
Download to read offline



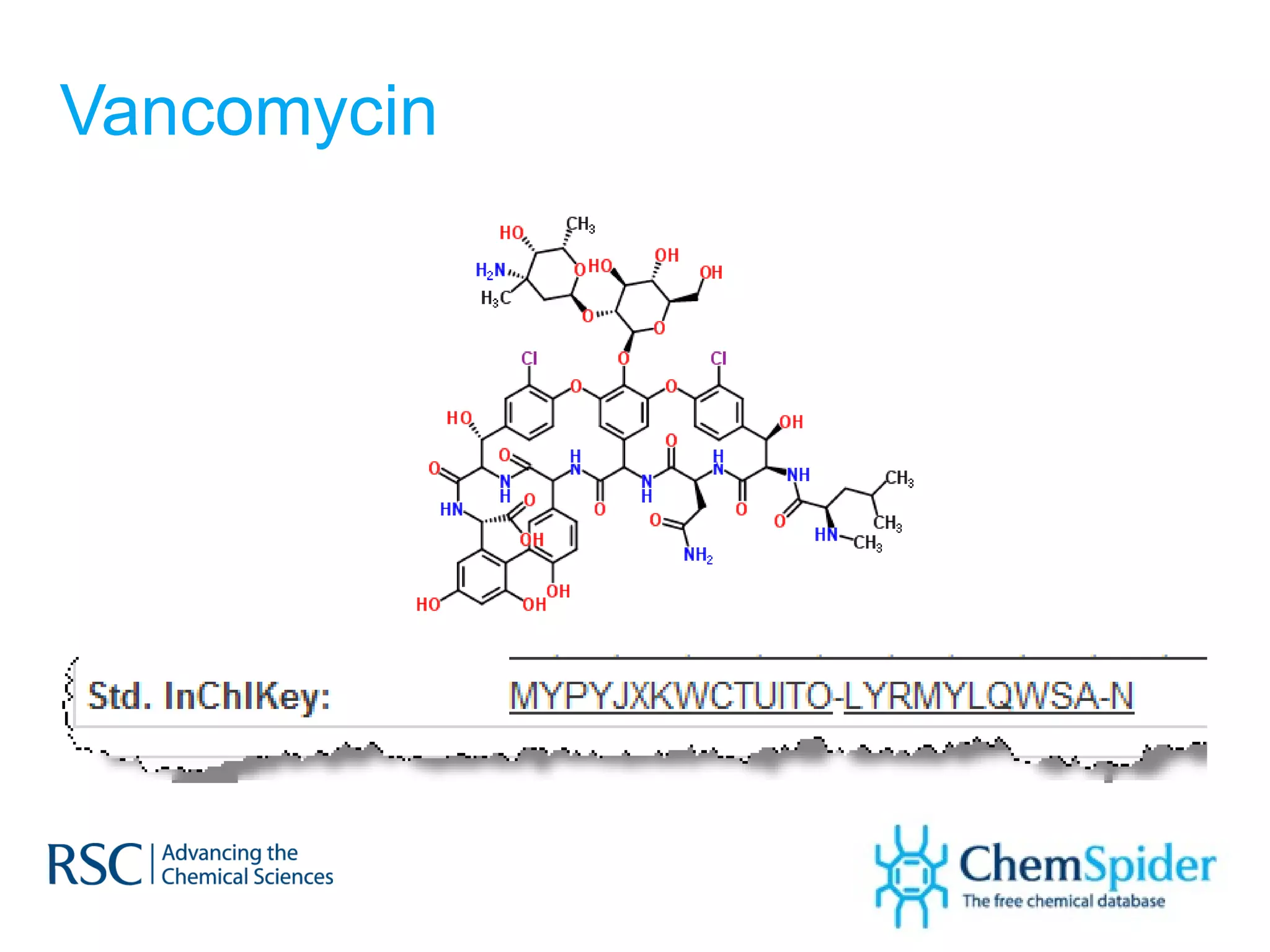
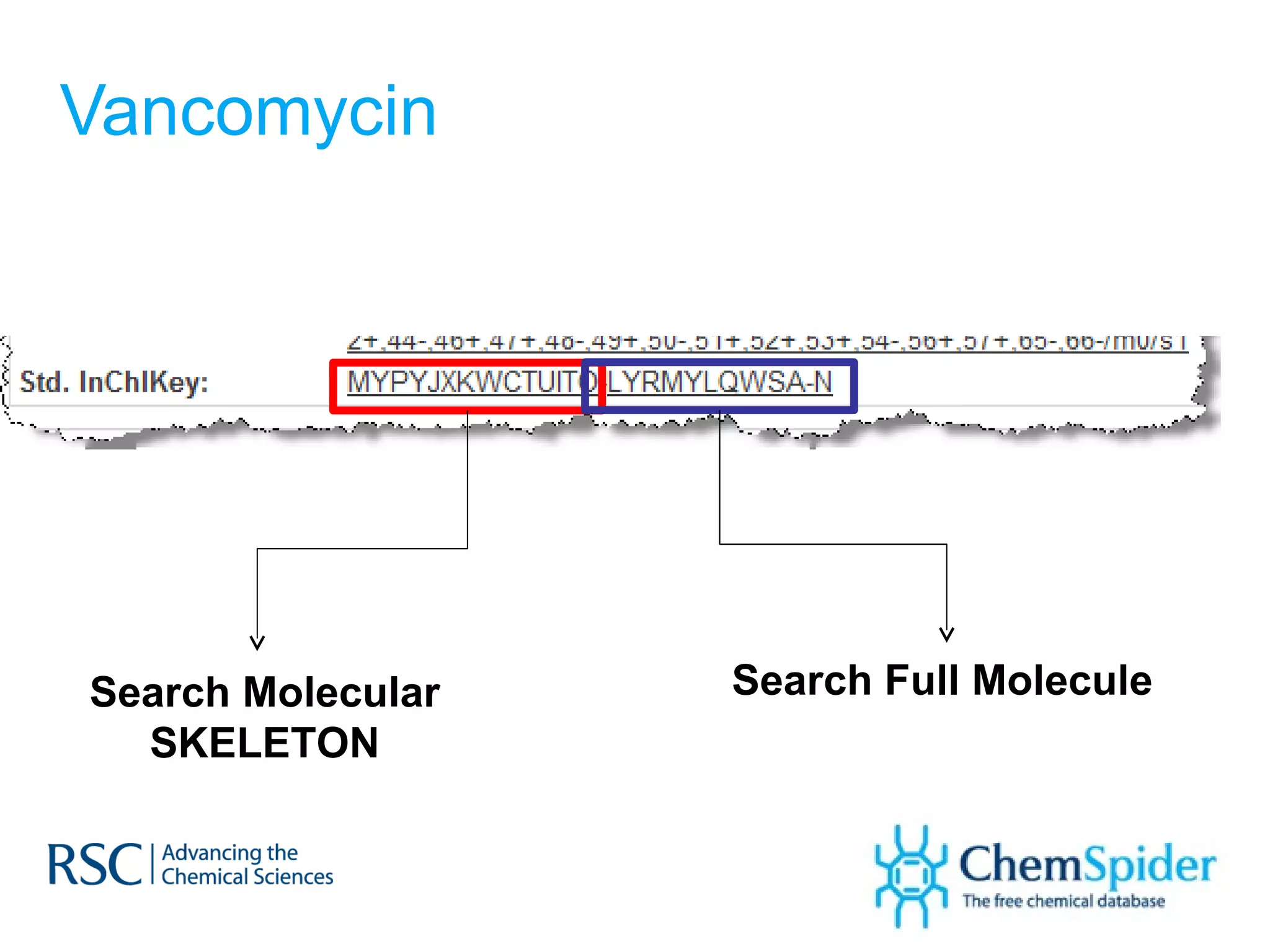

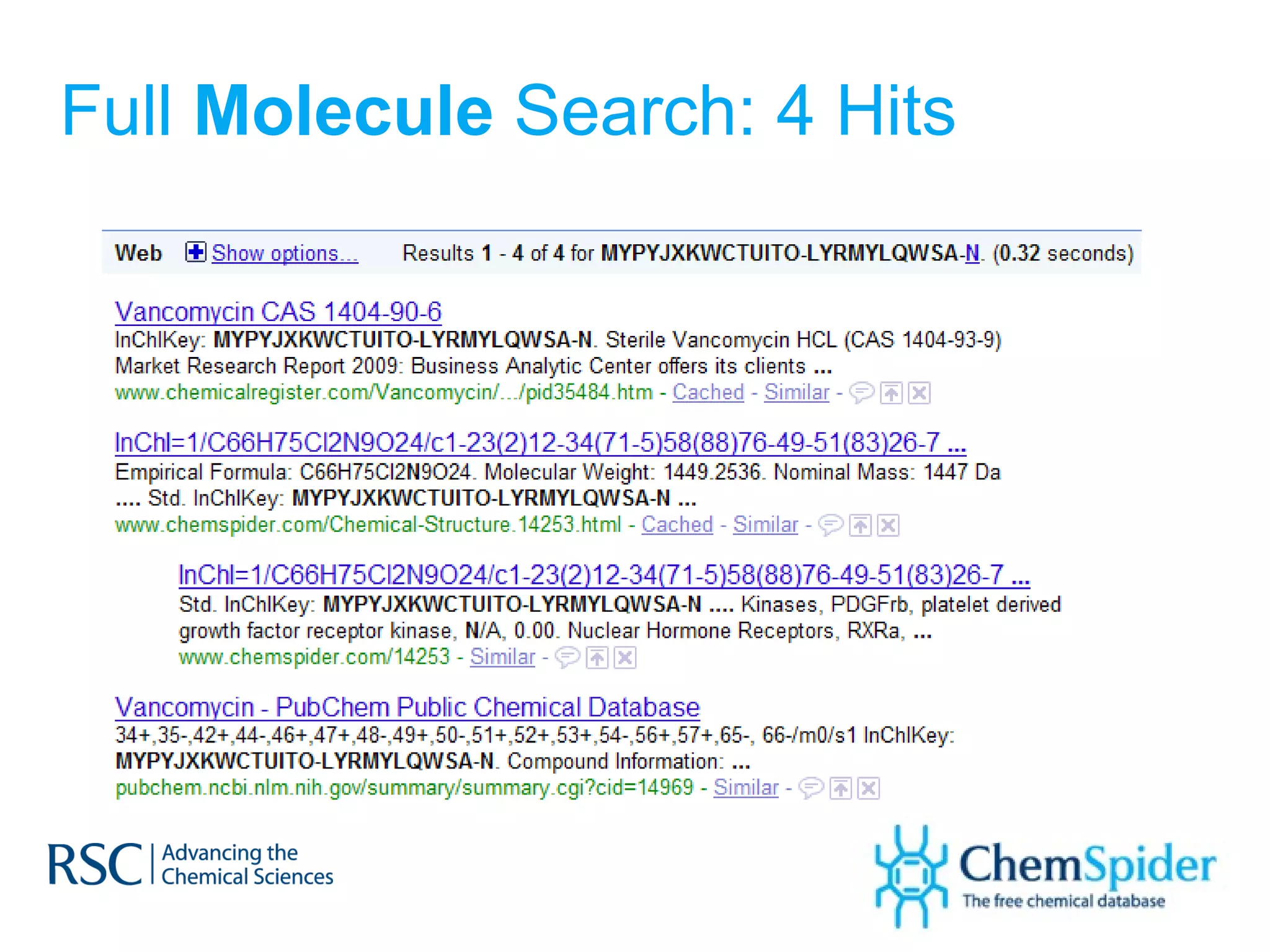


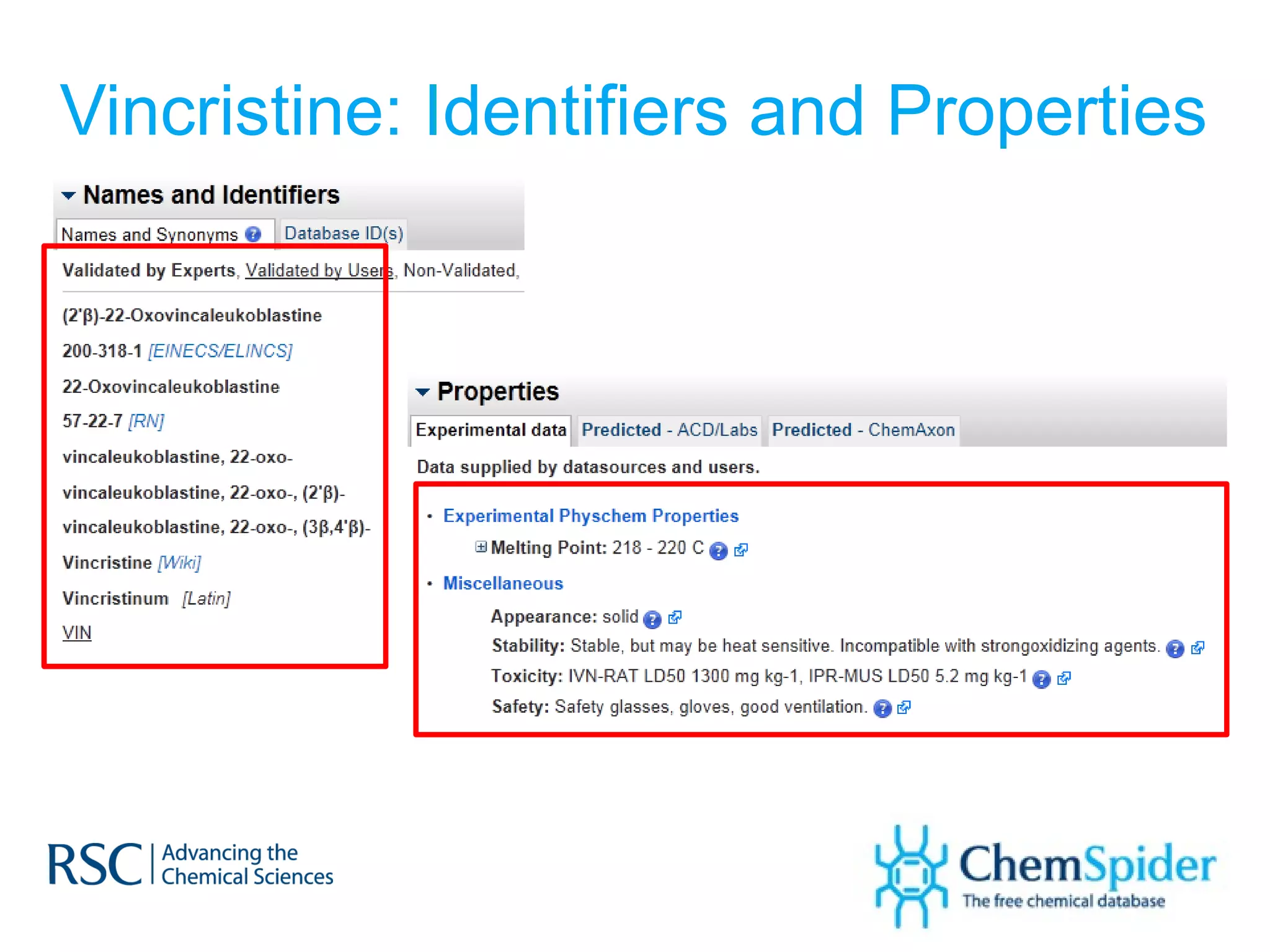













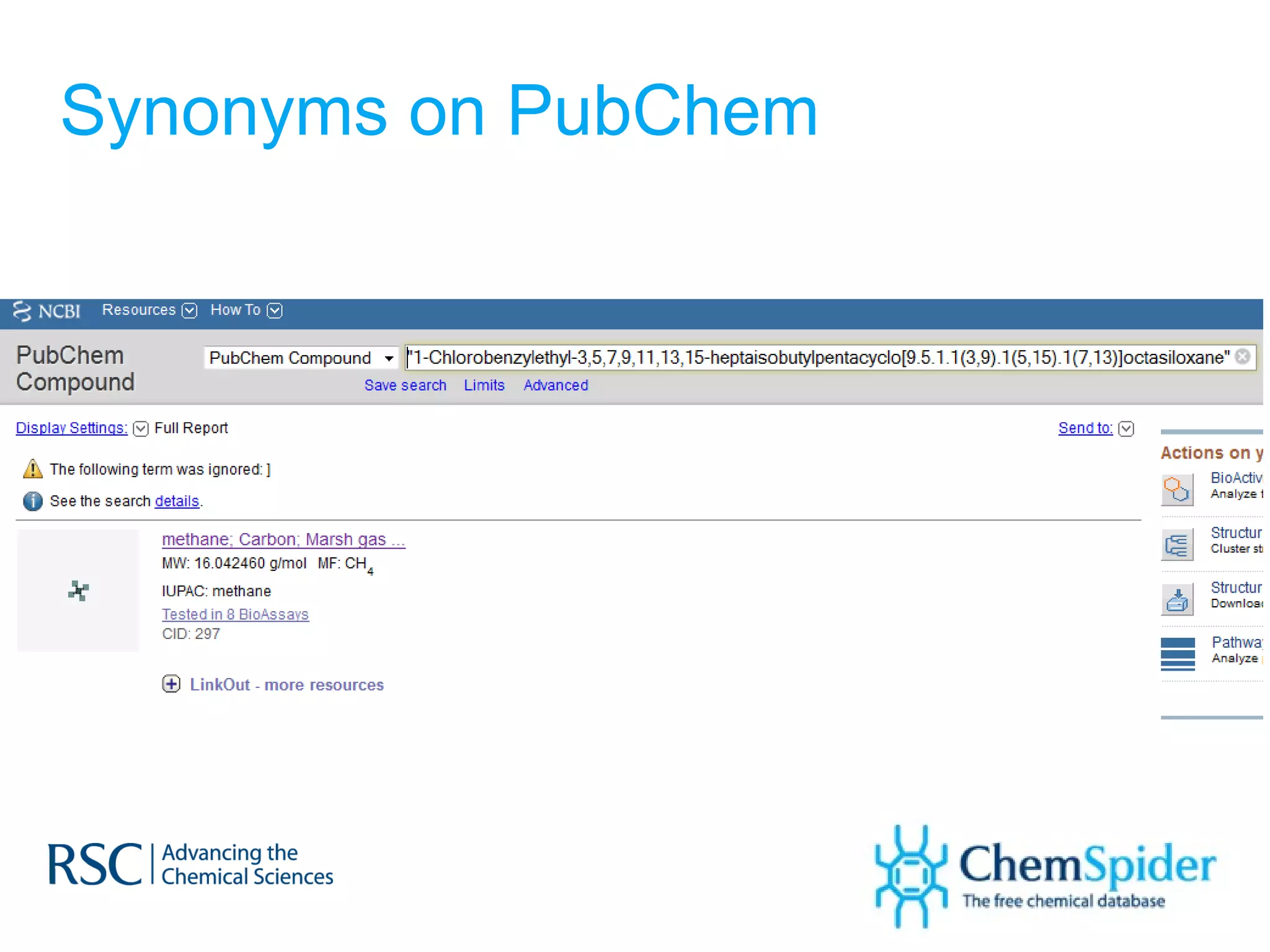
