Download as PDF, PPTX











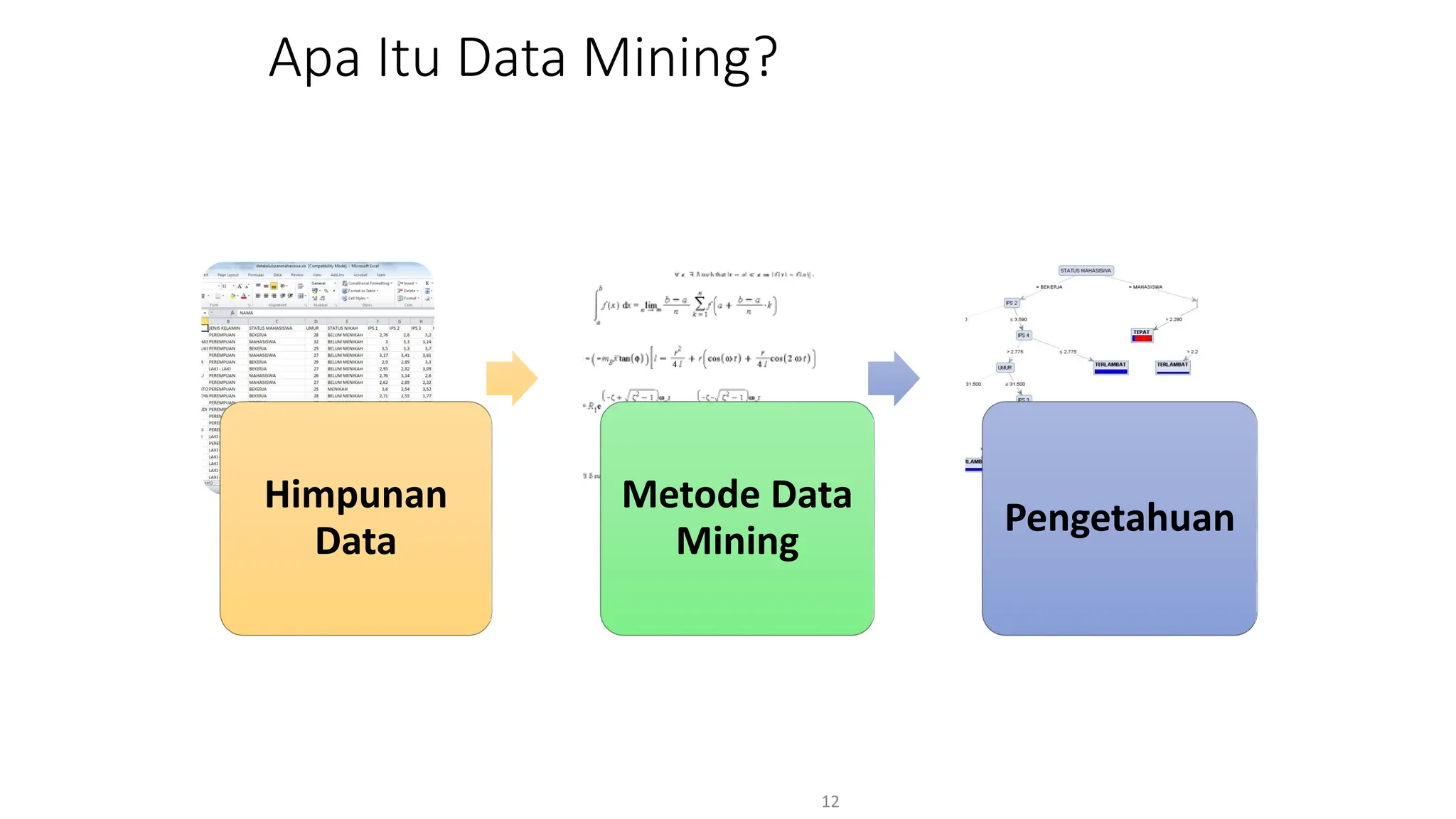

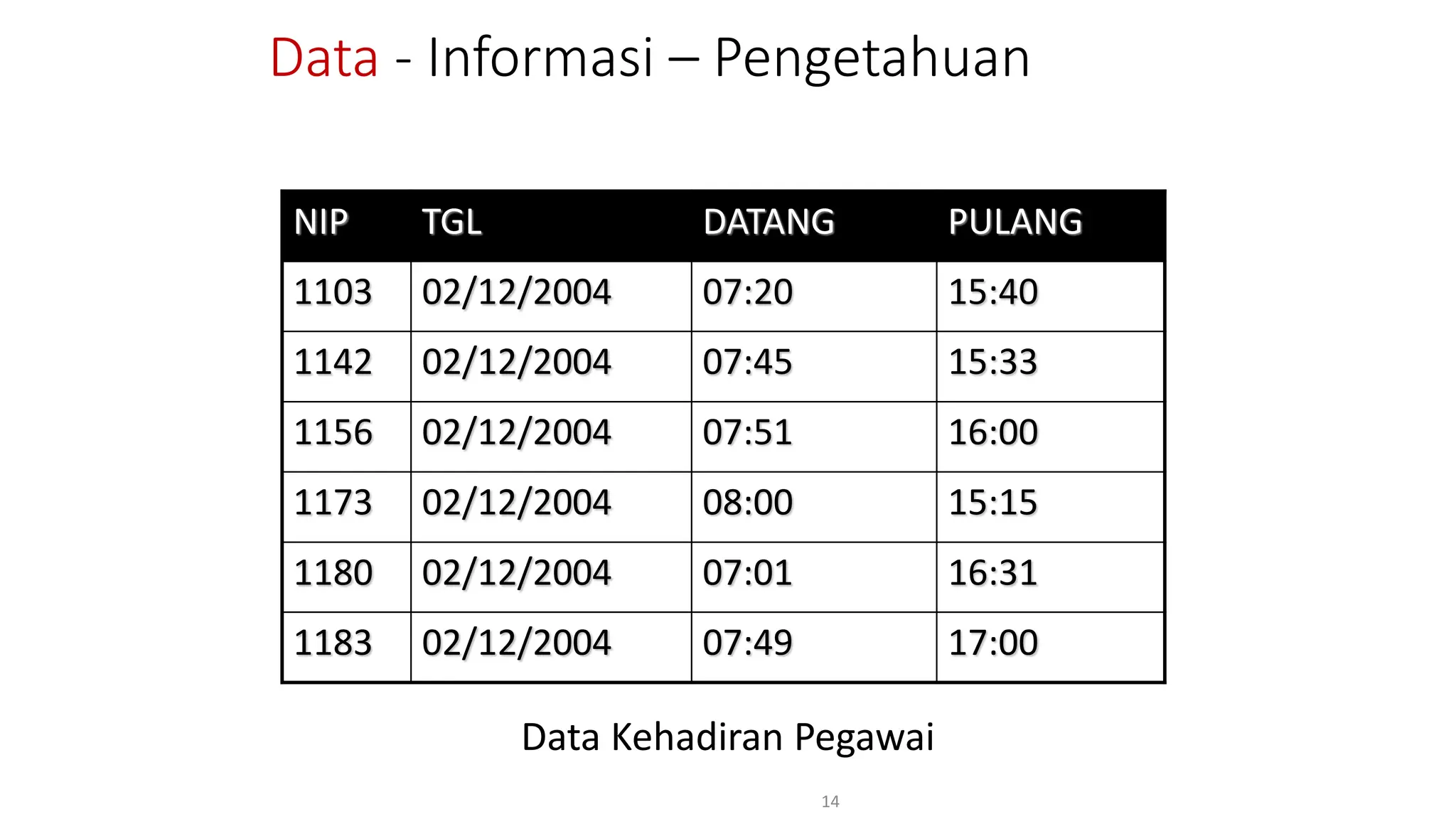
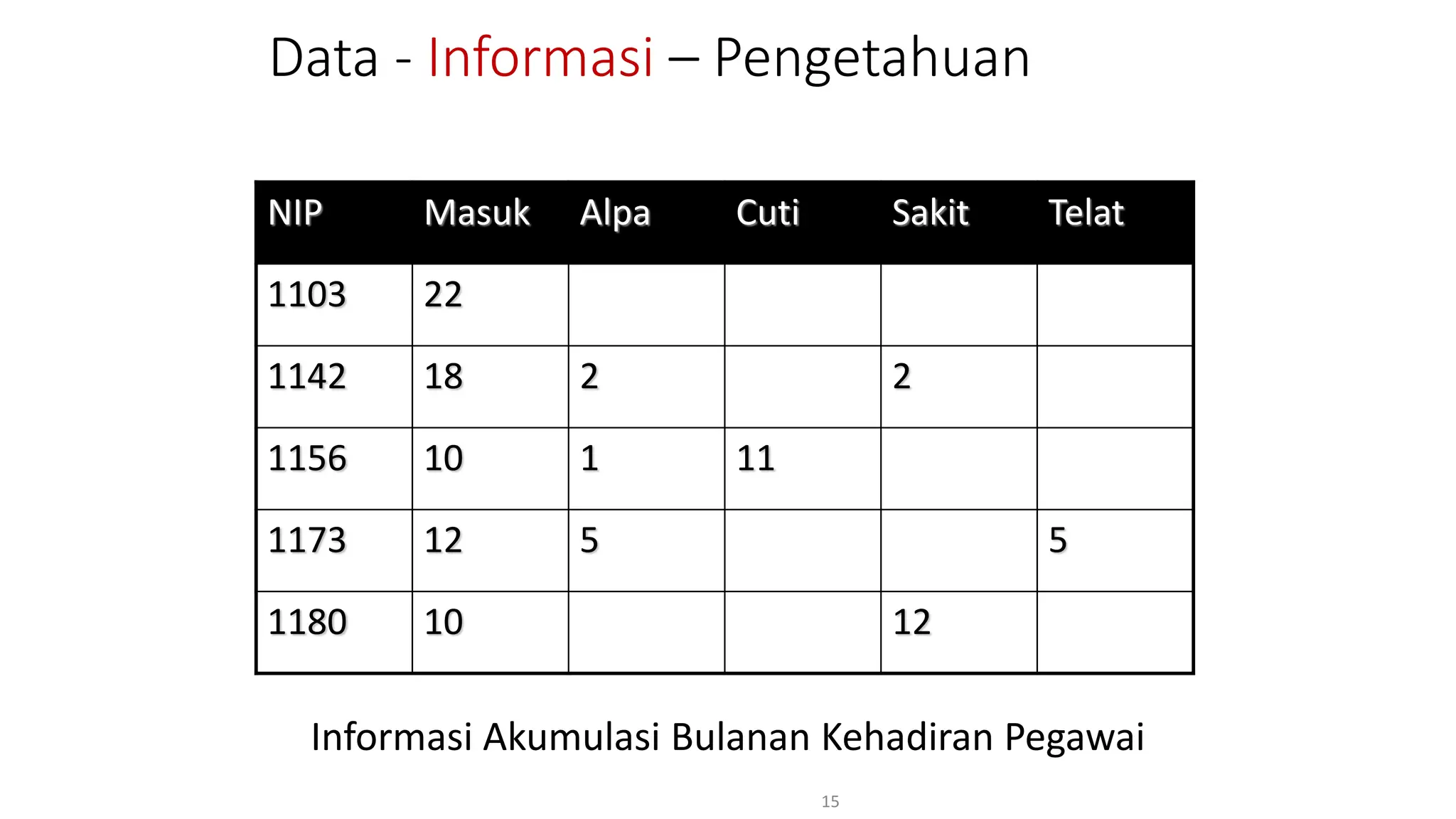
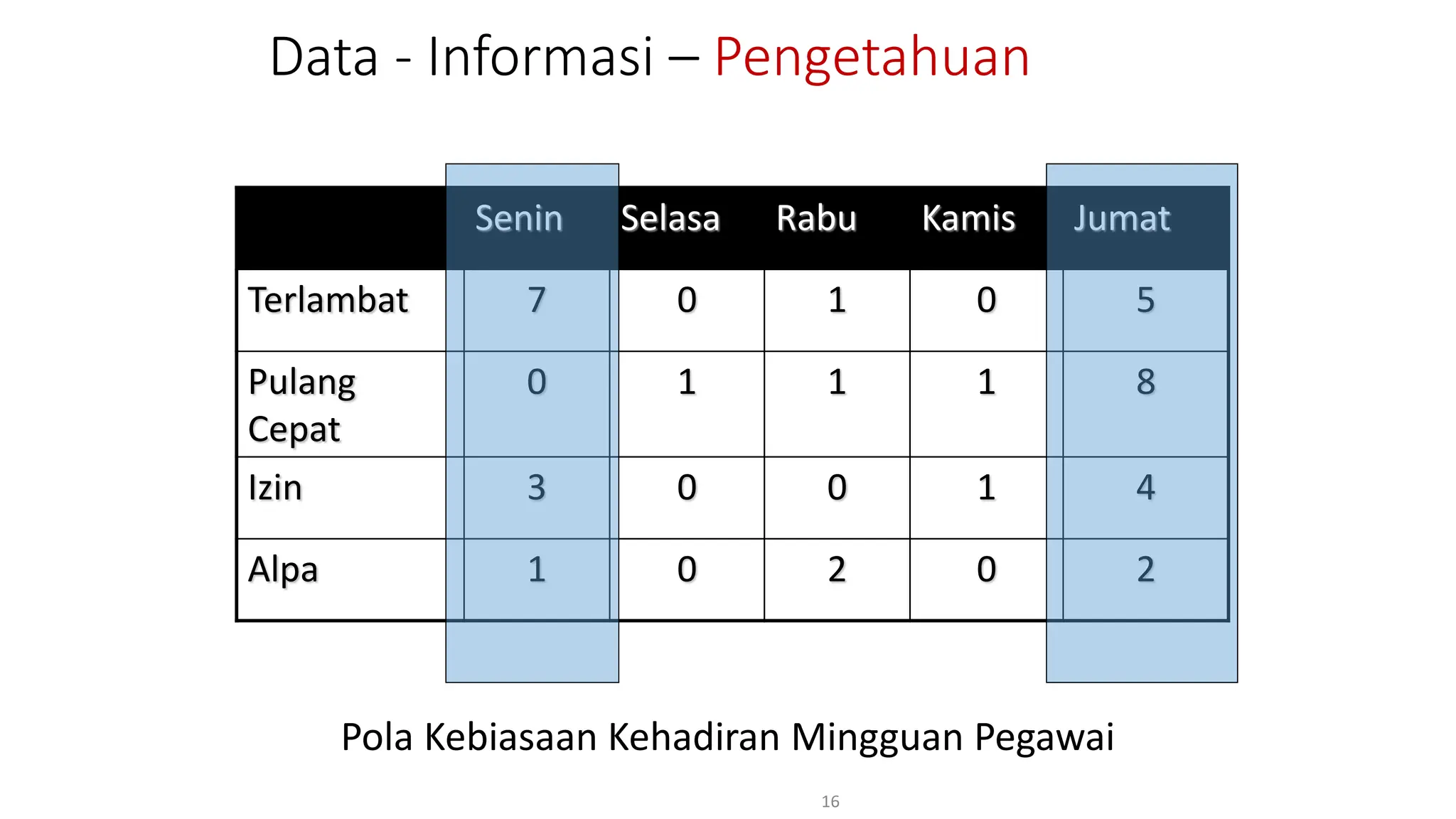

