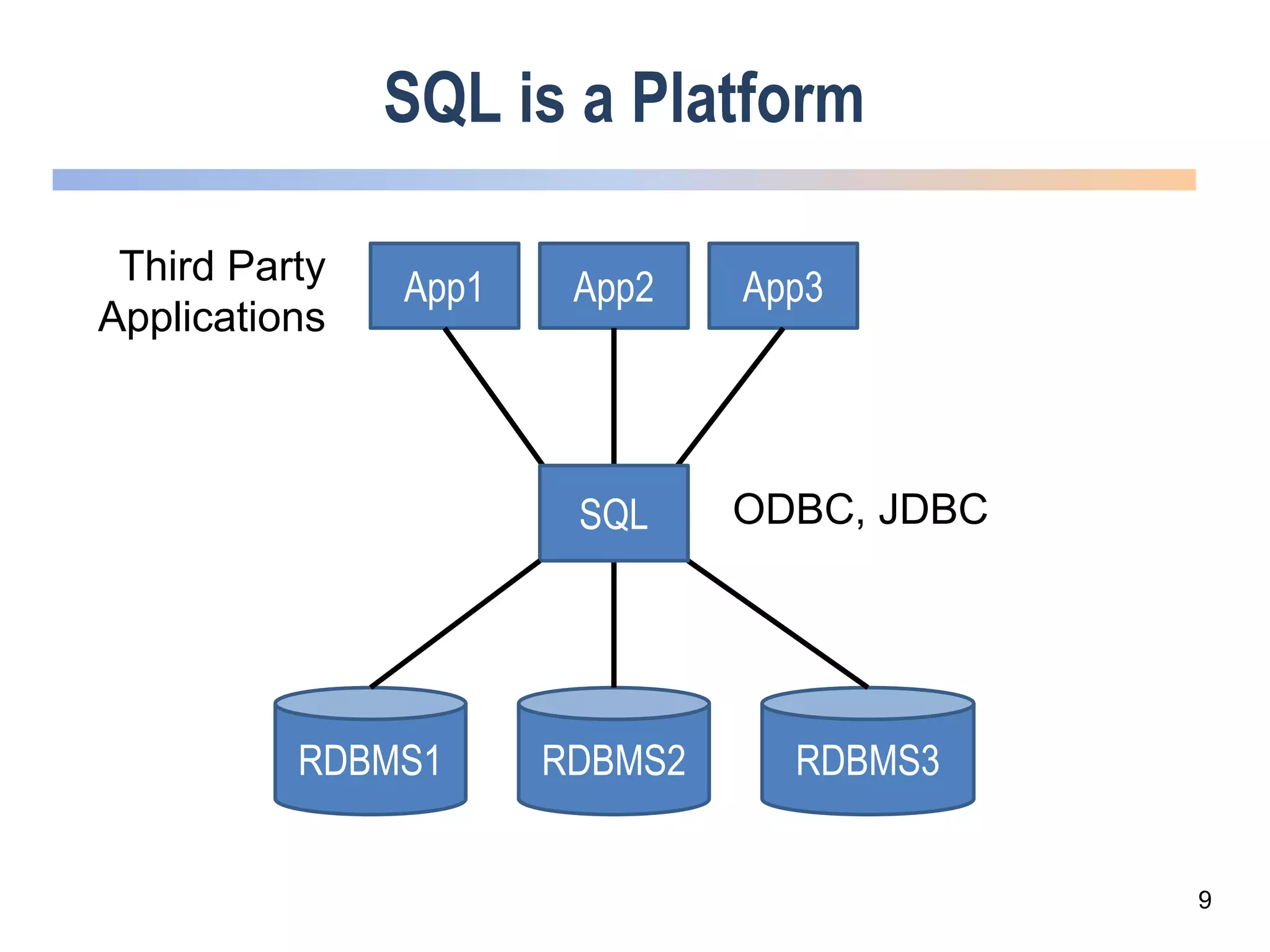
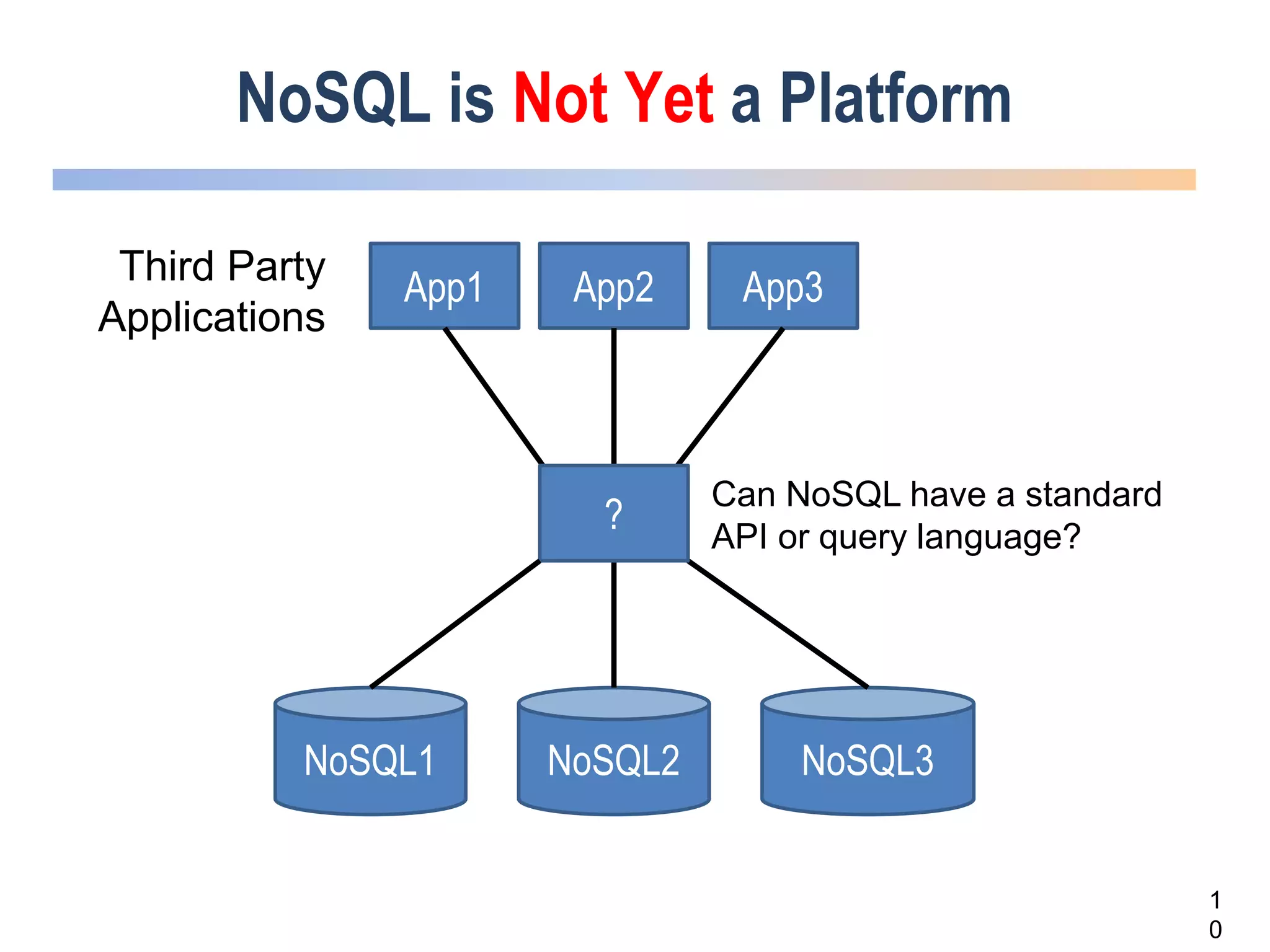
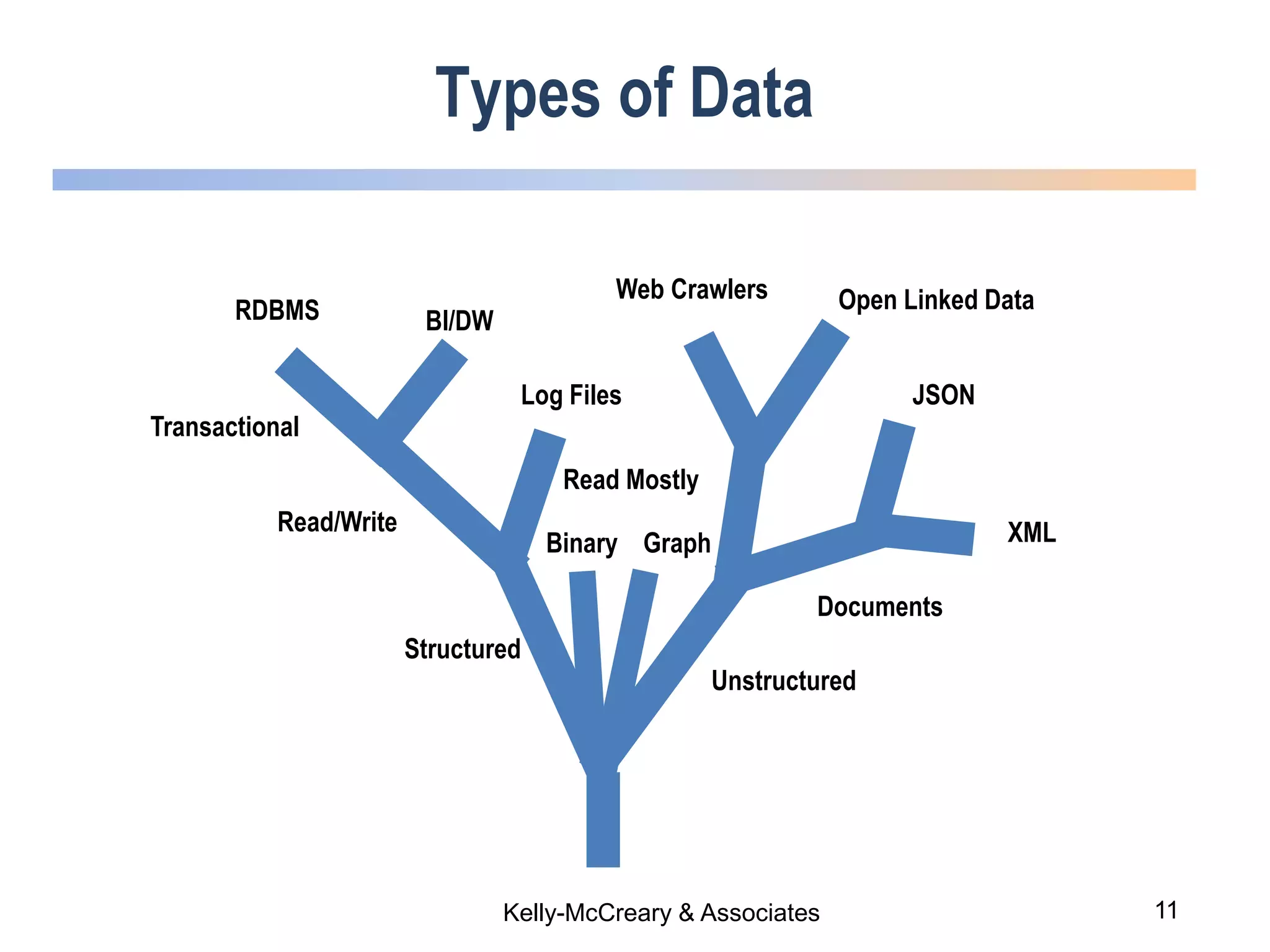


