
Download to read offline




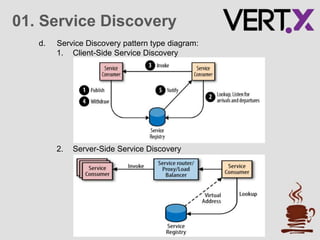
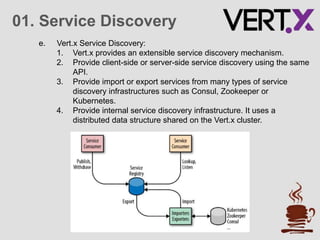






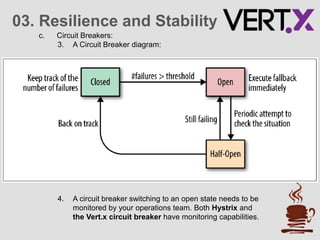



The document discusses service discovery patterns essential for microservices, emphasizing client-side and server-side discovery methods. It elaborates on resilience and stability patterns, including failure management, circuit breakers, and health checks, outlining how to handle potential failures in microservices. Additionally, it provides practical steps for setting up a demo using Vert.x for service discovery and application resilience.



































