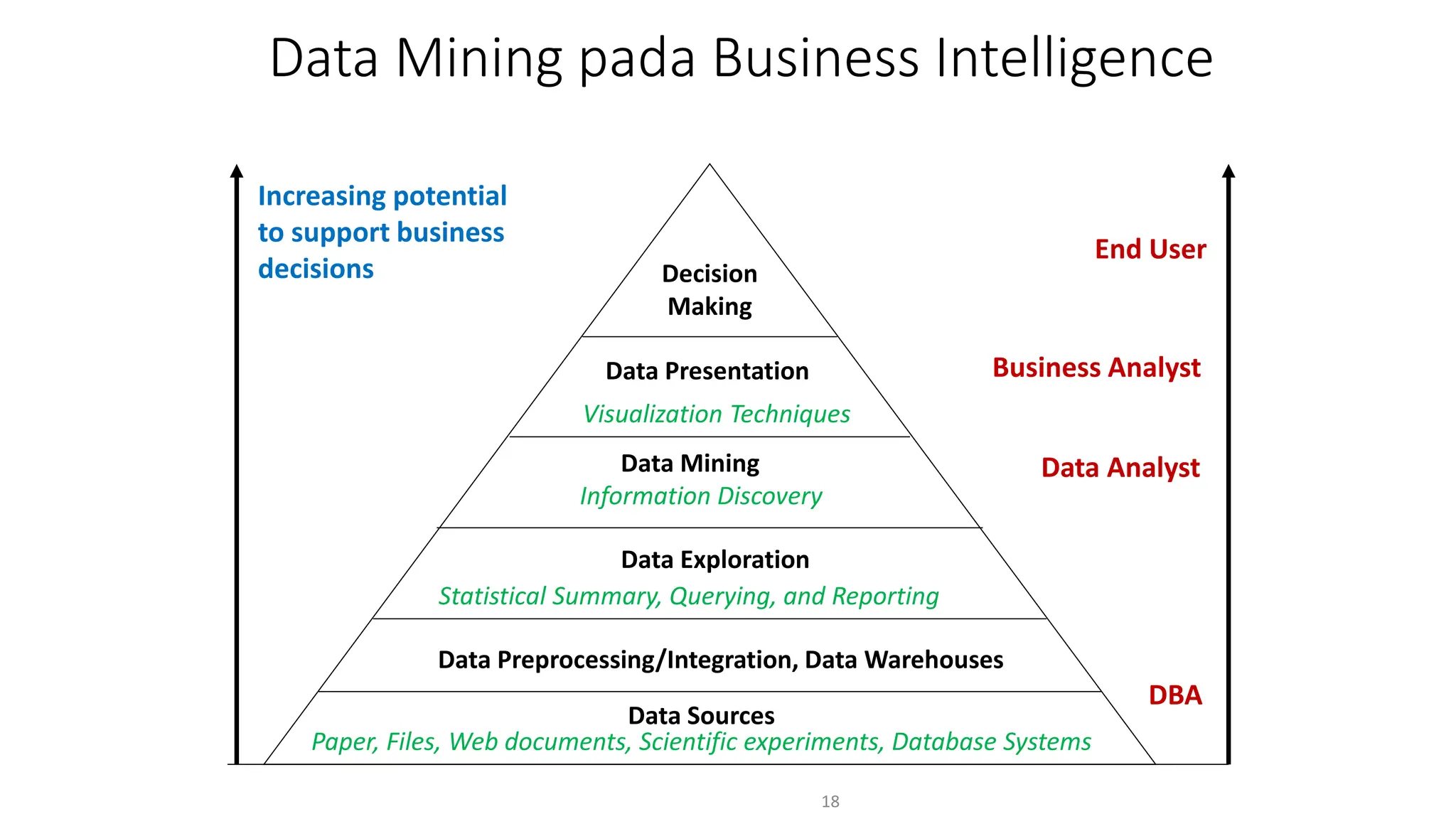
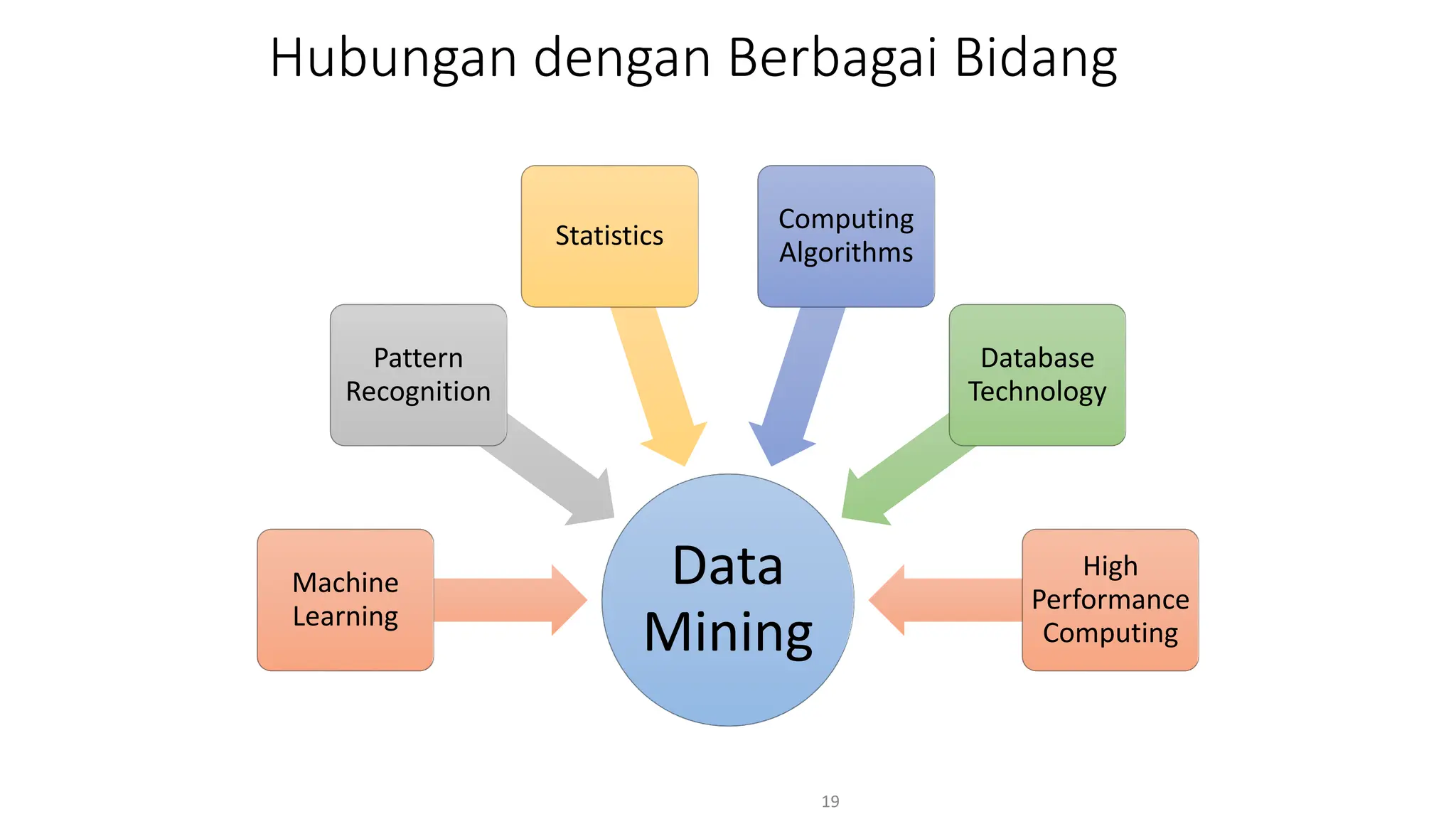


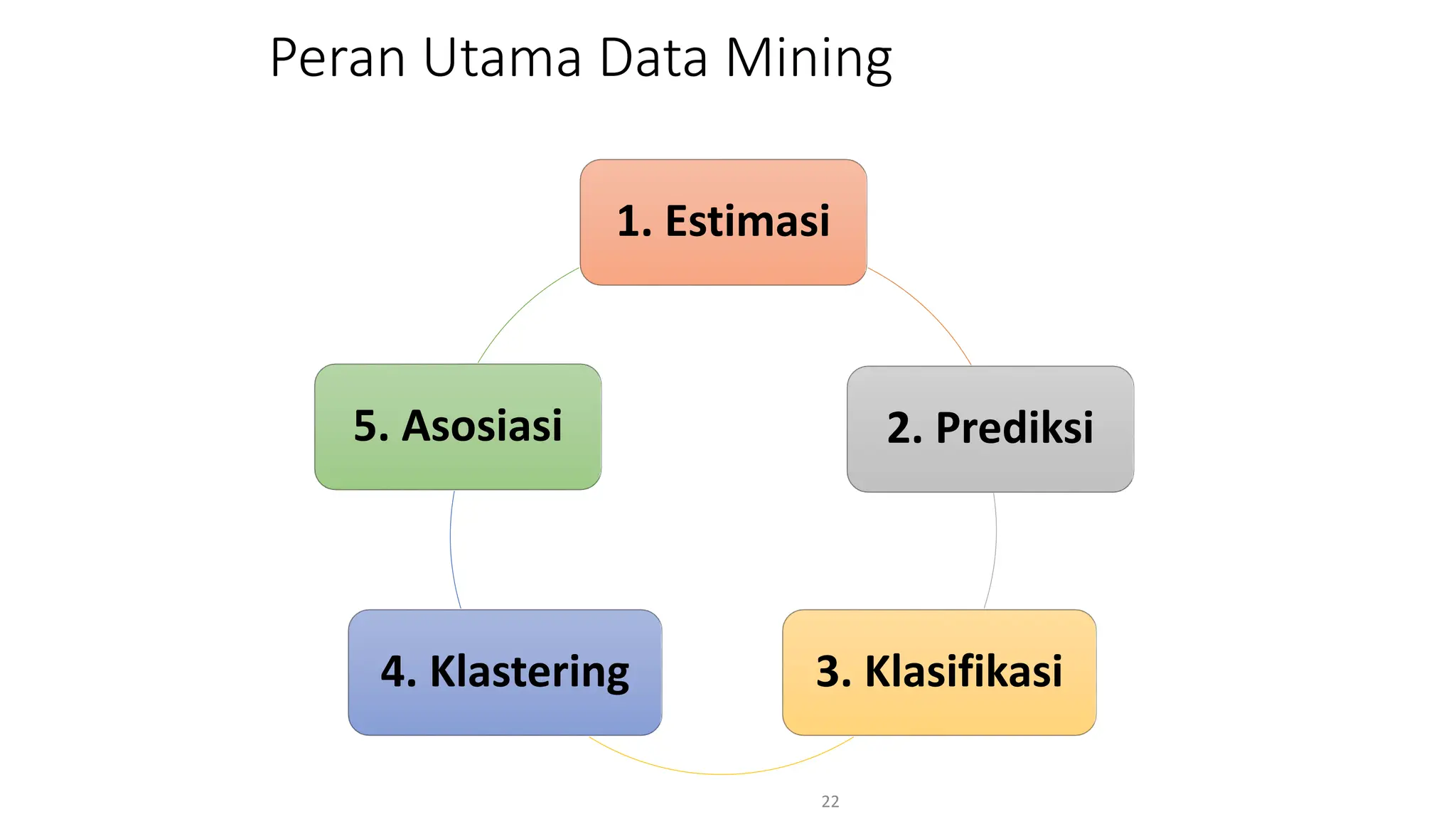


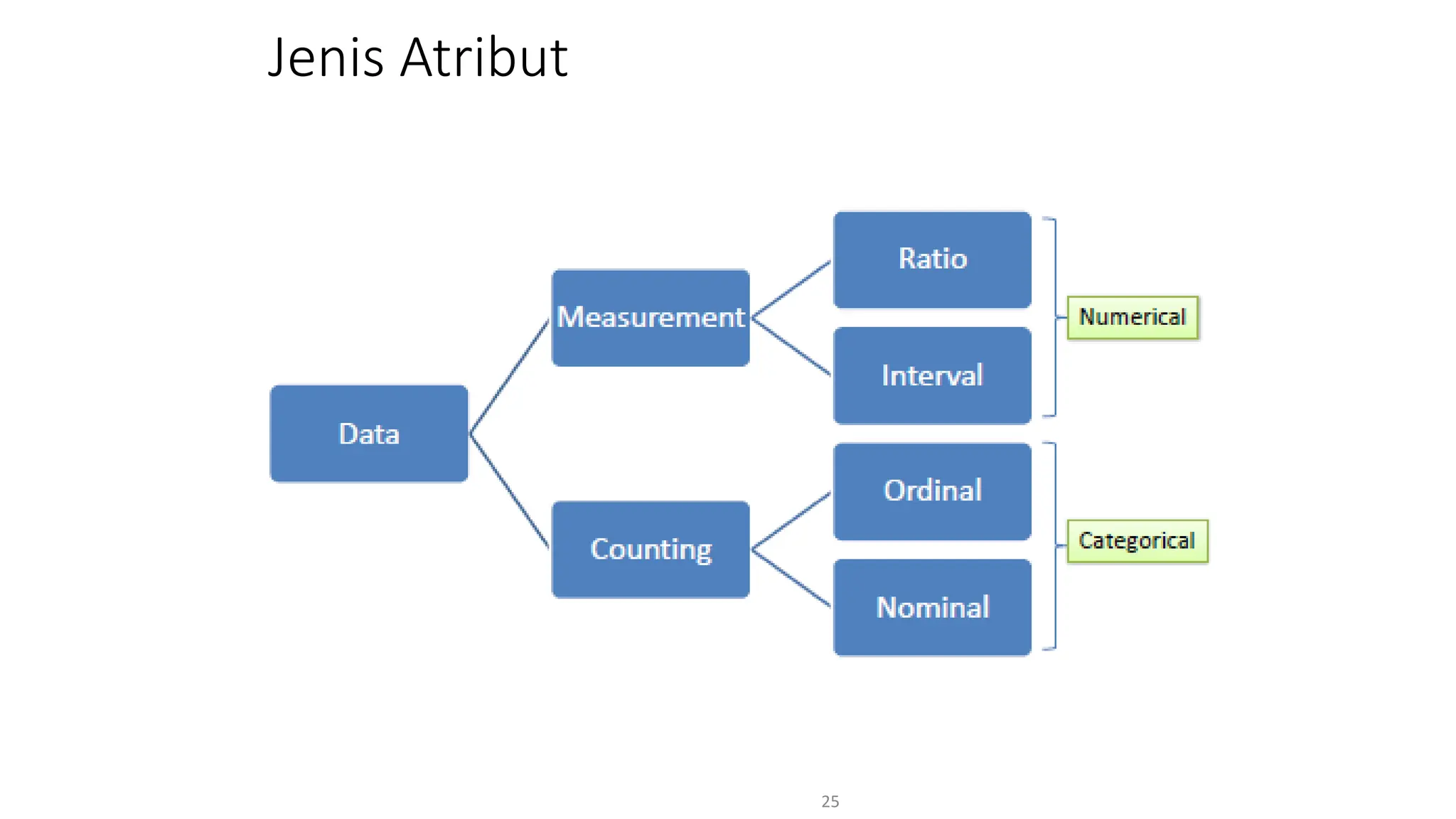
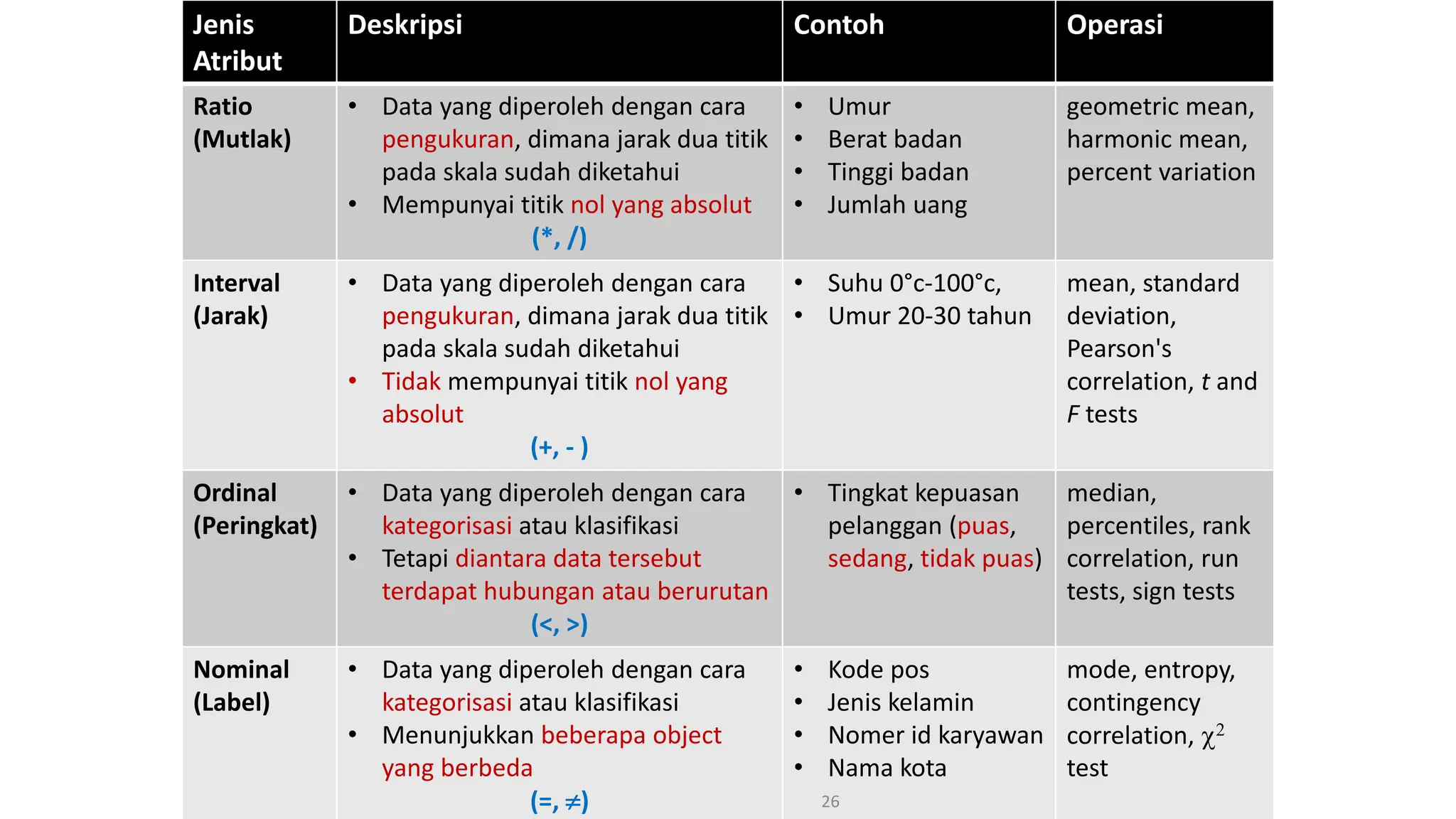
