Download as PDF, PPTX




![Local models: pros and cons
• Examples of local models are locally weighted regression and
nearest neighbours
• We will consider here a Lazy Learning algorithm [2, 5, 4]
published in previous works.
• PRO: fast and easy local linear learning procedures for
parametric identification and validation.
• CON:
• the dataset of observed input/output data must always be kept
in memory.
• Each prediction requires a repetition of the learning procedure.
Combining Lazy Learning, Racing and Subsamplingfor Effective Feature Selection – p. 6/2](https://image.slidesharecdn.com/coimbra-160524080154/85/Combining-Lazy-Learning-Racing-and-Subsampling-for-Effective-Feature-Selection-13-320.jpg)


![Feature selection
• In recent years many applications of data mining (text mining,
bioinformatics, sensor networks) deal with a very large number n
of features (e.g. tens or hundreds of thousands of variables) and
often comparably few samples.
• In these cases, it is common practice to adopt feature selection
algorithms [7] to improve the generalization accuracy.
• Several techniques exist for feature selection: we focus here on
wrapper search techniques.
• Wrapper methods assess subsets of variables according to their
usefulness to a given learning machine. These methods conducts
a search for a good subset using the learning algorithm itself as
part of the evaluation function. The problem boils down to a
problem of stochastic state space search.
• Well-known example of greedy wrapper search is forward
selection. Combining Lazy Learning, Racing and Subsamplingfor Effective Feature Selection – p. 9/2](https://image.slidesharecdn.com/coimbra-160524080154/85/Combining-Lazy-Learning-Racing-and-Subsampling-for-Effective-Feature-Selection-16-320.jpg)


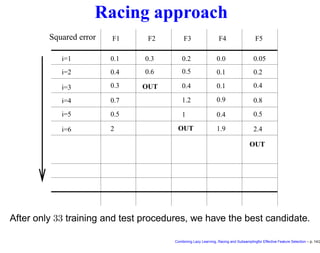
![The racing idea
• Suppose that we have F feature set candidates, N training
samples and that the assessment is perfomed by leave-one-out.
• The conventional approach is to to test all the F models on all the
N samples and eventually choose the best.
• The racing idea [8] is to test each feature set on one point at the
time.
• After only a small number of points, by using statistical tests, we
can detect that some feature sets are significantly worse than
others.
• We can discard them and keep focusing on the others.
Combining Lazy Learning, Racing and Subsamplingfor Effective Feature Selection – p. 12/2](https://image.slidesharecdn.com/coimbra-160524080154/85/Combining-Lazy-Learning-Racing-and-Subsampling-for-Effective-Feature-Selection-19-320.jpg)



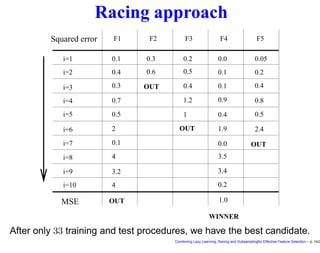
![F-racing for feature selection
• We propose a nonparametric multiple test, the Friedman test [6],
to compare different configurations of input variables and to select
the ones to be eliminated from the race.
• The use of the Friedman test for racing was proposed first by one
of the authors in the context of a technique for comparing
metaheuristics for combinatorial optimization problems [3]. This is
the first time that the technique is used in a feature selection
setting.
• The main merit of this nonparametric approach is that it does not
require to formulate hypotheses on the distribution of the
observations.
• The idea of F-racing techniques consists in using blocking and
paired multiple test to compare different models in similar conditions
and discard as soon as possible the worst ones.
Combining Lazy Learning, Racing and Subsamplingfor Effective Feature Selection – p. 15/2](https://image.slidesharecdn.com/coimbra-160524080154/85/Combining-Lazy-Learning-Racing-and-Subsampling-for-Effective-Feature-Selection-25-320.jpg)




![Software
• MATLAB toolbox on Lazy Learning [1].
• R contributed packages:
• lazy package.
• racing package.
• Web page: http://iridia.ulb.ac.be/~lazy.
• About 5000 accesses since October 2002.
Combining Lazy Learning, Racing and Subsamplingfor Effective Feature Selection – p. 21/2](https://image.slidesharecdn.com/coimbra-160524080154/85/Combining-Lazy-Learning-Racing-and-Subsampling-for-Effective-Feature-Selection-31-320.jpg)



