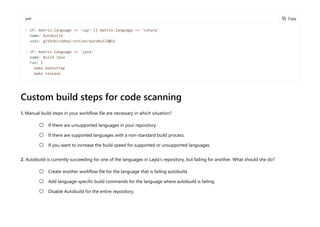
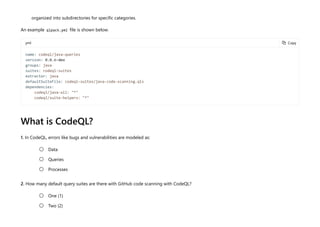
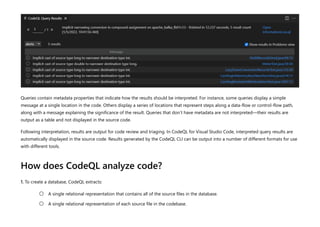
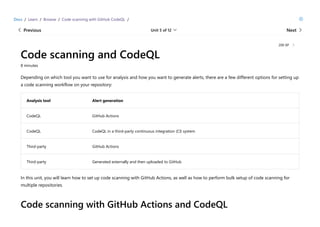
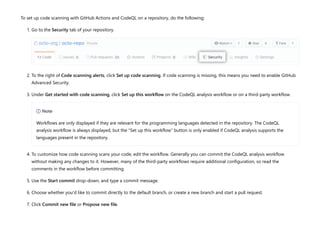
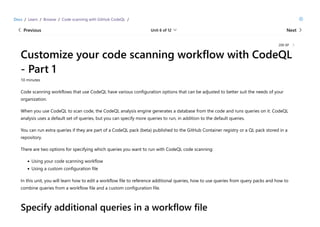
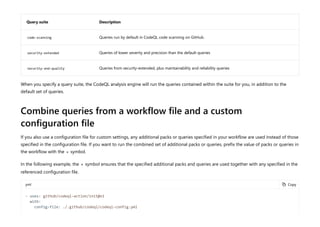
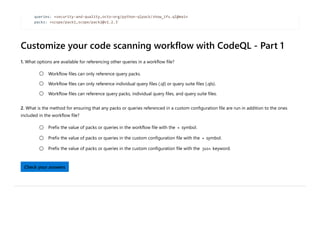
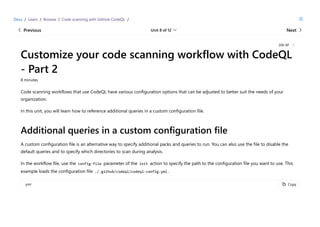
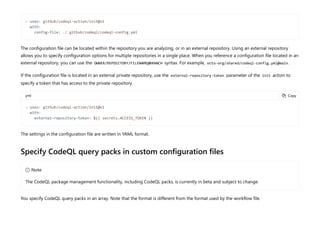
CodeQL is a static analysis tool used for automating security checks and performing variant analysis by treating code as data and executing queries against databases extracted from code. The document outlines how to create CodeQL databases, execute queries, and interpret results, emphasizing the modularity and efficiency of its declarative, object-oriented query language. It also details the setup of code scanning workflows with GitHub Actions, including customizing query execution through workflow files and QL packs.














![If you only want to run custom queries, you can disable the default security queries by using disable-default-queries: true . This flag
should also be used if you are trying to construct a custom query suite that excludes a particular rule. This is to avoid having all of the
queries run twice.
Specify directories to scan
For the interpreted languages that CodeQL supports (Python, Ruby and JavaScript/TypeScript), you can restrict code scanning to files in
specific directories by adding a paths array to the configuration file. You can exclude the files in specific directories from analysis by adding
a paths-ignore array.
yml = Copy
paths:
- src
paths-ignore:
- src/node_modules
- '**/*.test.js'
7 Note
• The paths and paths-ignore keywords, used in the context of the code scanning configuration file, should not be confused with
the same keywords when used for on.<push|pull_request>.paths in a workflow. When they are used to modify
on.<push|pull_request> in a workflow, they determine whether the actions will be run when someone modifies code in the
specified directories.
• The filter pattern characters ? , + , [ , ] , and ! are not supported and will be matched literally.
• ** characters can only be at the start or end of a line, or surrounded by slashes, and you can't mix ** and other characters. For](https://image.slidesharecdn.com/codeql-240621161817-b47cddab/85/CodeQL-Microsoft-documentation-Basic-of-CodeQL-27-320.jpg)




