Schema in DataWarehouse modeling
Data Mining and Warehousing (Mount Kenya University)
Scan to open on Studocu
Studocu is not sponsored or endorsed by any college or university
Schema in Data Warehouse modeling
Data Mining and Warehousing (Mount Kenya University)
Scan to open on Studocu
Studocu is not sponsored or endorsed by any college or university
Downloaded by GOPIREDDY RAMANJANEYA REDDY (ramugopireddy07@gmail.com)
lOMoARcPSD|21403001
2.
WAREHOUSE SCHEMA
At theheart of every data warehouse lies a schema. But data warehouse schemas are more than
technical blueprints. They encapsulate an organization's business logic and analytical
requirements, translating complex data relationships into a structured format that supports
efficient querying and reporting.
Understanding data warehouse schemas is fundamental for anyone designing, implementing, or
using a data warehouse. Schemas are the linchpins that ensure data within the warehouse is
structured to support efficient storage, retrieval, and analysis, ultimately enabling organizations
to leverage their data for strategic decision-making.
Let’s go through what data warehouse schemas are, the most common types, and how you can
integrate schemas into your data warehouse.
What is a data warehouse schema?
A data warehouse schema describes how data is organized, stored, and related. The schema
serves as the template for constructing and populating a data warehouse, dictating the structure
of data tables, their relationships, and the rules governing data integrity and consistency.
The necessity for schemas in data warehousing stems from the need to integrate data from
various source systems into a cohesive, query-optimized format. This integration process
involves standardizing data formats, resolving inconsistencies, and defining transparent
relationships between data elements. Schemas provide a systematic approach to this integration,
enabling data from disparate sources to be combined in a way that supports comprehensive,
cross-functional analysis.
Downloaded by GOPIREDDY RAMANJANEYA REDDY (ramugopireddy07@gmail.com)
lOMoARcPSD|21403001
3.
Without a well-definedschema, a data warehouse becomes a disorganized repository, making
data retrieval inefficient and analysis unreliable. By carefully designing the schema,
organizations ensure that their data warehouse reflects their operational realities and is optimized
for the analytical queries that will be performed most frequently.
The key components of a data warehouse schema
Fact tables, dimension tables, attributes, and relationships – these are key components within a
data warehouse schema that support the efficient storage, retrieval, and analysis of large volumes
of data.
Fact tables
Fact tables are the central component of a data warehouse schema, primarily designed to store
quantitative information for analysis and reporting. These tables contain measurable, numerical
data known as facts and foreign keys related to dimension tables. Fact tables support storing data
related to business events, such as sales transactions, and are often large due to the volume of
transactions they capture.
Dimension tables
Dimension tables contain descriptive attributes or fields that categorize and provide context to
the numerical facts in the fact tables, making the data meaningful and accessible. They are used
for filtering, grouping, and labeling data. Examples of dimension tables include dates, products,
or customers. Dimension tables are typically smaller than fact tables and provide a textual
reference to the facts, making the data warehouse user-friendly.
Attributes
Downloaded by GOPIREDDY RAMANJANEYA REDDY (ramugopireddy07@gmail.com)
lOMoARcPSD|21403001
4.
Attributes are thedata elements that describe the instances in a dimension table, providing
additional details. For example, attributes in a customer dimension table might include customer
ID, name, address, and phone number. Attributes are used to search, filter, and classify data
within the warehouse.
Primary keys
A primary key is a unique identifier for each record in a table. It ensures that each record can be
uniquely identified, preventing duplicate entries. In dimension tables, primary keys are crucial
for uniquely identifying each dimension member, whereas, in fact tables, they might consist of a
composite key made up of several foreign keys that together provide a unique identifier for each
fact record.
Foreign keys
Foreign keys are columns in a fact table that uniquely identify a row in a dimension table,
creating a link between the fact and dimension tables. These keys enable the relational database
management system (RDBMS) to maintain referential integrity by ensuring each foreign key
value matches a primary key value in the dimension table. This relationship allows for the
efficient organization and retrieval of related data across tables.
Relationships
Relationships in a data warehouse schema define how data in one table is related to data in
another, typically between fact and dimension tables. These relationships are established through
primary and foreign keys, allowing users to perform complex queries that join data across
multiple tables. Relationships enable the analysis of facts within the context provided by
dimensions.
Downloaded by GOPIREDDY RAMANJANEYA REDDY (ramugopireddy07@gmail.com)
lOMoARcPSD|21403001
5.
Constraints
Constraints are rulesenforced on data columns in a table to ensure data integrity and accuracy.
These include primary key constraints (providing unique values for the column), foreign key
constraints (ensuring valid references to another table), and check constraints (ensuring that data
in a column meets certain conditions). Constraints help maintain the reliability of the data within
the warehouse.