![References
[1] M. Birattari and G. Bontempi. The lazy learning toolbox, for
use with matlab. Technical Report TR/IRIDIA/99-7, IRIDIA-
ULB, Brussels, Belgium, 1999.
[2] M. Birattari, G. Bontempi, and H. Bersini. Lazy learn-
ing meets the recursive least-squares algorithm. In M. S.
Kearns, S. A. Solla, and D. A. Cohn, editors, NIPS 11,
pages 375–381, Cambridge, 1999. MIT Press.
[3] M. Birattari, T. Stützle, L. Paquete, and K. Varrentrapp. A
racing algorithm for configuring metaheuristics. In W. B.
Langdon, editor, GECCO 2002, pages 11–18. Morgan
Kaufmann, 2002.
[4] G. Bontempi, M. Birattari, and H. Bersini. Lazy learning
for modeling and control design. International Journal of
Control, 72(7/8):643–658, 1999.
[5] G. Bontempi, M. Birattari, and H. Bersini. A model selection
approach for local learning. Artificial Intelligence Commu-
nications, 121(1), 2000.
[6] W. J. Conover. Practical Nonparametric Statistics. John
Wiley & Sons, New York, NY, USA, third edition, 1999.
24-1](https://image.slidesharecdn.com/coimbra-160524080154/85/Combining-Lazy-Learning-Racing-and-Subsampling-for-Effective-Feature-Selection-35-320.jpg)
![[7] I. Guyon and A. Elisseeff. An introduction to variable and
feature selection. Journal of Machine Learning Research,
3:1157–1182, 2003.
[8] O. Maron and A. Moore. The racing algorithm: Model selec-
tion for lazy learners. Artificial Intelligence Review, 11(1–
5):193–225, 1997.
24-2](https://image.slidesharecdn.com/coimbra-160524080154/85/Combining-Lazy-Learning-Racing-and-Subsampling-for-Effective-Feature-Selection-36-320.jpg)

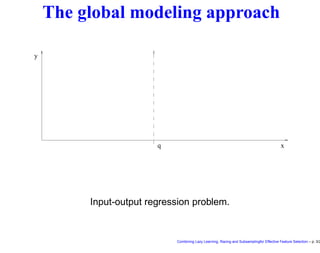
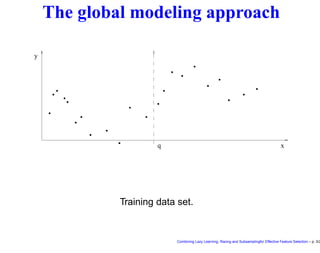
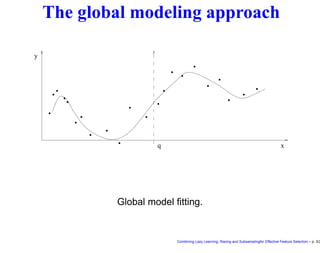
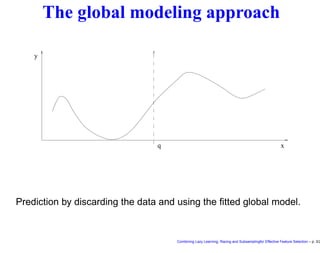
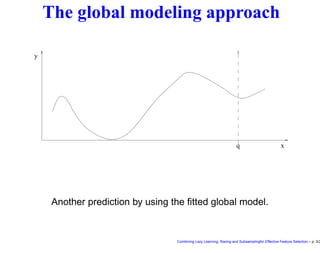
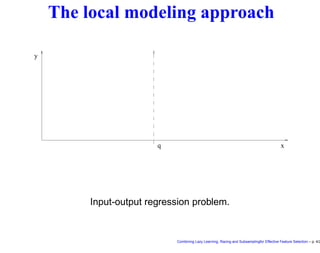
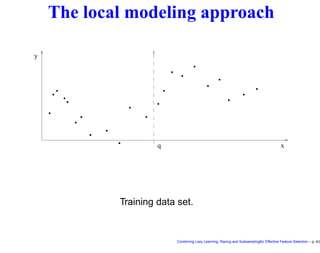
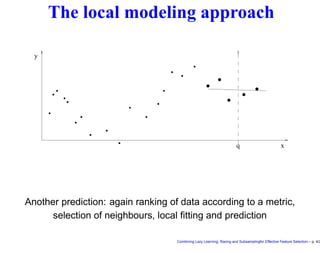
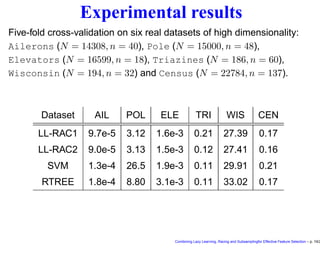
This document discusses approaches to feature selection for machine learning models, specifically comparing global versus local modeling techniques. It proposes combining lazy learning, racing, and subsampling for effective feature selection. Lazy learning uses local linear models for prediction rather than global nonlinear models, improving computational efficiency when many predictions are needed. Racing and subsampling allow efficient evaluation of feature subsets during wrapper-based feature selection by discarding poor-performing subsets early based on statistical tests of performance on subsets of the data. Experimental results are said to validate this combined approach for feature selection.

















































![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)