![Option Required Usage
--source-root Optional. Use if you run the CLI outside the checkout root of the repository. By default, the database create command
assumes that the current directory is the root directory for the source files, use this option to specify a different location.
Single language example
This example creates a CodeQL database for the repository checked out at /checkouts/example-repo . It uses the JavaScript extractor to
create a hierarchical representation of the JavaScript and TypeScript code in the repository. The resulting database is stored in /codeql-
dbs/example-repo .
Bash
Multiple languages example
This example creates two CodeQL databases for the repository checked out at /checkouts/example-repo-multi . It uses:
= Copy
$ codeql database create /codeql-dbs/example-repo --language=javascript
--source-root /checkouts/example-repo
> Initializing database at /codeql-dbs/example-repo.
> Running command [/codeql-home/codeql/javascript/tools/autobuild.cmd]
in /checkouts/example-repo.
> [build-stdout] Single-threaded extraction.
> [build-stdout] Extracting
...
> Finalizing database at /codeql-dbs/example-repo.
> Successfully created database at /codeql-dbs/example-repo.](https://image.slidesharecdn.com/codeql-240621161817-b47cddab/85/CodeQL-Microsoft-documentation-Basic-of-CodeQL-33-320.jpg)
![• --db-cluster to request analysis of more than one language.
• --language to specify which languages to create databases for.
• --command to tell the tool the build command for the codebase, here make.
• --no-run-unnecessary-builds to tell the tool to skip the build command for languages where it is not needed (like Python).
The resulting databases are stored in python and cpp subdirectories of /codeql-dbs/example-repo-multi .
Bash
Analyze a CodeQL database
After creating your CodeQL database, follow the steps below to analyze it:
= Copy
$ codeql database create /codeql-dbs/example-repo-multi
--db-cluster --language python,cpp
--command make --no-run-unnecessary-builds
--source-root /checkouts/example-repo-multi
Initializing databases at /codeql-dbs/example-repo-multi.
Running build command: [make]
[build-stdout] Calling python3 /codeql-bundle/codeql/python/tools/get_venv_lib.py
[build-stdout] Calling python3 -S /codeql-bundle/codeql/python/tools/python_tracer.py -v -z all -c /codeql-dbs/example-
repo-multi/python/working/trap_cache -p ERROR: 'pip' not installed.
[build-stdout] /usr/local/lib/python3.6/dist-packages -R /checkouts/example-repo-multi
[build-stdout] [INFO] Python version 3.6.9
[build-stdout] [INFO] Python extractor version 5.16
[build-stdout] [INFO] [2] Extracted file /checkouts/example-repo-multi/hello.py in 5ms
[build-stdout] [INFO] Processed 1 modules in 0.15s
[build-stdout] <output from calling 'make' to build the C/C++ code>
Finalizing databases at /codeql-dbs/example-repo-multi.
Successfully created databases at /codeql-dbs/example-repo-multi.
$](https://image.slidesharecdn.com/codeql-240621161817-b47cddab/85/CodeQL-Microsoft-documentation-Basic-of-CodeQL-34-320.jpg)






![CodeQL to run each analysis in parallel. We recommend that all workflows adopt this configuration due to the performance benefits of
parallelizing builds.
If your repository contains code in more than one of the supported languages, you can choose which languages you want to analyze.
There are several reasons you might want to prevent a language being analyzed. For example, the project might have dependencies in a
different language to the main body of your code, and you might prefer not to see alerts for those dependencies.
If your workflow uses the language matrix then CodeQL is hardcoded to analyze only the languages in the matrix. To change the
languages you want to analyze, edit the value of the matrix variable. You can remove a language to prevent it being analyzed or you can
add a language that was not present in the repository when code scanning was set up. For example, if the repository initially only
contained JavaScript when code scanning was set up, and you later added Python code, you will need to add python to the matrix.
yml
If your workflow does not contain a matrix called language, then CodeQL is configured to run analysis sequentially. If you don't specify
languages in the workflow, CodeQL automatically detects, and attempts to analyze, any supported languages in the repository. If you want
to choose which languages to analyze, without using a matrix, you can use the languages parameter under the init action.
yml
= Copy
jobs:
analyze:
name: Analyze
...
strategy:
fail-fast: false
matrix:
language: ['javascript', 'python']
= Copy
- uses: github/codeql-action/init@v1
with:](https://image.slidesharecdn.com/codeql-240621161817-b47cddab/85/CodeQL-Microsoft-documentation-Basic-of-CodeQL-42-320.jpg)