![Synonyms on PubChem 1,3-DICHLORO-PROPAN-2-ONE (2R,3R)-Butanediol bis(methanesulfonate) Ethyl-1-propenyl ether, mixture of cis and trans PSS-[2-[(Chloromethyl)phenyl]ethyl]-Heptaisobutyl substituted 1-Chlorobenzylethyl-3,5,7,9,11,13,15-heptaisobutylpentacyclo [9.5.1.1(3,9).1(5,15).1(7,13)]octasiloxane](https://image.slidesharecdn.com/ebipresentationoctober2011100911-111011100454-phpapp02/75/ChemSpider-An-Online-Database-and-Registration-System-Linking-the-Web-36-2048.jpg)
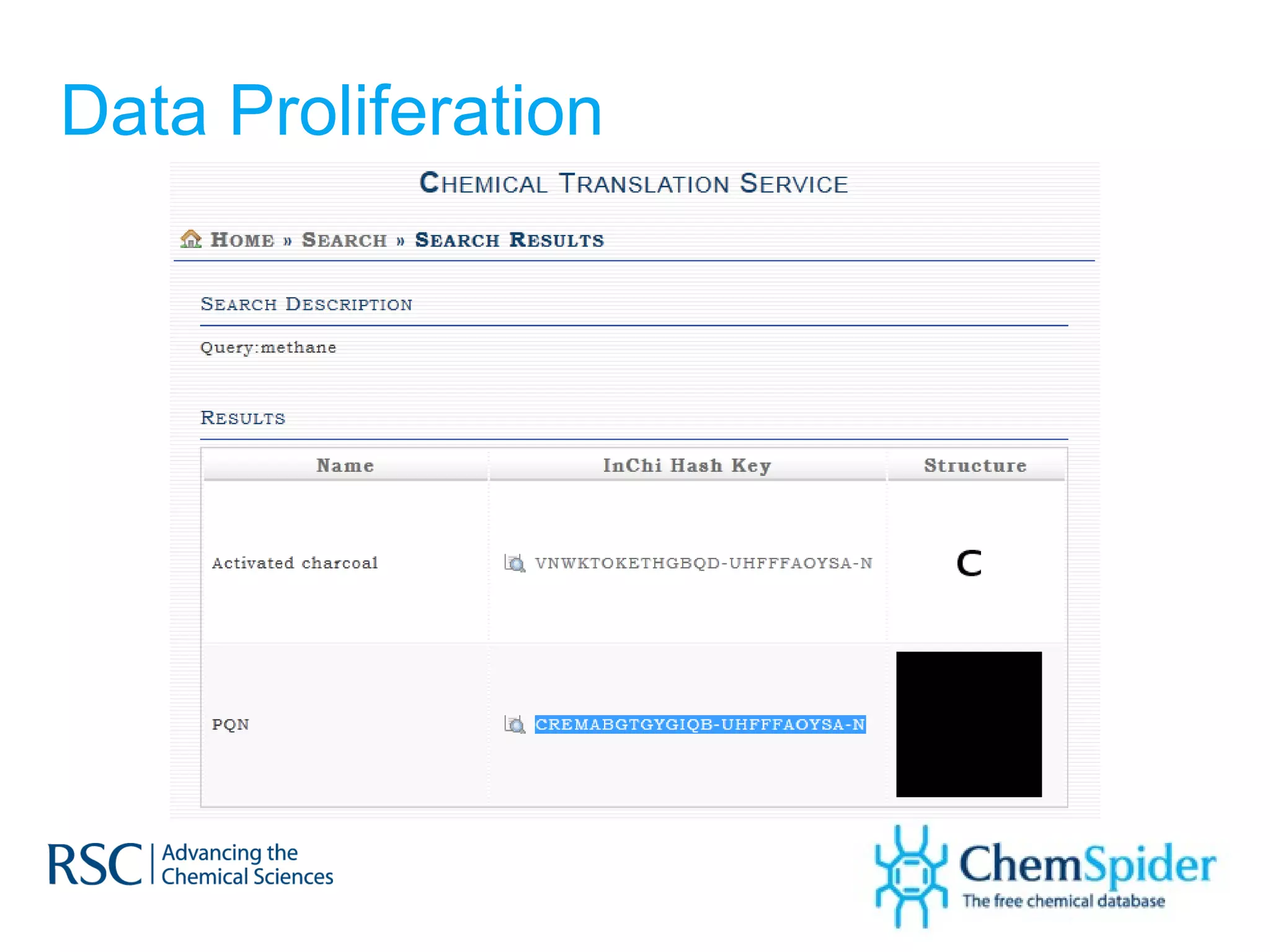
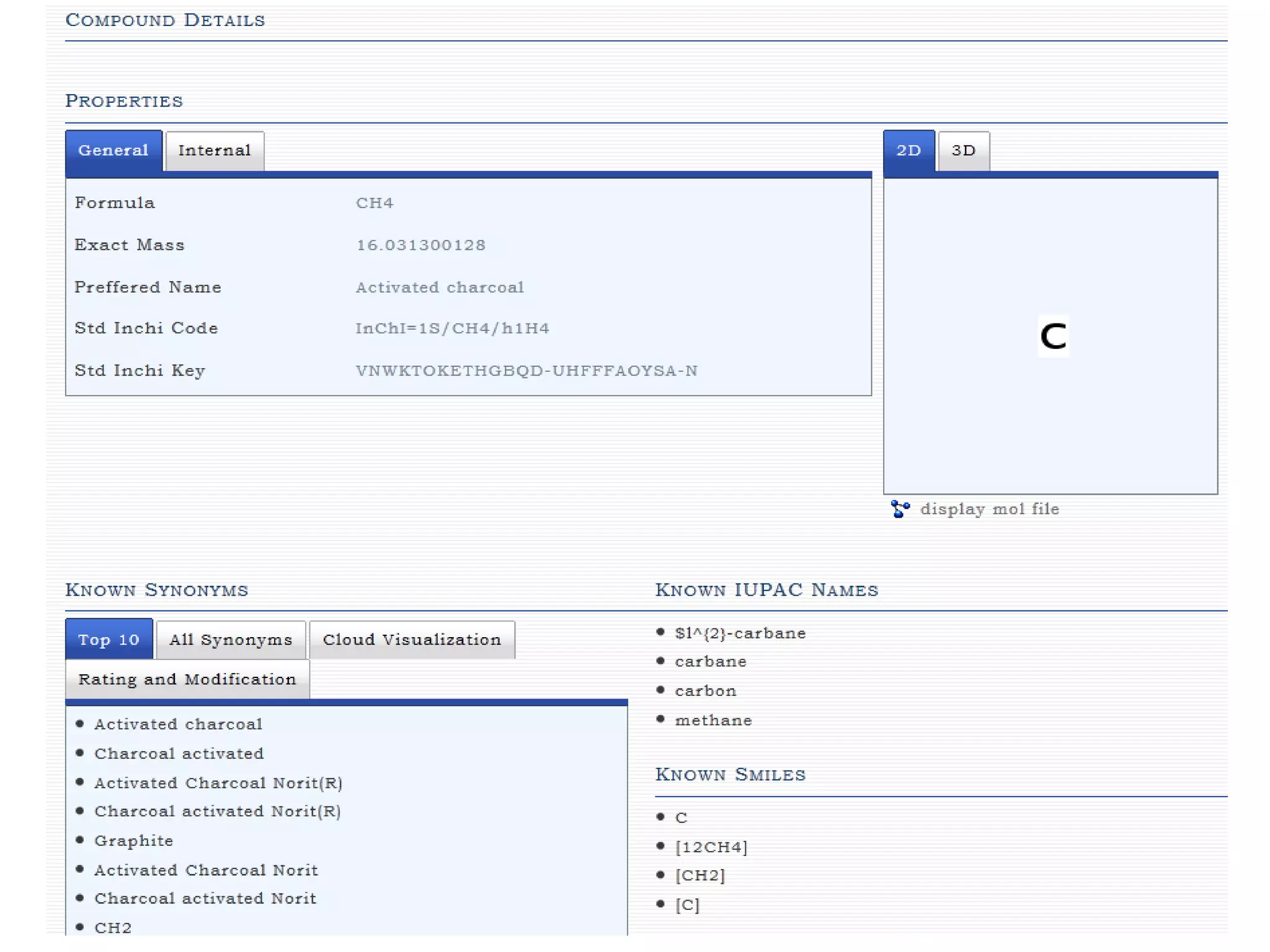
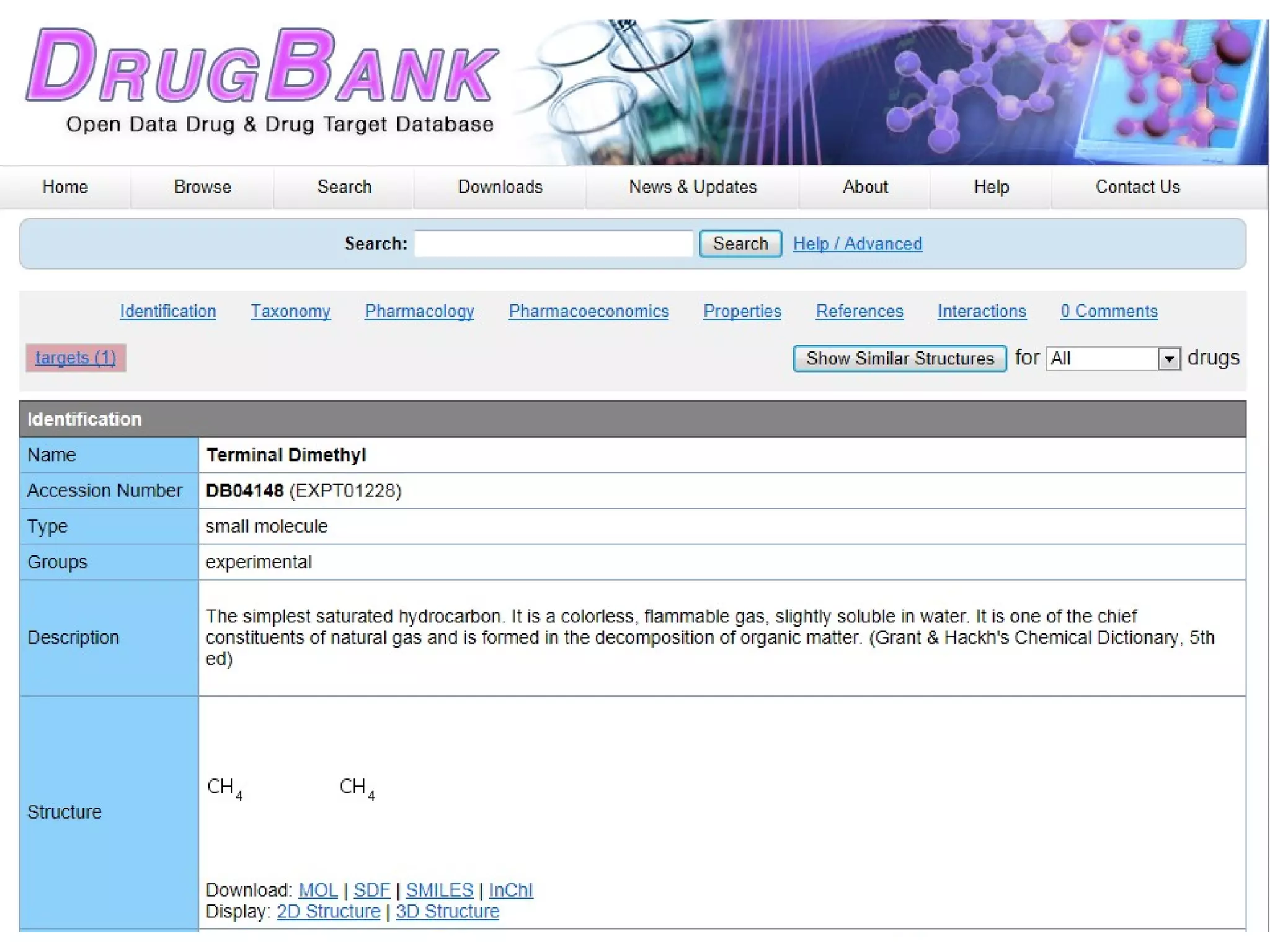
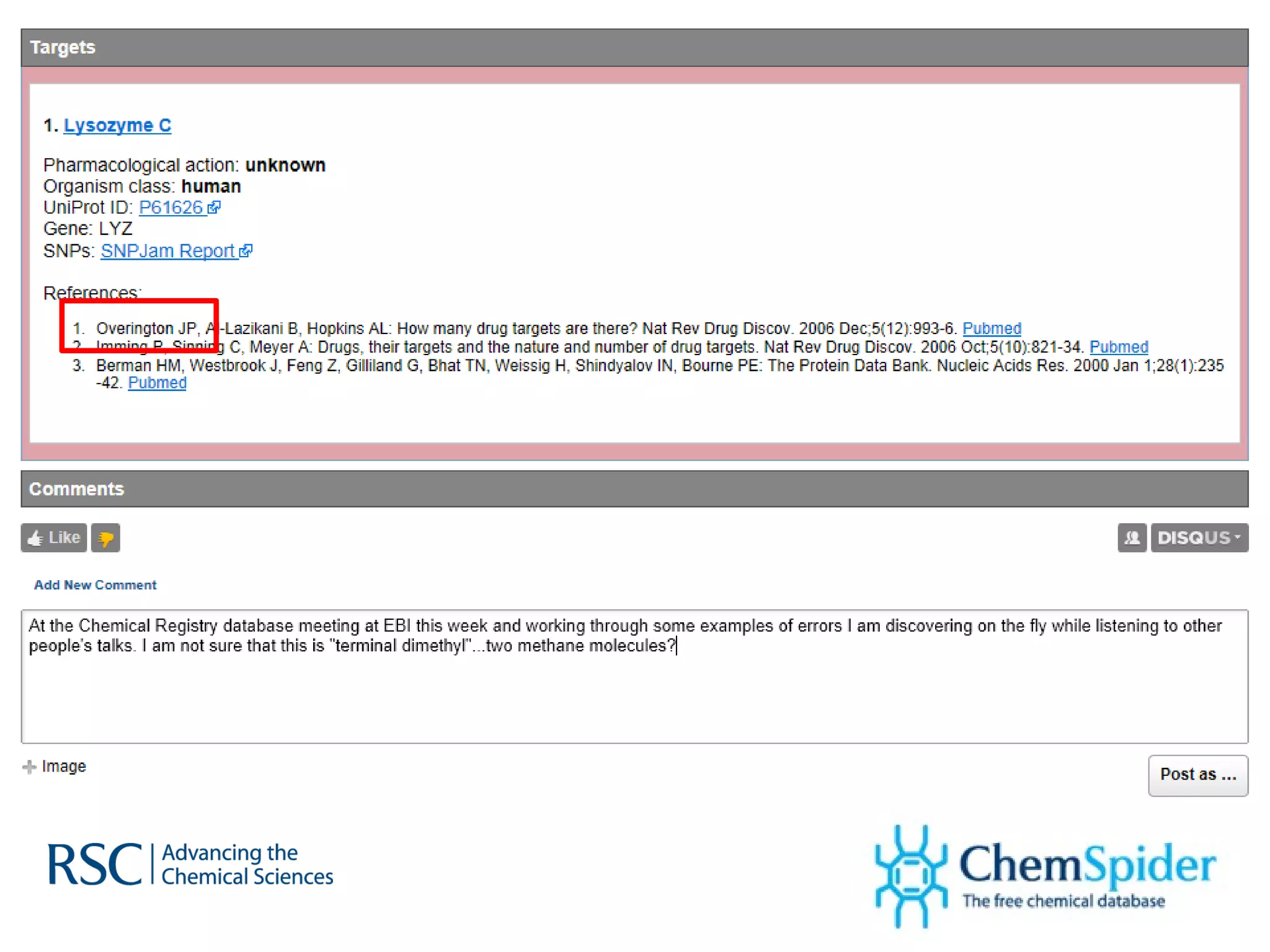
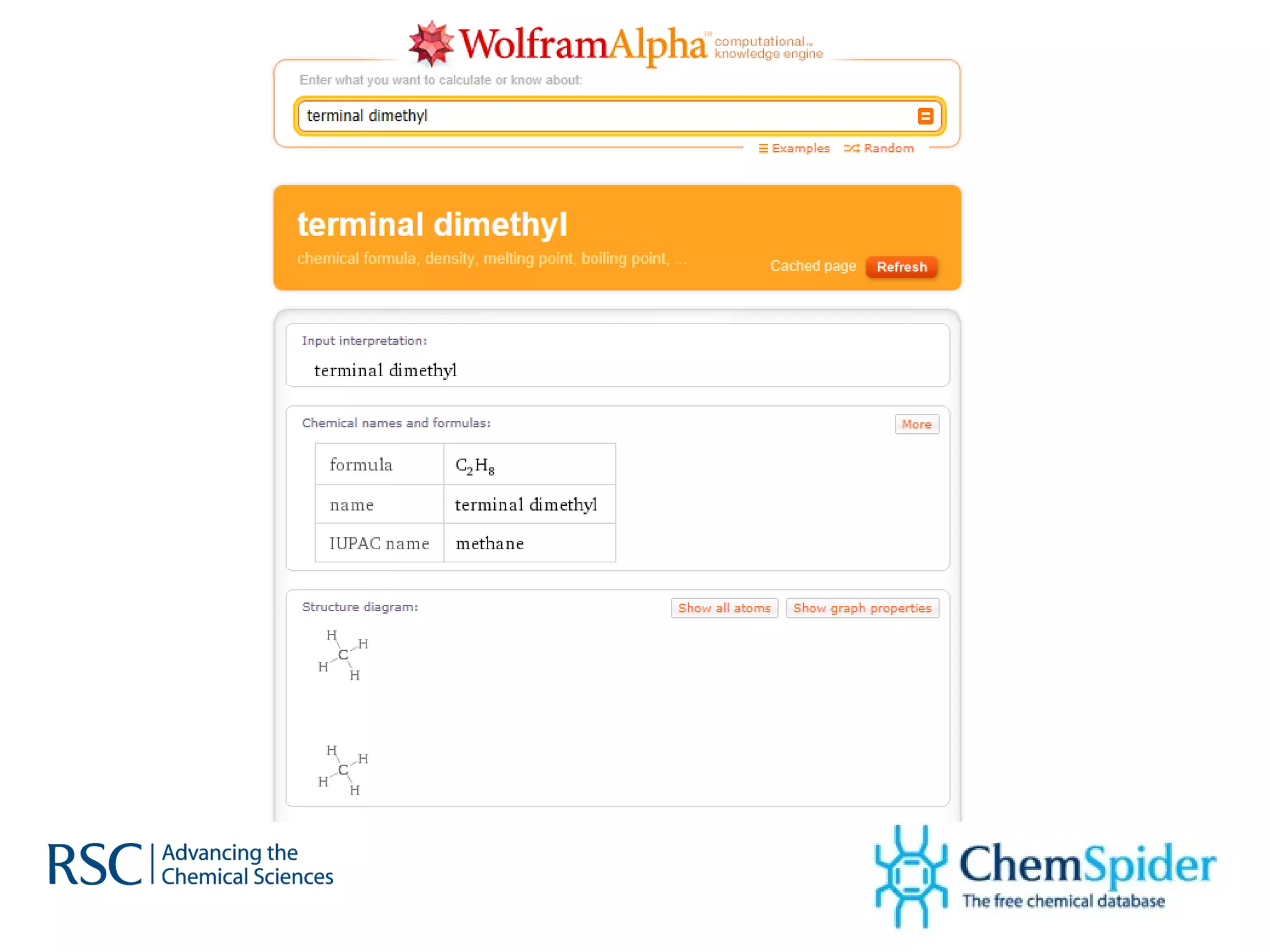
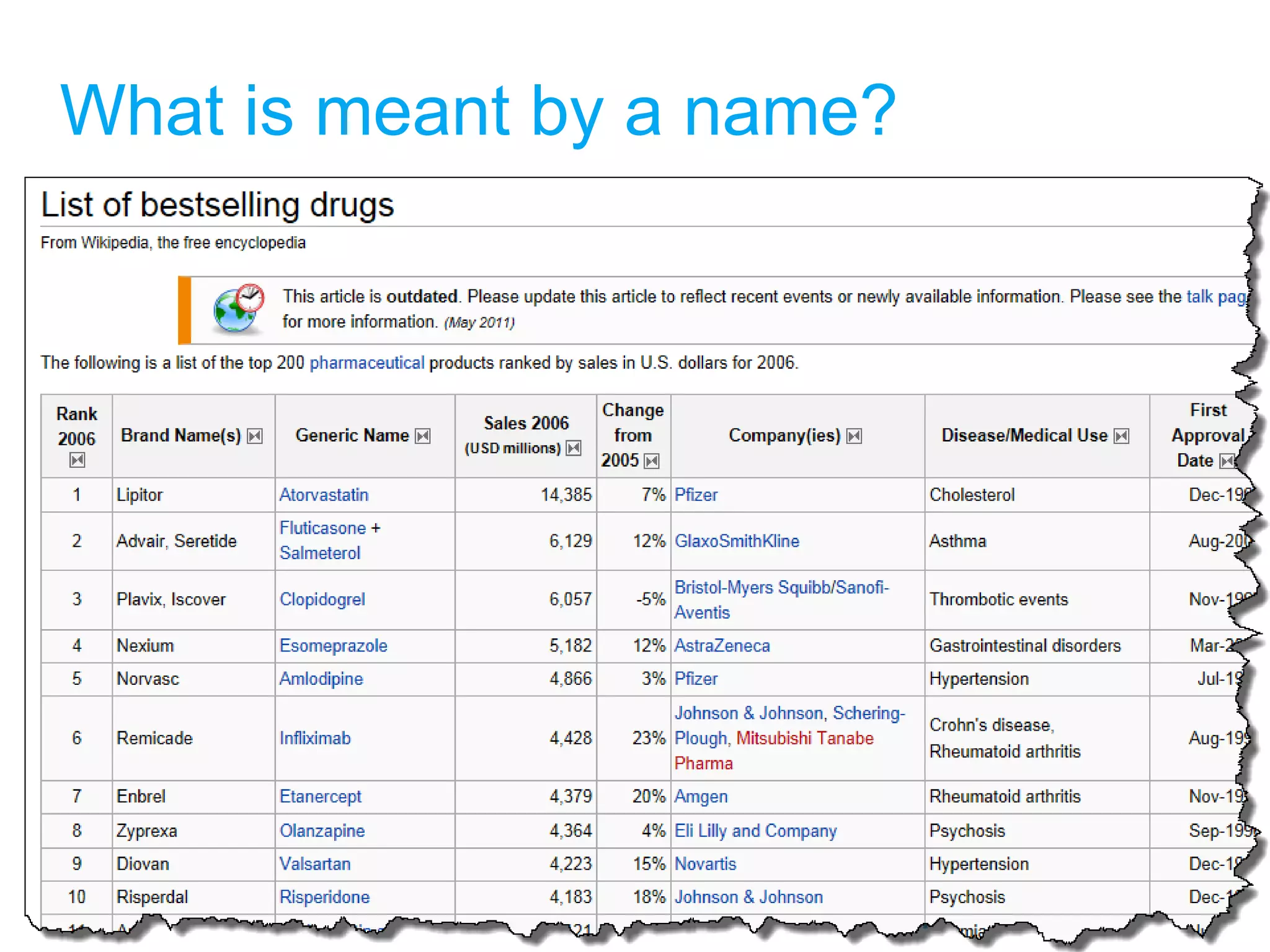

