





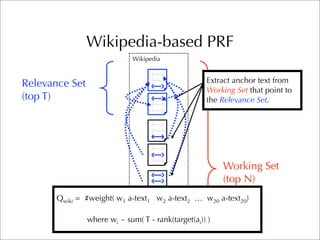
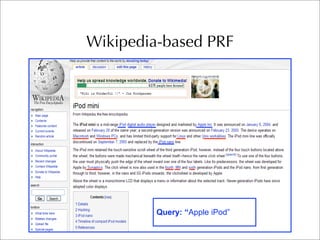



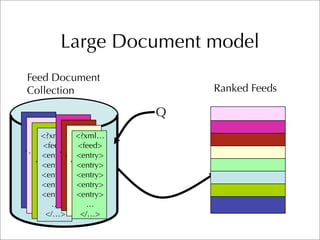
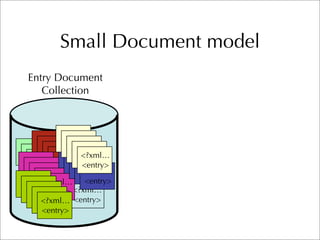
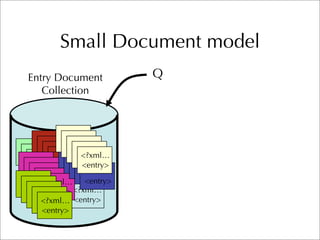
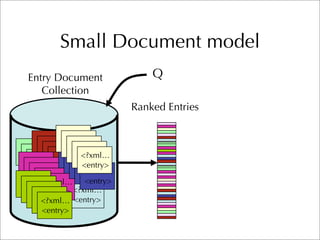
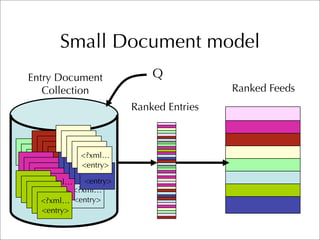



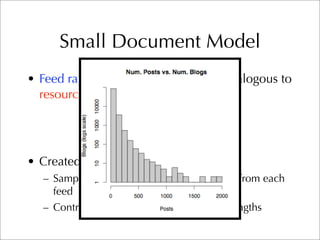






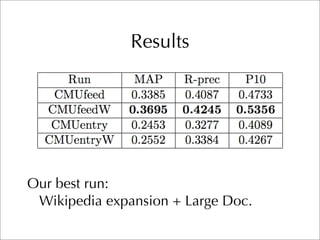
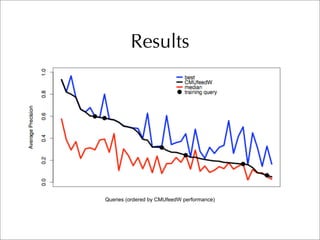
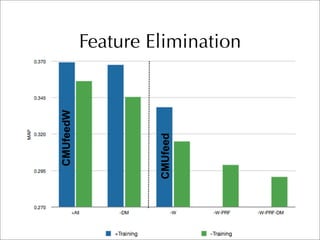


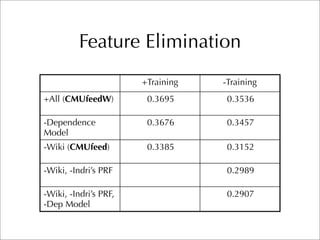

The document describes two retrieval models and two pseudo-relevance feedback models for blog distillation that were investigated by CMU at the TREC 2007 Blog Track. The two retrieval models were a large document model that used entire blog feeds as the retrieval unit, and a small document model that used individual blog entries as the retrieval unit. The two feedback models were Indri's built-in pseudo-relevance feedback and a Wikipedia-based pseudo-relevance feedback model. Results of the different approaches on the blog distillation task are also briefly mentioned.





















































