Downloaded 58 times
































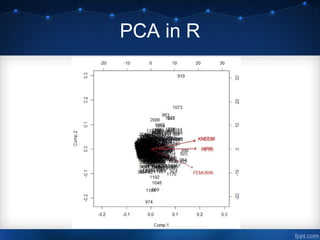


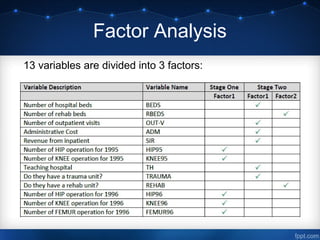



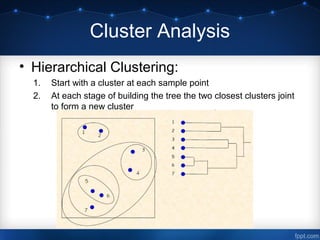





















This document discusses using data mining techniques to analyze hospital data and increase sales of orthopedic equipment. It analyzes data on U.S. hospitals from selected midwestern states to identify target hospital segments. Dimension reduction using factor and principal component analysis identifies key factors related to operations, size, and rehabilitation. Cluster analysis segments hospitals into groups using hierarchical and k-means clustering. Regression analysis identifies hospitals with high sales potential based on their current sales levels. The overall aim is to use data mining to select hospital market segments to focus sales efforts on for increasing orthopedic equipment sales.






















































![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Mijat Kustudic - Building Financial Intelligence with AI Agen...](https://cdn.slidesharecdn.com/ss_thumbnails/38y2lb5lse6wstegtvas-3-mijat-kustudic-building-financial-intelligence-with-ai-agents-260114111931-1a4783ce-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Ivica Milaric - The Future of Gaming and AI Tools.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/tijgzsmgse2kj2y5pzzp-5-ivica-milaric-the-future-of-gaming-x-ai-tools-260114111931-87c2b3ac-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)