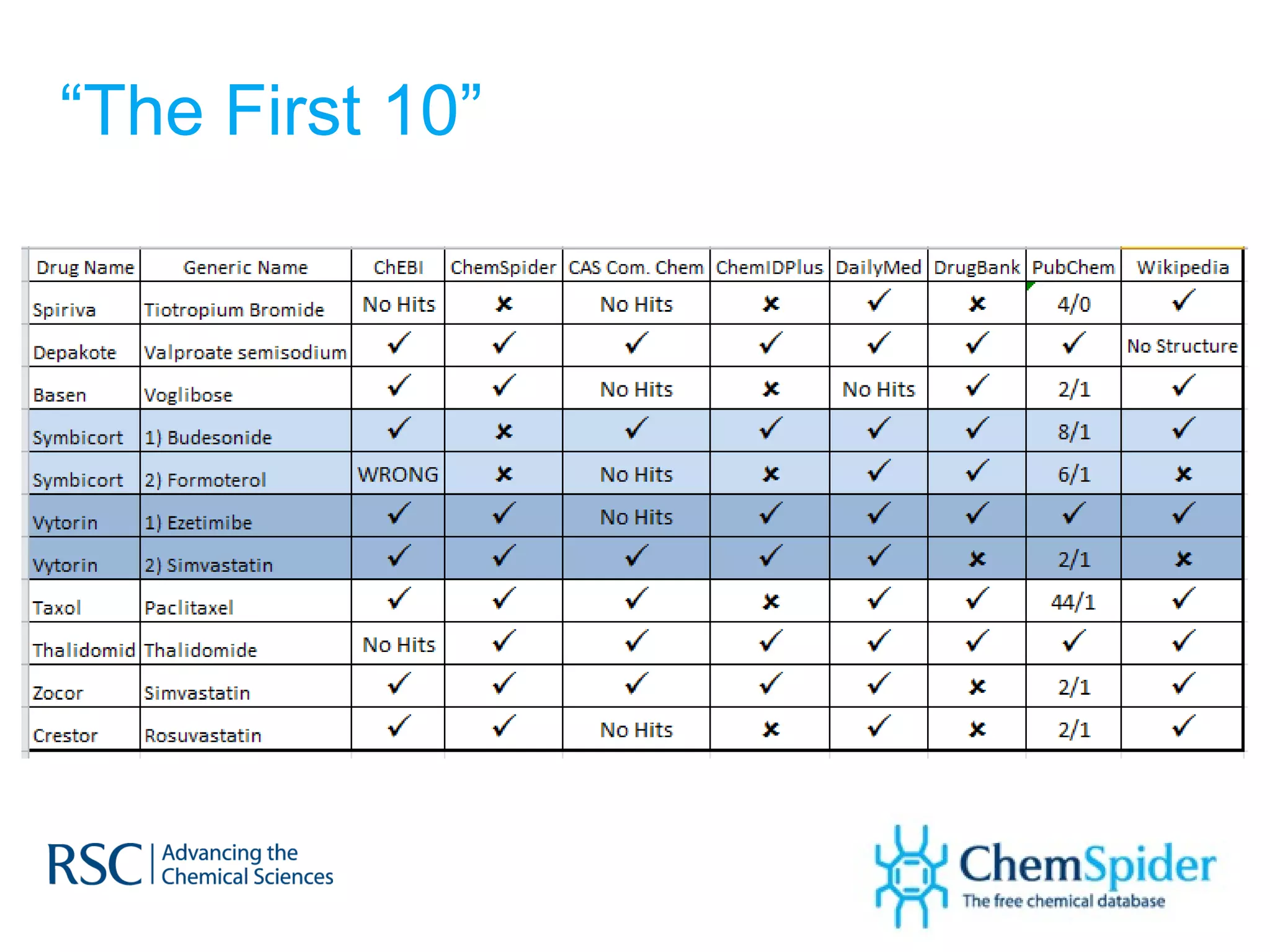

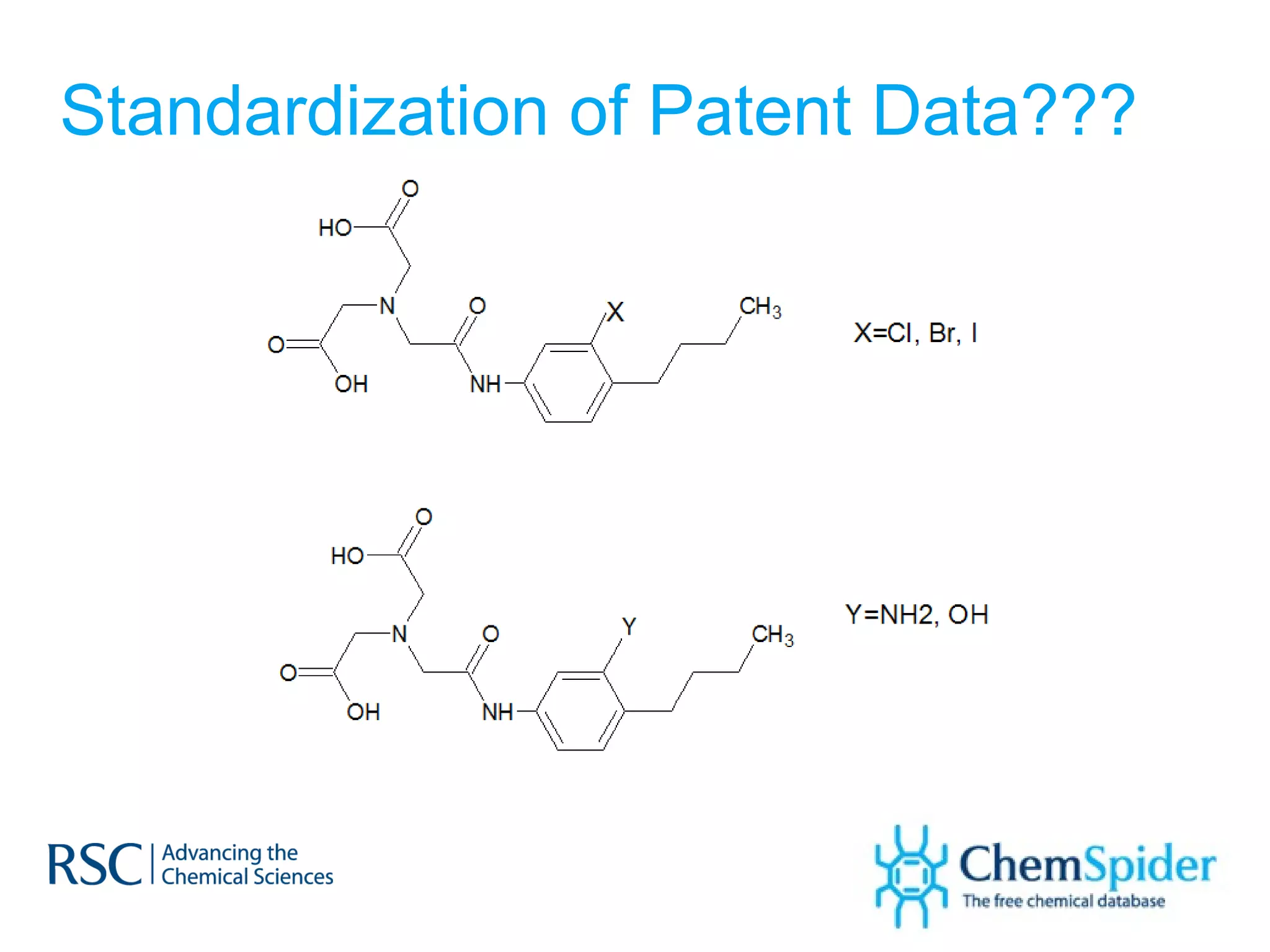
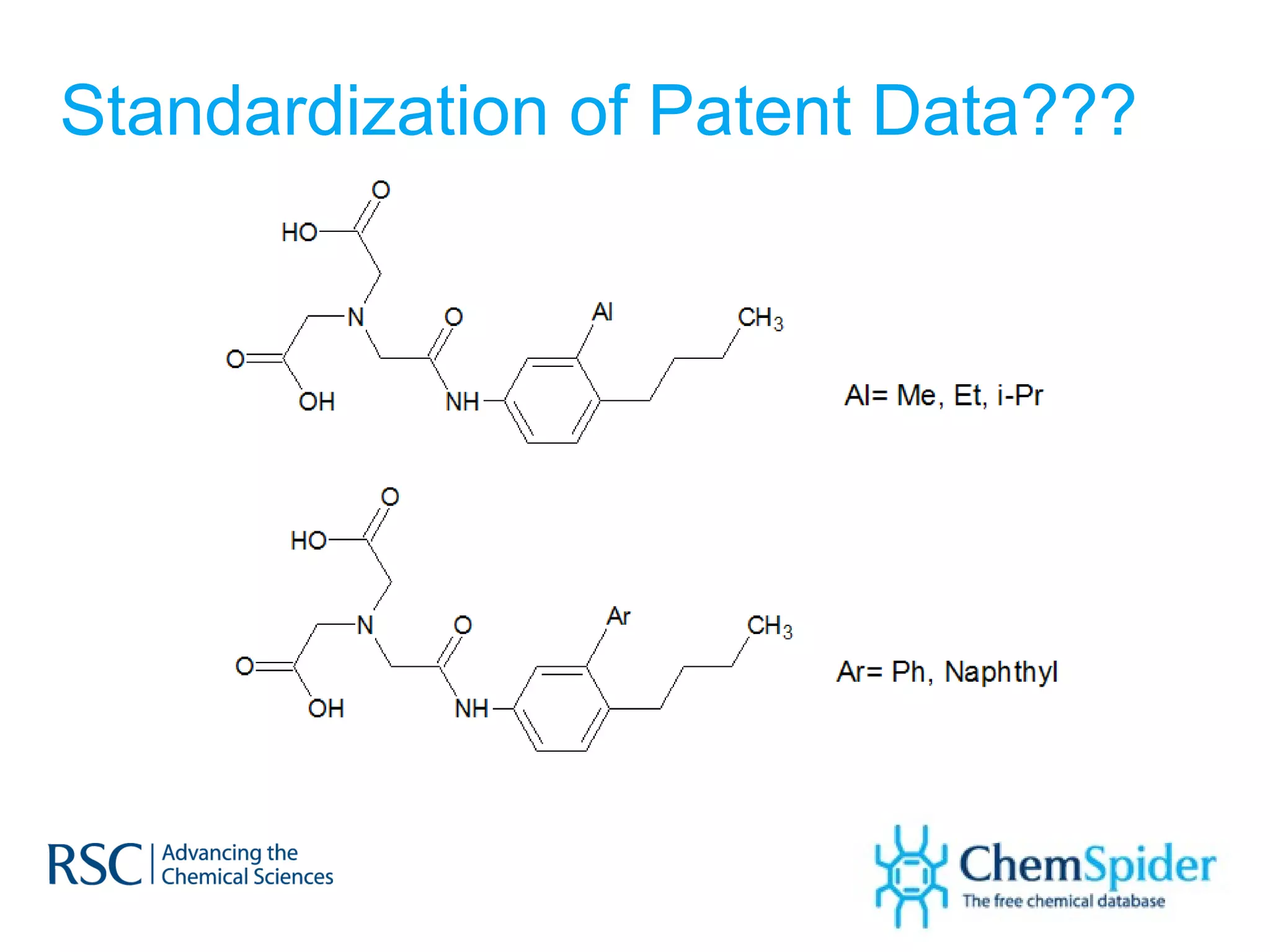
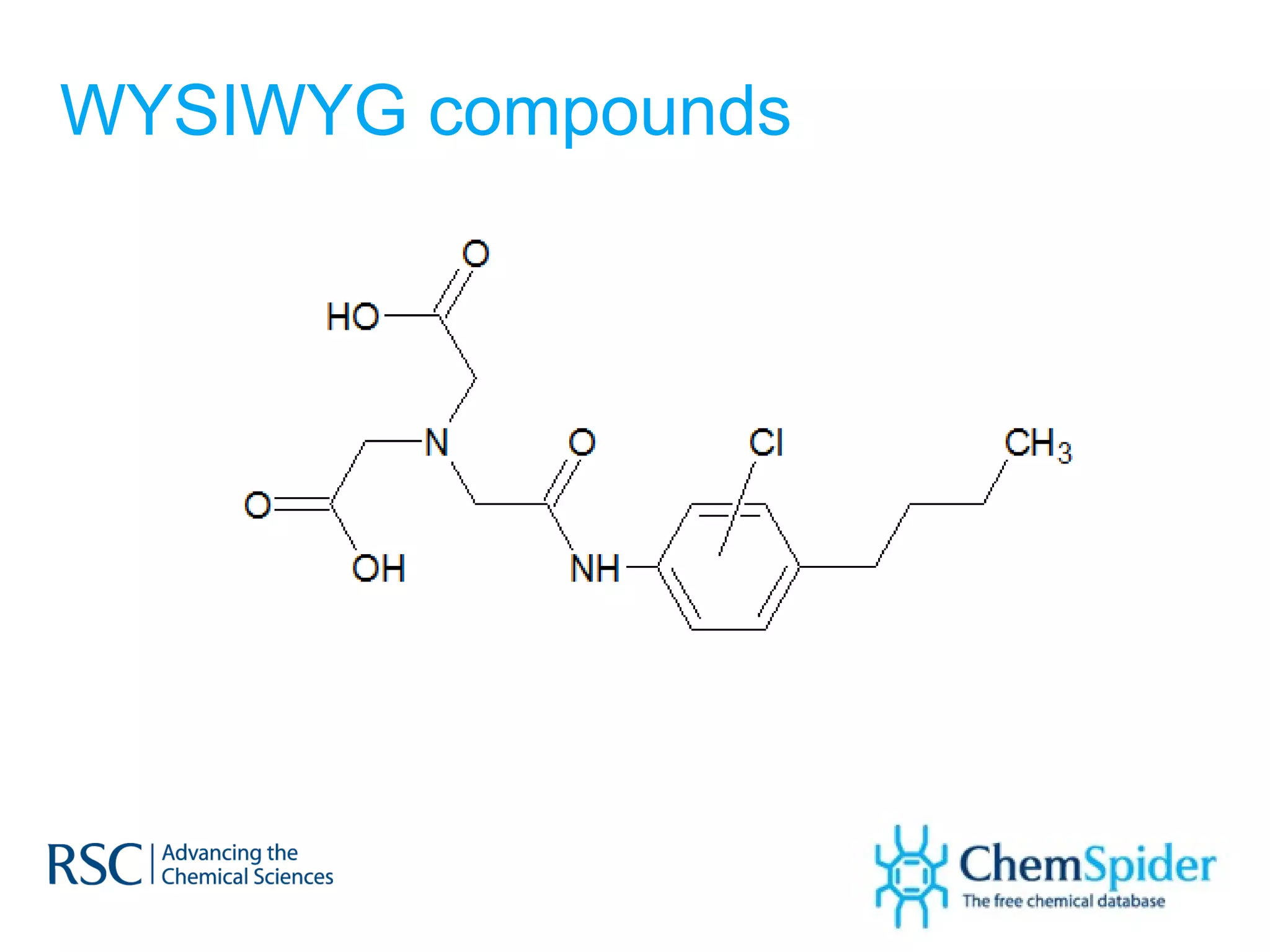



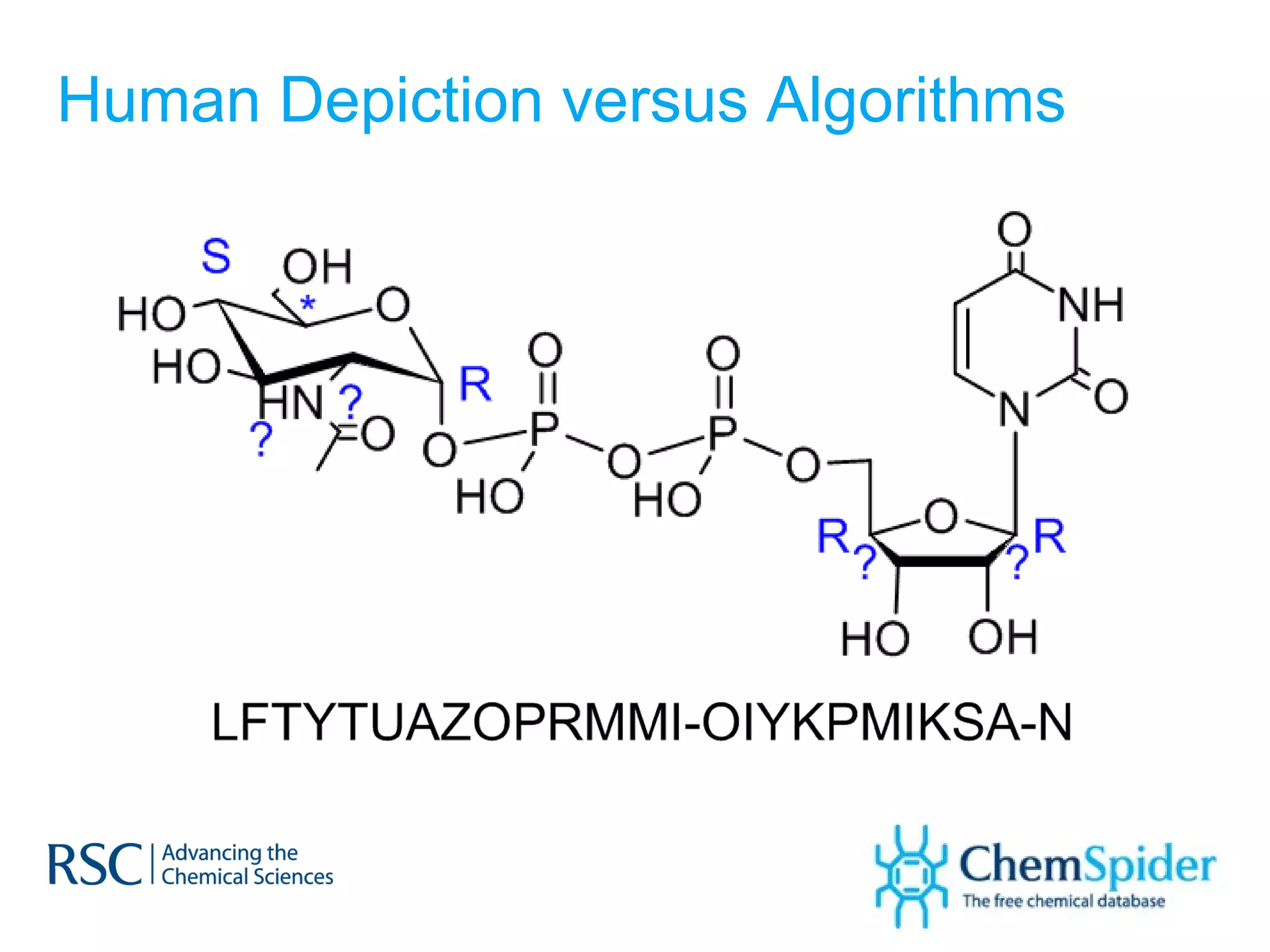