Hierarchy
Hierarchy in a data warehouse refers to the levels of data categorization within dimension tables,
providing a means to drill down or roll up through different layers of data aggregation. For
example, a time dimension might have a year, quarter, month, and day hierarchy. Hierarchies are
essential for supporting various levels of data analysis and reporting.
Aggregated data
Aggregated data refers to data that has been summarized or rolled up from detailed data to a
higher-level summary. This is often done in fact tables to provide quicker access to summary
data for reporting and analysis, such as totals, averages, or counts. Aggregation helps improve
query performance and aids in analyzing trends over time.
Indexes
Indexes are data structures that improve the speed of data retrieval operations on a database table
by providing quick access to rows. Indexes are vital in data warehouses due to the large volume
of data and the need for quick retrieval times for complex queries. While indexes improve read
Downloaded by GOPIREDDY RAMANJANEYA REDDY (ramugopireddy07@gmail.com)
lOMoARcPSD|21403001
6.
performance, they canadd overhead to data insertion and update operations, so their use must be
balanced with overall system performance needs.
Types of Data Warehouse Schema.
The 3 most popular data warehouse schemas: Star, Snowflake, and Galaxy/Fact
Constellation
Star Schema in Data Warehouse modeling
A star schema is a type of data modeling technique used in data warehousing to represent data in
a structured and intuitive way. In a star schema, data is organized into a central fact table that
contains the measures of interest, surrounded by dimension tables that describe the attributes of
the measures.
The fact table in a star schema contains the measures or metrics that are of interest to the user or
organization. For example, in a sales data warehouse, the fact table might contain sales revenue,
units sold, and profit margins. Each record in the fact table represents a specific event or
transaction, such as a sale or order.
The dimension tables in a star schema contain the descriptive attributes of the measures in the
fact table. These attributes are used to slice and dice the data in the fact table, allowing users to
analyze the data from different perspectives. For example, in a sales data warehouse, the
dimension tables might include product, customer, time, and location.
In a star schema, each dimension table is joined to the fact table through a foreign key
relationship. This allows users to query the data in the fact table using attributes from the
dimension tables. For example, a user might want to see sales revenue by product category, or by
region and time period.
Downloaded by GOPIREDDY RAMANJANEYA REDDY (ramugopireddy07@gmail.com)
lOMoARcPSD|21403001
7.
The star schemais a popular data modeling technique in data warehousing because it is easy to
understand and query. The simple structure of the star schema allows for fast query response
times and efficient use of database resources. Additionally, the star schema can be easily
extended by adding new dimension tables or measures to the fact table, making it a scalable and
flexible solution for data warehousing.
Star schema is the fundamental schema among the data mart schema and it is simplest. This
schema is widely used to develop or build a data warehouse and dimensional data marts. It
includes one or more fact tables indexing any number of dimensional tables. The star schema is a
necessary cause of the snowflake schema. It is also efficient for handling basic queries.
It is said to be star as its physical model resembles to the star shape having a fact table at its
center and the dimension tables at its peripheral representing the star’s points. Below is an
example to demonstrate the Star Schema:
Downloaded by GOPIREDDY RAMANJANEYA REDDY (ramugopireddy07@gmail.com)
lOMoARcPSD|21403001
8.
In the abovedemonstration, SALES is a fact table having attributes i.e. (Product ID, Order ID,
Customer ID, Employer ID, Total, Quantity, Discount) which references to the dimension
tables. Employee dimension table contains the attributes: Emp ID, Emp Name, Title,
Department and Region. Product dimension table contains the attributes: Product ID, Product
Name, Product Category, Unit Price. Customer dimension table contains the attributes: Customer
ID, Customer Name, Address, City, Zip. Time dimension table contains the attributes: Order ID,
Order Date, Year, Quarter, Month.
Model of Star Schema:
In Star Schema, Business process data, that holds the quantitative data about a business is
distributed in fact tables, and dimensions which are descriptive characteristics related to fact
Downloaded by GOPIREDDY RAMANJANEYA REDDY (ramugopireddy07@gmail.com)
lOMoARcPSD|21403001
9.
data. Sales price,sale quantity, distant, speed, weight, and weight measurements are few
examples of fact data in star schema.
Often, A Star Schema having multiple dimensions is termed as Centipede Schema. It is easy to
handle a star schema which have dimensions of few attributes.
Advantages of Star Schema:
1. Simpler Queries –
Join logic of star schema is quite cinch in comparison to other join logic which are
needed to fetch data from a transactional schema that is highly normalized.
2. Simplified Business Reporting Logic –
In comparison to a transactional schema that is highly normalized, the star schema makes
simpler common business reporting logic, such as of reporting and period-over-period.
3. Feeding Cubes –
Star schema is widely used by all OLAP systems to design OLAP cubes efficiently. In
fact, major OLAP systems deliver a ROLAP mode of operation which can use a star
schema as a source without designing a cube structure.