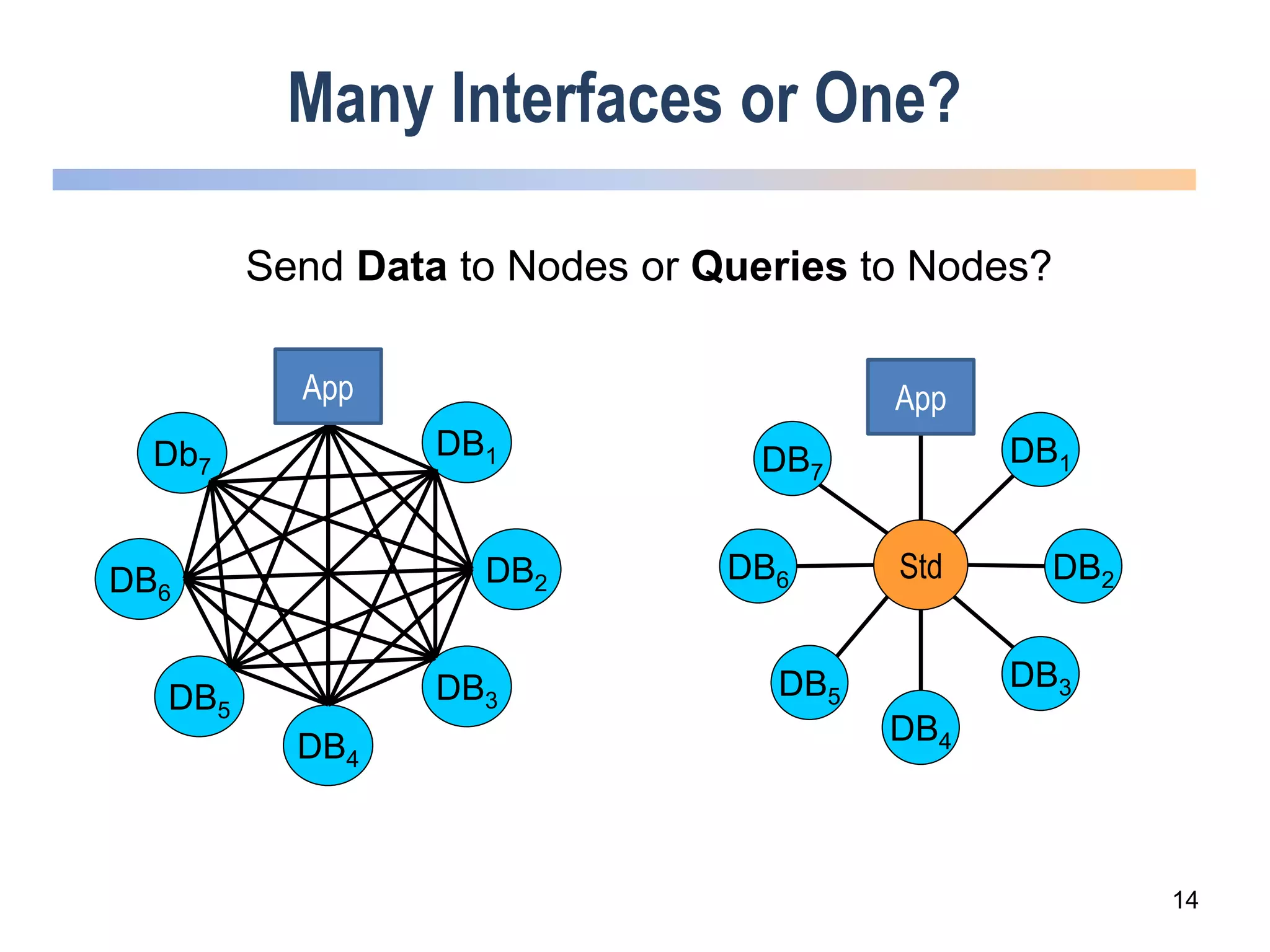

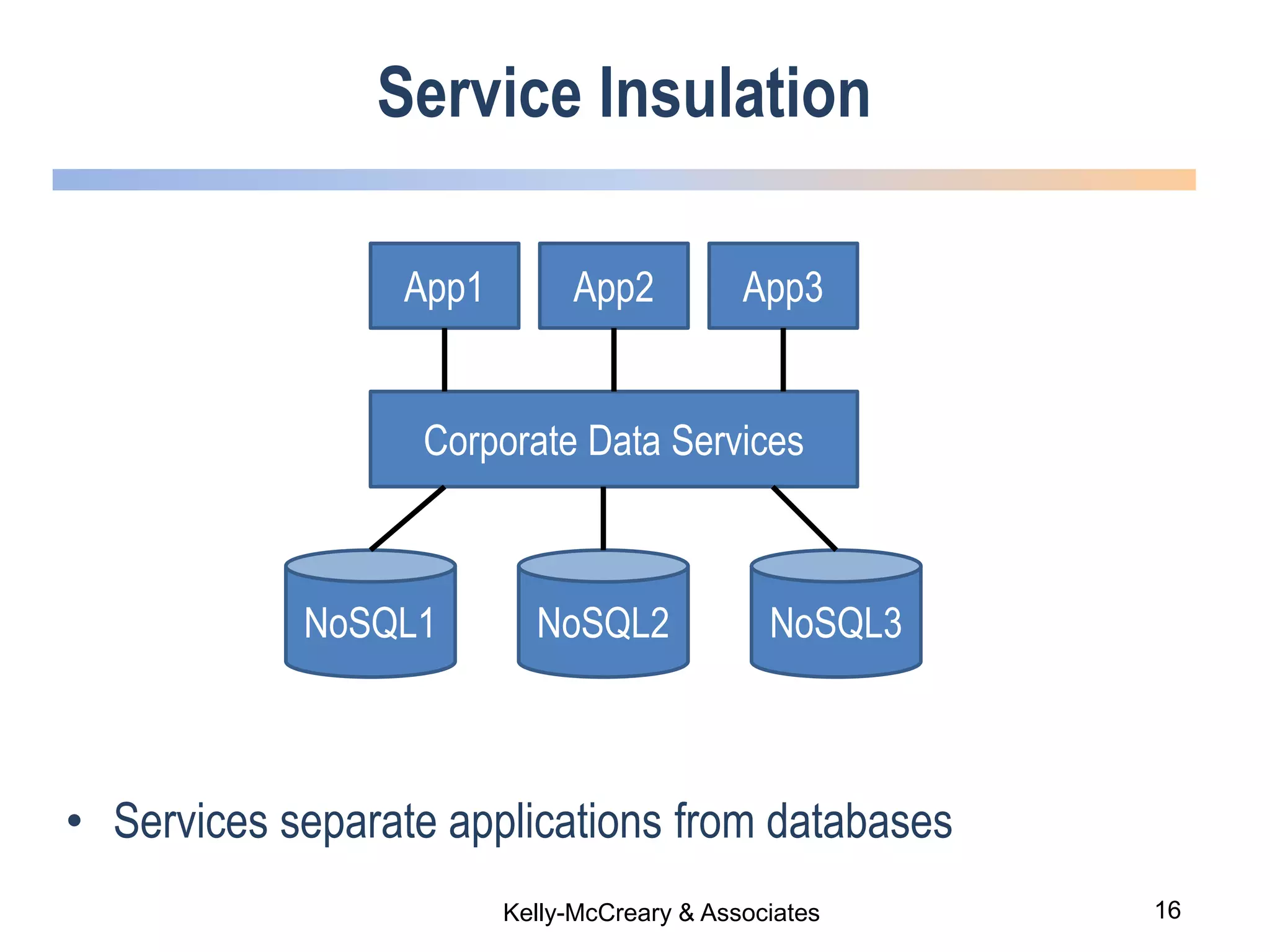
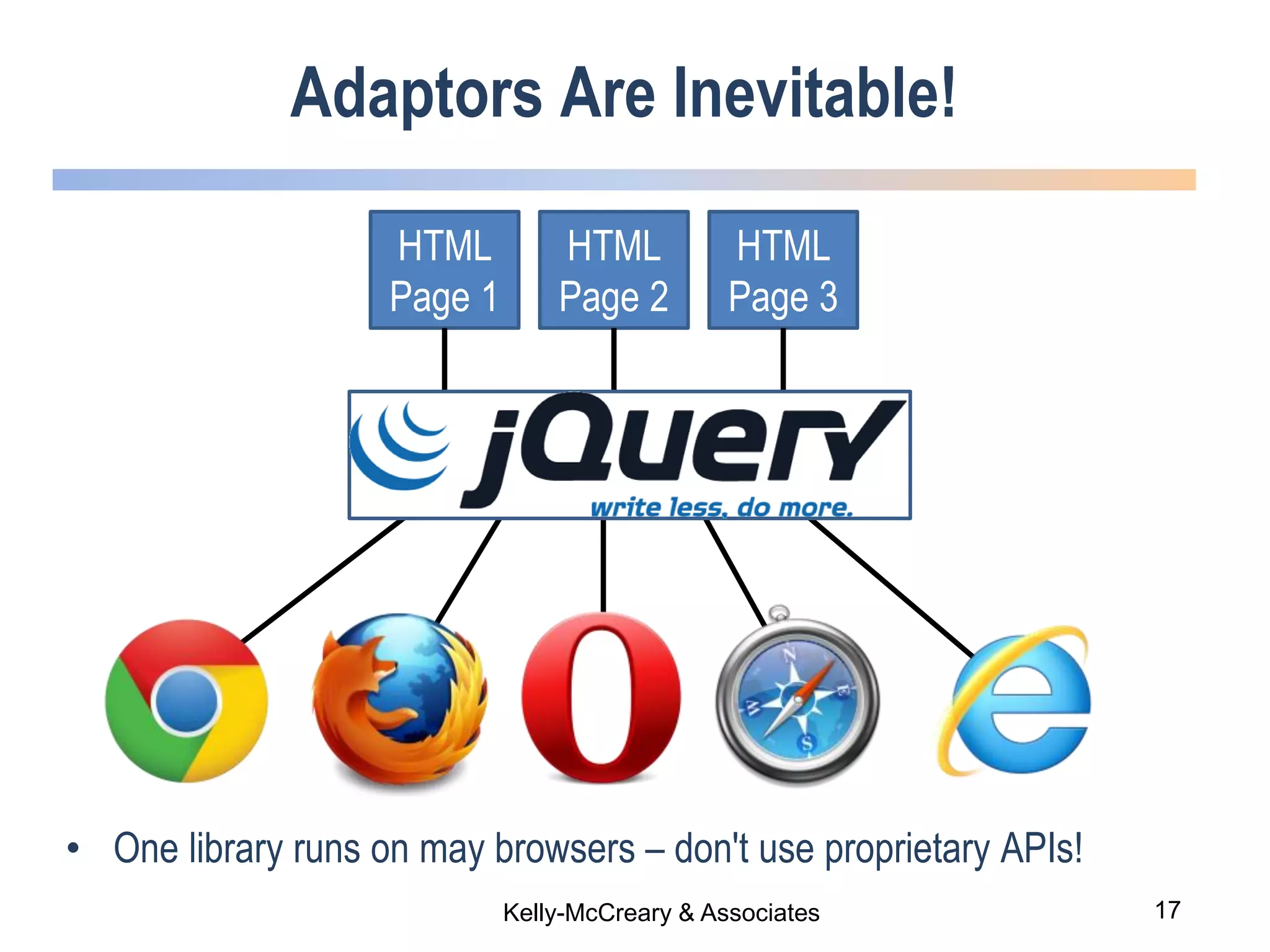