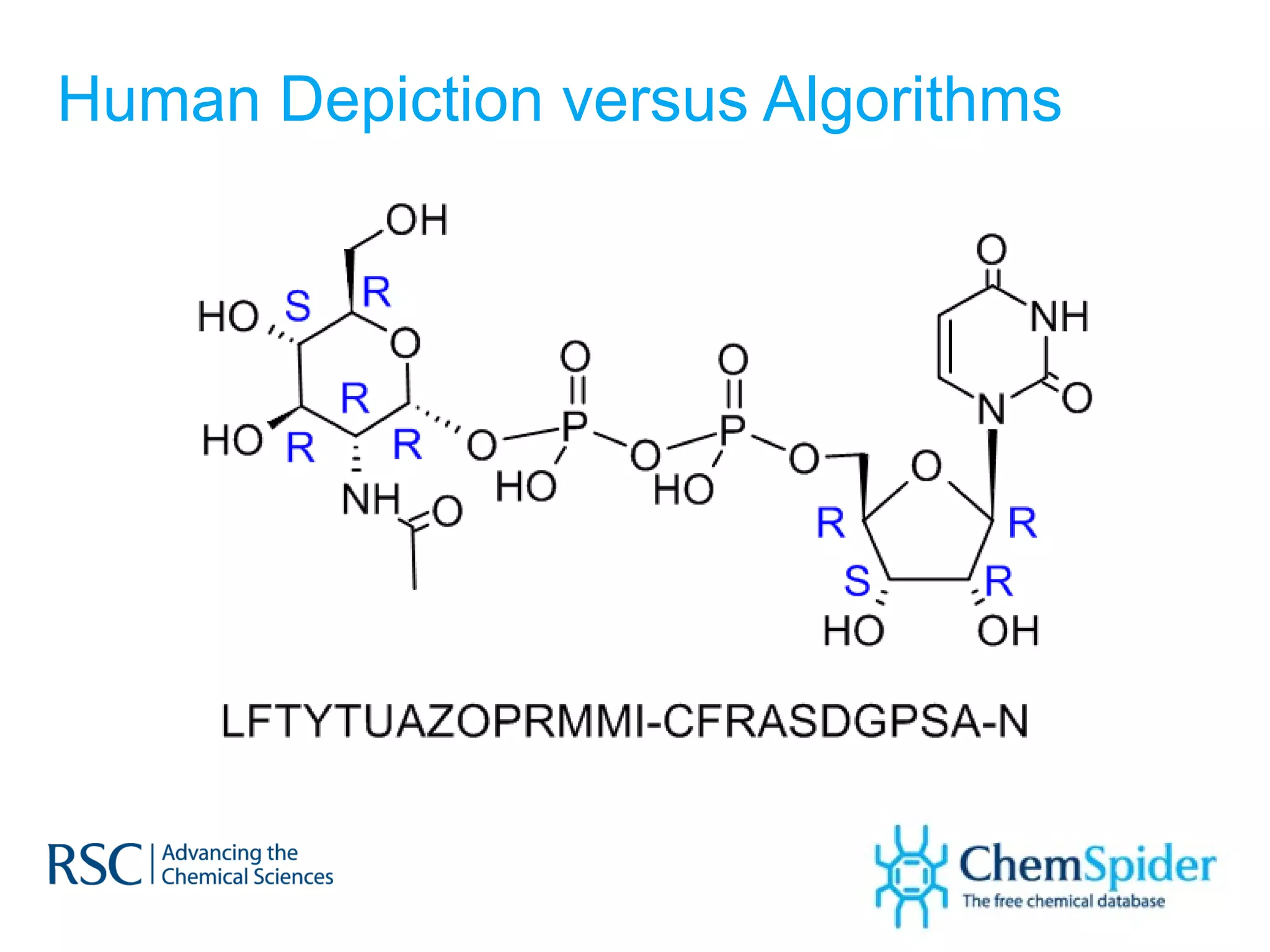






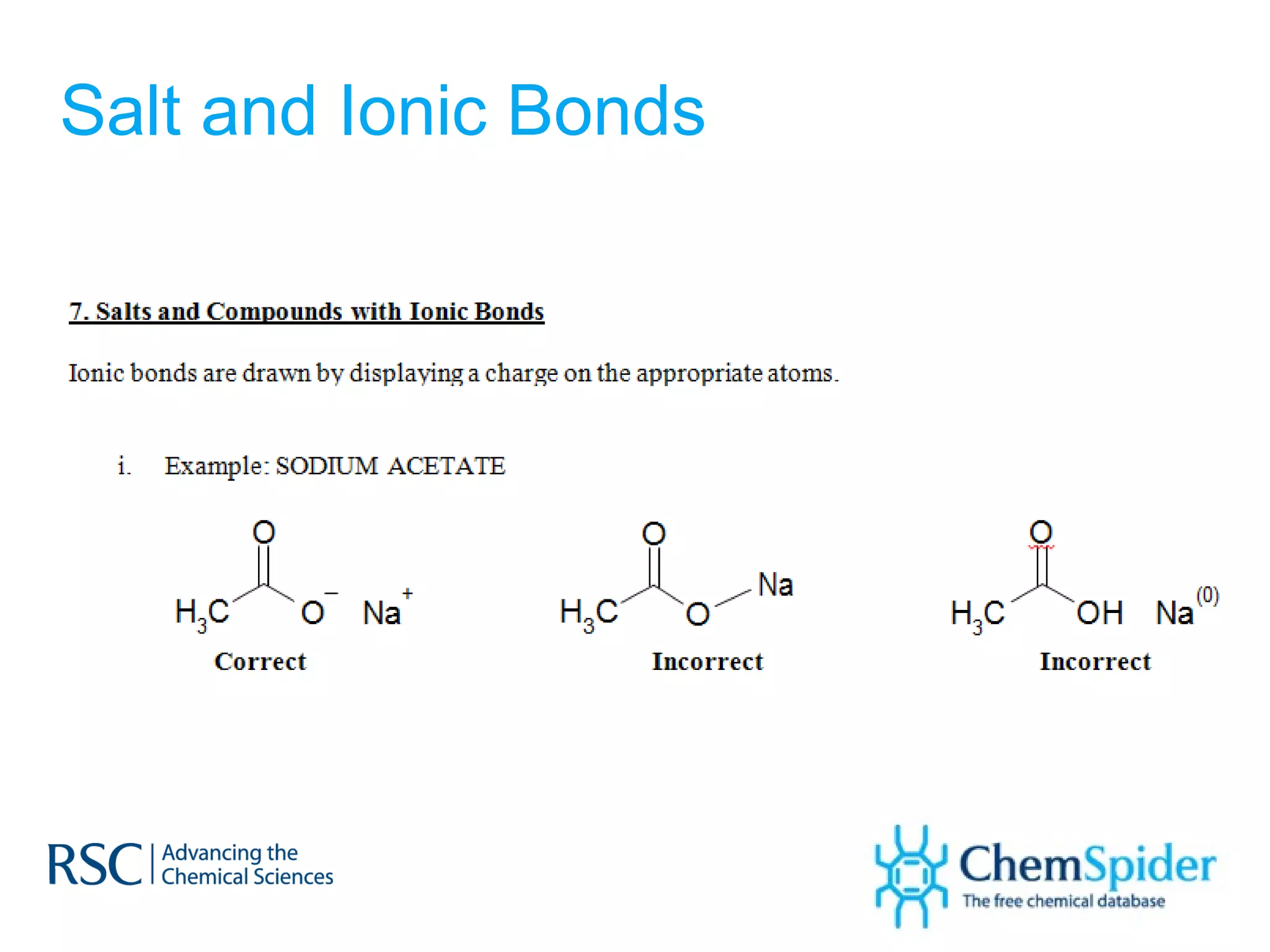







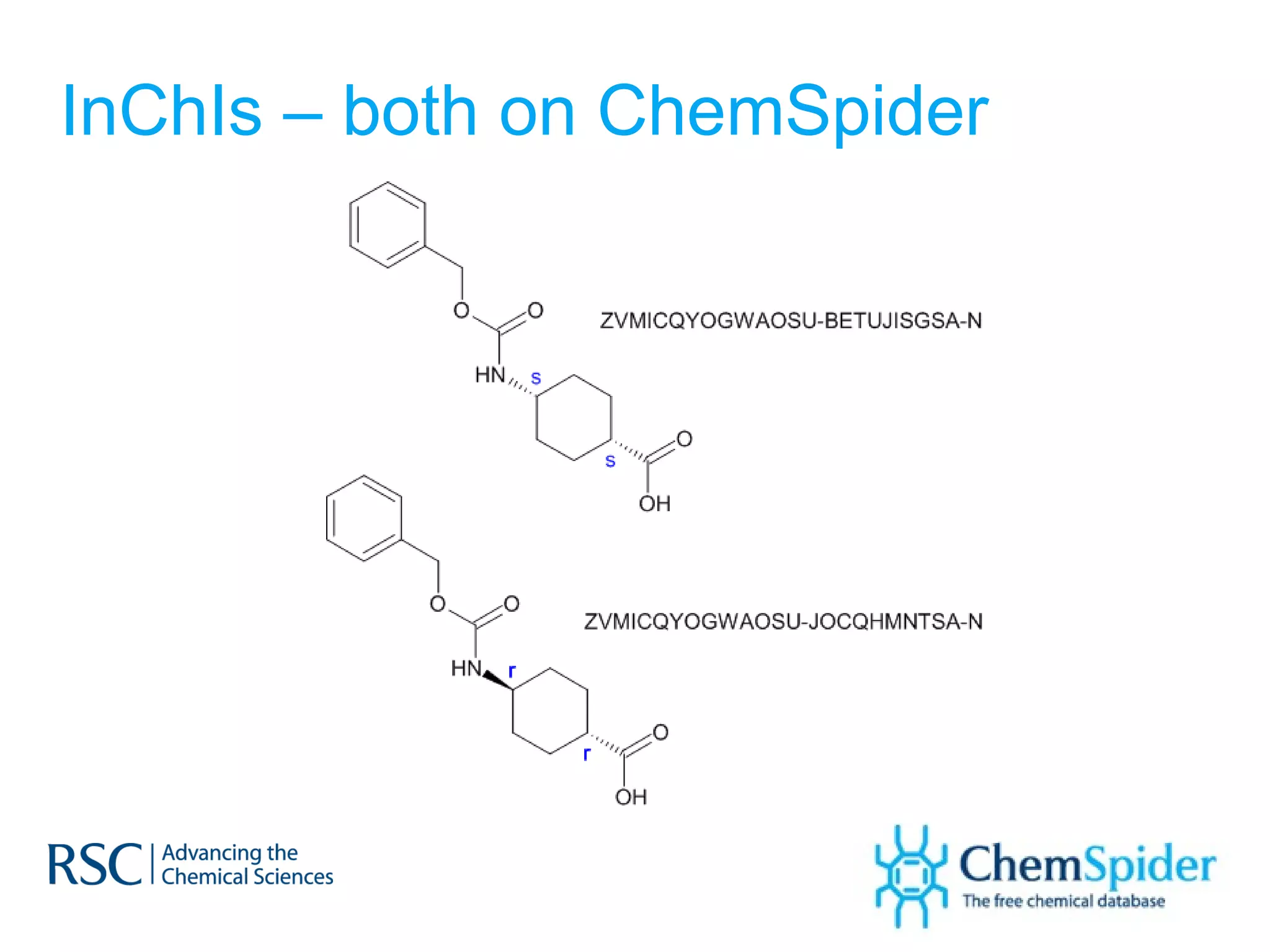
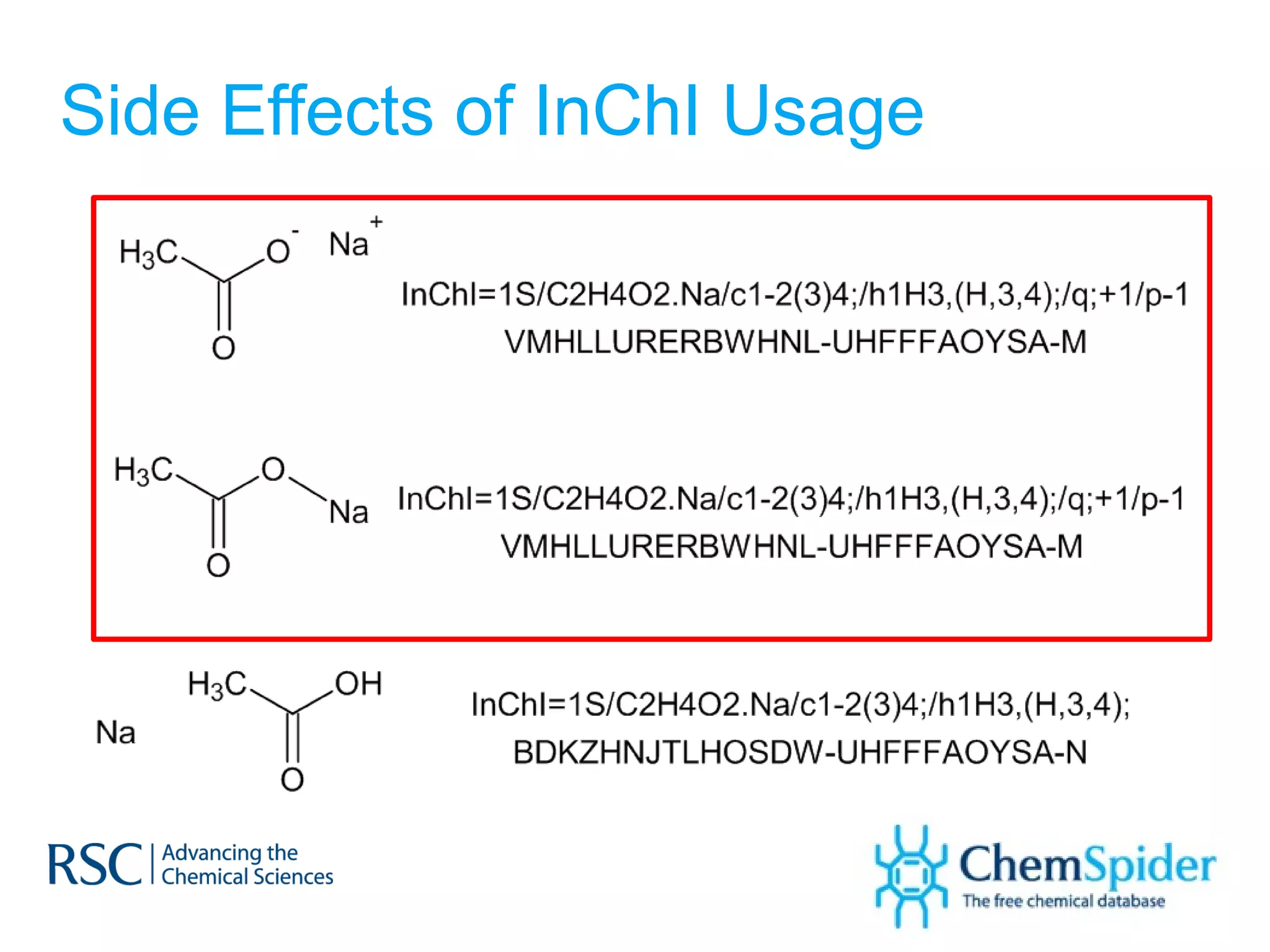
ChemSpider is an online database offering over 26 million unique molecules, utilizing open source components and crowd-sourced data curation. It addresses challenges in data quality and standardization, particularly with the InChI system, while focusing on accurate name-structure relationships for chemical entities. The project aims to standardize its entire database and enhance collaboration among data providers to improve the quality of chemical information available online.


































































