Download to read offline














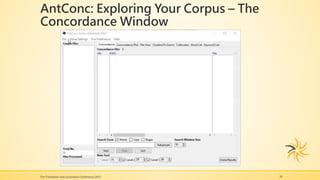
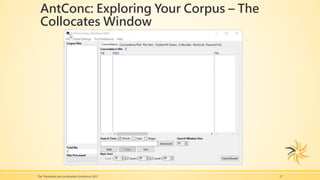
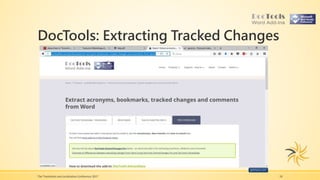


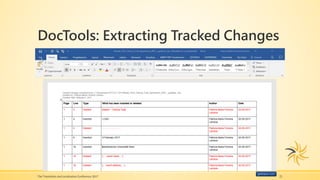





The presentation focuses on providing translators with valuable resources and tips for using corpora, tracking changes, and searching multiple PDF files effectively. It includes insights on using software like Bootcat, AntConc, and Doctools, along with techniques for building and utilizing online corpora. The speaker, Patricia M. Ferreira Larrieux, shares her extensive background in translation and localization, emphasizing the importance of these tools in specialized terminology extraction.
















































