Download to read offline




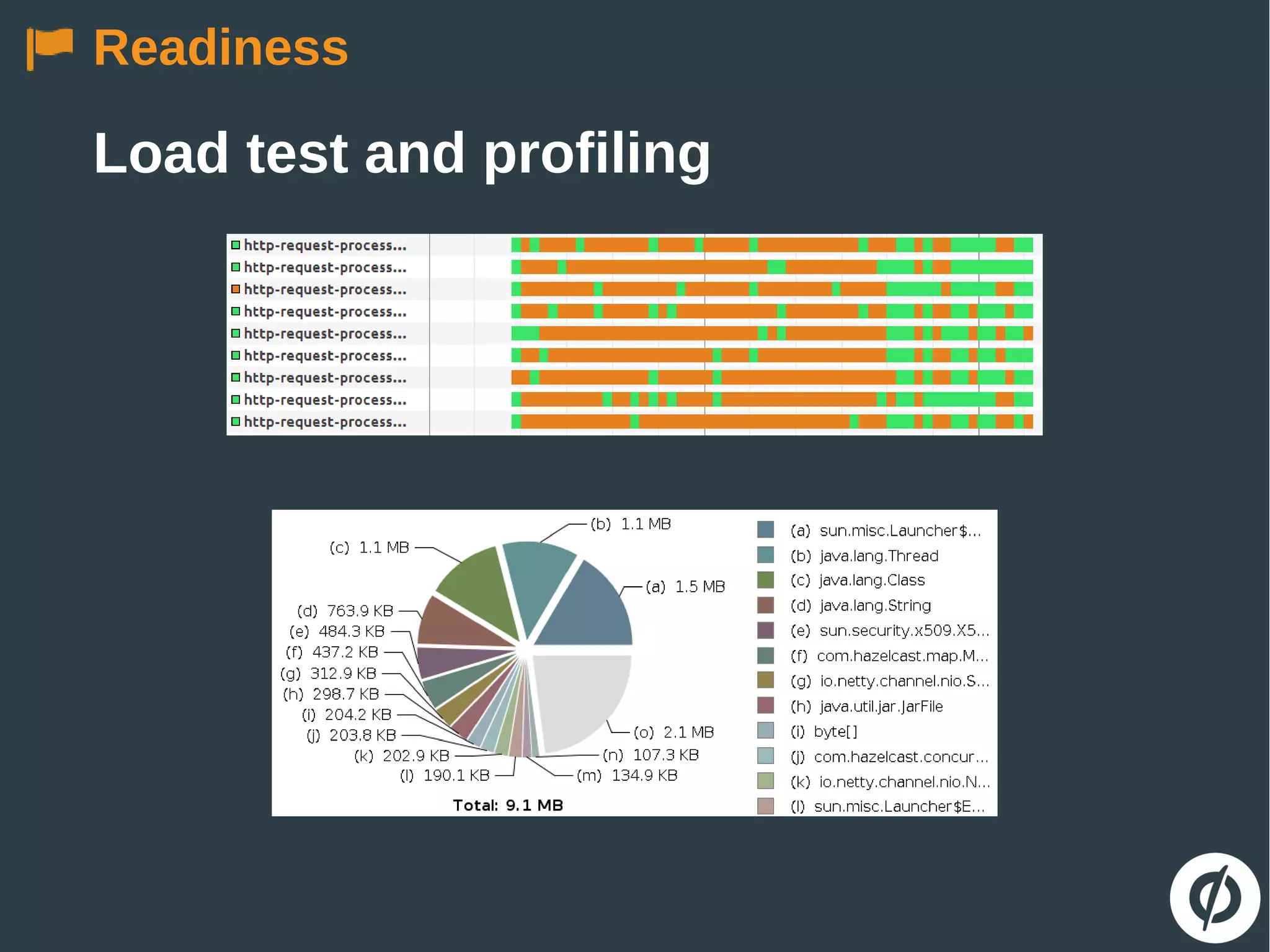


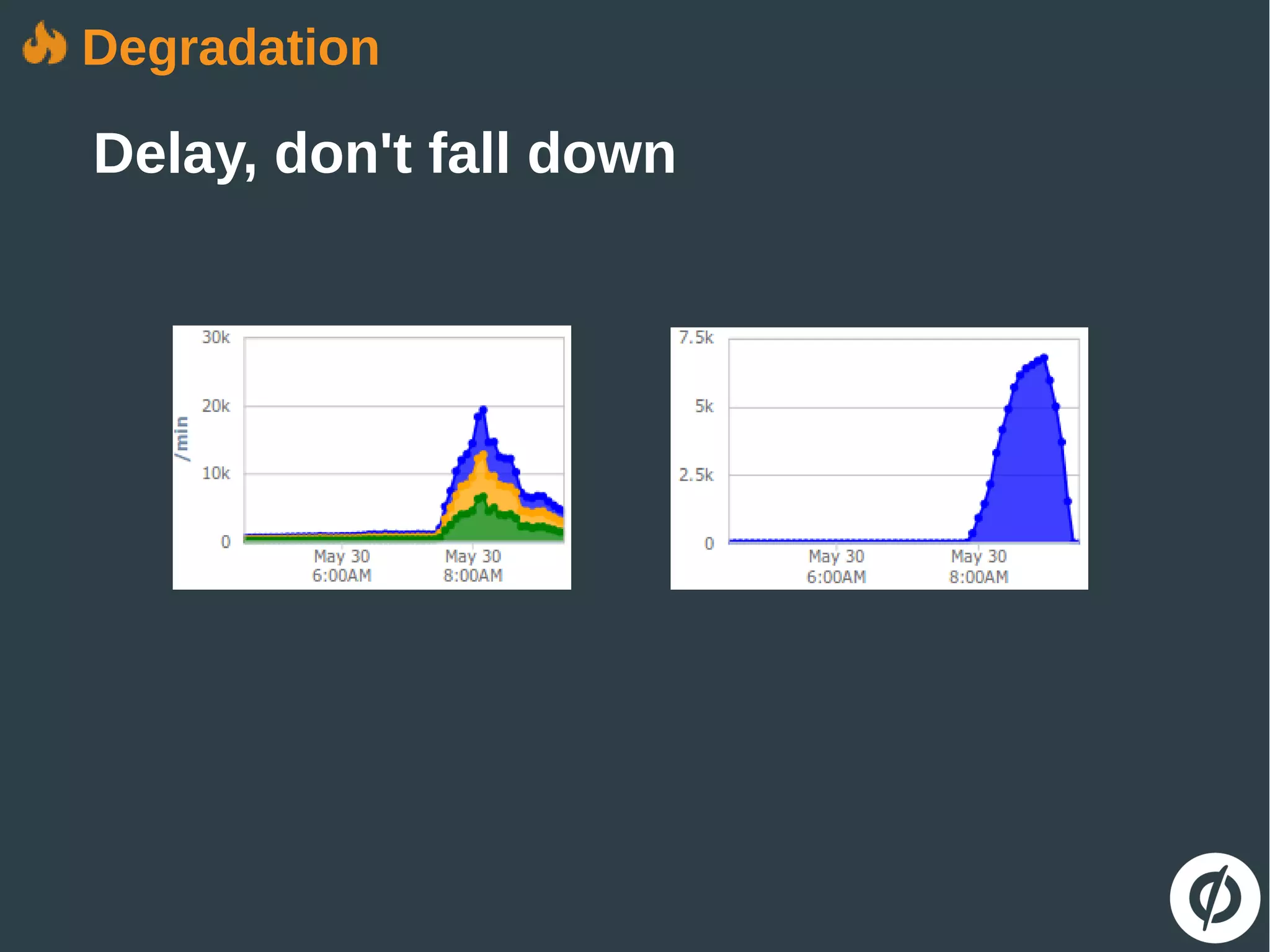


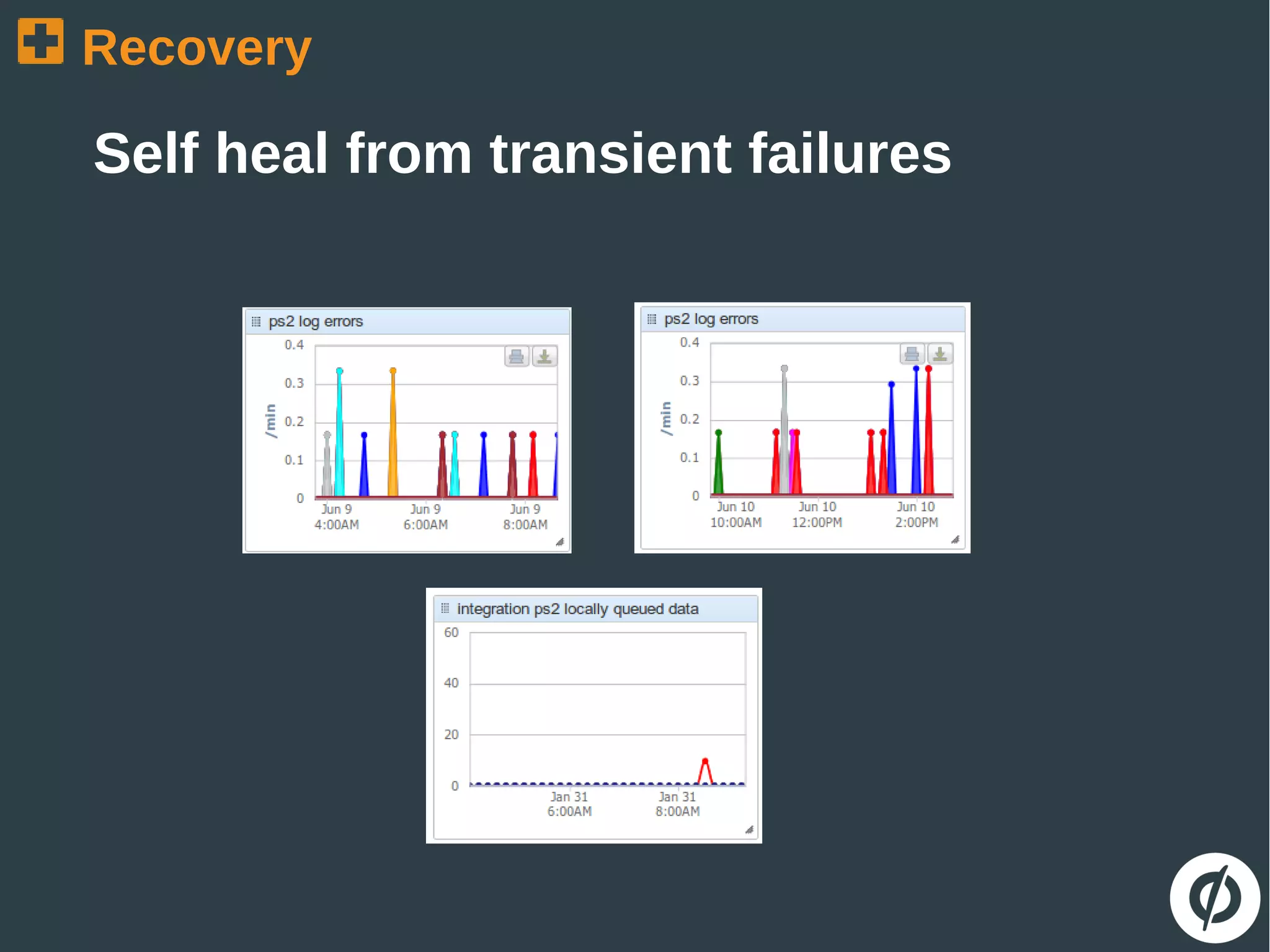