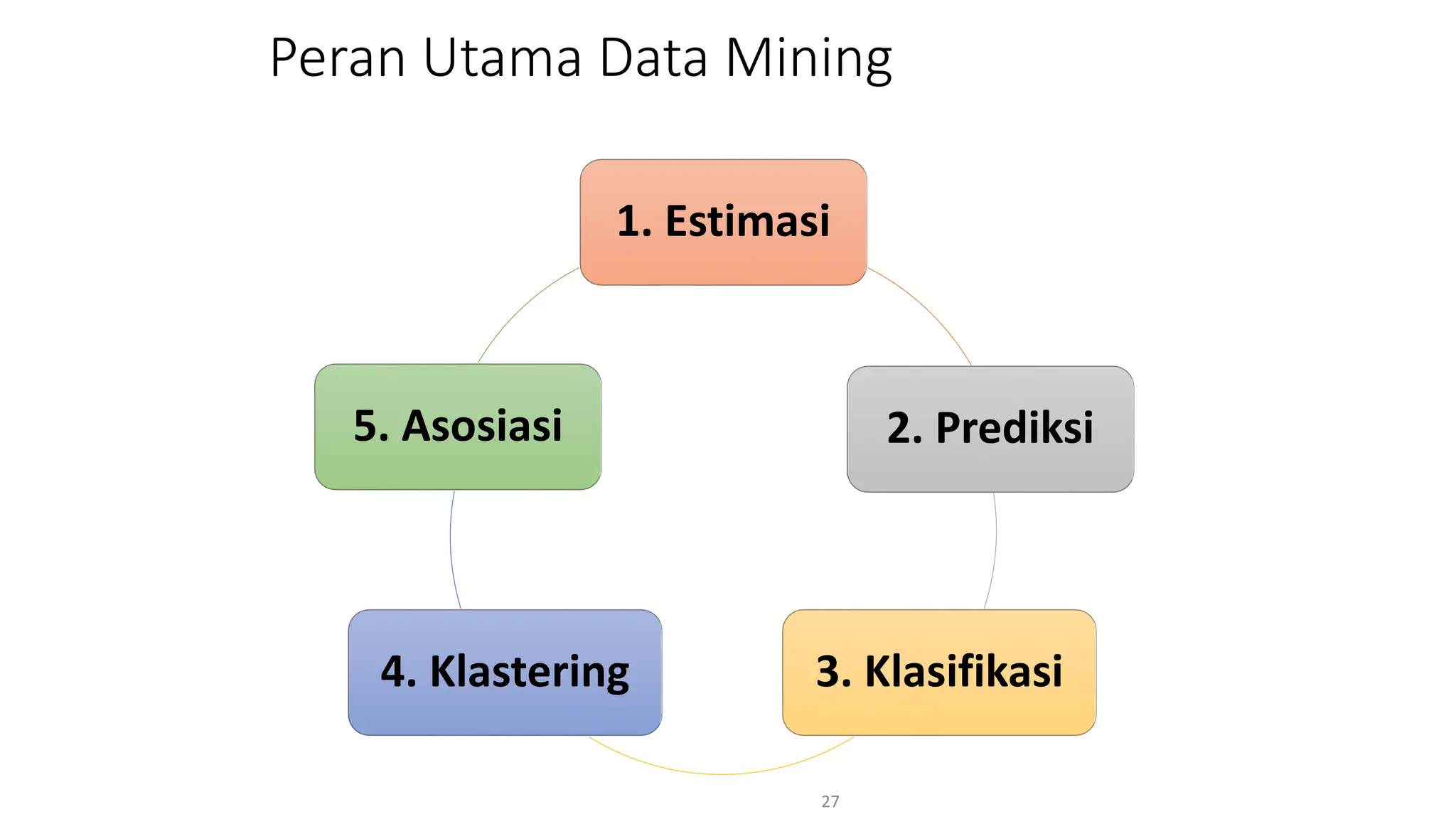
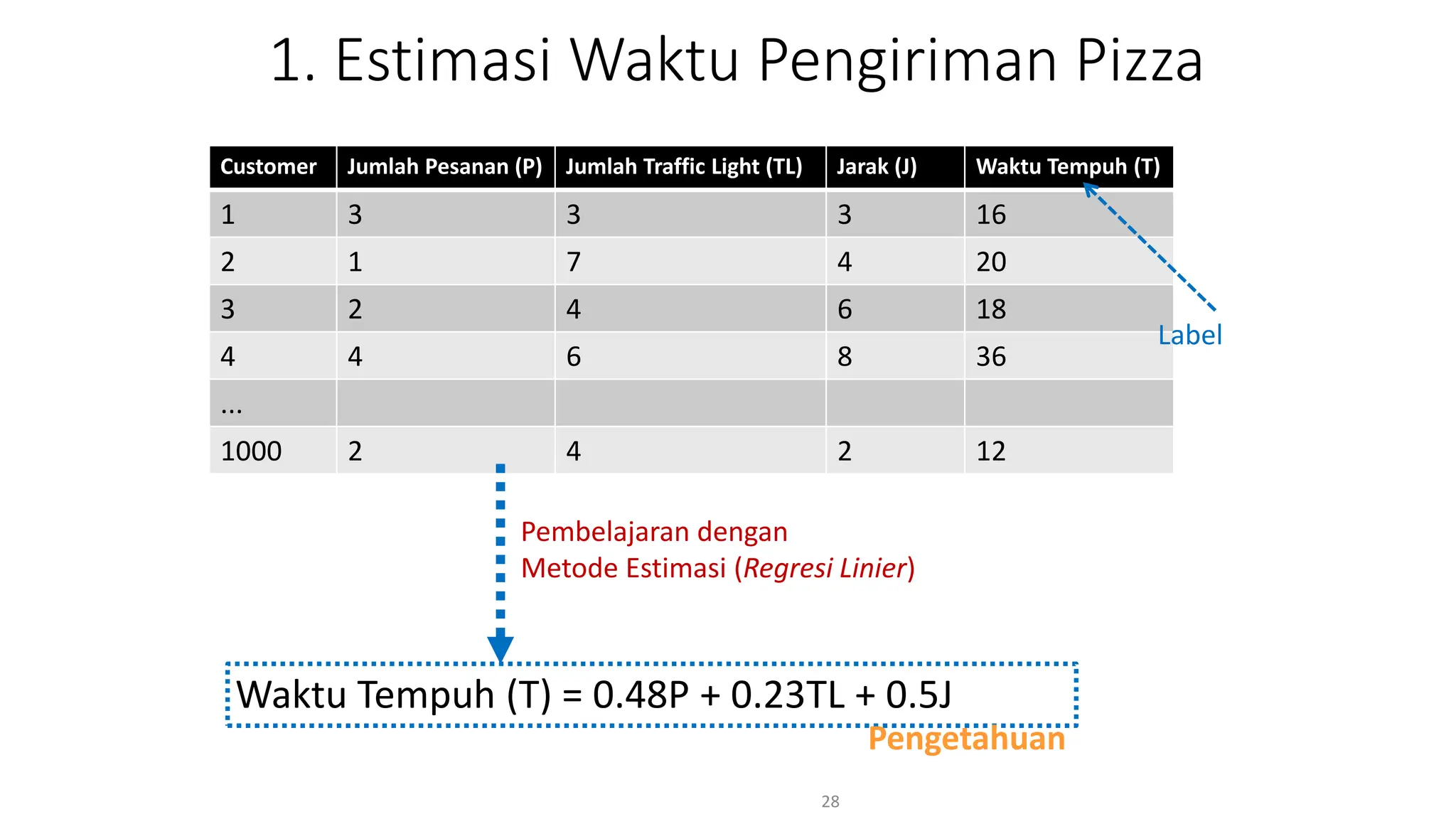
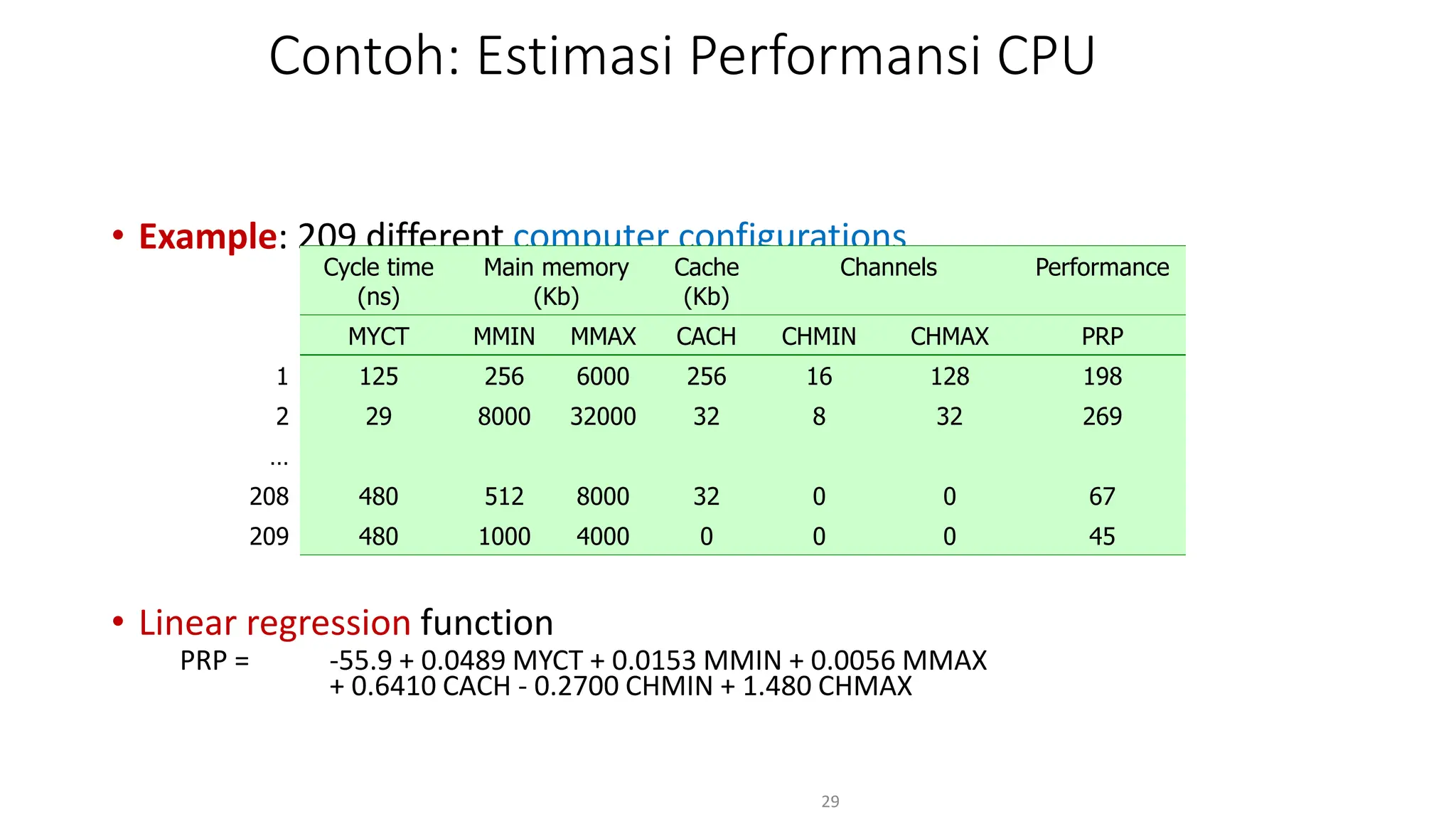
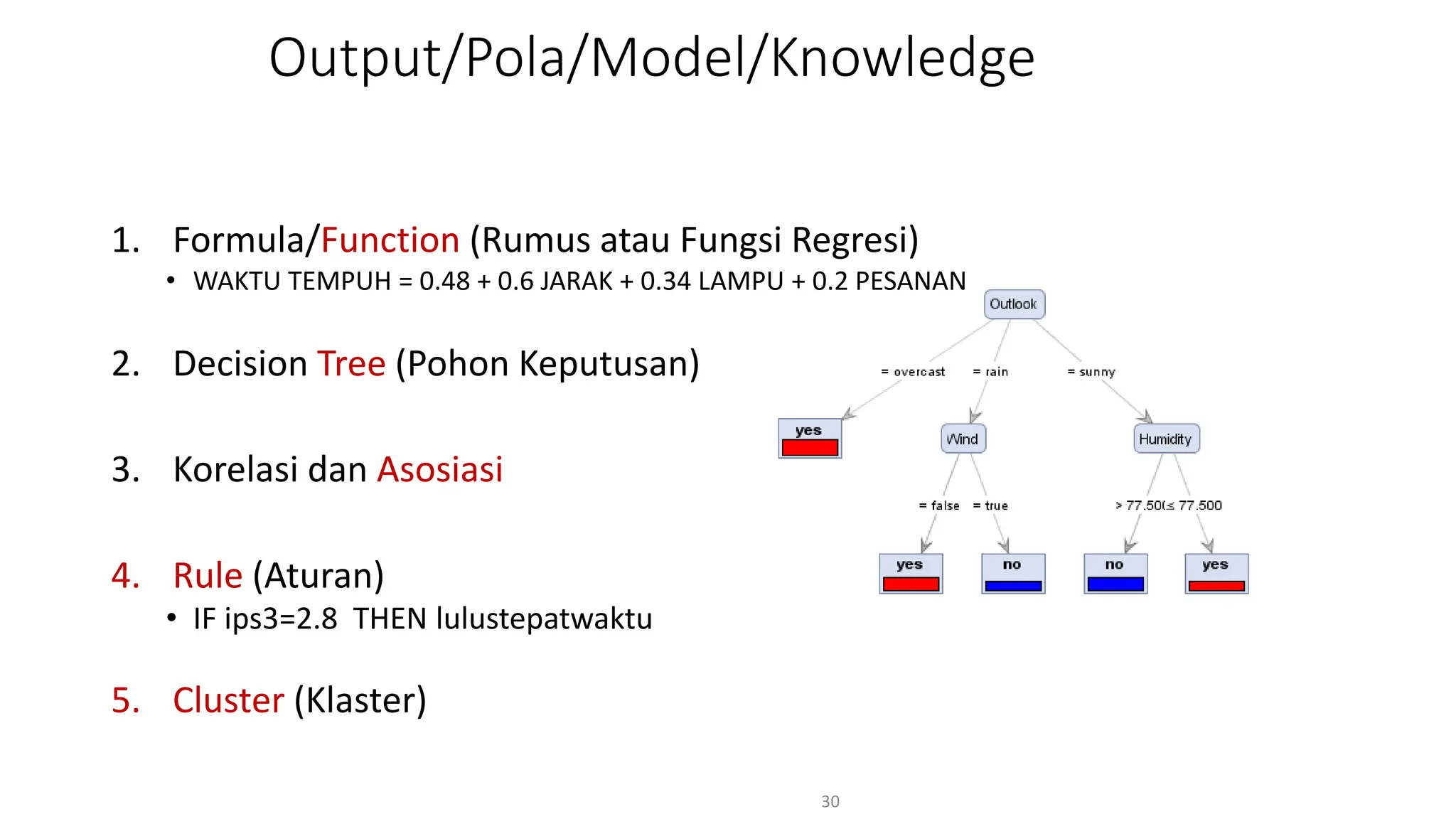

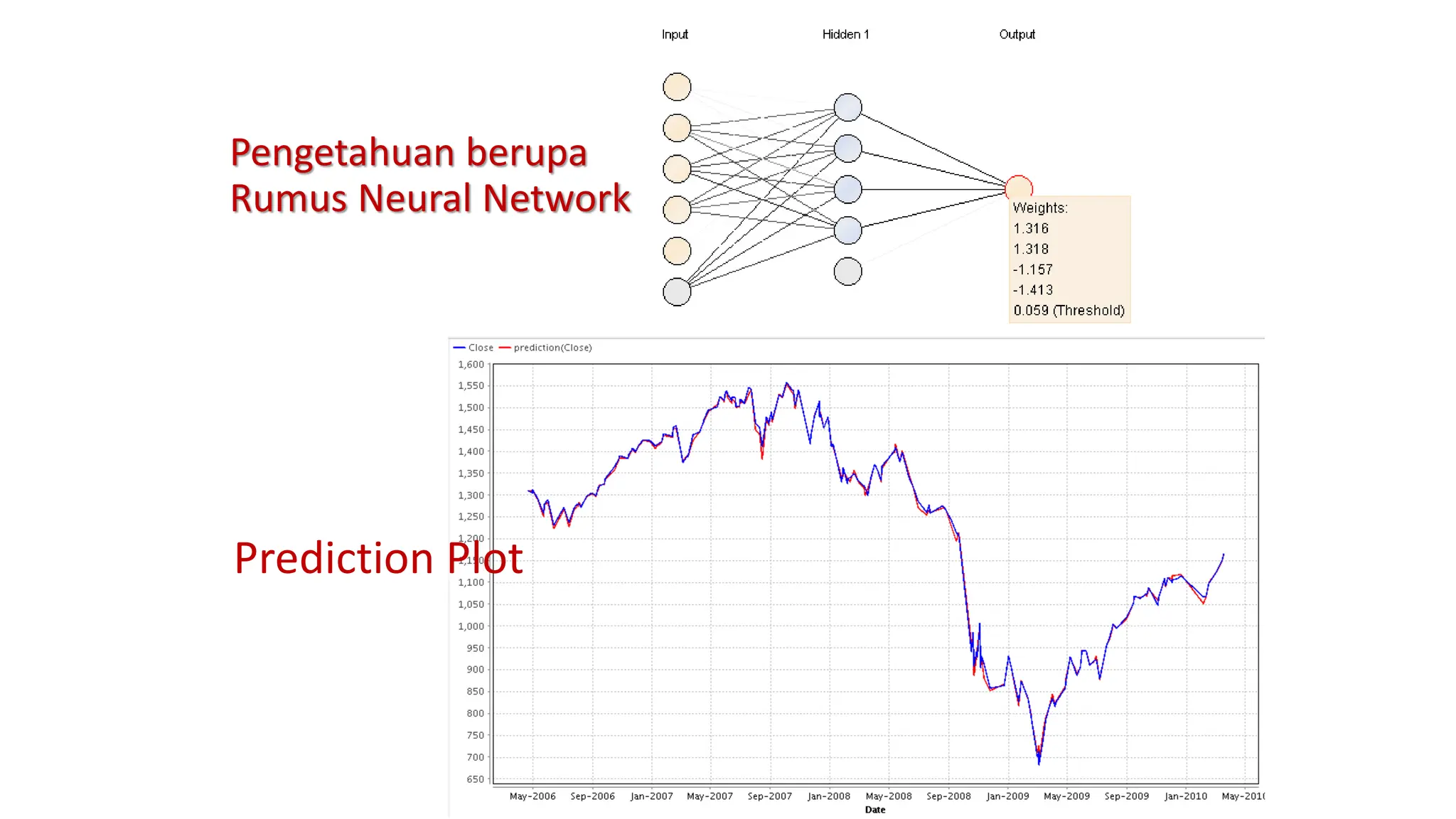
