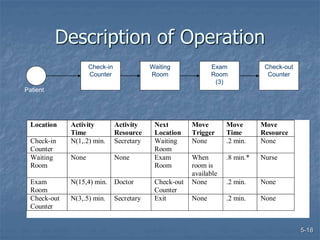
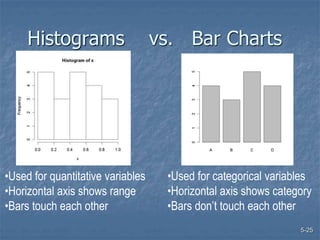
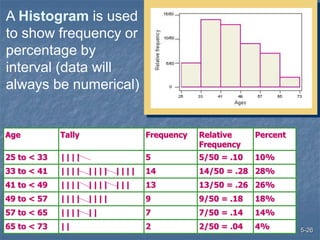
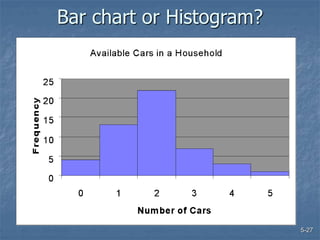
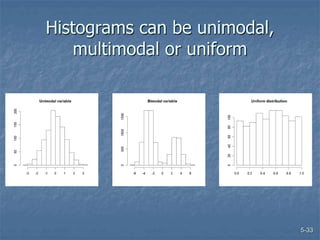
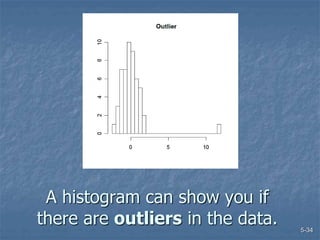
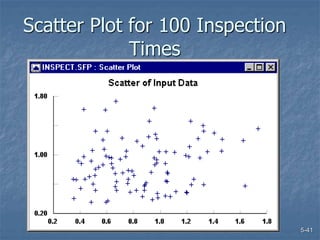
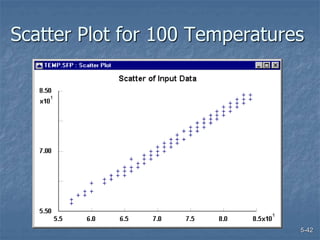
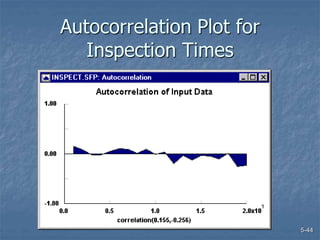
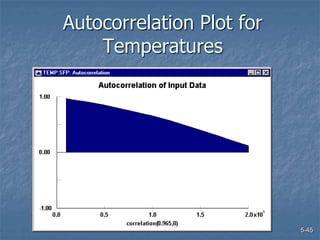
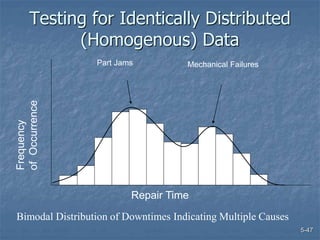
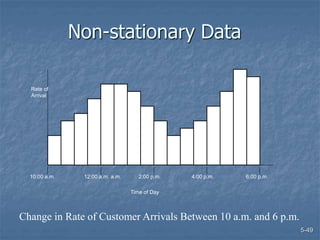
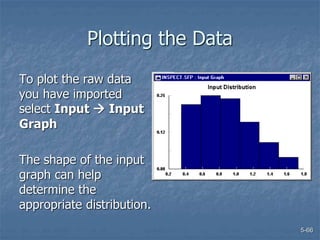
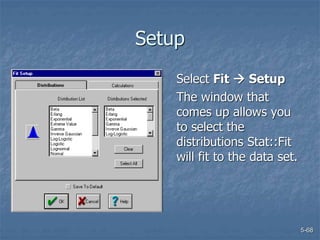
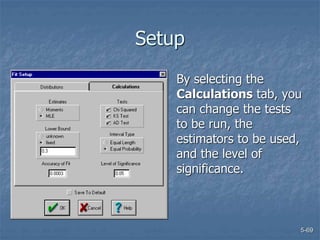
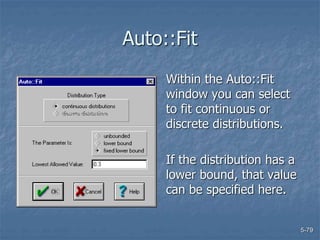
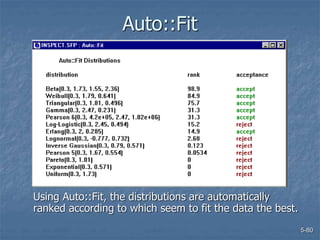
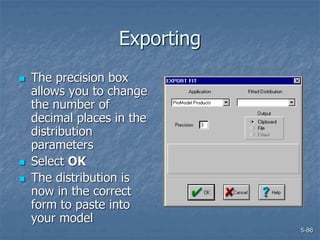
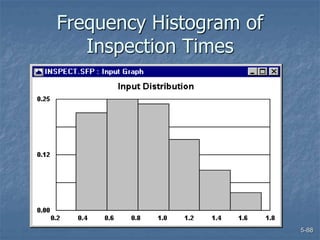
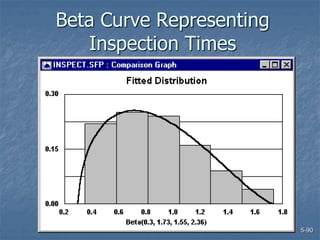
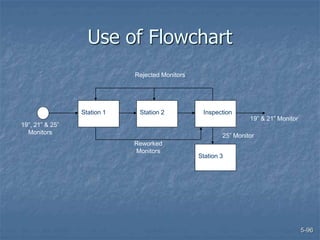
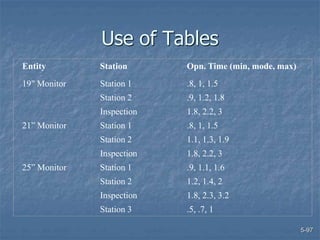
This document discusses data collection and analysis for simulation modeling. It addresses questions like what types of data to gather, how to gather and analyze data, and how to represent data in a simulation. The key types of data are structural, operational, and numerical. Data should be gathered through methods like questionnaires, observation, and interviews. Basic statistical analysis techniques are described for understanding data characteristics like center, spread, and outliers. Common probability distributions are also introduced for representing random variables in a simulation model.