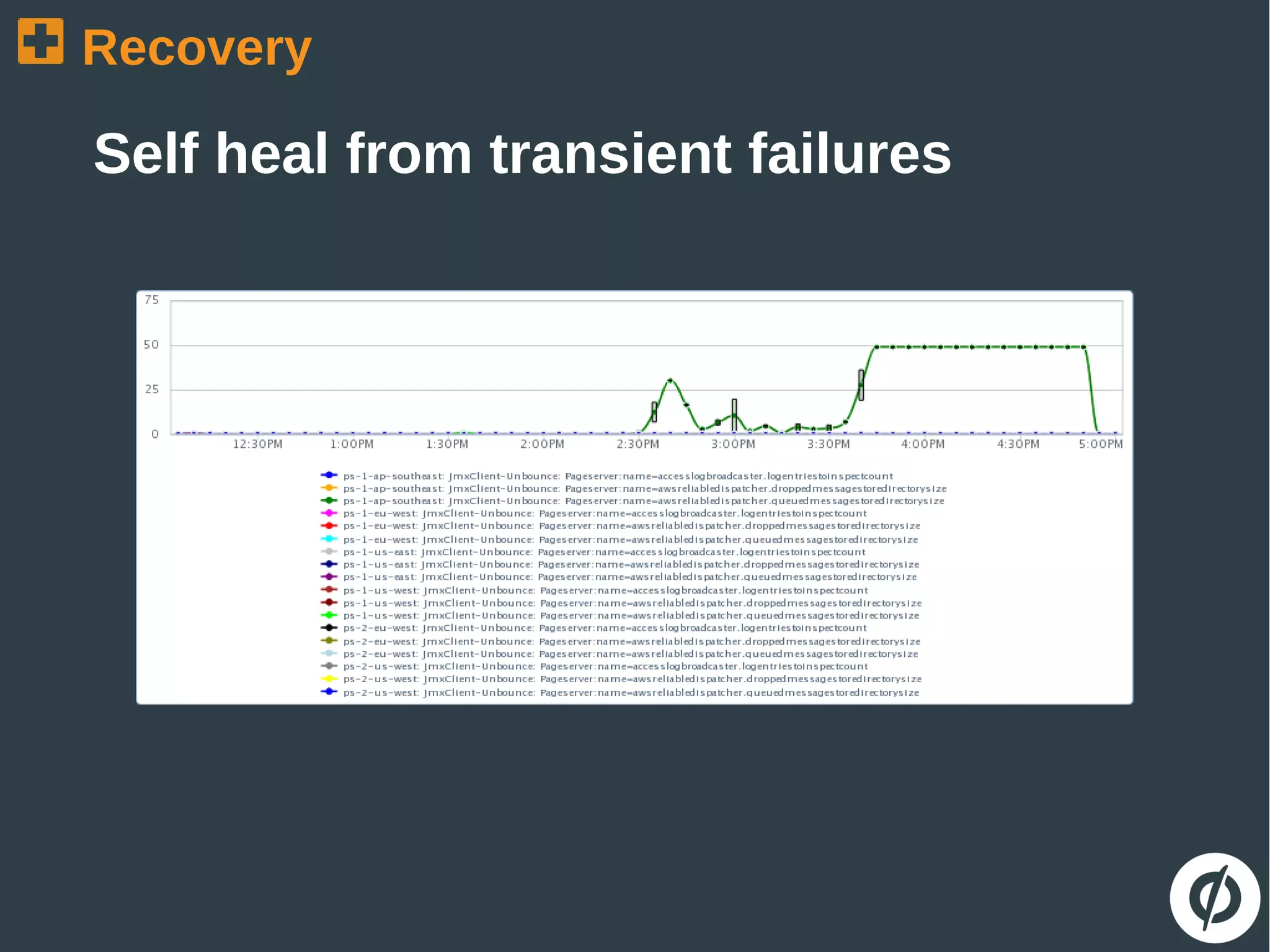







The document discusses the challenges and strategies in building robust applications capable of handling heavy web traffic and potential failures. It emphasizes the importance of strategies such as load testing, queue decoupling, and healthy logging for system recovery and stability. The overall message revolves around viewing failures as opportunities for improvement and implementing defensive coding practices.
































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













