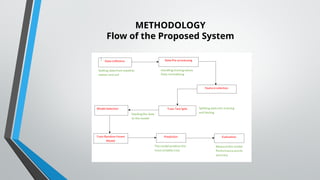
The document discusses the development of a crop recommendation system that utilizes neural networks to optimize agricultural decision-making based on soil and weather data. It addresses the challenges farmers face in selecting suitable crops, emphasizing the integration of AI to enhance productivity and sustainability in agriculture. The study demonstrates a machine learning methodology that achieved significant accuracy in predicting optimal crops, while also suggesting areas for future research to improve crop yield and resource management.