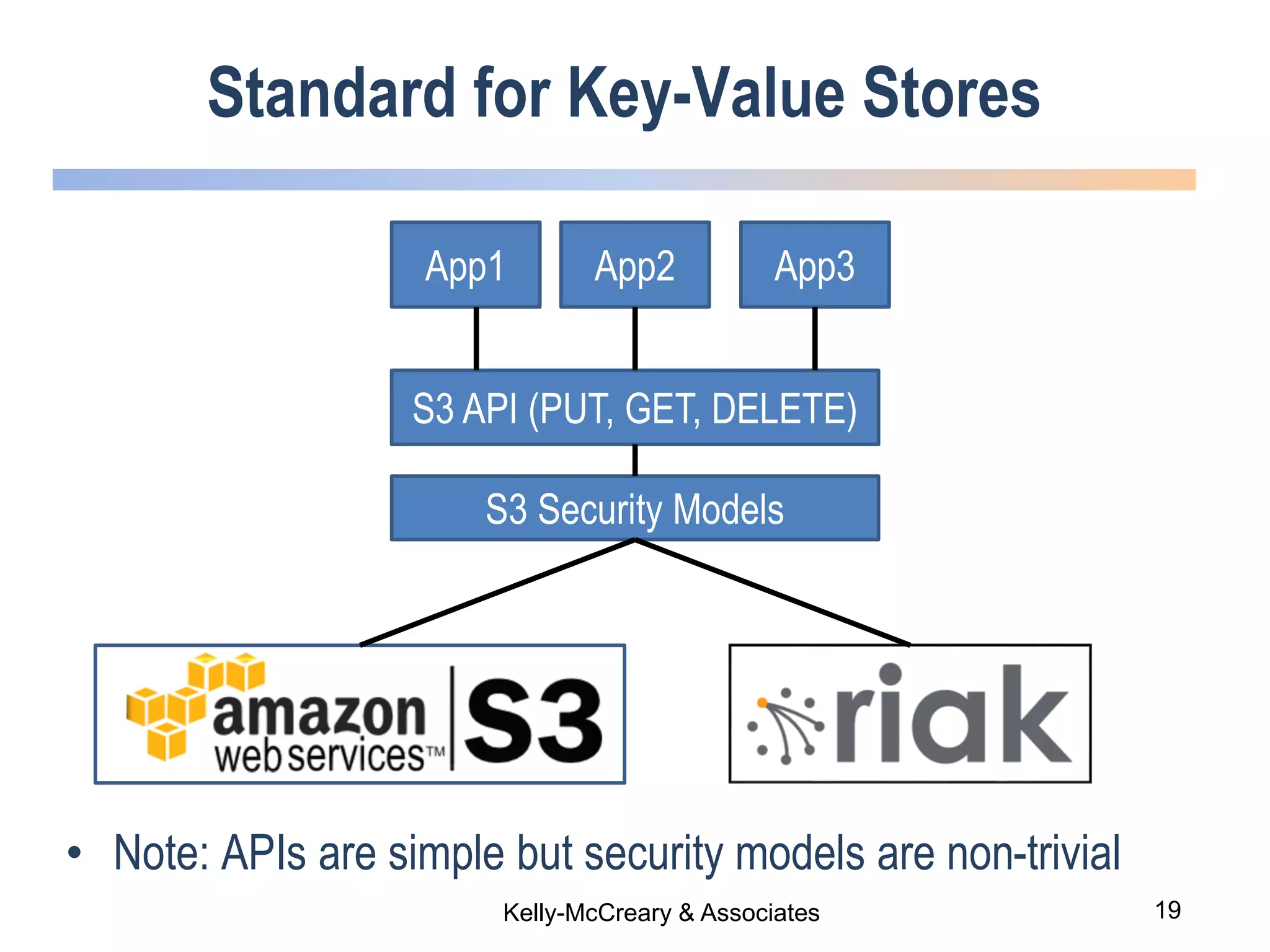

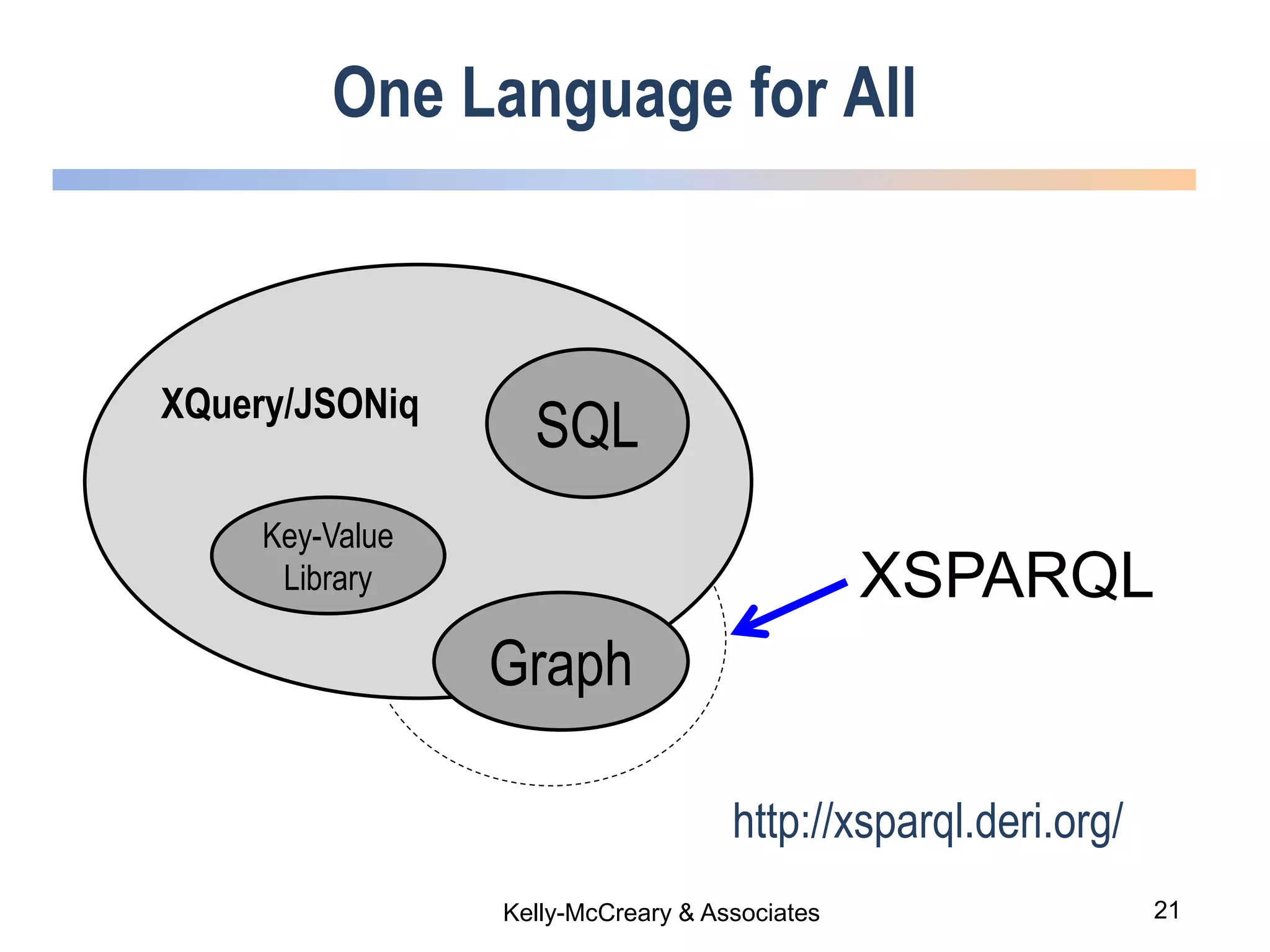
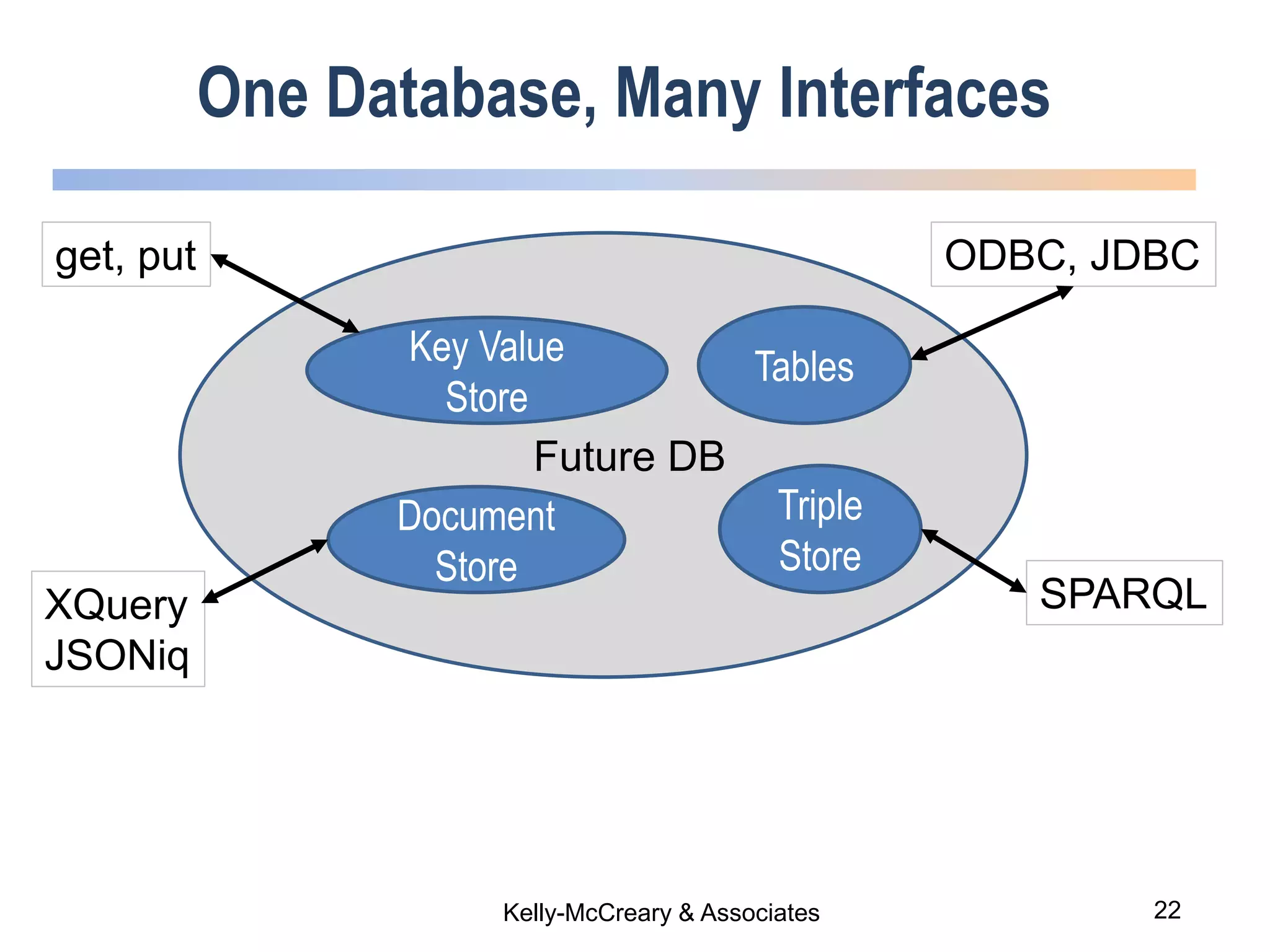
