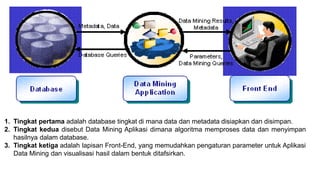
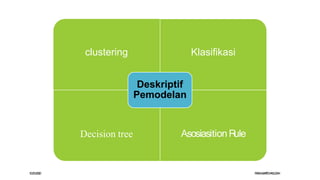
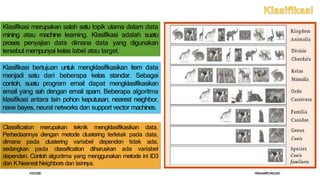
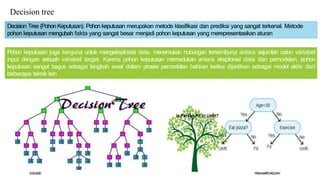
Dokumen ini membahas tiga tingkat arsitektur data mining: tingkat database untuk penyimpanan data, aplikasi data mining untuk pengolahan data, dan front-end untuk visualisasi hasil. Selain itu, dijelaskan juga tentang pemodelan prediktif, klasifikasi, clustering, serta aturan asosiasi yang berfungsi untuk menganalisis dan menemukan pola dalam data. Contoh penggunaan metode ini termasuk penyaringan spam dan analisis perilaku pelanggan dalam pemasaran.