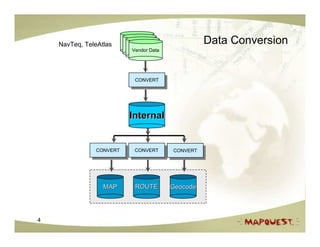
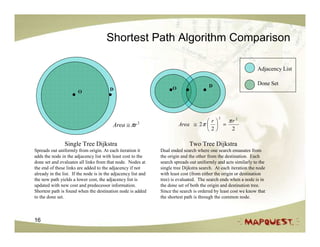
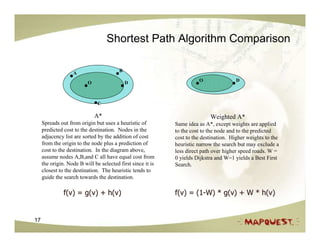
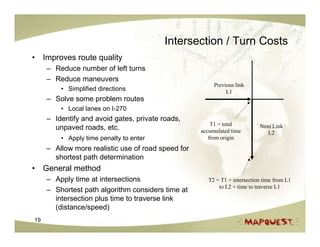
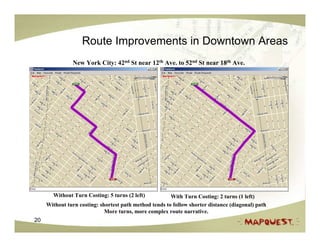
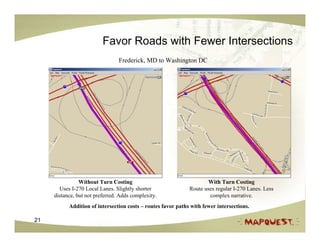
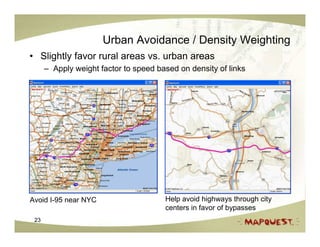
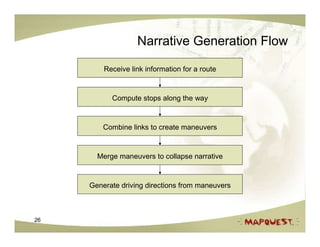
The document discusses geospatial search and routing technologies. It provides an overview of how MapQuest uses a combination of proprietary and open source technologies like NavTeq, TeleAtlas, and OpenStreetMap data to perform geocoding, routing, and geospatial searches. It describes the routing algorithms like Dijkstra's and A* that are used to find the optimal path between locations. It also discusses techniques for generating driving directions and narratives from route data and methods for testing routing quality and performance.