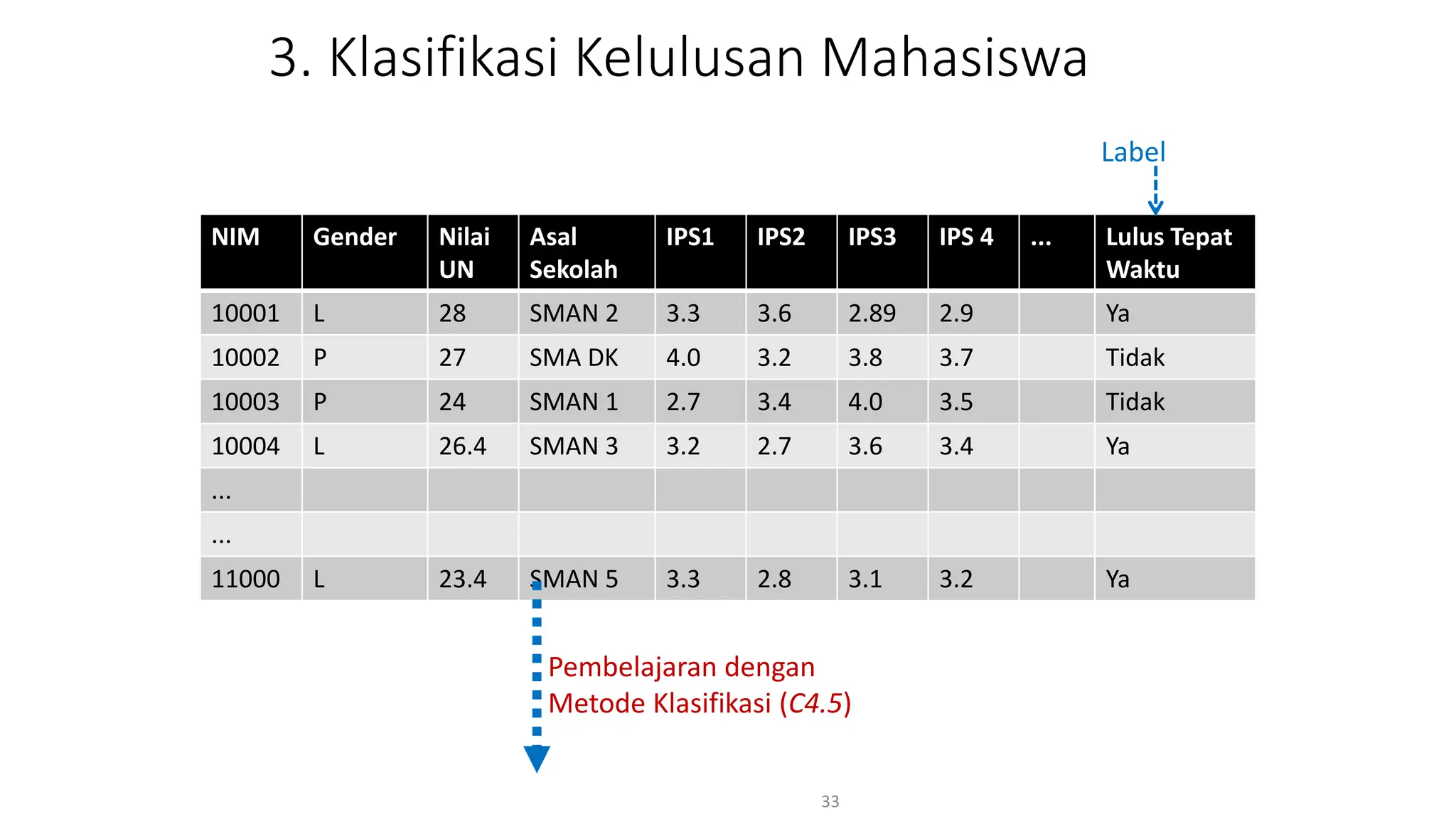
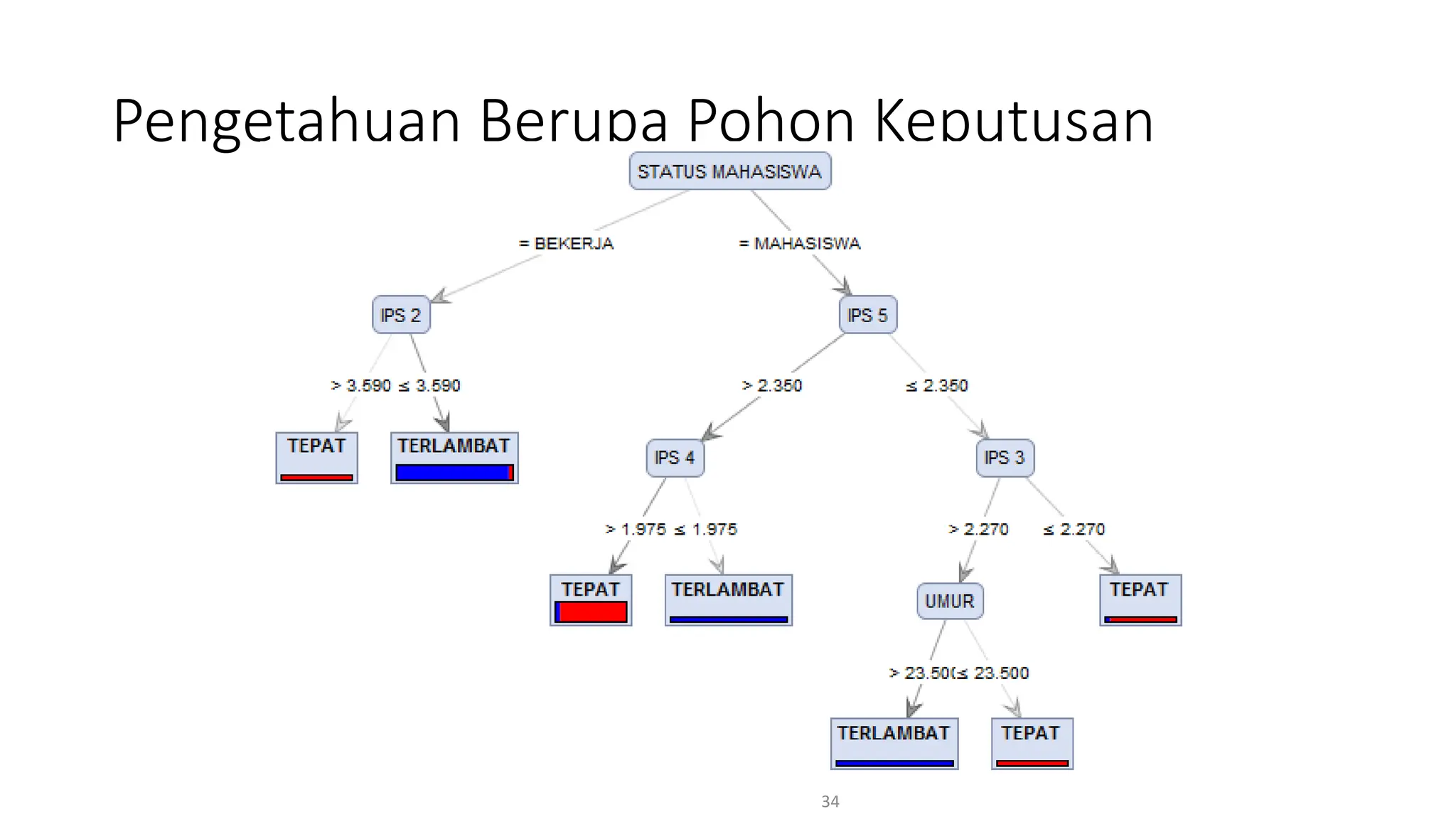
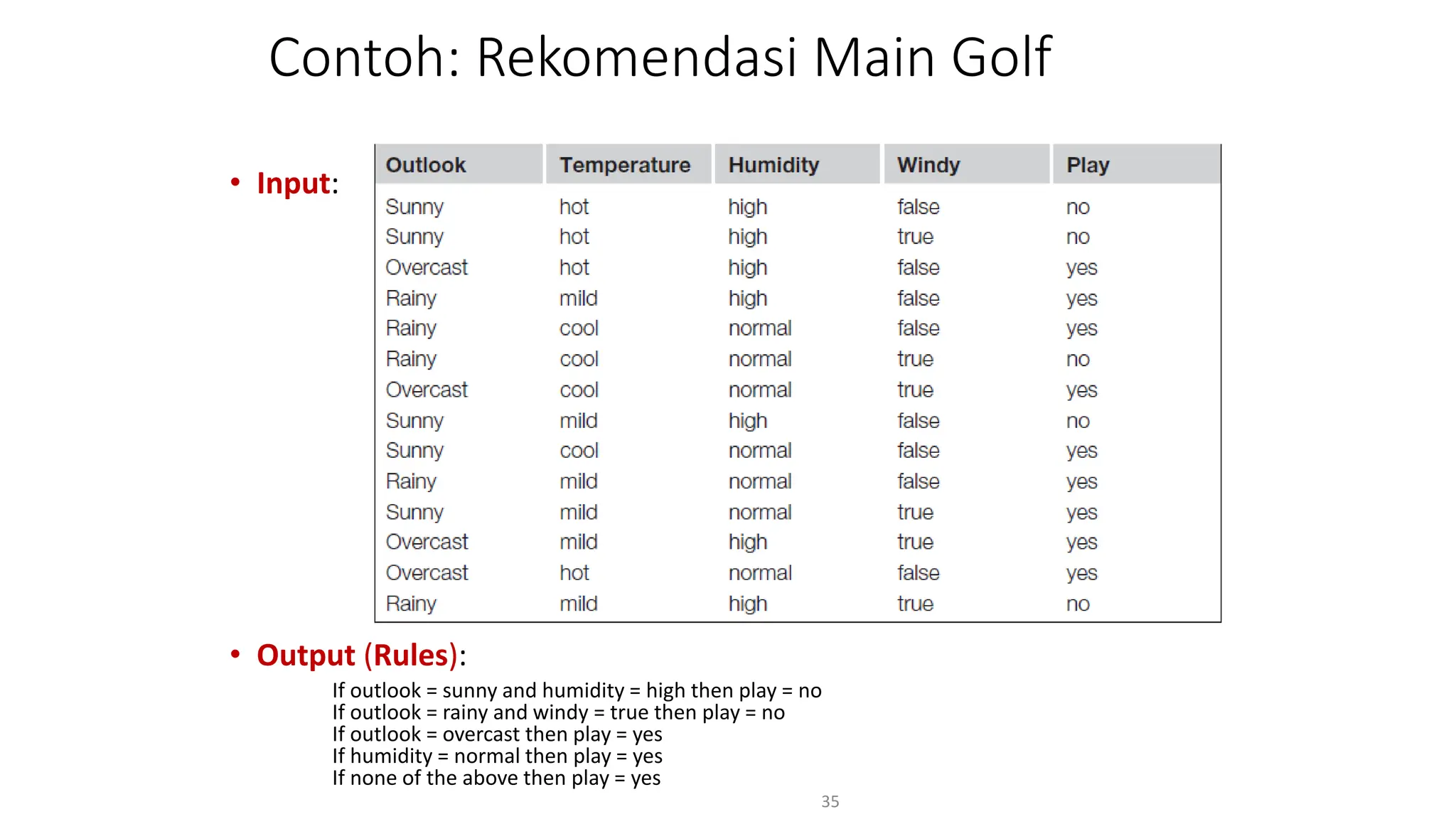
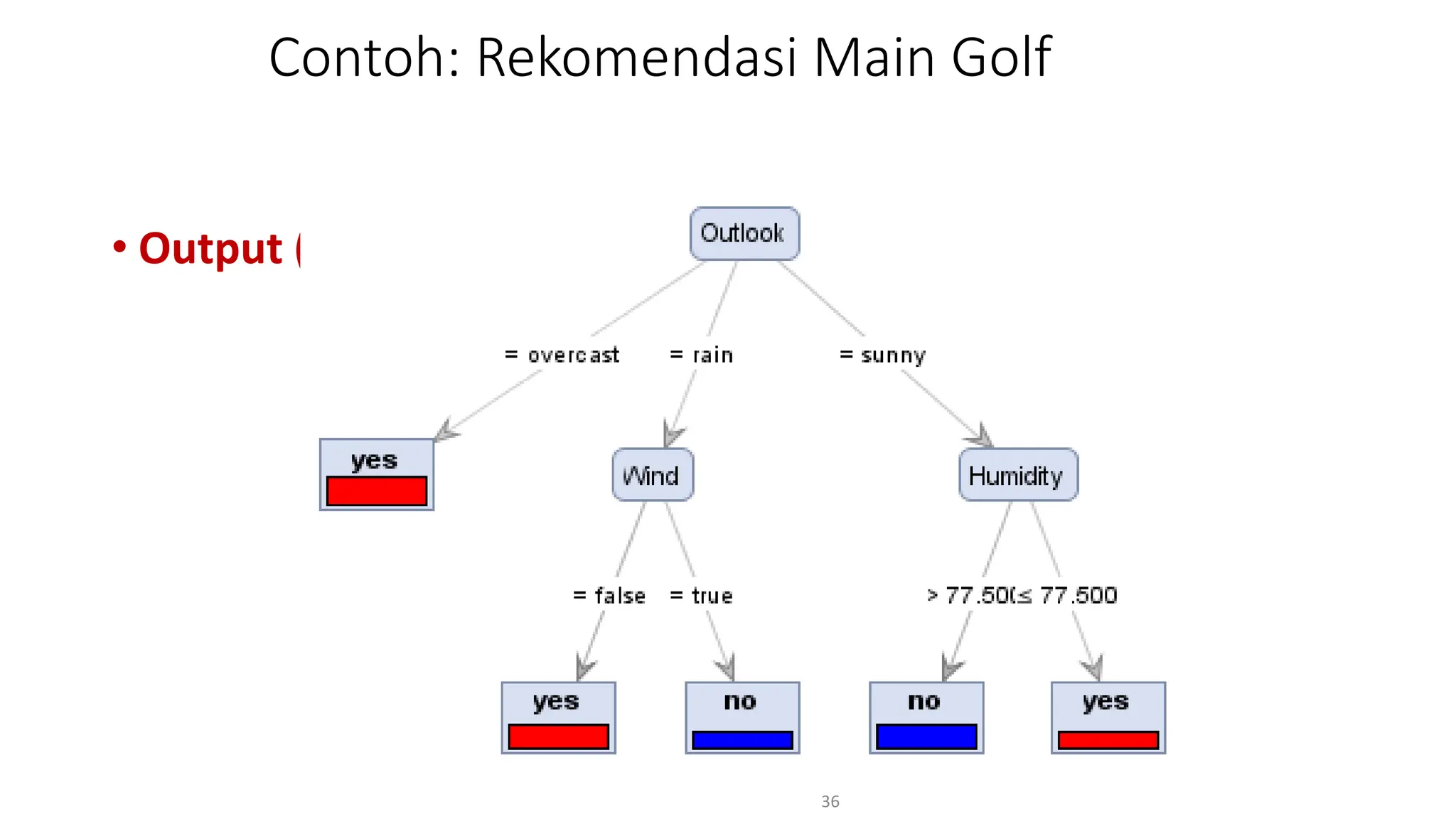
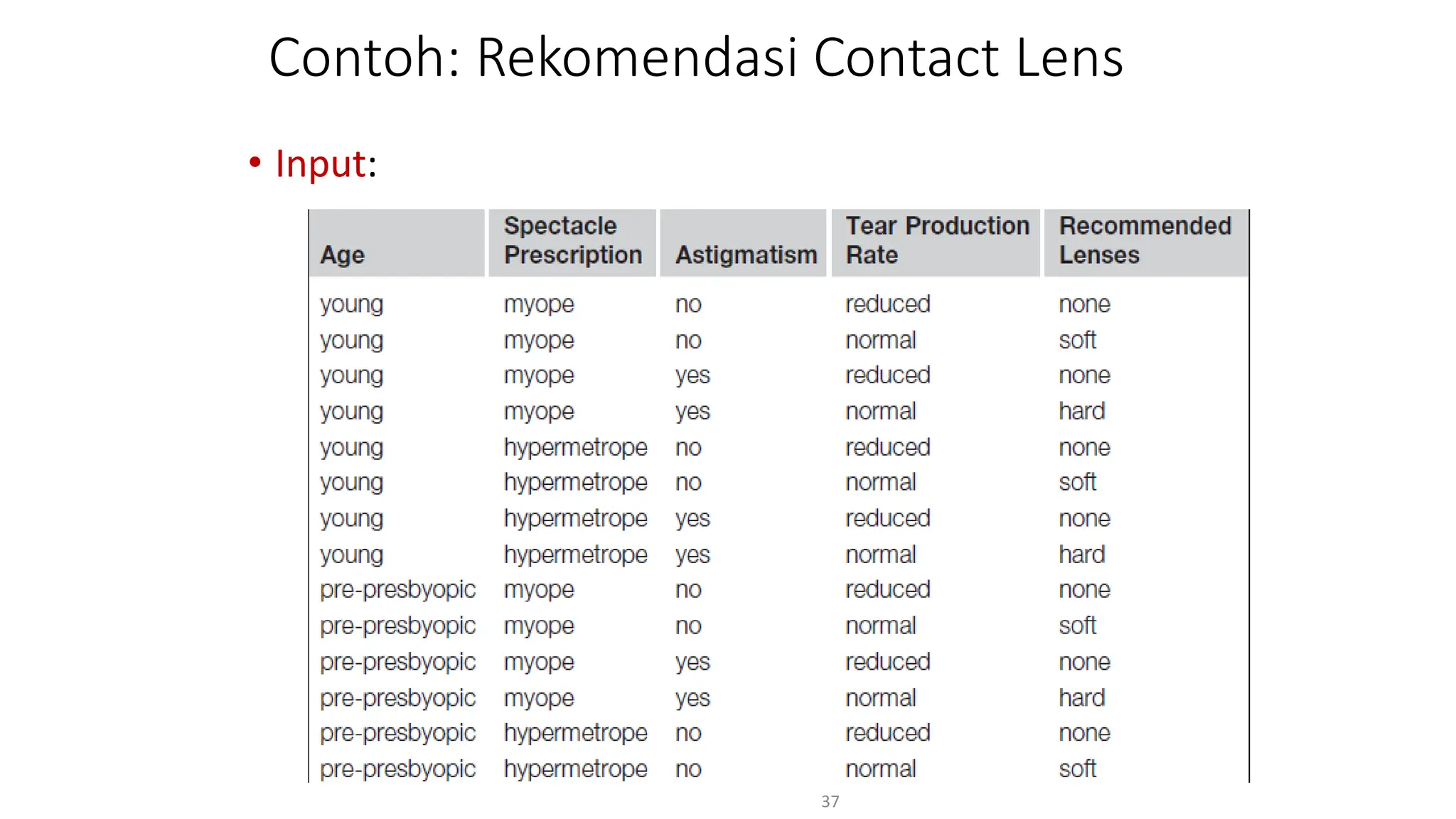
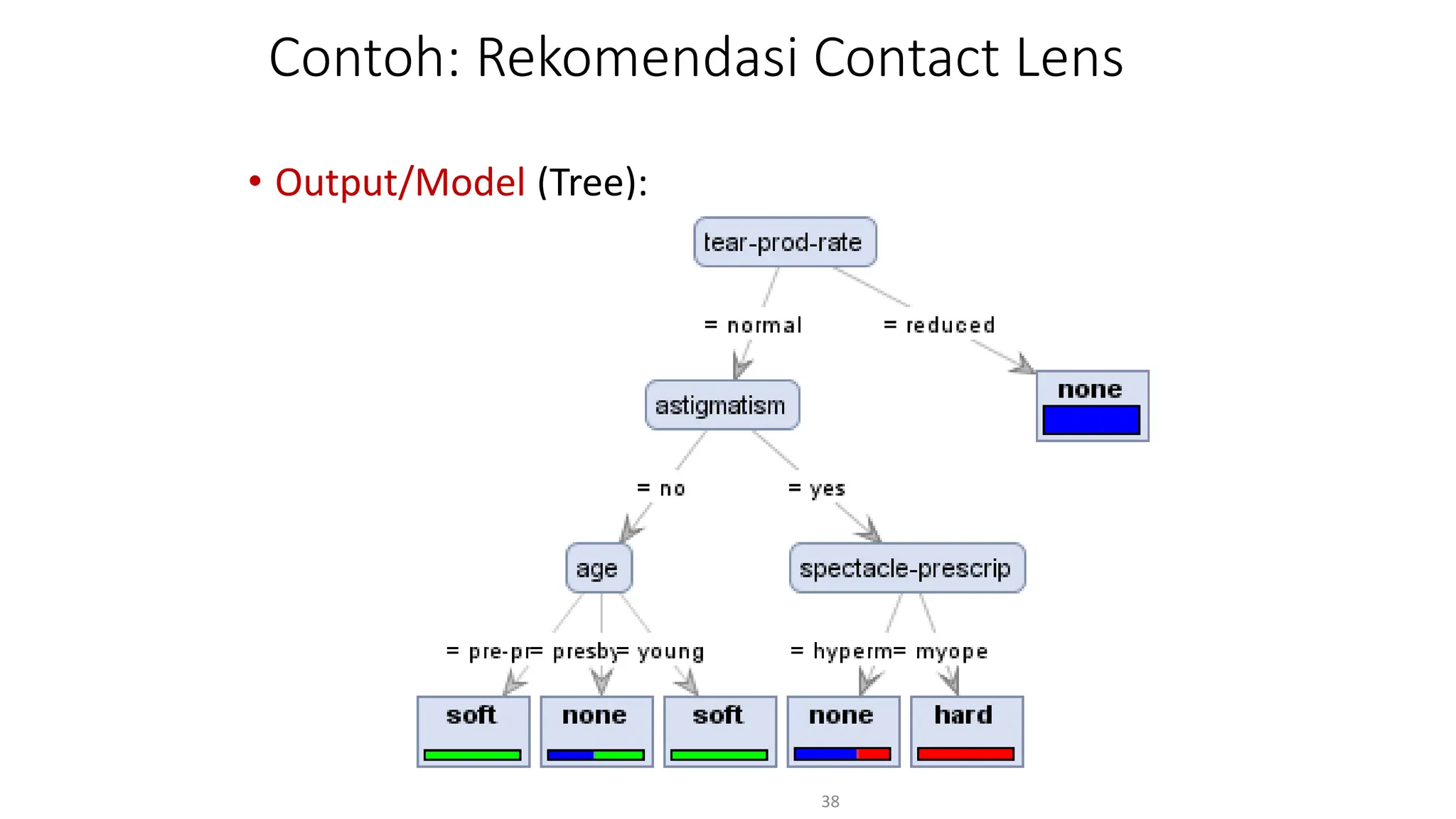