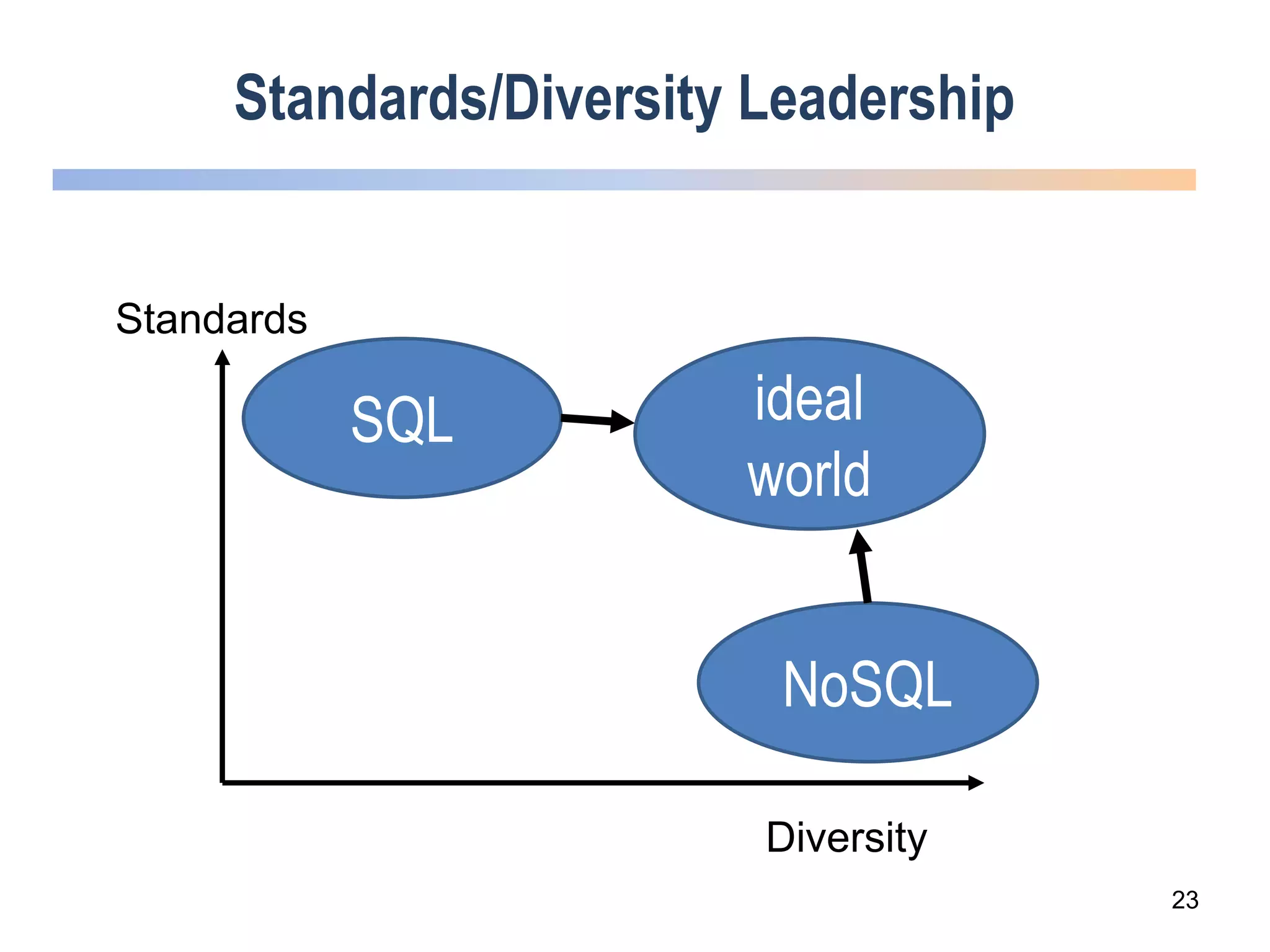

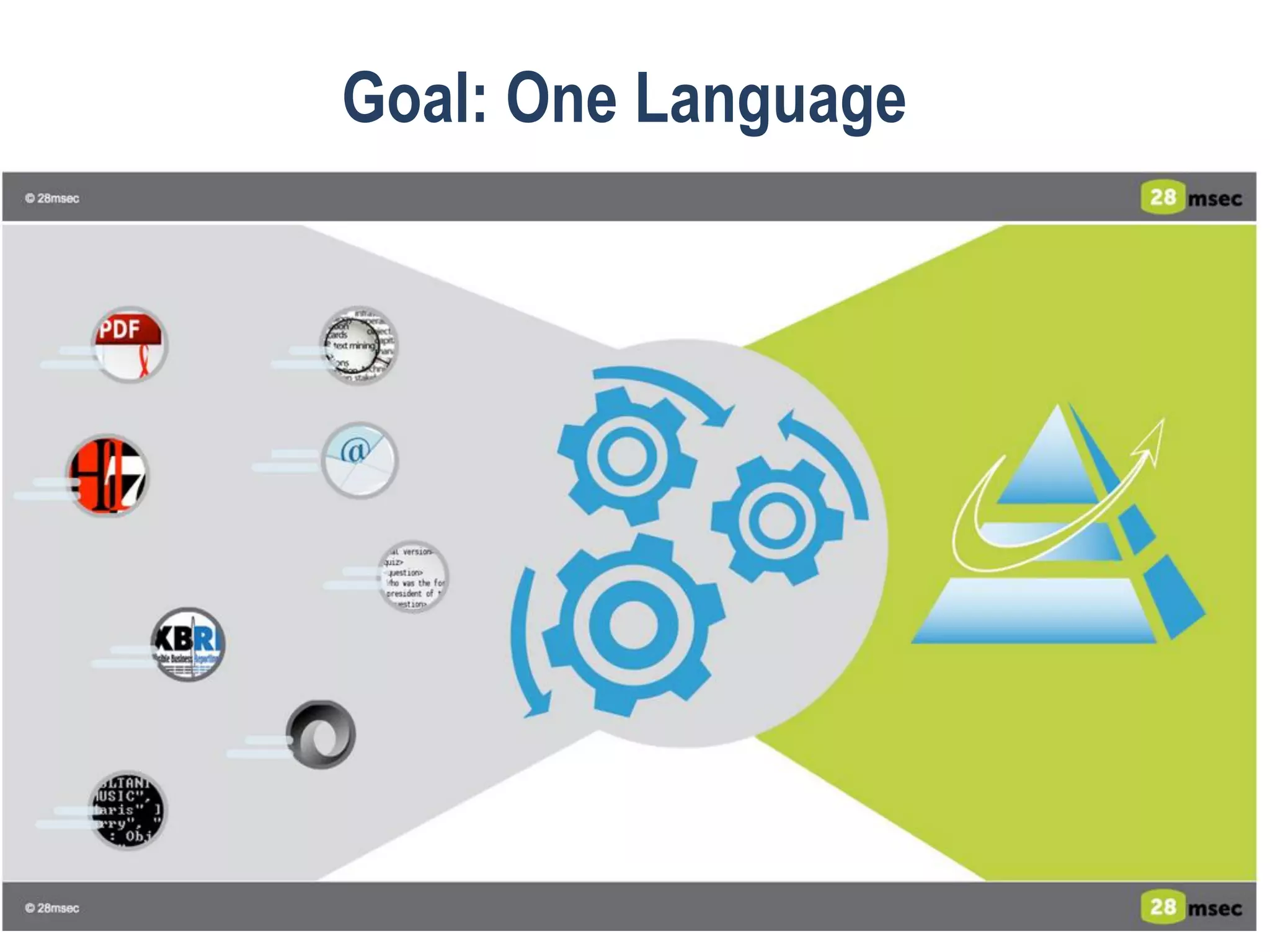




The webinar discusses trends in advanced query languages for NoSQL databases, highlighting how standardized query languages enable diverse data querying across various NoSQL databases. It features an interview with Matthias Brantner from 28msec about utilizing JSONiq in a modern ETL framework. The session aims to address the current limitations and explore the potential of common query languages like JSONiq to enhance application portability in NoSQL environments.



































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