Disadvantages of Star Schema –
1. Data integrity is not enforced well since in a highly de-normalized schema state.
2. Not flexible in terms if analytical needs as a normalized data model.
3. Star schemas don’t reinforce many-to-many relationships within business entities – at
least not frequently.
Features:
Downloaded by GOPIREDDY RAMANJANEYA REDDY (ramugopireddy07@gmail.com)
lOMoARcPSD|21403001
10.
Central fact table:The star schema revolves around a central fact table that contains the
numerical data being analyzed. This table contains foreign keys to link to dimension tables.
Dimension tables: Dimension tables are tables that contain descriptive attributes about the data
being analyzed. These attributes provide context to the numerical data in the fact table. Each
dimension table is linked to the fact table through a foreign key.
Denormalized structure: A star schema is denormalized, which means that redundancy is
allowed in the schema design to improve query performance. This is because it is easier and
faster to join a small number of tables than a large number of tables.
Simple queries: Star schema is designed to make queries simple and fast. Queries can be written
in a straightforward manner by joining the fact table with the appropriate dimension tables.
Aggregated data: The numerical data in the fact table is usually aggregated at different levels of
granularity, such as daily, weekly, or monthly. This allows for analysis at different levels of
detail.
Fast performance: Star schema is designed for fast query performance. This is because the
schema is denormalized and data is pre-aggregated, making queries faster and more efficient.
Easy to understand: The star schema is easy to understand and interpret, even for non-technical
users. This is because the schema is designed to provide context to the numerical data through
the use of dimension tables.
Downloaded by GOPIREDDY RAMANJANEYA REDDY (ramugopireddy07@gmail.com)
lOMoARcPSD|21403001
11.
Snowflake Schema inData Warehouse Model
The snowflake schema is a variant of the star schema. Here, the centralized fact table is
connected to multiple dimensions. In the snowflake schema, dimensions are present in
a normalized form in multiple related tables. The snowflake structure materialized when the
dimensions of a star schema are detailed and highly structured, having several levels of
relationship, and the child tables have multiple parent tables. The snowflake effect affects only
the dimension tables and does not affect the fact tables.
A snowflake schema is a type of data modeling technique used in data warehousing to represent
data in a structured way that is optimized for querying large amounts of data efficiently. In a
snowflake schema, the dimension tables are normalized into multiple related tables, creating a
hierarchical or “snowflake” structure.
In a snowflake schema, the fact table is still located at the center of the schema, surrounded by
the dimension tables. However, each dimension table is further broken down into multiple
related tables, creating a hierarchical structure that resembles a snowflake.
For Example, in a sales data warehouse, the product dimension table might be normalized into
multiple related tables, such as product category, product subcategory, and product details. Each
of these tables would be related to the product dimension table through a foreign
key relationship.
Example:
Downloaded by GOPIREDDY RAMANJANEYA REDDY (ramugopireddy07@gmail.com)
lOMoARcPSD|21403001
12.
Snowflake Schema
The Employeedimension table now contains the attributes: EmployeeID, EmployeeName,
DepartmentID, Region, and Territory. The DepartmentID attribute links with the Employee table
with the Department dimension table. The Department dimension is used to provide detail
about each department, such as the Name and Location of the department.
The Customer dimension table now contains the attributes: CustomerID, CustomerName,
Address, and CityID. The CityID attributes link the Customer dimension table with
the City dimension table. The City dimension table has details about each city such as city name,
Zipcode, State, and Country.
What is Snowflaking?
The snowflake design is the result of further expansion and normalization of the dimension table.
In other words, a dimension table is said to be snowflaked if the low-cardinality attribute of the
dimensions has been divided into separate normalized tables. These tables are then joined to the
Downloaded by GOPIREDDY RAMANJANEYA REDDY (ramugopireddy07@gmail.com)
lOMoARcPSD|21403001
13.
original dimension tablewith referential constraints (foreign key constrain).
Generally, snowflaking is not recommended in the dimension table, as it hampers the
understandability and performance of the dimension model as more tables would be required to
be joined to satisfy the queries.
Difference Between Snowflake and Star Schema
The main difference between star schema and snowflake schema is that the dimension table of
the snowflake schema is maintained in the normalized form to reduce redundancy. The
advantage here is that such tables (normalized) are easy to maintain and save storage space.
However, it also means that more joins will be needed to execute the query. This will adversely
impact system performance.
However, the snowflake schema can also be more complex to query than a star schema because
it requires more table joins. This can result in slower query response times and higher resource
usage in the database. Additionally, the snowflake schema can be more difficult to understand
and maintain because of the increased complexity of the schema design.
The decision to use a snowflake schema versus a star schema in a data warehousing project will
depend on the specific requirements of the project and the trade-offs between query performance,
schema complexity, and data integrity.