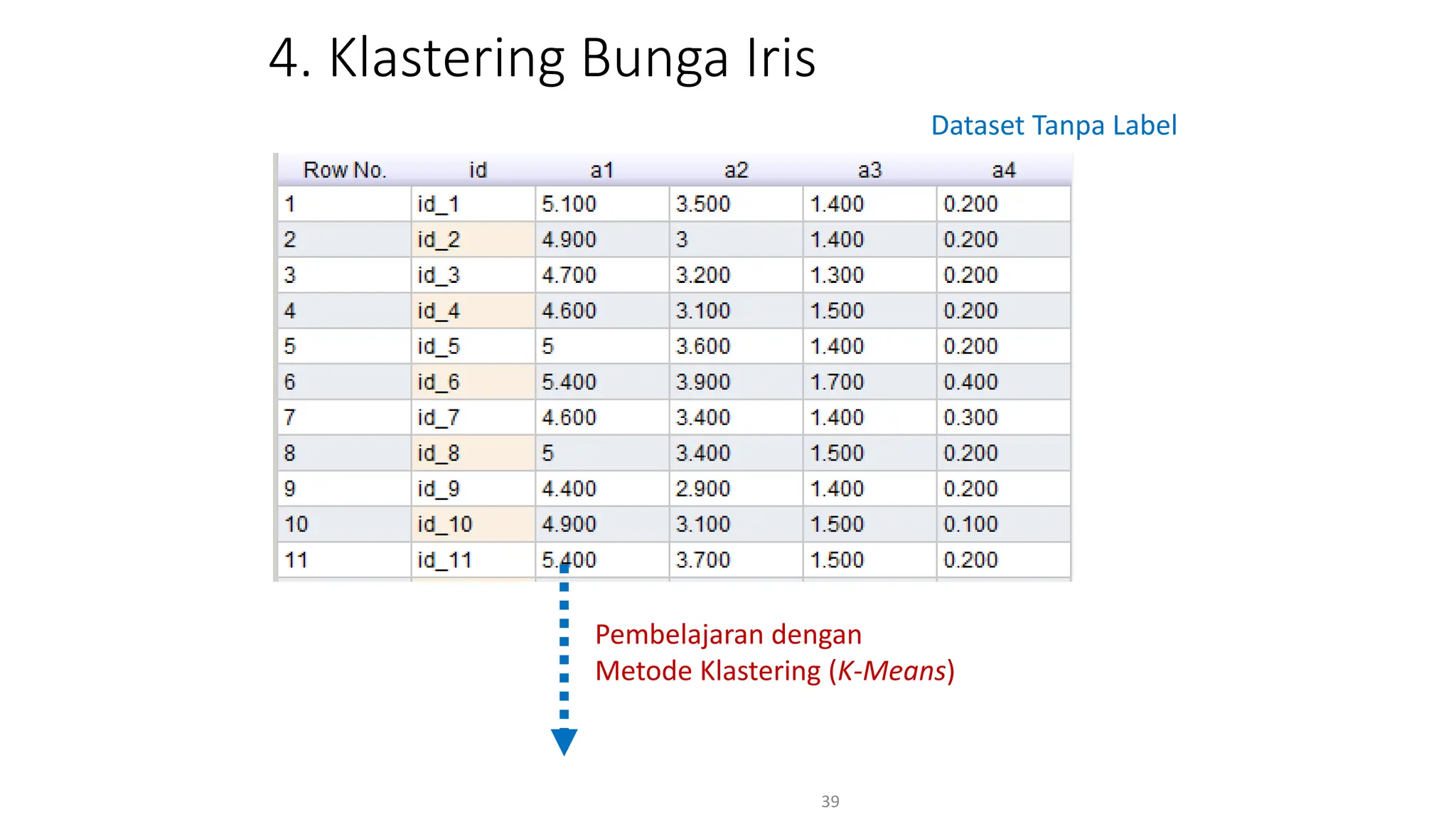
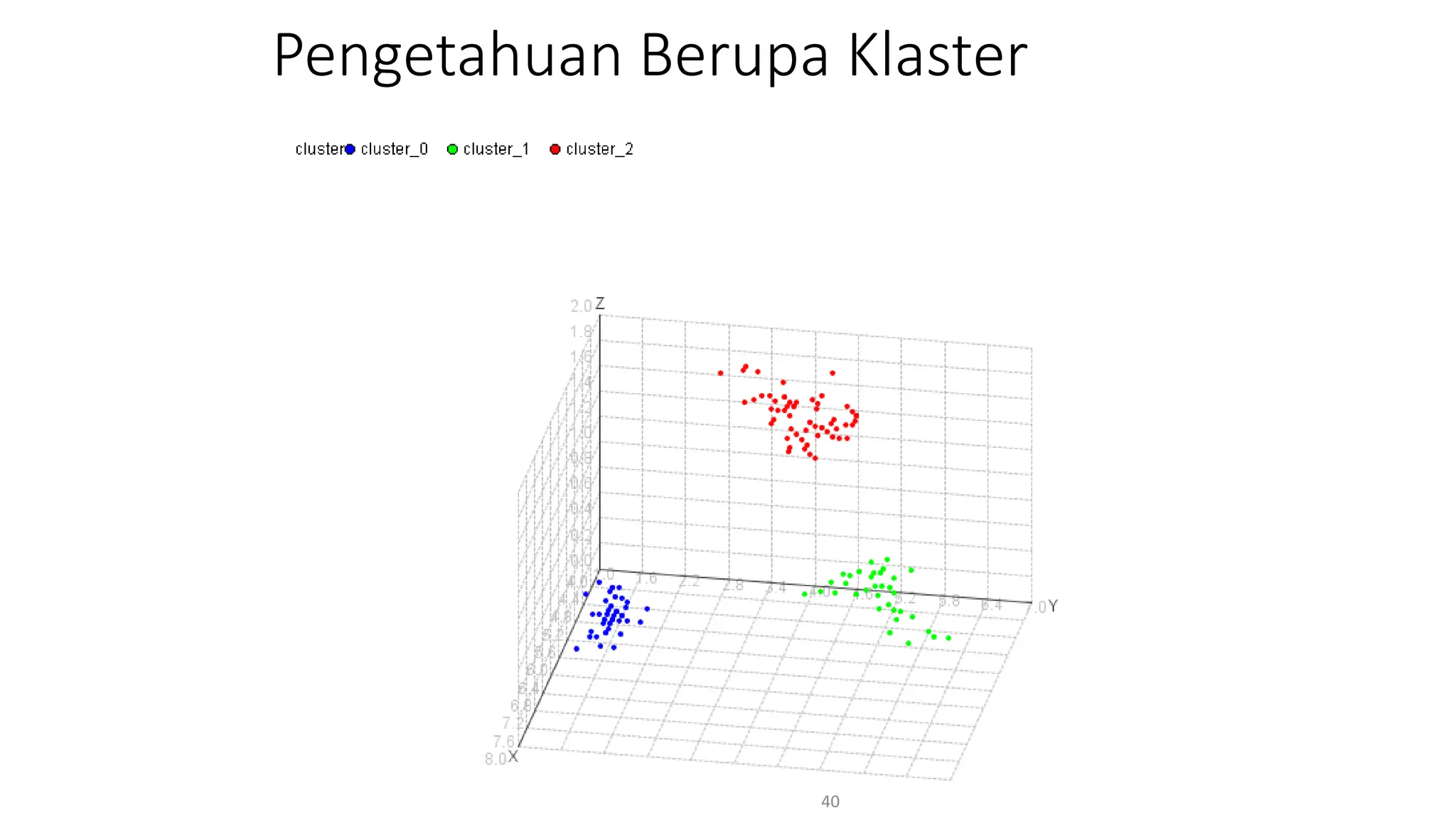
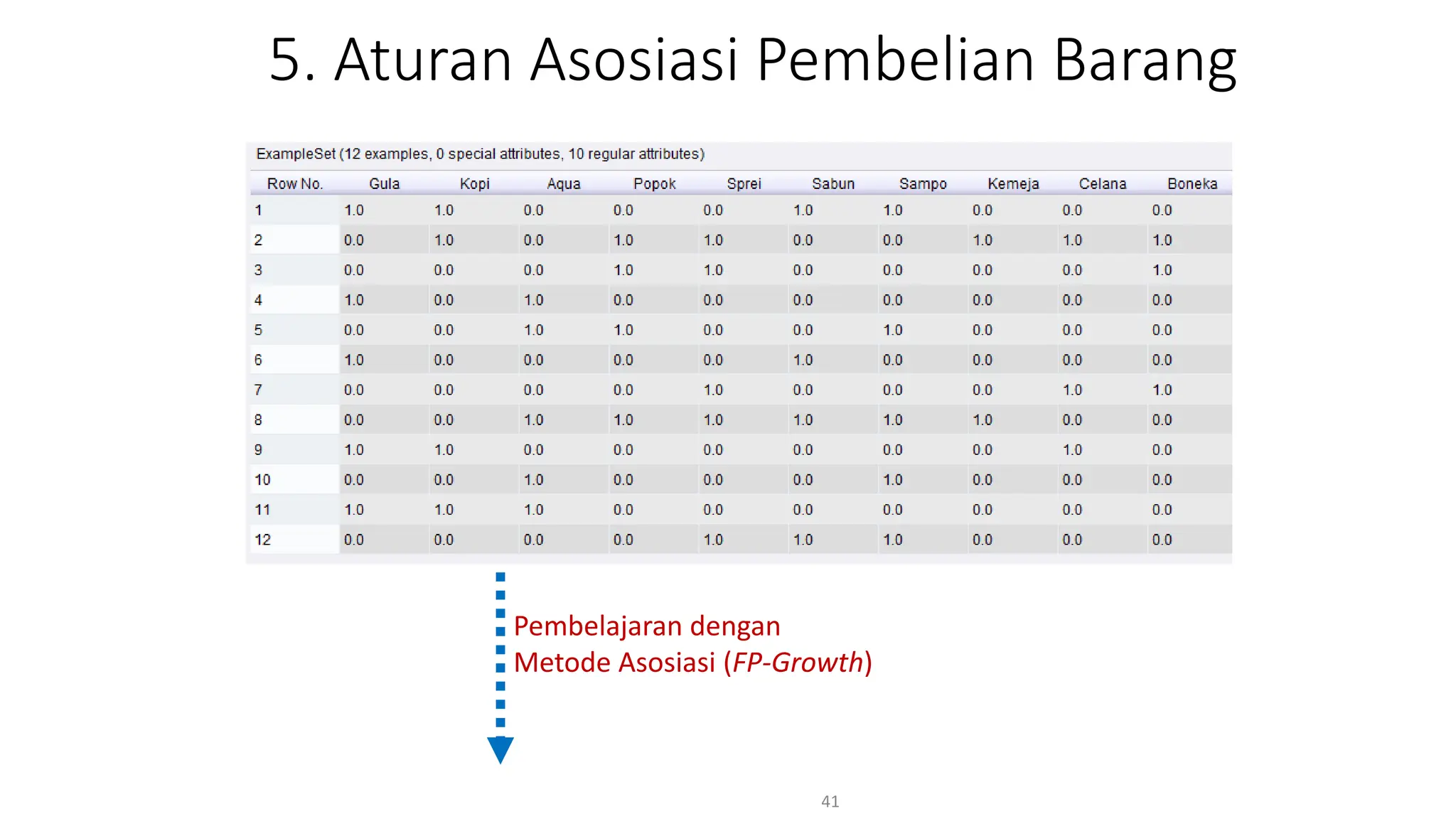
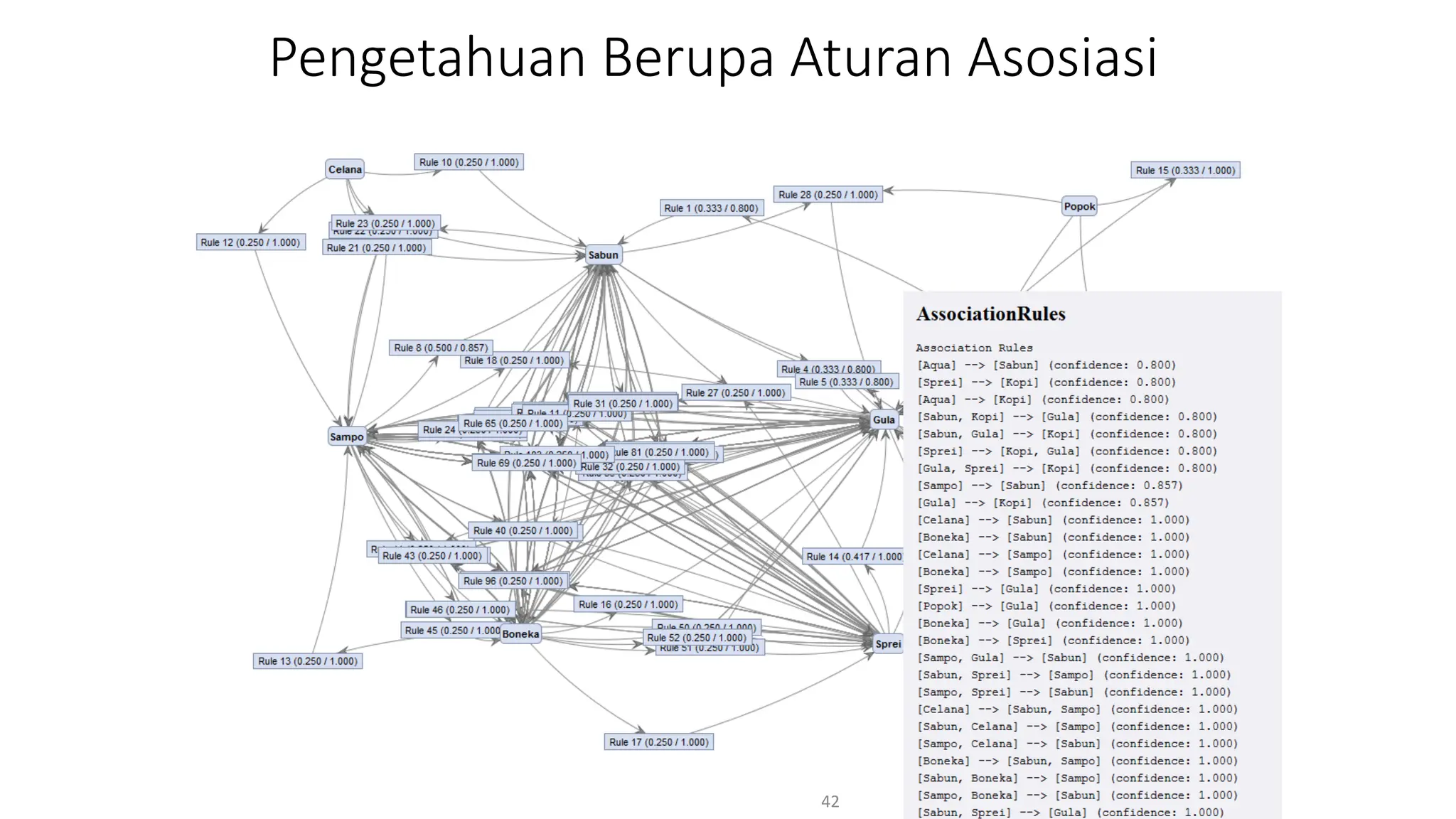









