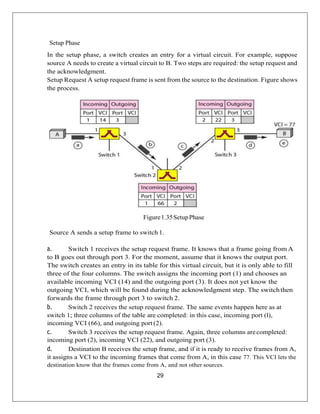
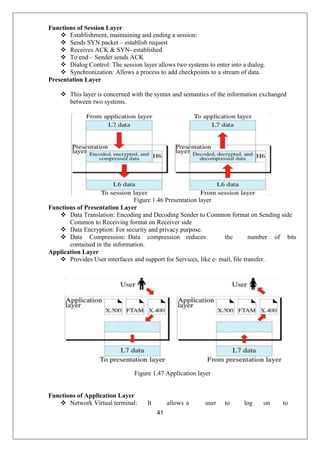
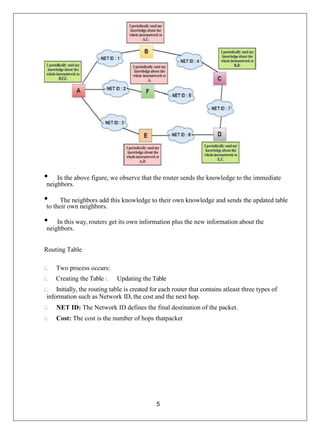
The document provides a comprehensive overview of data communication and computer networks, defining key concepts such as nodes, protocols, and types of connections. It elaborates on the characteristics of data communication systems, including delivery, accuracy, timeliness, and jitter, and describes various network topologies like mesh, star, bus, and ring, along with their advantages and disadvantages. Different types of networks based on size, including PAN, LAN, MAN, and WAN, are also discussed, highlighting their distinct features and use cases.