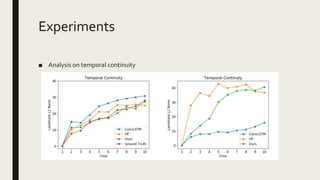
This document discusses controllable image-to-video translation for generating facial expression videos from a single neutral photo. It describes generating videos that smoothly transition from the neutral input photo to the peak expression state while preserving identity. The method trains models to jointly generate different expression types using adversarial and temporal continuity losses, as well as landmark prediction to maintain natural facial dynamics. Experiments analyze temporal smoothness and visualize generated expression videos.



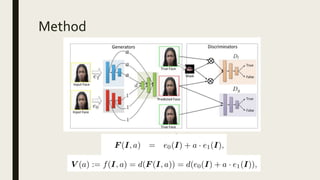
![Method
■ Problem formulation
■ Given an input image I ∈ RH×W×3 where H andW are respectively the height and
width of the image, our goal is to generate a sequence of video frames {V (a) := f(I,a);a
∈ [0,1]}, where f(I,a) denotes the model to be learned.
■ Properties:
– a=0, f(I,a)=I
– Smooth, f(I,a) and f(I,a+ Δa) should be visually similar when ∆a is small
– V (1) be the peak state of the expression](https://image.slidesharecdn.com/controllableimage-to-videotranslation-180822195843/85/Controllable-image-to-video-translation-4-320.jpg)








































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


