Characteristics of Snowflake Schema
• The snowflake schema uses small disk space.
• It is easy to implement the dimension that is added to the schema.
• There are multiple tables, so performance is reduced.
Downloaded by GOPIREDDY RAMANJANEYA REDDY (ramugopireddy07@gmail.com)
lOMoARcPSD|21403001
14.
• The dimensiontable consists of two or more sets of attributes that define information at
different grains.
• The sets of attributes of the same dimension table are populated by different source
systems.
Features of the Snowflake Schema
• Normalization: The snowflake schema is a normalized design, which means that data is
organized into multiple related tables. This reduces data redundancy and improves data
consistency.
• Hierarchical Structure: The snowflake schema has a hierarchical structure that is
organized around a central fact table. The fact table contains the measures or metrics of
interest, and the dimension tables contain the attributes that provide context to the
measures.
• Multiple Levels: The snowflake schema can have multiple levels of dimension tables,
each related to the central fact table. This allows for more granular analysis of data and
enables users to drill down into specific subsets of data.
• Joins: The snowflake schema typically requires more complex SQL queries that involve
multiple tables joins. This can impact performance, especially when dealing with large
data sets.
• Scalability: The snowflake schema is scalable and can handle large volumes of data.
However, the complexity of the schema can make it difficult to manage and maintain.
Advantages of Snowflake Schema
• It provides structured data which reduces the problem of data integrity.
Downloaded by GOPIREDDY RAMANJANEYA REDDY (ramugopireddy07@gmail.com)
lOMoARcPSD|21403001
15.
• It usessmall disk space because data are highly structured.
Disadvantages of Snowflake Schema
• Snowflaking reduces space consumed by dimension tables but compared with the entire
data warehouse the saving is usually insignificant.
• Avoid snowflaking or normalization of a dimension table, unless required and
appropriate.
• Do not snowflake hierarchies of dimension table into separate tables. Hierarchies should
belong to the dimension table only and should never be snowflakes.
• Multiple hierarchies that can belong to the same dimension have been designed at the
lowest possible detail.
Fact Constellation in Data Warehouse modelling
Fact Constellation is a schema for representing multidimensional model. It is a collection of
multiple fact tables having some common dimension tables. It can be viewed as a collection of
several star schemas and hence, also known as Galaxy schema. It is one of the widely used
schemas for Data warehouse designing and it is much more complex than star and snowflake
schema. For complex systems, we require fact constellations.
Downloaded by GOPIREDDY RAMANJANEYA REDDY (ramugopireddy07@gmail.com)
lOMoARcPSD|21403001
16.
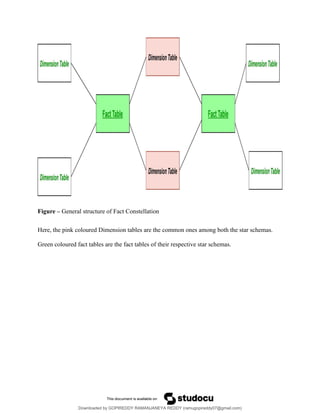
Figure – Generalstructure of Fact Constellation
Here, the pink coloured Dimension tables are the common ones among both the star schemas.
Green coloured fact tables are the fact tables of their respective star schemas.
Downloaded by GOPIREDDY RAMANJANEYA REDDY (ramugopireddy07@gmail.com)
lOMoARcPSD|21403001
17.
Example:
In above demonstration:
•Placement is a fact table having attributes: (Stud_roll, Company_id, TPO_id) with facts:
(Number of students eligible, Number of students placed).
• Workshop is a fact table having attributes: (Stud_roll, Institute_id, TPO_id) with facts:
(Number of students selected, Number of students attended the workshop).
• Company is a dimension table having attributes: (Company_id, Name, Offer_package).
• Student is a dimension table having attributes: (Student_roll, Name, CGPA).
• TPO is a dimension table having attributes: (TPO_id, Name, Age).
Downloaded by GOPIREDDY RAMANJANEYA REDDY (ramugopireddy07@gmail.com)
lOMoARcPSD|21403001
18.
• Training Instituteis a dimension table having attributes: (Institute_id, Name,
Full_course_fee).
So, there are two fact tables namely, Placement and Workshop which are part of two different
star schemas having dimension tables – Company, Student and TPO in Star schema with fact
table Placement and dimension tables – Training Institute, Student and TPO in Star schema with
fact table Workshop. Both the star schema have two dimension tables common and hence,
forming a fact constellation or galaxy schema.
Advantage: Provides a flexible schema.
Disadvantage: It is much more complex and hence, hard to implement and maintain.
Downloaded by GOPIREDDY RAMANJANEYA REDDY (ramugopireddy07@gmail.com)
lOMoARcPSD|21403001