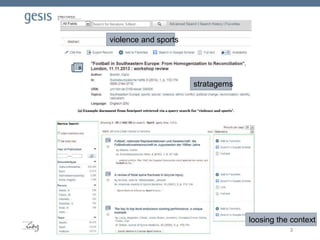
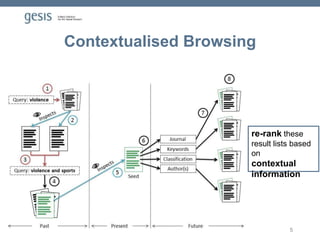
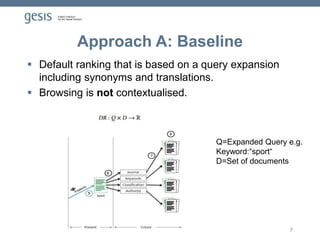
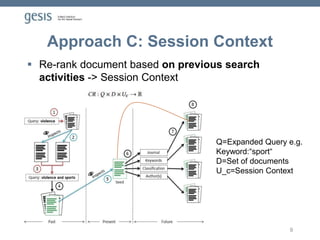
Download to read offline


![Introduction
Exploratory Search (especially
browsing/stratagem search) is one of the most
frequent search activities in DL [1-3]
DL offer high quality structured metadata that can
be utilised for browsing. E.g.:
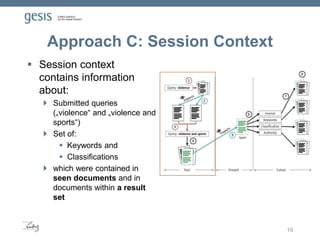
Keywords
Classifications
Journals
System support on this level rather low. E.g.:
Browsing DL by keywords acts as a simple
Boolean filter
2](https://image.slidesharecdn.com/jcdl18carevic-180604220901/85/Contextualised-Browsing-in-a-Digital-Library-s-Living-Lab-2-320.jpg)




![Methodology
Measure the effectiveness of our contextualised
ranking features on two levels:
Mean First Relevant (MFR): The mean of the first
clicked document in a result set [4]
Usefulness [5]
Local usefulness: the immediate relevance of a
document
Global usefulness: the total number of implicit
relevance signals for the entire session starting
from stratagem usage.
12](https://image.slidesharecdn.com/jcdl18carevic-180604220901/85/Contextualised-Browsing-in-a-Digital-Library-s-Living-Lab-12-320.jpg)








![References
[1] Zeljko Carevic, Maria Lusky, Wilko van Hoek, and Philipp
Mayr. 2017. Investigating exploratory search activities based on
the stratagem level in digital libraries. International Journal on
Digital Libraries (2017), 1–21.
[2] Zeljko Carevic and Philipp Mayr. 2016. Survey on High-level
Search Activities based on the Stratagem Level in Digital
Libraries. In Proceedings of TPDL 2016, Springer, 54–66
[3] Philipp Mayr and Ameni Kacem. 2017. A Complete Year of
User Retrieval Sessions in a Social Sciences Academic Search
Engine. In Proceedings of TPDL 2017, Springer, 560–565
[4] Norbert Fuhr. 2017. Some Common Mistakes In IR
Evaluation, And How They Can Be Avoided. Technical Report.
University of Duisburg-Essen, Germany
[5] Daniel Hienert and Peter Mutschke. 2016. A usefulness-
based approach for measuring the local and global effect of IIR
services. In Proceedings of the 2016 ACM Conference on
Human Information Interaction and Retrieval. ACM, 153–162
21](https://image.slidesharecdn.com/jcdl18carevic-180604220901/85/Contextualised-Browsing-in-a-Digital-Library-s-Living-Lab-21-320.jpg)

The document discusses the implementation of contextualized browsing features in a digital library to improve exploratory search effectiveness. It evaluates two contextual re-ranking approaches—document similarity and session context—compared to a non-contextualized baseline, revealing that both contextual methods significantly enhance search results. Results indicate that document similarity performs best, especially for short sessions, and that contextualization affects the usefulness of search results.
























































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)









