Downloaded 10 times





























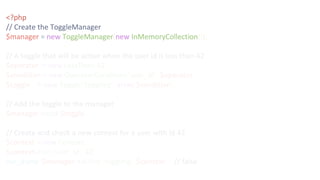
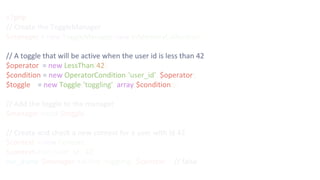
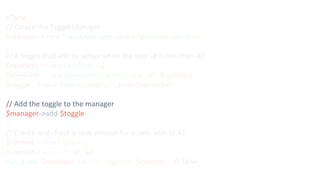
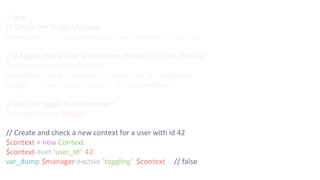

![$ curl -XPUT 127.0.0.1:8000/toggles/search_beta -d '{
"name" : "search_beta",
"status" : "conditionally-active",
"conditions" : [
{
"name" : "operator-condition",
"key" : "user_id",
"operator" : {
"name" : "in-set",
"values" : [42, 1337]
}
}
]
}'](https://image.slidesharecdn.com/phpnw16-161003062052/85/Continously-delivering-58-320.jpg)
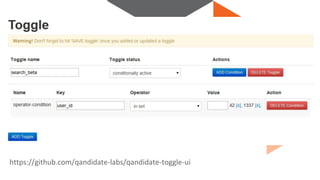

























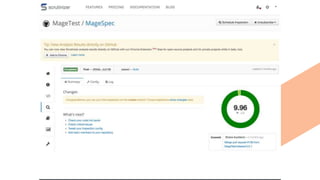
















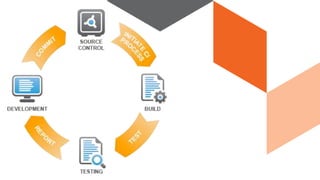
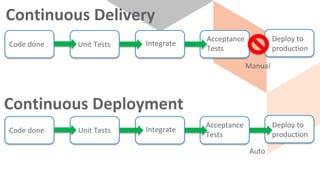
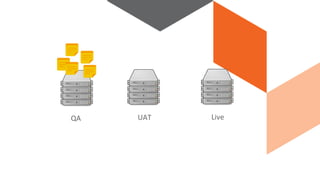
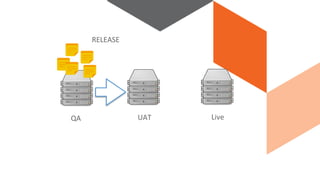
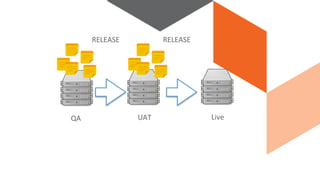
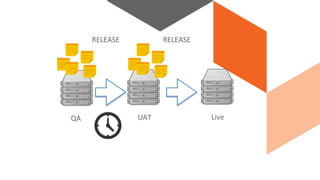
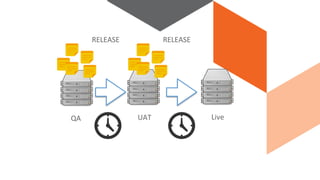
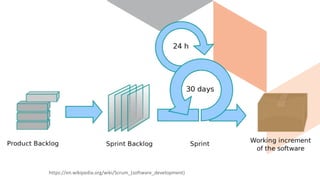
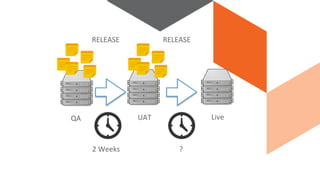
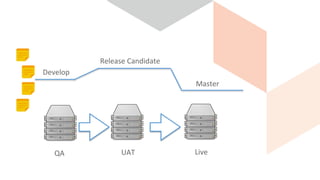
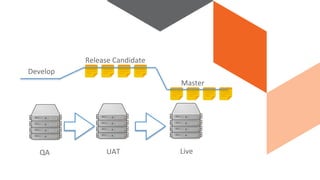
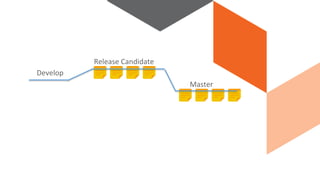
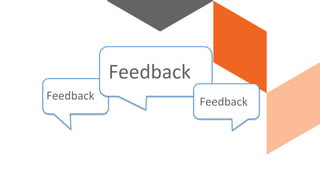
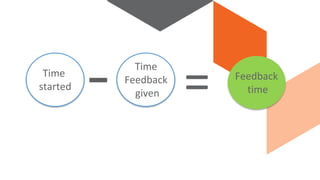
The document discusses continuous integration and delivery in software development, focusing on reducing integration problems and increasing release velocity. It covers the benefits of feature toggles, feedback loops, and proposed workflows for efficient development in Magento environments. Additionally, it emphasizes testing and deployment practices to ensure high-quality software delivery.





















































