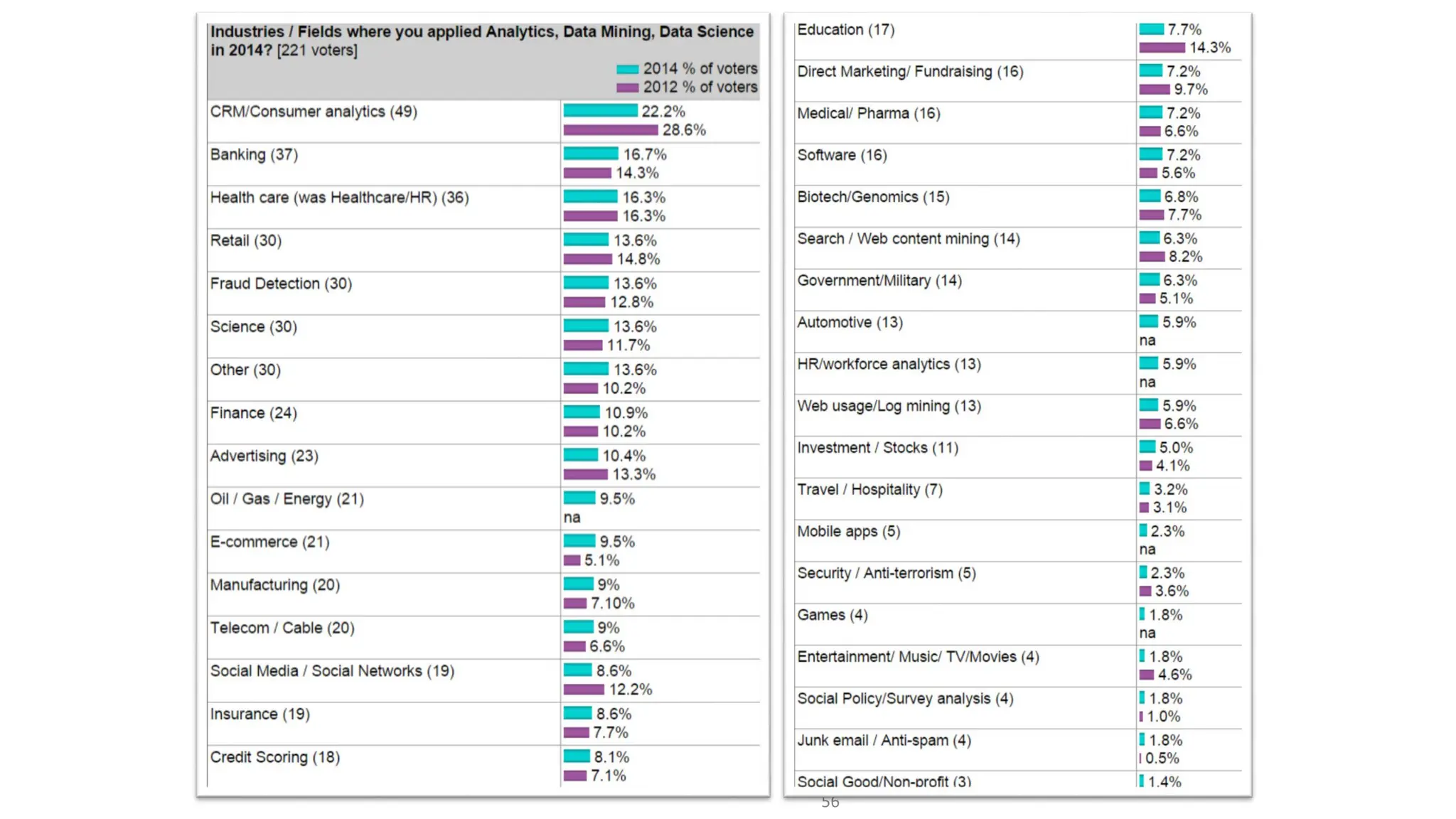





Dokumen ini menjelaskan tentang pengantar data mining, termasuk definisi, metode, dan penerapannya dalam berbagai bidang, serta istilah-istilah terkait seperti big data, machine learning, dan artificial intelligence. Data mining berfungsi untuk mengekstrak pola dan pengetahuan dari data besar yang dihasilkan oleh berbagai sumber, dengan fokus pada membantu manusia dalam memahami data tersebut. Selain itu, dokumen ini juga menyentuh evolusi ilmu pengetahuan menuju data science dan aplikasi praktis dari data mining dalam keputusan bisnis dan analisis data.















































